分布式链路追踪系统 Zipkin 埋点库 Brave 使用入门
- - 叉叉哥的BLOG微服务架构下,服务之间的关系错综复杂. 从调用一个 HTTP API 到最终返回结果,中间可能发生了多个服务间的调用. 而这些被调用的服务,可能部署在不同的服务器上,由不同的团队开发,甚至可能使用了不同的编程语言. 在这样的环境中,排查性能问题或者定位故障就很麻烦. Zipkin 是一个分布式链路追踪系统(distributed tracing system).
微服务架构下,服务之间的关系错综复杂。从调用一个 HTTP API 到最终返回结果,中间可能发生了多个服务间的调用。而这些被调用的服务,可能部署在不同的服务器上,由不同的团队开发,甚至可能使用了不同的编程语言。在这样的环境中,排查性能问题或者定位故障就很麻烦。
Zipkin 是一个分布式链路追踪系统(distributed tracing system)。它可以收集并展示一个 HTTP 请求从开始到最终返回结果之间完整的调用链。
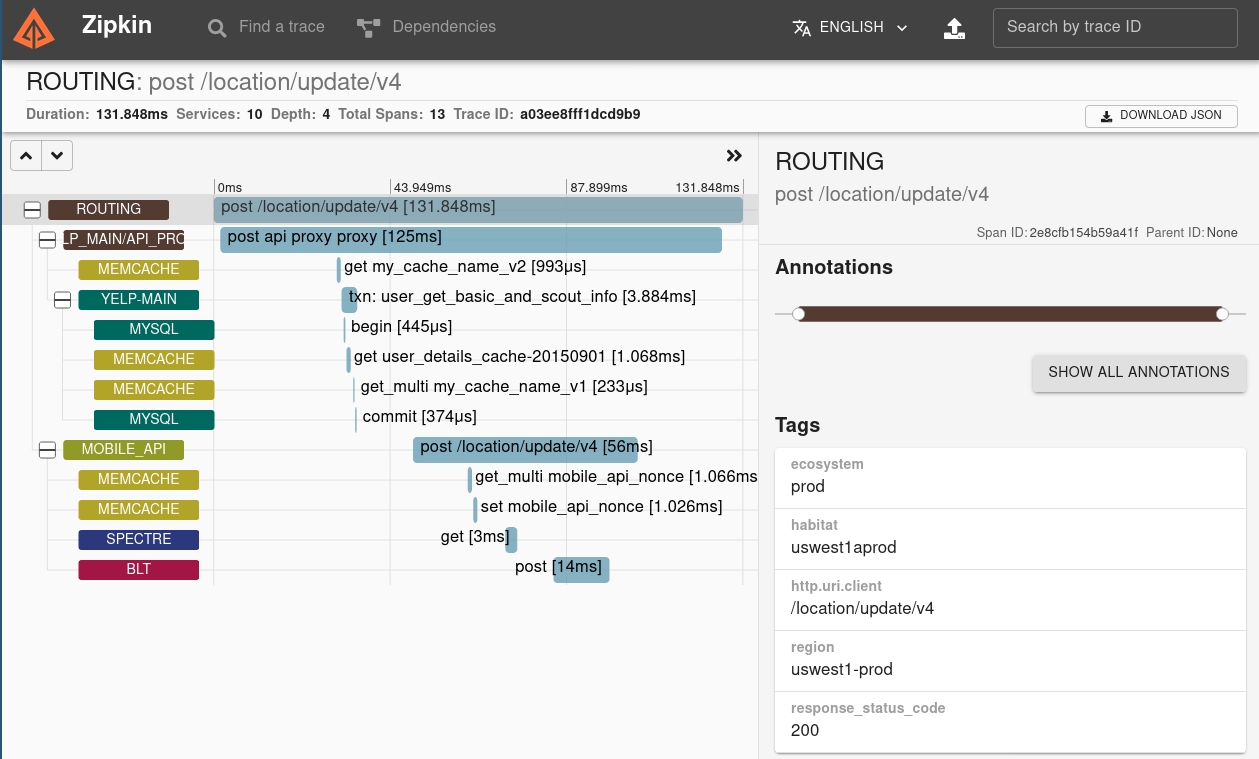
Trace 代表一个完整的调用链。一个 trace 对应一个随机生成的唯一的 traceId。例如一个 HTTP 请求到响应是一个 trace。一个 trace 内部包含多个 span。Span Trace 中的一个基本单元。一个 span 同样对应一个随机生成的唯一的 spanId。例如一个 HTTP 请求到响应过程中,内部可能会访问型数据库执行一条 SQL,这是一个新的 span,或者内部调用另外一个服务的 HTTP API 也是一个新的 span。一个 trace 中的所有 span 是一个树形结构,树的根节点叫做 root span。除 root span 外,其他 span 都会包含一个 parentId,表示父级 span 的 spanId。 Annotation 每个 span 中包含多个 annotation,用来记录关键事件的时间点。例如一个对外的 HTTP 请求从开始到结束,依次有以下几个 annotation:
cs Client Send,客户端发起请求的,这是一个 span 的开始sr Server Receive,服务端收到请求开始处理ss Server Send,服务端处理请求完成并响应cr Client Receive,客户端收到响应,这个 span 到此结束记录了以上的时间点,就可以很容易分析出一个 span 每个阶段的耗时:
cr - cs 是整个流程的耗时sr - cs 以及 cr - ss 是网络耗时ss - sr 是被调用服务处理业务逻辑的耗时然而, sr 和 ss 两个 annotation 依赖被调用方,如果被调用方没有相应的记录,例如下游服务没有对接 instrumentation 库,或者像执行一条 SQL 这样的场景,被调用方是一个数据库服务,不会记录 sr 和 ss,那么这个 span 就只有 cs 和 cr。
相关文档:
当上游服务通过 HTTP 调用下游服务,如何将两个服务中的所有 span 串联起来,形成一个 trace,这就需要上游服务将 traceId 等信息传递给下游服务,而不能让下游重新生成一个 traceId。
Zipkin 通过 B3 传播规范(B3 Propagation),将相关信息(如 traceId、spanId 等)通过 HTTP 请求 Header 传递给下游服务:
1 | Client Tracer Server Tracer |
相关文档:
GitHub 仓库: https://github.com/openzipkin/brave
Brave is a distributed tracing instrumentation library.
翻译: Brave 是分布式链路追踪的埋点库。
instrumentation 这个单词本意是”仪器、仪表、器乐谱写”,为了更加便于理解,这里我翻译为”埋点”。埋点的意思就是在程序的关键位置(即上面介绍的各个 annotation)做一些记录。
在 GitHub 仓库的 instrumentation 目录中,可以看到官方已经提供了非常多的 instrumentation。
另外在 https://zipkin.io/pages/tracers_instrumentation 文档中,还有其他非 Java 语言的 instrumentation 以及非官方提供的 instrumentation,可以根据需要来选择。其他 instrumentation 本文不做介绍,本文重点是 Zipkin 官方提供的 Java 语言 instrumentation : Brave 。
本文以 Web 服务为例,不涉及像 Dubbo 这样的 RPC 服务。
假设现有一个 Spring MVC 项目想要对接 Zipkin,需要使用 Brave 埋点,并将相关数据提交到 Zipkin 服务上。
首先加入一个 dependencyManagement,这样就不需要在各个依赖包中添加版本号了:
1 | <dependencyManagement> |
最新版本号可以在这里查看:
https://mvnrepository.com/artifact/io.zipkin.brave/brave-bom
需要注意的是,不同版本配置方法会略有差异,具体可以参考官方文档。本文使用的 Brave 版本号为 5.11.2。
添加依赖:
1 | <dependency> |
下面提供了两种配置方式( Java 配置方式 和 XML 配置方式)创建 Tracing 对象,需要根据项目的实际情况选择其中一种。
如果现有的项目是 Spring Boot 项目或者非 XML 配置的 Spring 项目,可以采用这种方式。
1 | @Configuration |
如果现有项目是采用 XML 配置的 Spring 项目,可以采用这种方式。
相对于 Java 配置方式,需要多添加一个 brave-spring-beans 依赖:
1 | <dependency> |
该模块提供了一系列 Spring FactoryBean,用于通过 XML 来创建对象:
1 | <bean id="sender" class="zipkin2.reporter.beans.OkHttpSenderFactoryBean"> |
上面两种方式本质上是一样的,都是创建了一个 Tracing 对象。
该对象是单实例的,如果想要在其他地方获取到这个对象,可以通过静态方法 Tracing tracing = Tracing.current() 来获取。
Tracing 对象提供了一系列 instrumentation 所需要的工具,例如 tracing.tracer() 可以获取到 Tracer 对象, Tracer 对象的作用后面会有详细介绍。
创建 Tracing 对象一些相关属性:
localServiceName 服务的名称spanReporter 指定一个 Reporter<zipkin2.Span> 对象作为埋点数据的提交方式,这里通常会使用静态方法 AsyncReporter.create(Sender sender) 来创建一个 AsyncReporter 对象,当然如果有特殊需求也可以自己实现 Reporter 接口来自定义提交方式。创建 AsyncReporter 对象需要提供一个 Sender,下面列出了一些官方提供的 Sender 可供选择: zipkin-sender-okhttp3 使用 OkHttp3 提交,使用方法: sender = OkHttpSender.create("http://localhost:9411/api/v2/spans"),本文中的示例使用的就是这种方式zipkin-sender-urlconnection 使用 Java 自带的 java.net.HttpURLConnection 提交,使用方法: sender = URLConnectionSender.create("http://localhost:9411/api/v2/spans")zipkin-sender-activemq-client 使用 ActiveMQ 消息队列提交,使用方法: sender = ActiveMQSender.create("failover:tcp://localhost:61616")zipkin-sender-kafka 使用 Kafka 消息队列提交,使用方法: sender = KafkaSender.create("localhost:9092")zipkin-sender-amqp-client 使用 RabbitMQ 消息队列提交,使用方法: sender = RabbitMQSender.create("localhost:5672") currentTraceContext 指定一个 CurrentTraceContext 对象来设置 TraceContext 对象的作用范围,通常会使用 ThreadLocalCurrentTraceContext,也就是用 ThreadLocal 来存放 TraceContext。 TraceContext 包含了一个 trace 的相关信息,例如 traceId。
由于在 Spring MVC 应用中,一个请求的业务逻辑通常在同一个线程中(暂不考虑异步 Servlet)。一个请求内部的所有业务逻辑应该共用一个 traceId,自然是把 TraceContext 放在 ThreadLocal 中比较合理。这也意味着,默认情况下 traceId 只在当前线程有效,跨线程会失效。当然,跨线程也有对应的方案,本文后续会有详细介绍。
在 CurrentTraceContext 中可以添加 ScopeDecorator ,通过 MDC (Mapped Diagnostic Contexts) 机制关联一些日志框架:
以 Logback 为例(本文中案例使用的方式),可以配置下面的 pattern 在日志中输出 traceId 和 spanId:
1 | <pattern>%d [%X{traceId}/%X{spanId}] [%thread] %-5level %logger{36} - %msg%n</pattern> |
添加依赖:
1 | <dependency> |
首先创建 HttpTracing 对象,用于 HTTP 协议链路追踪。
Java 配置方式:
1 | @Bean |
XML 配置方式:
1 | <bean id="httpTracing" class="brave.spring.beans.HttpTracingFactoryBean"> |
DelegatingTracingFilter 用于处理外部调用的 HTTP 请求,记录 sr(Server Receive) 和 ss(Server Send) 两个 annotation。
非 Spring Boot 项目可以在 web.xml 中添加 DelegatingTracingFilter:
1 | <filter> |
如果是 Spring Boot 项目可以用 FilterRegistrationBean 来添加 DelegatingTracingFilter:
1 | @Bean |
到此,Spring MVC 项目已经完成了最基本的 Brave 埋点和提交 Zipkin 的配置。如果有现有的 Zipkin 服务,将创建 OkHttpSender 提供的接口地址换成实际地址,启动服务后通过 HTTP 请求一下服务,就会在 Zipkin 上找到一个对应的 trace。
由于每个服务内部还会调用其他服务,例如通过 HTTP 调用外部服务的 Api、连接远程数据库执行 SQL,此时还需要用到其他 instrumentation。
由于篇幅有限,下面仅介绍几个常用的 instrumentation。
brave-instrumentation-mysql 可以为 MySQL 上执行的每条 SQL 语句生成一个 span,用于分析 SQL 的执行时间。
添加依赖:
1 | <dependency> |
使用方法:在 JDBC 连接地址末尾加上参数 ?statementInterceptors=brave.mysql.TracingStatementInterceptor 即可。
该模块用于 mysql-connector-java 5.x 版本,另外还有 brave-instrumentation-mysql6 和 brave-instrumentation-mysql8 可分别用于 mysql-connector-java 6+ 和 mysql-connector-java 8+ 版本。
brave-instrumentation-okhttp3 用于 OkHttp 3.x,在通过 OkHttpClient 请求外部 API 时,生成 span,并且通过 B3 传播规范将链路信息传递给被调用方。
添加依赖:
1 | <dependency> |
使用方法:
1 | OkHttpClient okHttpClient = new OkHttpClient.Builder() |
如果你使用的 HTTP 客户端库不是 OkHttp 而是 Apache HttpClient 的话,可以使用 brave-instrumentation-httpclient。
1 | Span currentSpan = Tracing.currentTracer().currentSpan(); // 获取当前 span |
可将业务相关的信息写入 tag 中,方便在查看调用链信息时关联查看业务相关信息。
1 | Span currentSpan = Tracing.currentTracer().currentSpan(); // 获取当前 span |
如果使用了某些组件访问外部服务,找不到官方或开源的 instrumentation,或者有一个本地的耗时任务,也想通过创建一个 span 来记录任务的运行时间和结果,可以自己创建一个新的 span。
1 | ScopedSpan span = Tracing.currentTracer().startScopedSpan("span name"); |
下面是另外一种方式,这种方式提供了更多的特性:
1 | Tracer tracer = Tracing.currentTracer(); |
1 | Runnable runnable = ...; // 原始的 Runnable 对象 |
同样的方式也可以使用于 Callable 对象。
1 | ExecutorService service = ....; |
除 Zipkin 之外,还有很多优秀的开源或商业的分布式链路追踪系统。其中一部分对 Zipkin 协议做了兼容,如果不想使用 Zipkin 也是可以尝试一下其他的分布式链路追踪系统。