导言
公司的一个报表业务,数据量比较大,用户使用频繁。为了更好的用户体验,我们之前尝试过多种技术:MongoDB、ElasticSearch、Greenplum 等,但是一直没办法做到大部分查询秒级响应。
前段时间探索了很多大数据产品,无意中发现 ClickHouse,很快就被其极致的性能所吸引。在一番实验和研究后,我们决定用 ClickHouse 解决这个历史债务。花了一个月的时间,用 ClickHouse 重写了之前的业务逻辑,经过详细的验证,功能和之前保持一摸一样。性能是一个很好的衡量指标,于是这两天我做了这个性能对比测试。
结论
- 相同业务场景下,ClickHouse 只用了 Greenplum 一半的机器资源,但是比 Greenplum 快 10倍+
- ClickHouse 很少会把机器 CPU 全部用满;Greenplum 基本上会把机器 CPU 全占满
- ClickHouse 和 Greenplum 内存使用量都很少,只用到了20多GB
- 30并发之后,Greenplum 开始偶尔无法响应,并抛出异常;ClickHouse 到100并发还完好,只是会稍微慢一点
测试准备
1. 数据集
- 数据总量: 380 GB
- 1个事实表: 11 亿数据(26列)
- 2个纬度表:
- 纬度表B:8000 数据(45列)
- 纬度表C:1000 数据(52列)
- 为了充分发挥数据库的特性,数据模型在不同的数据库上会有不同的设计,业务逻辑不变
- ClickHouse 擅长单表查询,于是我会在原始表的基础上,创建一个新表(宽表)基于 MergeTree引擎,通过 materialized view 实时同步数据到新表
- Greenplum 用分区策略加速查询
2. 机器配置
- Greenplum
- 主节点:16C、64G、2.5TB HDD
- 副节点:16C、64G、1.5GB HDD
- ClickHouse
3. 查询条件
- Q1:动态时间区间 < 30 天;动态店铺ID;动态Limit Offset;
- Q2:动态时间区间 < 30 天;动态店铺ID;更多动态Where条件;动态Limit Offset;
- Q3:动态时间区间 > 30 天、< 180天;动态店铺ID;动态Limit Offset;
- Q4:动态时间区间 > 30 天、< 180天;动态店铺ID;更多动态Where条件;动态Limit Offset;
- Q5:动态时间区间 < 30 天;标签汇总;动态店铺ID;动态Limit Offset;
- Q6:动态时间区间 < 30 天;标签汇总;动态店铺ID;更多动态Where条件;动态Limit Offset;
- Q7:动态时间区间 > 30 天、< 180天;标签汇总;动态店铺ID;动态Limit Offset;
- Q8:动态时间区间 > 30 天、< 180天;标签汇总;动态店铺ID;更多动态Where条件;动态Limit Offset;
4. 压测步骤
- 使用 Golang 语言开发程序,生成查询SQL、请求数据库、提供统一的 API 接口
- 使用 Jmeter 调用Golang 提供的 Rest API 接口
- 压测前,使用 Jmeter 单线程模式,循环调用 10次 x 4组查询API , 预热系统
- 压测中,使用 Jmeter 1并发、10并发、30并发、50并发、100并发模式测试,每种并发,循环 3 次
- 压测后,收集 监控到的请求响应数据
5. 结果可视化
- 使用 Python + plotly + pandas 生成图表
压测结果
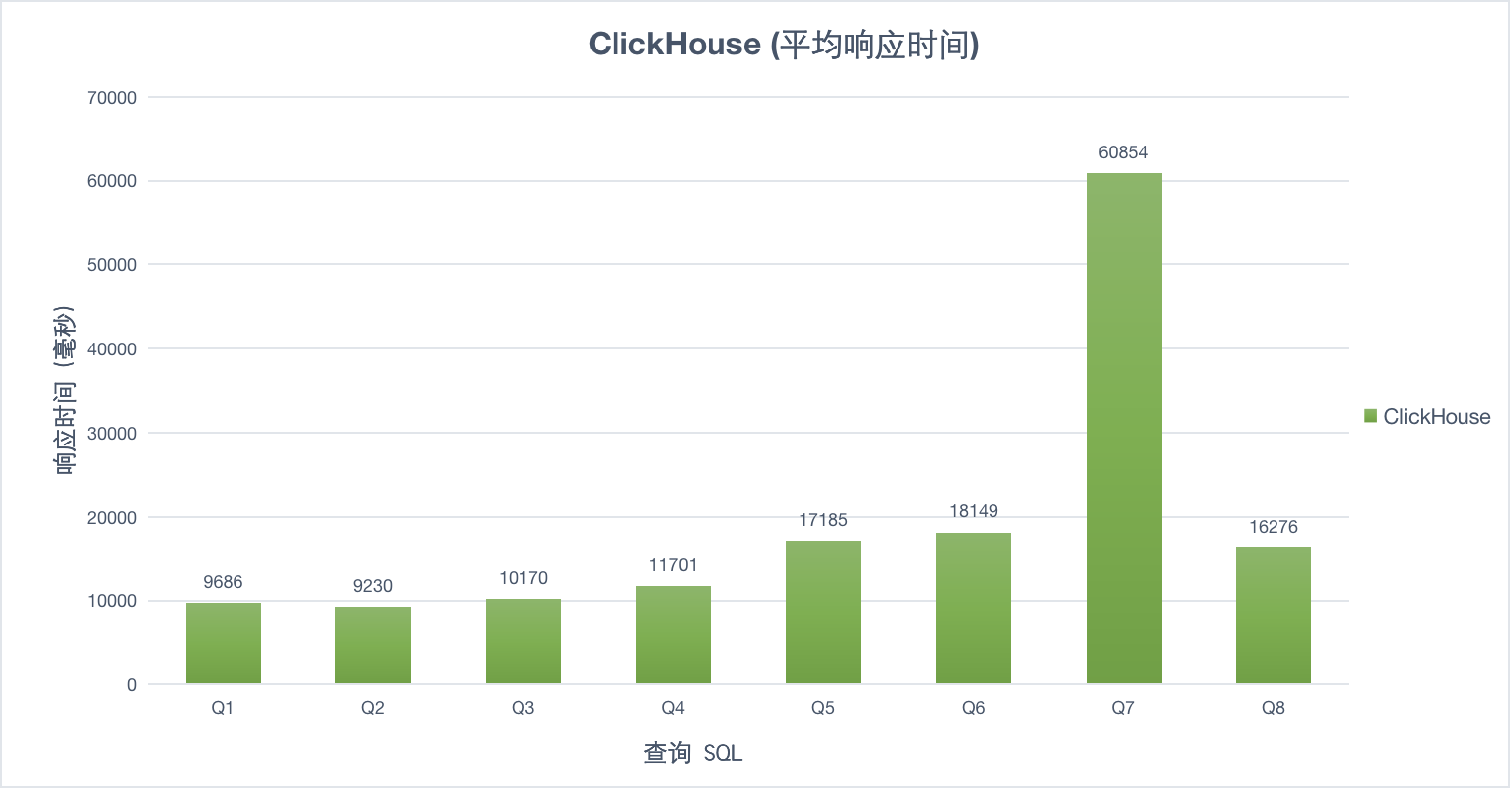
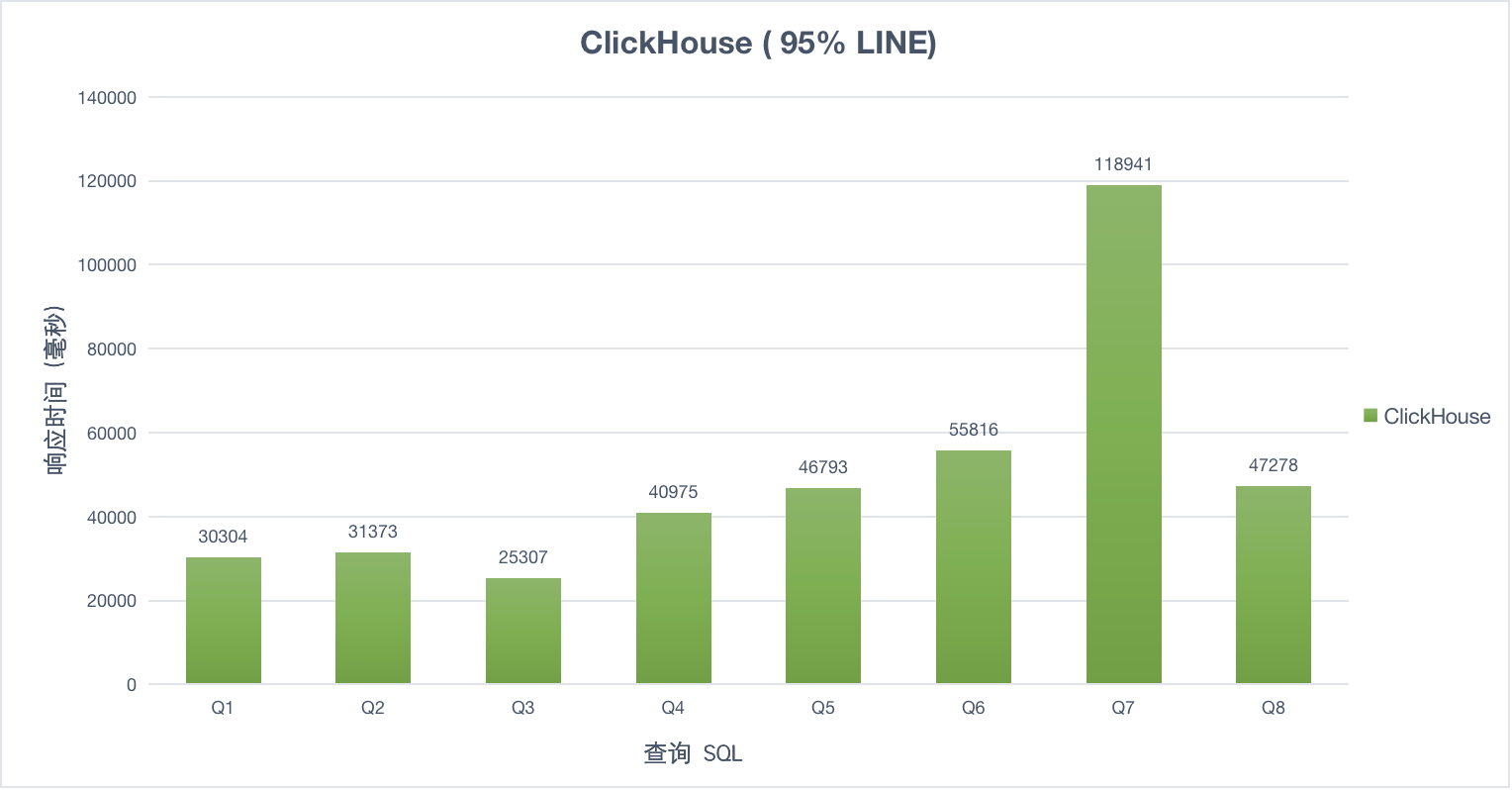
1并发
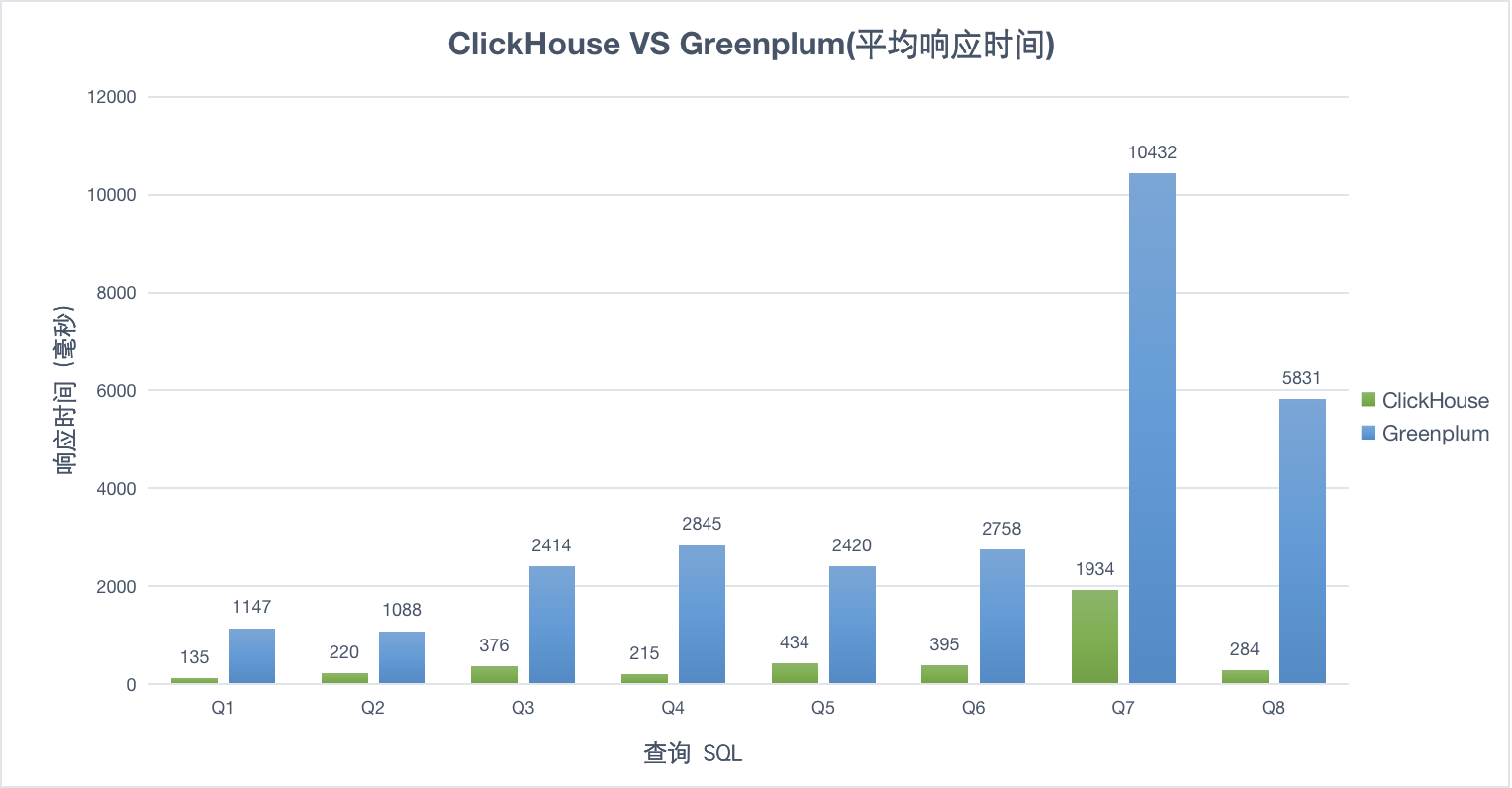
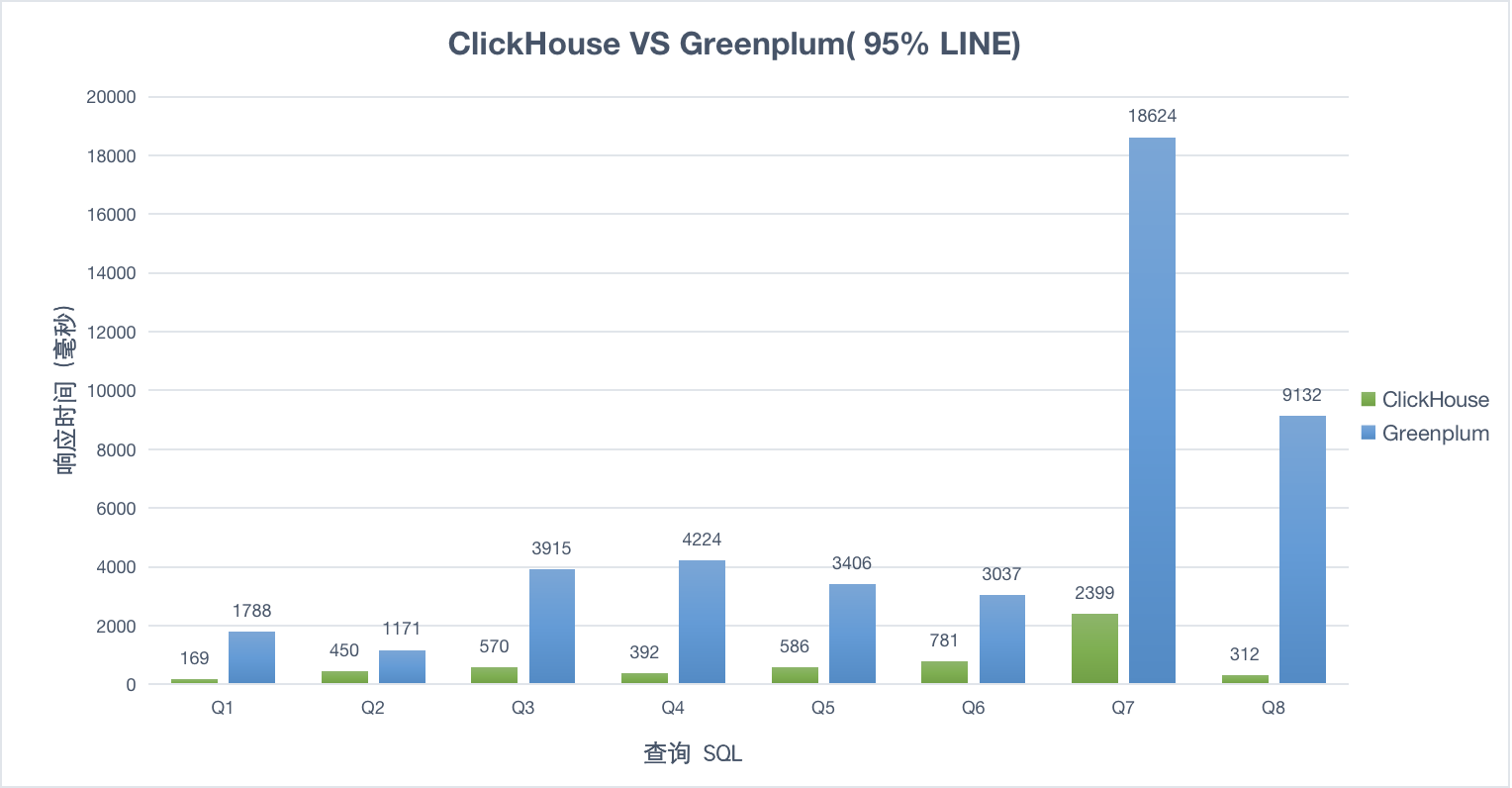
10并发
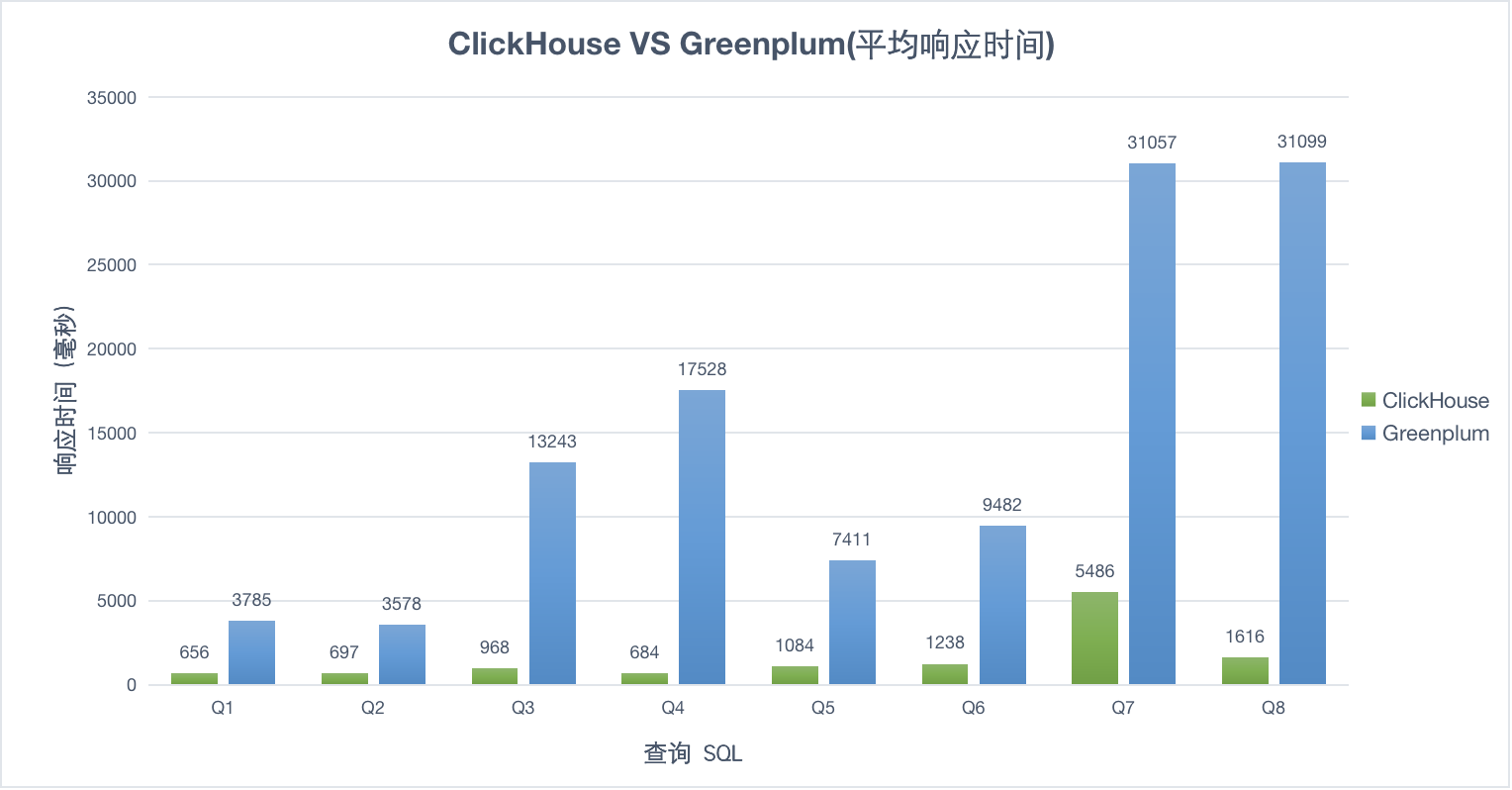
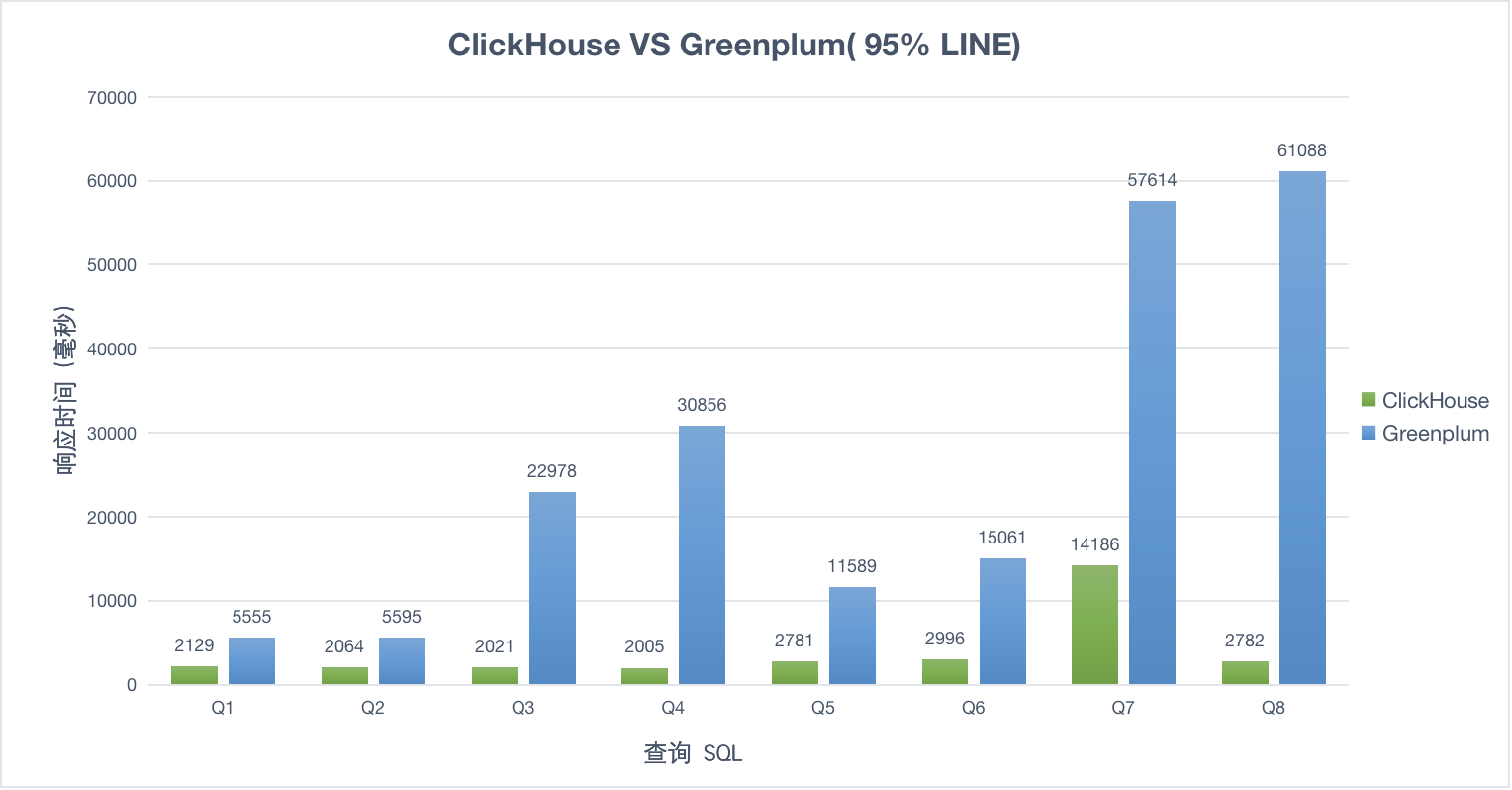
30并发
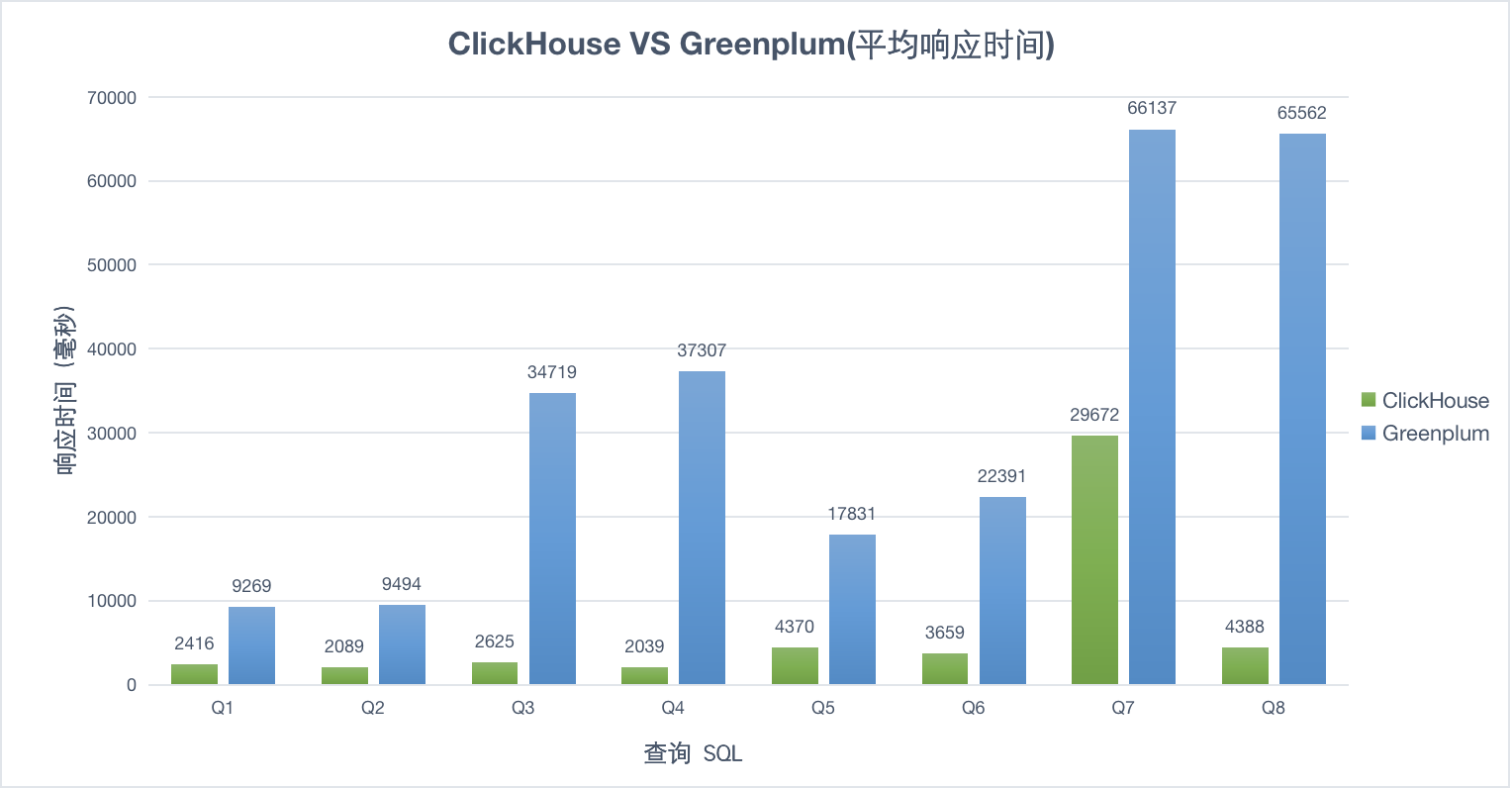
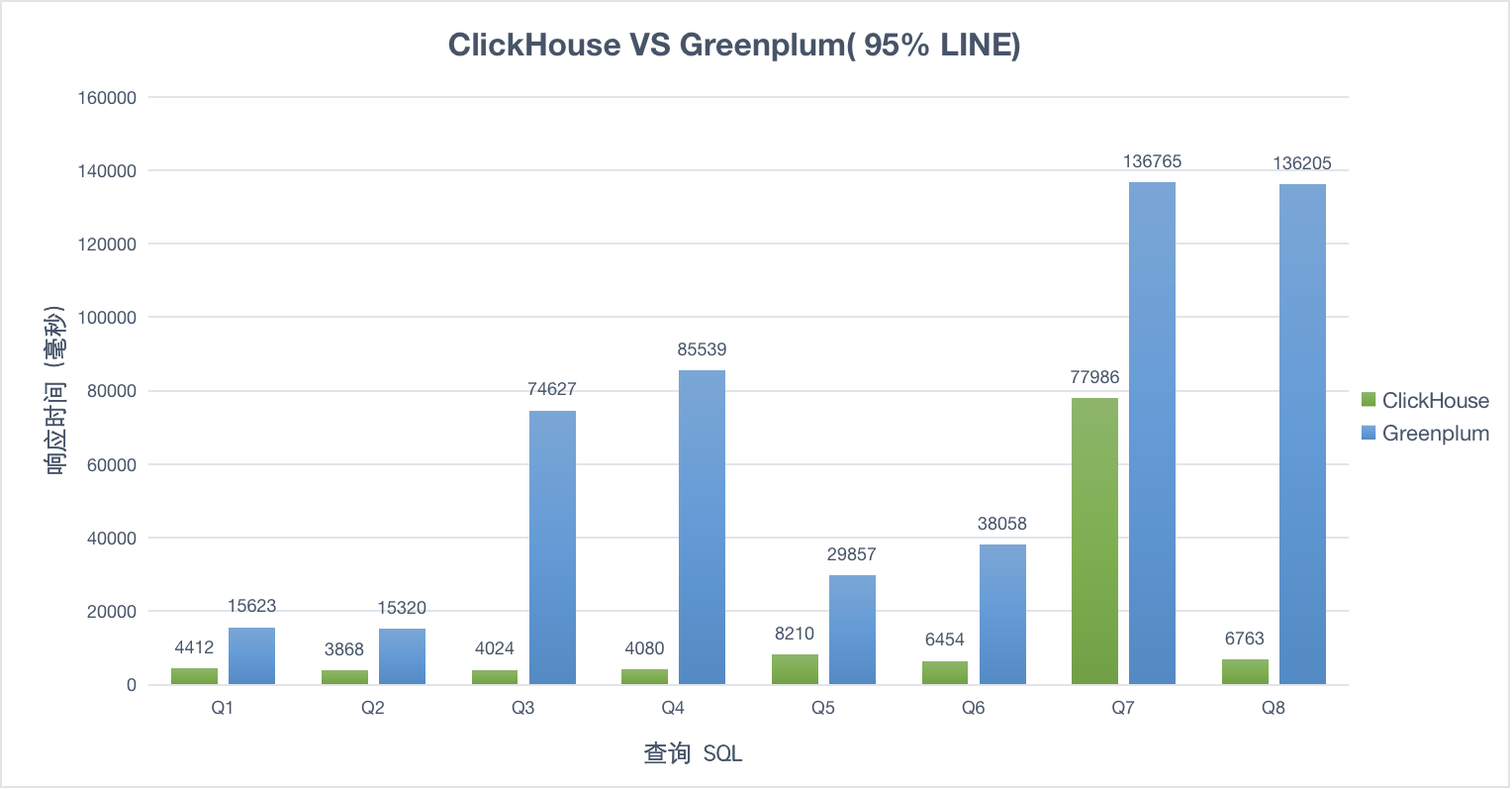
50并发
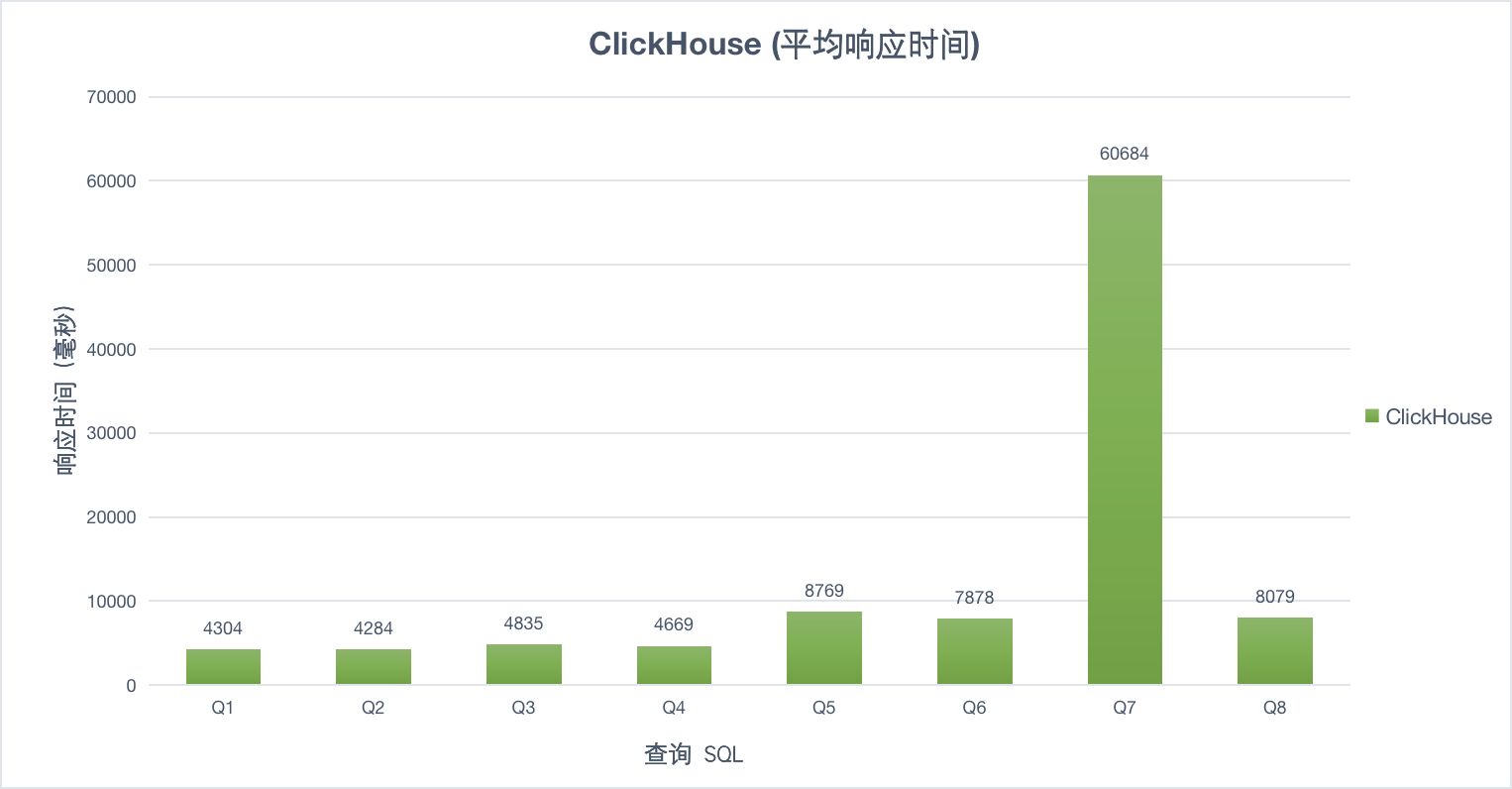
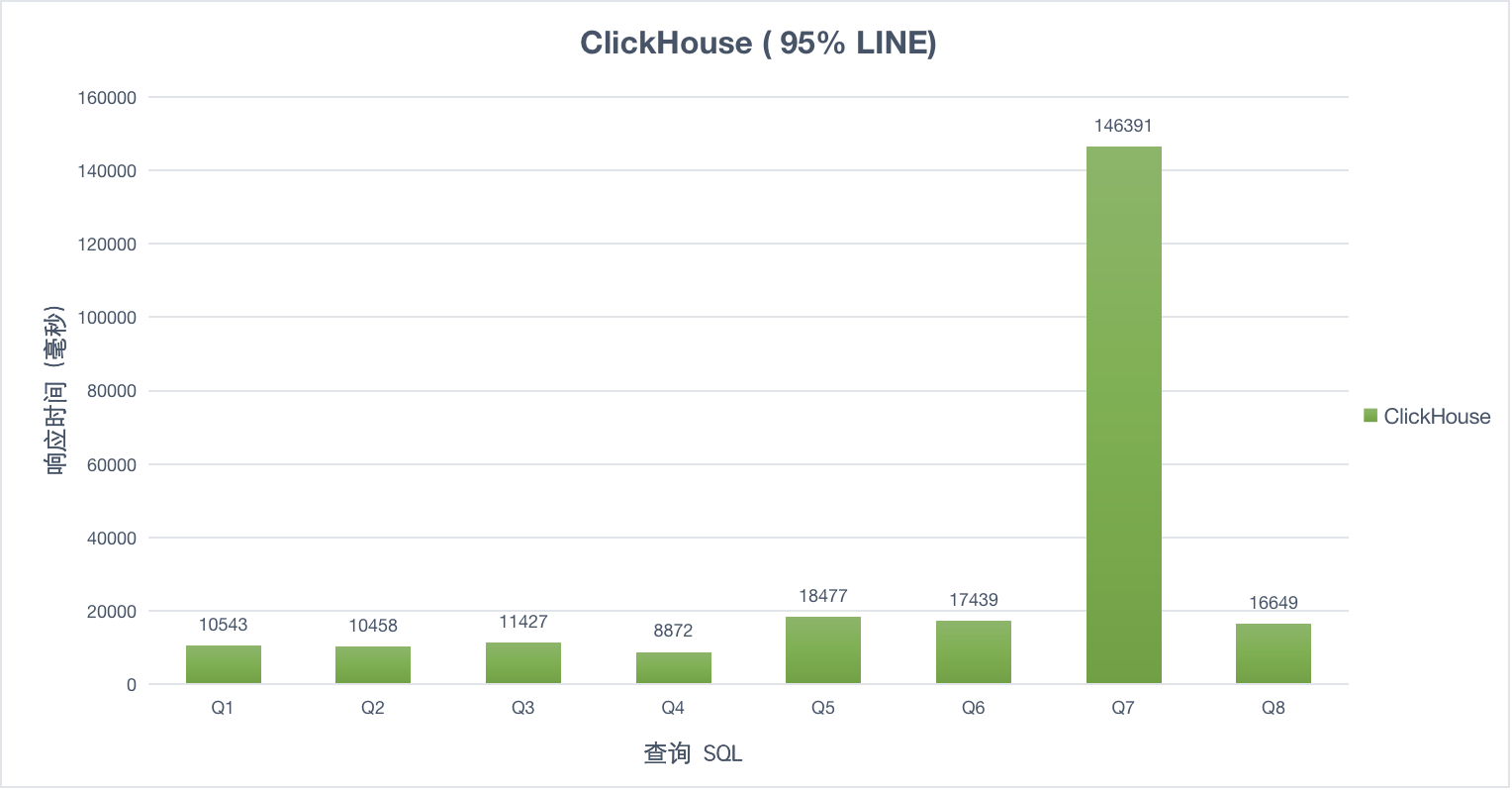
100并发