游戏排名算法:Elo、Glicko、TrueSkill
- - 标点符Elo等级分制度(英语:Elo rating system)是指由匈牙利裔美国物理学家Arpad Elo创建的一个衡量各类对弈活动水平的评价方法,是当今对弈水平评估公认的权威标准,且被广泛用于国际象棋、围棋、足球、篮球等运动. 网络游戏的竞技对战系统也采用此分级制度. ELO等级分制度是基于统计学的一个评估棋手水平的方法.
Elo等级分制度(英语:Elo rating system)是指由匈牙利裔美国物理学家Arpad Elo创建的一个衡量各类对弈活动水平的评价方法,是当今对弈水平评估公认的权威标准,且被广泛用于国际象棋、围棋、足球、篮球等运动。网络游戏的竞技对战系统也采用此分级制度。
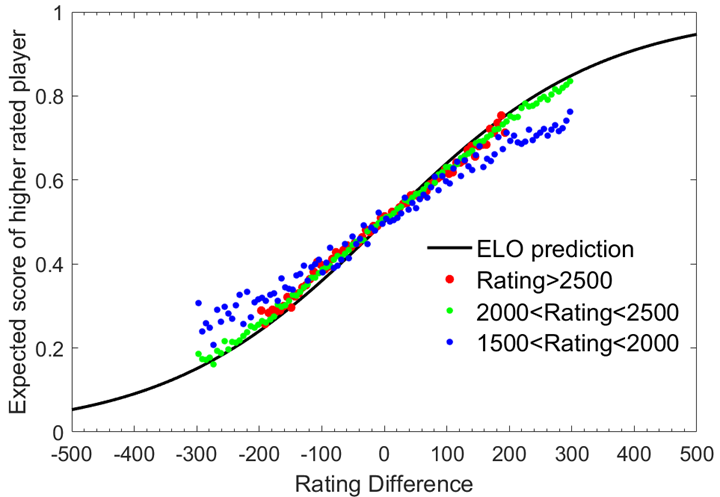
ELO等级分制度是基于统计学的一个评估棋手水平的方法。美国国际象棋协会在1960年首先使用这种计分方法。由于它比先前的方法更公平客观,这种方法很快流行开来。1970年国际棋联正式开始使用等级分制度。Elo模型原先采用正态分布。但是实践显明棋手的表现并非呈正态分布,所以现在的等级分计分系统通常使用的是逻辑分布。
两个选手(player)在排名系统的不同,可以用来预测比赛结果。两个具有相同排名(rating)的选手相互竞争时,不管哪一方获胜都会得到相同的得分(score)。如果一个选手的排名(rating)比他的对手高100分,则得64%;如果差距是200分,那么排名高的选手的期望得分(expected score)应为76%。(可以理解为,获胜的机率更高)
一个选手的Elo rating由一个数字表示,它的增减依赖于排名选手间的比赛结果。在每场游戏后,获胜者将从失利方获得分数。胜者和败者间的排名的不同,决定着在一场比赛后总分数的获得和丢失。在高排名选手和低排名选手间的系列赛中,高排名的选手按理应会获得更多的胜利。如果高排名选手获胜,那么只会从低排名选手处获得很少的排名分(rating point)。然而,如果低排名选分爆冷获胜(upset win),可以获得许多排名分。低排名选手在平局的情况下也能从高排名选手处获得少量的得分。这意味着该排名系统是自动调整的(self-correcting)。长期来看,一个选手的排名如果太低,应比排名系统的预测做得更好,这样才能获得排名分,直到排名开始反映出他们真正的实力。
计分方法
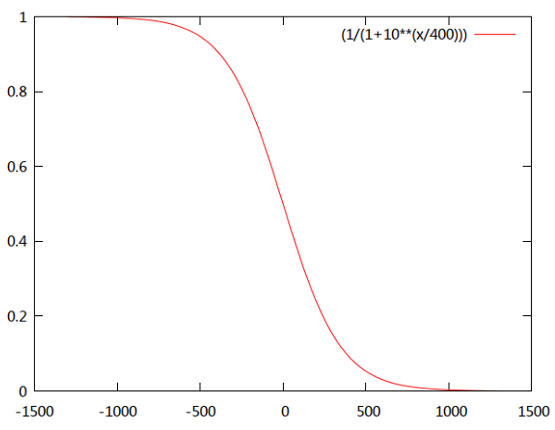
假设棋手A和B的当前等级分分别为$R_{A}$和$R_{B}$,则按Logistic distribution A对B的胜率期望值当为:
$$E_{A}=\frac {1}{1+10^{(R_{B}-R_{A})/400}}$$
类似B对A的胜率为:
$$E_{B}=\frac {1}{1+10^{(R_{A}-R_{B})/400}}$$
假如一位棋手在比赛中的真实得分$S_{A}$(胜=1分,和=0.5分,负=0分)和他的胜率期望值$E_{A}$不同,则他的等级分要作相应的调整。具体的数学公式为:
$$R_{A}^{\prime }=R_{A}+K(S_{A}-E_{A})$$
公式中$R_{A}$和$R_{A}^{\prime }$分别为棋手调整前后的等级分。在大师级比赛中{K通常为16。
例如,棋手A等级分为1613,与等级分为1573的棋手B战平。若K取32,则A的胜率期望值为$\frac {1}{1+10^{(1573-1613)/400}}$,约为0.5573,因而A的新等级分为1613 + 32*(0.5-0.5573) = 1611.166
世界足球Elo评级是由网站eloratings.net发布的男子国家联盟足球队的排名系统。它基于Elo评级系统,但也对足球运动修改了特定各种的变量。其中包括:净胜球的数量,比赛的重要程度,主场优势。这使得Elo评级方法可以用来对足球运动的球队进行排名,但目前还没有任何球队的官方,使用根据Elo系统算出的球队评级排名。
Elo评级背后的基本原则是将所有球队以一个联赛的形式进行赛后积分统计,球队不比赛等级分不会变动,这与国际足联计算世界排名的方式并不相同。Elo自己有一个复杂全面且有效的权重评分系统,这与国际足联计分系统中的第一步也不相同。另外在国际足联系统中,球队会在赛后计算后直接获得现有分数,而Elo系统中只是算出加减分数,然后再得出当前分数。
等级分的计算是基于以下公式:
$$R_{n}=R_{o}+KG(W-W_{e})$$
或者
$$P=KG(W-W_{e})$$
注解:
在计算球队的等级分时会将小数点四舍五入。
比赛的重要程度
比赛的权重指数由重要程度来衡量,这个指数反映了比赛的重要程度,指数越高比赛越重要。而这主要取决于该场比赛是属于什么类型的比赛。各主要赛事的重要程度指数如下表所示:
| 比赛类型 | 指数 (K) |
| 世界杯 | 60 |
| 洲际锦标赛和洲际锦标赛决赛 | 50 |
| 世界杯和洲际锦标赛的预选赛 | 40 |
| 其他所有比赛 | 30 |
| 友谊赛 | 20 |
进球数
如果比赛是平局,或者是一球小胜:G=1
如果比赛赢了两个净胜球:$G=\frac {3}{2}$
如果比赛赢了三个净胜球或以上:这里的 N 指的是净胜球数 $G=\frac {11+N}{8}$
示例表:
| 净胜球 | K (G)系数 |
| 0 | 1 |
| +1 | 1 |
| +2 | 1.5 |
| +3 | 1.75 |
| +4 | 1.875 |
| +5 | 2 |
| +6 | 2.125 |
| +7 | 2.25 |
| +8 | 2.375 |
| +9 | 2.5 |
| +10 | 2.625 |
比赛结果
W是比赛的结果(胜一局为1,平一局为0.5,负一局为0)。注意:如果比赛拖进加时赛决胜负,那么加时赛的结果也会被计算在内。如果比赛由点球大战决定胜负,则比赛将会被判定为平局(W=0.5)。
比赛预期结果
$W_e$是比赛的预期结果,从下列公式得出:(比赛的结果符合预期为0.5):
$$W_{e}=\frac {1}{10^{-dr/400}+1}$$
这里的dr是评级分的差额(为主队增加100分)。dr为0时获得0.5、为120时,高排名的队伍为0.666,低排名的队伍为0.334、为800时,高排名的队伍为0.99,低排名的队伍为0.01。
另一种更为被大众所熟知的足球排名:国际足联世界排名则不是基于Elo系统,而是由国际足球管理机构使用自己官方的国家球队评级系统进行计算。但是国际足联女子世界排名系统却采用了一种修改后的Elo系统计算公式。
计分规则
$$R_{aft}=R_{bef}+K(S_{act}-S_{exp})$$
$$S_{exp}=\frac {1}{1+10^{-x/2}}$$
$$x=\frac {R_{bef}-O_{bef}\pm H}{c}$$
所有球队的平均积分约为1300分。顶级国家通常超过2000分。为了进行排名,一支球队必须与正式排名的球队至少打过5场比赛,并且已经没有超过18个月停赛。即使球队没有正式排名,他们的积分评分也会保持不变,直到他们进行下一场比赛。
实质比赛结果
实际结果的主要组成部分是球队是赢球,输球还是平局,但球差也被考虑在内。
如果比赛结果为赢家和输家,输家将获得由附表给出的百分比,结果总是小于或等于20%(对于大于零的目标差异)。其结果是基于目标差异和他们得分的目标数量。剩下的百分数奖励给获胜者。例如,2-1场比赛的比赛结果分别为84%-16%,4-3场比赛的比赛结果为82%-18%,8-3场比赛的比赛结果为96.2%-3.8%。因此,即使他们赢得比赛,球队也有可能失分,假设他们没有赢得足够的胜利。
如果比赛以平局结束,球队将获得相同的结果,但数量取决于得分目标,因此结果不一定总和为100%。例如,0-0平局每队获得47%的收入,1-1平局每场获得50%,4-4平局每场获得52.5%。
进球
以下是从非胜者的角度(落败或和局)。获胜队伍的因素最多可达100%。
| 进球差 | |||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 /+ | |
| 非胜队的进球数 | 给予比例(百分比) | ||||||
| 0 | 47 | 15 | 8 | 4 | 3 | 2 | 1 |
| 1 | 50 | 16 | 8.9 | 4.8 | 3.7 | 2.6 | 1.5 |
| 2 | 51 | 17 | 9.8 | 5.6 | 4.4 | 3.2 | 2 |
| 3 | 52 | 18 | 10.7 | 6.4 | 5.1 | 3.8 | 2.5 |
| 4 | 52.5 | 19 | 11.6 | 7.2 | 5.8 | 4.4 | 3 |
| 5 | 53 | 20 | 12.5 | 8 | 6.5 | 5 | 3.5 |
胜者可以获得
| 进球差 | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 /+ | |
| 落败队伍的进球数 | 给予比例(百分比) | |||||
| 0 | 85 | 92 | 96 | 97 | 98 | 99 |
| 1 | 84 | 91.1 | 95.2 | 96.3 | 97.4 | 98.5 |
| 2 | 83 | 90.2 | 94.4 | 95.6 | 96.8 | 98 |
| 3 | 82 | 89.3 | 93.6 | 94.9 | 96.2 | 97.5 |
| 4 | 81 | 88.4 | 92.8 | 94.2 | 95.6 | 97 |
| 5 | 80 | 87.5 | 92 | 93.5 | 95 | 96.5 |
中立场或主客场
在历史统计上,主队获得66%的积分,而客队获得34%的积分。
这也有助于定义缩放常数c,其值为200。除了导致预期结果差异为64%-36%的100点差异外,还导致会有300积分的差异,导致预期结果为85%-15%。
比赛系数
| 重要比赛 | 重要比赛系数(M) | K-value |
| 国际足联女子世界杯比赛 | 4 | 60 |
| 女子奥运足球比赛 | 4 | 60 |
| 女子世界杯外围赛 | 3 | 45 |
| 女子奥运会外围赛 | 3 | 45 |
| 女子洲区决赛圈 | 3 | 45 |
| 女子洲区外围赛 | 2 | 30 |
| 两队间前10友谊赛 | 2 | 30 |
| 友谊赛 | 1 | 15 |
2018年6月10日,国际足联公布了最新的排名系统:
$$P=P_{\text{before}}+I(W-W_{e})$$
其中:
Glicko评分系统(英文:Glicko rating system)及Glicko-2评分系统(英文:Glicko-2 rating system)是评估选手在比赛中(如国际象棋及围棋)的技术能力方法之一。此方法由马克·格利克曼发明,原为国际象棋评分系统打造,后作为等级分评分系统的改进版本广泛应用。格里克曼在此算法中的主要贡献是“评分可靠性”(Ratings Reliability,简称RD),即评分标准差(Ratings Deviation)。
Glicko与Glicko-2评分系统被发表至公有领域。诸多在线游戏服务器(如《Pokémon Showdown》、《Lichess》、《自由互联网国际象棋服务器》、《Chess.com》、《在线围棋服务器 (页面存档备份,存于互联网档案馆)》[1]、《反恐精英:全球攻势》、《军团要塞2》、《刀塔霸业》、《激战2》、《Splatoon 2》及《皇舆争霸》)和多个竞技性编程比赛都采用此种评分方法。[2]Glicko所使用的算法可在其网站上找到。
算法中,评分可靠性用于测量选手的评分,一评分可靠性(评分标准差)相当于一标准差。举个例子,一名评分为1500分的选手,其评分可靠性为50,表示有95%的可能性这名选手的真实实力约在1400至1600分(1500分的两个标准差)之间。选手的实力区间需增加并减去评分中的两个评分标准差来计算。在比赛结束后,选手的实力评分的波动根据评分标准差来计算:当选手的评分标准差较低(选手的评分已较为准确)或其对手的评分标准差较高时(对手的真实实力无法确定)时,选手的评分波动也较小。评分标准差将在比赛后减小,但将在一段时间不活跃后渐渐增大。
Glicko-2是Glicko评分系统的改进版本,引进了评分挥发度$\sigma$(Rating Volatility)的概念。澳大利亚国际象棋联盟采用稍加修改版的Glicko-2评分系统。
Elo系统的问题在于无法确定选手评分的可信度,而Glicko系统正是针对此进行改进。假设两名评分均为1700的选手A、B在进行一场对战后A获得胜利,在美国国际象棋联赛的Elo系统下,A选手评分将增长16,对应地B选手评分将下降16。但是加入A选手是已经很久没玩,但B选手每周都会玩,那么在上述情况下A选手的1700评分并不能十分可信地用于评定其实力,而B选手的1700评分则更为可信。
虽然很多情况下并不是这么极端,但我觉得把选手评分的可信度考虑进入是很有必要的。因此Glicko系统扩展了Elo,将不再是仅计算选手评分(可以视为选手实力的“最佳猜测”),还加入了“评分误差”(RD,ratings deviation),从统计术语的概念来说,RD用于衡量一个评分的不确定度(RD值越高,评分越不可信)。高RD值意味着选手并不频繁地进行对战,或者该选手仅进行了很少次数的对战,而低RD值说明选手会很经常地进行对抗比赛。
在Glicko 系统中,选手的评分仅根据对战的结果而改变,但其RD值改变同事取决于游戏结果和未进行游戏的时间长度。该系统的一个特征是游戏的结果经常会减少选手的RD值,而未进行对战的时间则经常会增长选手的RD值。造成这个现象的原因是因为选手玩的局数越多,关于选手能力的信息就学习到越多,评分也就越真实;而随着时间流失,我们对玩家实力就越不确定,反映在RD值上就是增长。
一个很有趣的发现是在Glicko系统中,双方评分的变化并不像Elo那样经常是相同的。例如A选手的评分增长了X,在Elo系统中对手B的评分会减少X,而在Glicko系统中并非如此。实际上,在Glicko中,对手B的评分减少取决于双方的RD值。
由于Glicko系统会同时用评分和RD值、以区间的形式评定选手实力,因此相较于仅使用评分更具有实际意义。此处应用95%置信区间,那么区间下限是选手评分减去2倍的RD值,区间上限是选手评分加上2倍的RD值。例如一个选手的评分是1850、RD值是50,那么他的实际实力区间为1750~1950。选手的RD值越小,该区间越窄,也就是说我们有95%的把握可以确定选手的实力在一个较小的区间值。
为了应用该算法,我们需要对发生在同一个“评分周期(rating period)”的所有游戏进行计算。一个评分周期可以长达数月,也可以短到一分钟。在前面的例子中,选手的评分和RD值在评分周期的一开始是已知的,对战的结果是可观测的,那么在评分周期结束时就可以根据计算更新选手的评分和RD值(同时该值可以作为下一评分周期的前置评分和RD)。当每个选手在评分周期中稳定地进行5~10局对战时,Glicko系统表现得最好。评分周期的时间长度由相关人员自行设定。
若选手没有评分,则其评分通常被设为1500,评分标准差为350。
测算标准差
新的评分标准差RD可使用旧的评分标准差$RD_{0}$计算:
$$RD=\min ({\sqrt {{RD_{0}}^{2}+c^{2}t}},350)$$
t为自上次比赛至现在的时间长度(评分期),350则是新选手的评分标准差。若选手在一个评分期间内进行了多场比赛,此算法会将进行的比赛作为一场看待。评分期根据选手进行比赛的频繁程度,可能长至七个月,短至几分钟。常数c根据选手在特定时间段内的技术不确定性计算而来,计算方法可能通过数据分析,或是估算选手的评分标准差将在什么时候达到未评分选手的评分标准差得来。若一名选手的评分标准差将在100个评分期间内达到350的不确定度,则评分标准差为50的玩家的常数c可通过解$350=\sqrt {50^{2}+100c^{2}}$的方式计算而来。或$c=\sqrt {(350^{2}-50^{2})/100}\approx 34.6$
测算新评分
在经过m场比赛后,选手的新评分可通过下列等式计算:
$$r=r_{0}+{\frac {q}{{\frac {1}{RD^{2}}}+{\frac {1}{d^{2}}}}}\sum _{i=1}^{m}{g(RD_{i})(s_{i}-E(s|r_{0},r_{i},RD_{i}))}$$
其中:
测算新评分标准差
原先用于计算评分标准差的函数应增大标准差值,进而反应模型中一定非观察时间内,玩家的技术不确定性的增长。随后,评分标准差将在几场游戏后更新:
$$RD’=\sqrt {({\frac {1}{RD^{2}}}+{\frac {1}{d^{2}}})^{-1}}$$
Glicko-2 系统中的每个玩家都有一个评分 r、一个评分偏差 RD 和一个评分波动率$\sigma$。波动性度量表明玩家评级的预期波动程度。当球员表现不稳定时(例如,当球员在稳定一段时间后取得了异常强劲的成绩)时,波动性衡量指标较高,而当球员表现稳定时,波动性衡量指标较低。与最初的 Glicko 系统一样,通常以间隔的形式总结球员的实力(而不仅仅是报告评级)。一种方法是报告 95% 的置信区间。区间中的最小值是玩家的评分减去两倍的RD,最高值是玩家的评分加上两倍的RD。因此,例如,如果某个玩家的评分为 1850,RD 为 50,则该区间将从 1750 到 1950。那么我们可以说我们有 95% 的把握认为该玩家的实际实力在 1750 到 1950 之间。当 a球员的 RD 较低,区间会很窄,因此我们有 95% 的信心认为球员的实力处于较小的数值区间。波动率度量没有出现在这个区间的计算中。
计算方法
为了应用评级算法,我们将“评级期”内的一组游戏视为同时发生。玩家在评级期开始时会有评级、RD 和波动率,将观察游戏结果,然后在评级期结束时计算更新的评级、RD 和波动率(然后将其用作预-后续评级期的期间信息)。 Glicko-2 系统在评级周期中的游戏数量中等到大时效果最佳,例如在评级周期中每个玩家平均至少玩 10-15 场游戏。评级期的时间长度由管理员自行决定。 Glicko-2 的评分量表与原始 Glicko 系统的评分量表不同。但是,很容易在两个尺度之间来回切换。以下步骤假设评级是在原始 Glicko 量表上,但公式会转换为 Glicko-2 量表,然后在最后转换回 Glicko。
步骤 1. 在评分期开始时确定每个玩家的评分和 RD。 系统常数$\tau$限制了波动率随时间的变化,需要在应用系统之前设置。 合理的选择介于 0.3 和 1.2 之间,但应测试系统以确定哪个值会导致最大的预测准确性。 较小的 $\tau$ 值可防止波动性度量发生大量变化,从而防止基于非常不可能的结果的评级发生巨大变化。如果预计 Glicko-2 的应用涉及极不可能的游戏结果集合,那么 $\tau$ 应该设置为一个小值,甚至小到,比如,$\tau$ = 0.2。
步骤 2. 对于每个玩家,将评分和 RD 转换为 Glicko-2 量表:
$$\mu = (r – 1500)/173.7178$$
$$\phi = RD/173.7178$$
$\sigma$的值,即波动率,不会改变。
我们现在想用 (Glicko-2) 评分 $\mu$、评分偏差$\phi$和波动率$\sigma$更新玩家的评分。他与 m 个等级为$\mu_1,…\mu_m$的对手对战。评分偏差$\phi _1,…,\phi _m$。 让$s_1,…,s_m$是对每个对手的得分(0 表示失败,0.5 表示平局,1 表示胜利)。 对手的波动率与计算无关。
步骤 3. 计算v。这是仅基于比赛结果的球队/球员评分的估计方差。
$$v=[\sum_{j=1}^{m} g(\phi_{j})^{2} \mathrm{E}(\mu, \mu_{j}, \phi_{j})\{1-\mathrm{E}(\mu, \mu_{j}, \phi_{j})\}]^{-1}$$
其中:
$$g(\phi) =\frac{1}{\sqrt{1+3 \phi^{2} / \pi^{2}}}$$
$$\mathrm{E}(\mu, \mu_{j}, \phi_{j}) =\frac{1}{1+\exp (-g(\phi_{j})(\mu-\mu_{j}))}$$
步骤 4. 通过将前期评分与仅基于游戏结果的表现评分进行比较,计算$\Delta$,即评分的估计改进。
$$\Delta=v \sum_{j=1}^{m} g(\phi_{j})\{s_{j}-\mathrm{E}(\mu, \mu_{j}, \phi_{j})\}$$
g()和 E()在上一个步骤已经定义过了。
步骤 5. 确定波动率的新值$\sigma ^{‘}$。 这个计算需要迭代。
1.让$a=\ln(\sigma^2)$,并定义
$$f(x)=\frac{e^{x}(\Delta^{2}-\phi^{2}-v-e^{x})}{2(\phi^{2}+v+e^{x})^{2}}-\frac{(x-a)}{\tau^{2}}$$
此外,定义收敛容差$\varepsilon $。 值 $\varepsilon = 0.000001$ 是一个足够小选择。
2.设置迭代算法的初始值。
设置$A=a=\ln(\sigma^2)$
如果$\Delta ^2 > \phi ^2 + v$,设置$B=\ln(\Delta ^2-\phi ^2-v)$。
如果$\Delta ^2 \leq \phi ^2 + v$,执行以下迭代:
设置$B= a-k\tau$,选择值 A 和 B 来减小ln(\sigma^2)。
3.让$f_A = f(A)$和$f_B = f(B)$
4.当$|B-A|>\varepsilon$,执行以下步骤。
5.一旦$|B-A| \leq \varepsilon$,设置$\sigma ^{‘} \leftarrow e^{A/2}$
步骤 6. 将评级偏差更新为新的预评级期值,\phi ^*。
$$\phi ^* = \sqrt{\phi ^2+\sigma ‘^{2}}$$
步骤 7. 将评级和 RD 更新为新值$\mu ‘$和$\phi ‘$:
$$\phi^{\prime} =1 / \sqrt{\frac{1}{\phi^{* 2}}+\frac{1}{v}} $$
$$\mu^{\prime} =\mu+\phi^{\prime 2} \sum_{j=1}^{m} g(\phi_{j})\{s_{j}-\mathrm{E}(\mu, \mu_{j}, \phi_{j})\}$$
步骤 8. 将评分和 RD 转换回原始比例:
$$r’=173.7178u’+1500$$
$$RD’=173.7178\phi ‘$$
请注意,如果玩家在评分期间未参加比赛,则仅适用第 6 步。 在这种情况下,玩家的评级和波动率参数保持不变,但 RD 根据:
$$\phi^{\prime}=\phi^{*}=\sqrt{\phi^{2}+\sigma^{2}}$$
在电子竞技游戏中,特别是当有多名选手参加比赛的时候需要平衡队伍间的水平,让游戏比赛更加有意思。这样的一个参赛选手能力平衡系统通常包含以下三个模块:
事实上目前已经有的游戏评分系统是Elo评分,但是Elo评分仅只是两名选手参加的游戏。TrueSkill系统是基于贝叶斯推断的评分系统,由微软研究院开发以代替传统Elo评分,并成功应用于Xbox Live自动匹配系统。TrueSkill评分系统是Glicko评分系统的衍伸,主要用于多人游戏中。TrueSkill评分系统考虑到了你水平的不确定性,综合考虑了玩家的胜率和可能的水平涨落。当玩家进行了更多的游戏后,即使你的胜率不变,系统也会因为对你的水平更加了解而改变对你的评分。
相较Elo评价系统,TrueSkill的优势在于:
怎样进行能力计算
TrueSkill排名系统是针对玩家能力进行设计的,以克服现有排名系统的局限性,确保比赛双方的公平性,可以在联赛中作为排名系统使用。它为玩家排名使用的为贝叶斯定理。 系统的特点是假设每一个玩家的能力不是固定的,其能力水平的表现为一个钟型曲线(正态分布或高斯分布)。
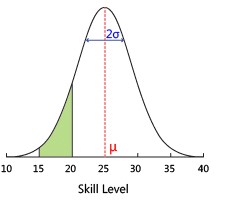
绿色区域15~20代表了Ranking System对的评分。可以看出系统的评分是比较保守的。$\sigma$越小则越靠近$\mu$,相应的玩家的能力水平就较高。总的来说玩家的水平受“平均得分”和“玩家稳定性”综合影响。
由于TrueSkill排名系统使用高斯信仰分布来描述一个玩家的能力,也就意味着玩家的能力始终落在4倍的$\sigma$内(概率为99.993666%)。从微软追踪的65万玩家数据显示,有99.99%都落在了3倍的$\sigma$内。 有趣的是,TrueSkill排名系统可以使用1作为最初的不确定性做所有的计算,将相乘$\mu$和$\sigma$可以缩放到任何其他的范围。假设所有的计算都以初始值$\mu$=3和$\sigma$=1,如果一个玩家有50级,几乎所有的$\mu$的发生是在±3倍的初始$\sigma$,$\sigma$可得50/6 = 8.3。 两个玩家最大的区别在于$\mu$值得大小。假设$\sigma$相当,那么$\mu$高的玩家赢得机会就越大,这一原则也适用在TrueSkill排名系统。但并不表示$\mu$高的就一定会赢。在单个的配对比赛中,玩家的个人表现与玩家的能力是相当的,游戏结果也是有个人表现决定的。因此,可以认为能力的一个玩家在TrueSkill的排名是在大量游戏中的平均表现。个人表现的变化原则是能力表现的一个参数。
怎样更新能力值
TrueSkill排名系统只会根据比赛结果更新$\mu$和$\sigma$,它假设的情况为一个玩家的表现围绕着他的能力水品进行变化,如果一个玩家玩一个基于点数的游戏,他战胜了所有的其他10个对手和他和战胜了另外一场比赛只有一个对手的积分是一样的,但是这样两场比赛确实反映了不同选手的能力情况。通常会使$\sigma$下降。在计算一场新的比赛结果之前,TrueSkill排名系统会计算比赛的排名与选手在比赛前的排名的变化情况。排名的变化最终影响了玩家技能的不确定性$\sigma$。这个参数可以被TrueSkill用来记录玩家的技能的变化。并且$\sigma$永远不可能为0。
下面这张表格来自微软研究院,此表格给出了8个新手在参与一个8人游戏后$\mu$和$\sigma$的变化。
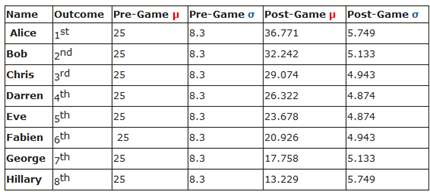
这里有个很有意思的现象:注意第四名Darren和第五名Eve,他们的$\sigma$是最小的,换句话说系统认为他们能力的可能起伏是最小的。这是因为通过这场游戏我们对他们了解得最多:他们赢了3/4个人,也输给了4/3个人。而对于第一名Alice,我们只知道她赢了7个人。 如果想知道更详细的定量分析可以先考虑最简单的两人游戏情况。
$$\begin{aligned}&\mu_{winner} \longleftarrow \mu_{winner}+\frac{\sigma_{winner}^{2}}{c} * v(\frac{\mu_{winner}-\mu_{loser }}{c}, \frac{\varepsilon}{c}) \\&\mu_{loser} \longleftarrow \mu_ {loser}-\frac{\sigma_{loser}^{2}}{c} * v(\frac{\mu_{winner}-\mu_{loser}}{c}, \frac{\varepsilon}{c}) \\&\sigma_{winner}^{2} \longleftarrow \sigma_{winner}^{2} *[1-\frac{\sigma_{winner}^{2}}{c} * w(\frac{\mu_{vinner}-\mu_{loser}}{c}, \frac{\varepsilon}{c}). \\&\sigma_{loser}^{2}<\sigma_{loser}^{2} * [1-\frac{\sigma_{loser}^{2}}{c} * w(\frac{\mu_{winner}-\mu_{loser}}{c}, \frac{\varepsilon}{c}). \\&c^{2}=2 \beta^{2}+\sigma_{winner}^{2}+\sigma_{loser}^{2}\end{aligned}$$
在上述的方程式中,唯一未知的就是选手的表现。另外还有就是游戏的模式。系数$\beta ^2$代表的是所有玩家的平均方差。v(.,.) 和w(.,.)是两个函数,比较复杂。$\varepsilon $是个与游戏模式有关的参数。 简而言之,你赢了$\mu$就增加,输了$\mu$减小;但不论输赢,$\sigma$都是在减小,所以有可能出现输了涨分的情况。
怎样进行选手匹配
势均力敌的对手能带来最精彩的比赛,所以当自动匹配对手时,系统会尽可能的为你安排可能与水平最为接近的玩家。TrueSkill评分系统采用了一个值域为(0,1)的函数来描述两个人是否势均力敌:结果越接近0代表差距越大,越接近1代表水平越接近。 假设有两个玩家A和B,他们的参数为$(\mu _{A},\sigma _{A})$和$(\mu _{B},\sigma _{B})$,则函数对这两个玩家的返回值为
$$e^{-\frac{(\mu_{A}-\mu_{B})^{2}}{2 c^{2}}} \sqrt{\frac{2 \beta^{2}}{c^{2}}}$$
c的值由如下公式给出
$$c^{2}=2 \beta^{2}+\mu_{A}^{2}+\mu_{B}^{2}$$
如果两人有较大几率被匹配在一起,光是平均值接近还不行(e指数上那一项),还得方差也比较接近才行(d)。
怎样创建能力排行榜
TrueSkill假设玩家的水平可以用一个正态分布来表示,而正态分布可以用两个参数:平均值和方差来完全描述。设Rank值为R,代表玩家水平的正态分布的两个参数平均值和方差分别为$\mu$和$\sigma$,则系统对玩家的评分即Rank值为 R=$\mu$-k*$\sigma$。k值越大则系统的评分越保守。在Xbox Live上,系统为每个玩家赋予的初值是$\mu = 25$以及 $\sigma = 25/3$,k=3。所以玩家的起始Rank值为R=25-3*25/3=0。
参考链接: