[原]Jaeger的客户端采样配置(Java版)
- - 程序员欣宸的博客这里分类和汇总了欣宸的全部原创(含配套源码): https://github.com/zq2599/blog_demos. 采样很好理解:使用Jaeger时,未必需要将所有请求都上报到Jaeger,有时候只要抽取其中一部分观察即可,这就是按照一定策略进行采样;. Jaeger采样配置分为客户端和服务端两种配置,默认用的是服务端配置.
这里分类和汇总了欣宸的全部原创(含配套源码): https://github.com/zq2599/blog_demos

#!/bin/bash
echo "停止docker-compose"
cd jaeger-service-provider && docker-compose down && cd ..
echo "编译构建"
mvn clean package -U -DskipTests
echo “创建provider镜像”
cd jaeger-service-provider && docker build -t bolingcavalry/jaeger-service-provider:0.0.1 . && cd ..
echo “创建consumer镜像”
cd jaeger-service-consumer && docker build -t bolingcavalry/jaeger-service-consumer:0.0.1 . && cd ..
echo "清理无效资源"
docker system prune --volumes -f
echo "启动docker-compose"
cd jaeger-service-provider && docker-compose up -d && cd ..
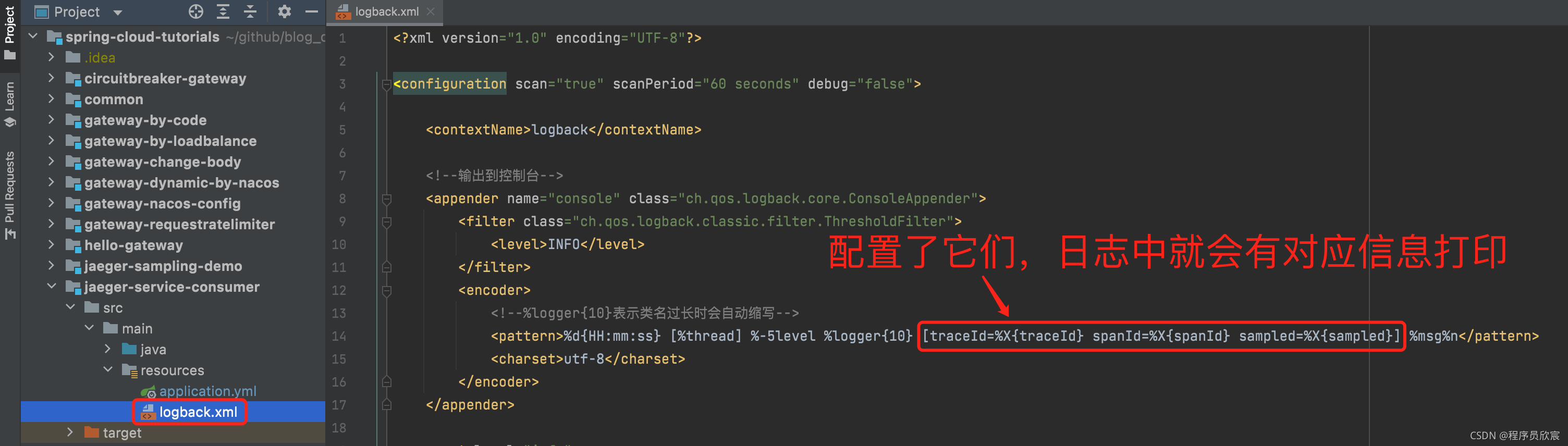
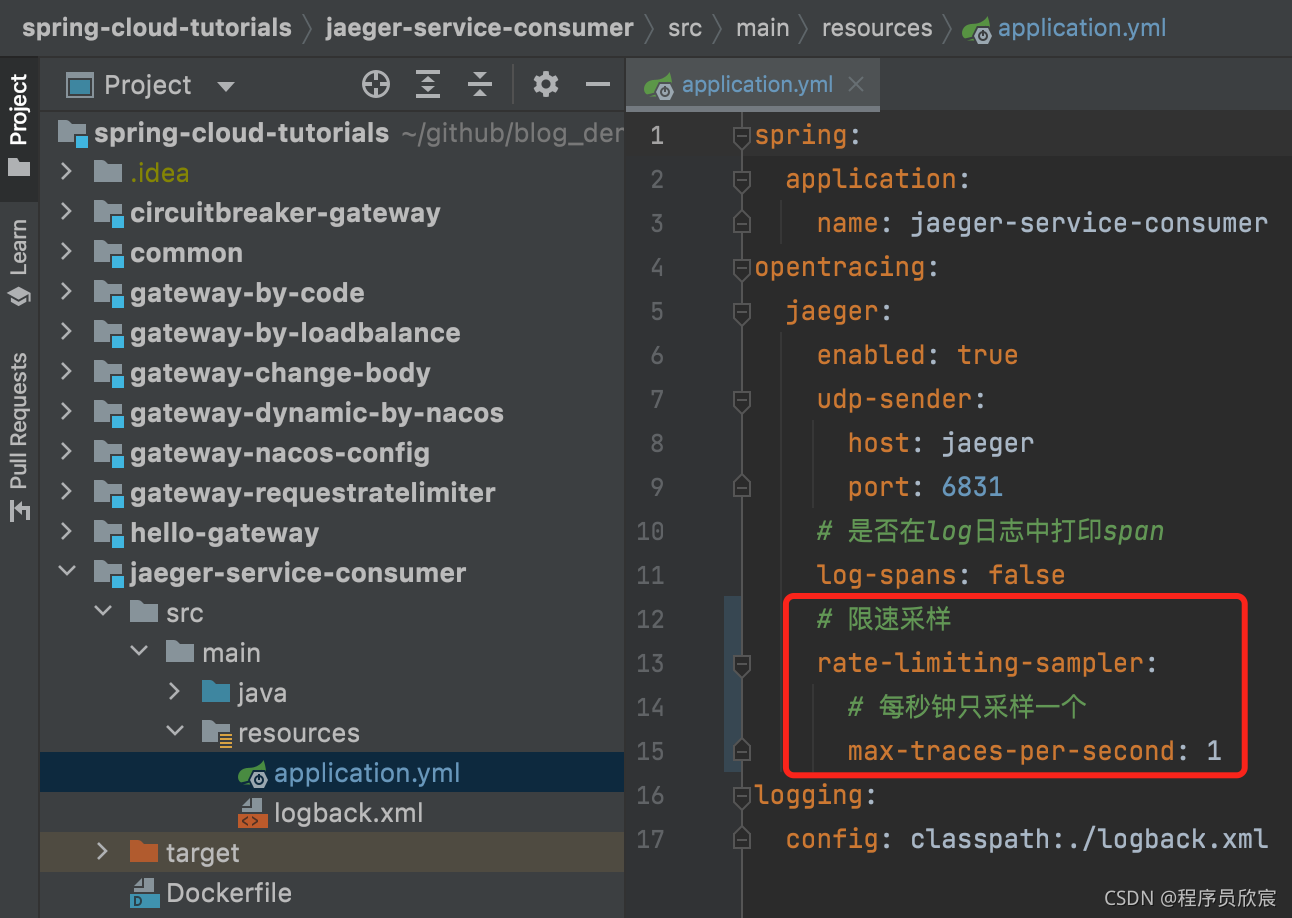
固定采样的逻辑很简单:要么全部上报,要么一个也不报
固定采样的配置方式如下图红框所示:
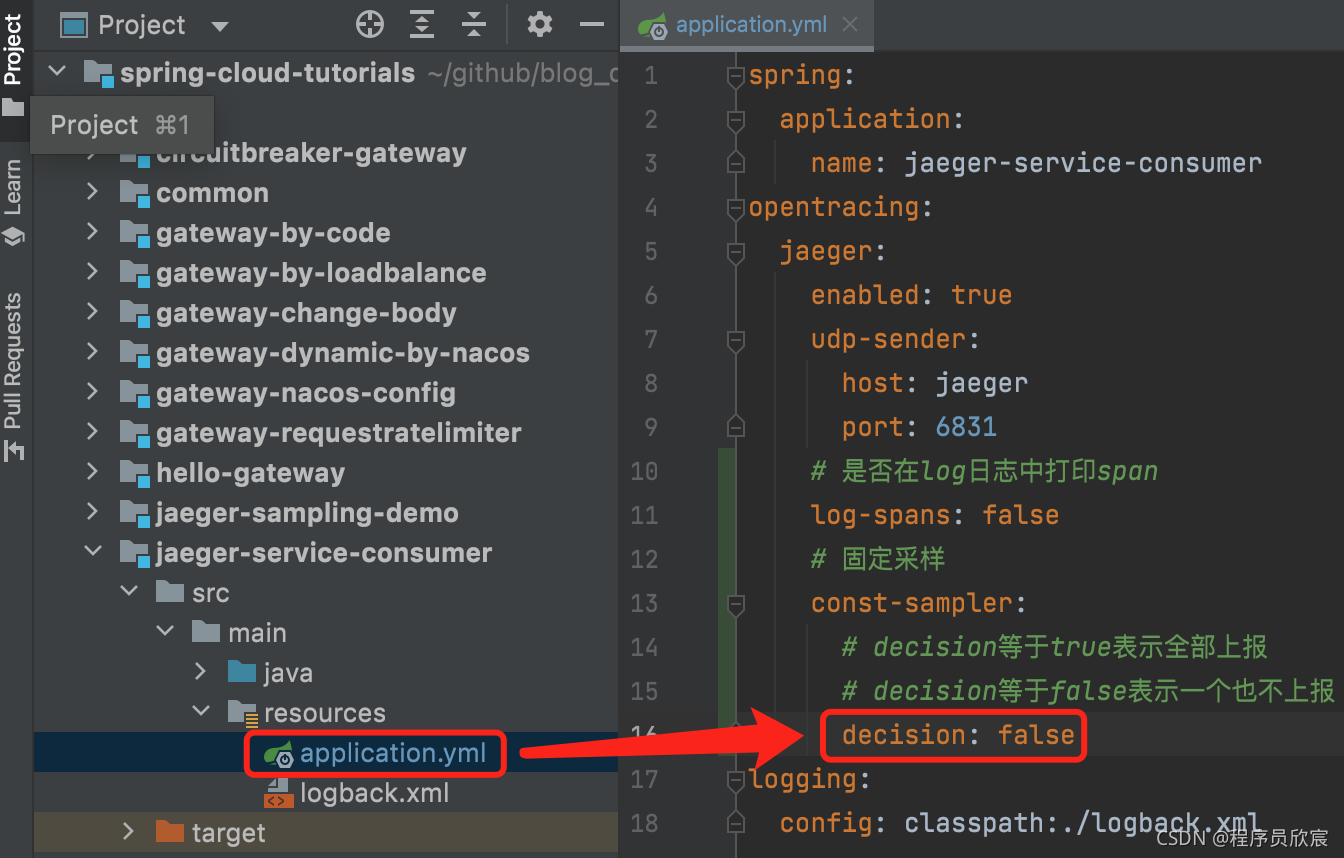
要注意的是:根据前置判定(consistent upfront 或者head-based)原则,只要将上述配置写入jaeger-service-consumer项目的配置文件即可,至于jaeger-service-provider维持原状不做任何改动
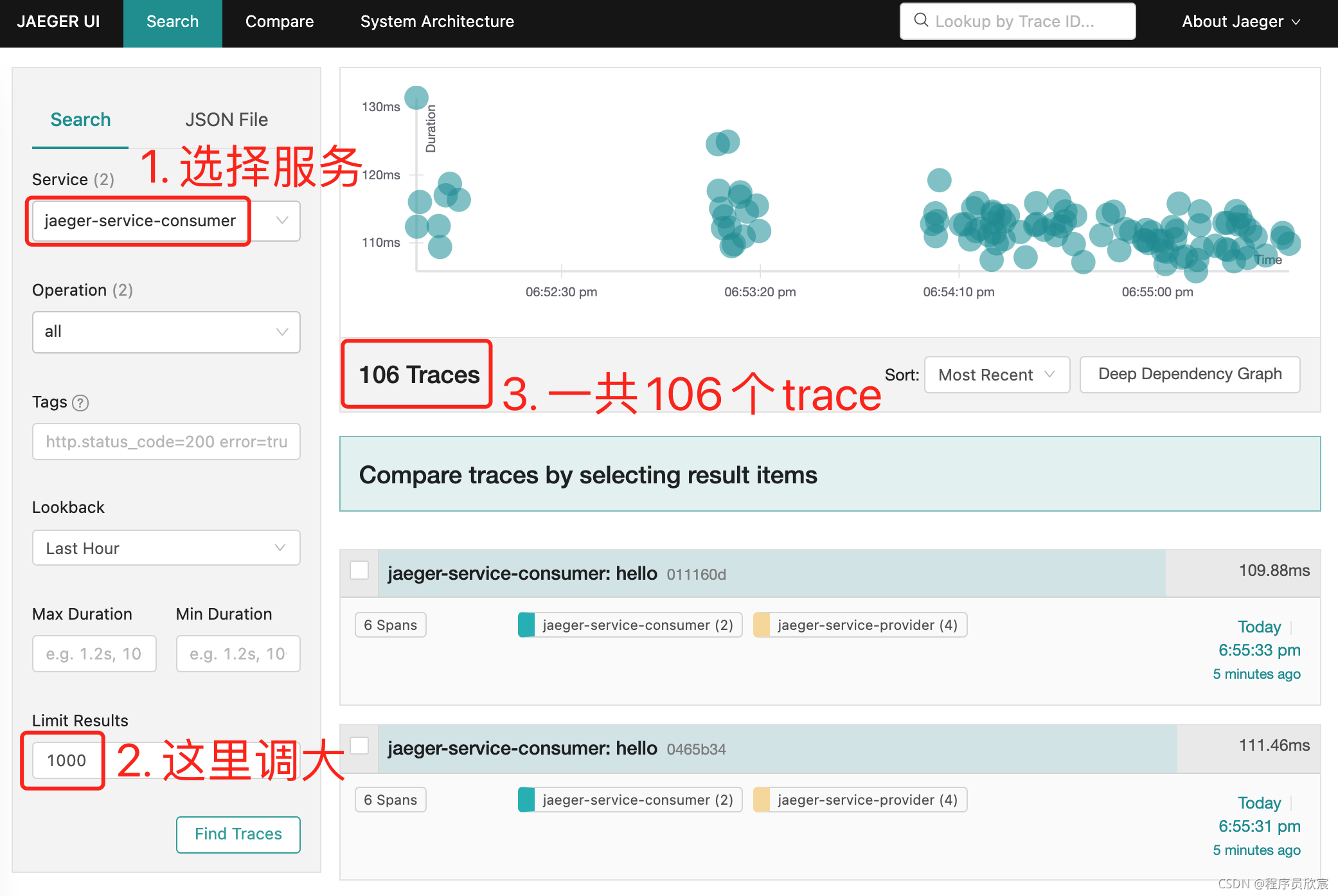
执行前面写的full.sh脚本,编译构建部署
浏览器访问http://localhost:18080/hello,产生一些web请求,多访问几次
看jaeger-service-consumer容器的日志,如下图,红框中的sampled=false表示未采样,三此请求的日志都是如此:

再看jaeger-service-provider容器的日志,如下图红框,也全部都没有采样,这证明Jaeger的前置判定原则(consistent upfront 或者head-based)是准确的,jaeger-service-consumer是一次trace的源头,被它关闭了采样的trace,在后续的服务中也会自动关闭采样:

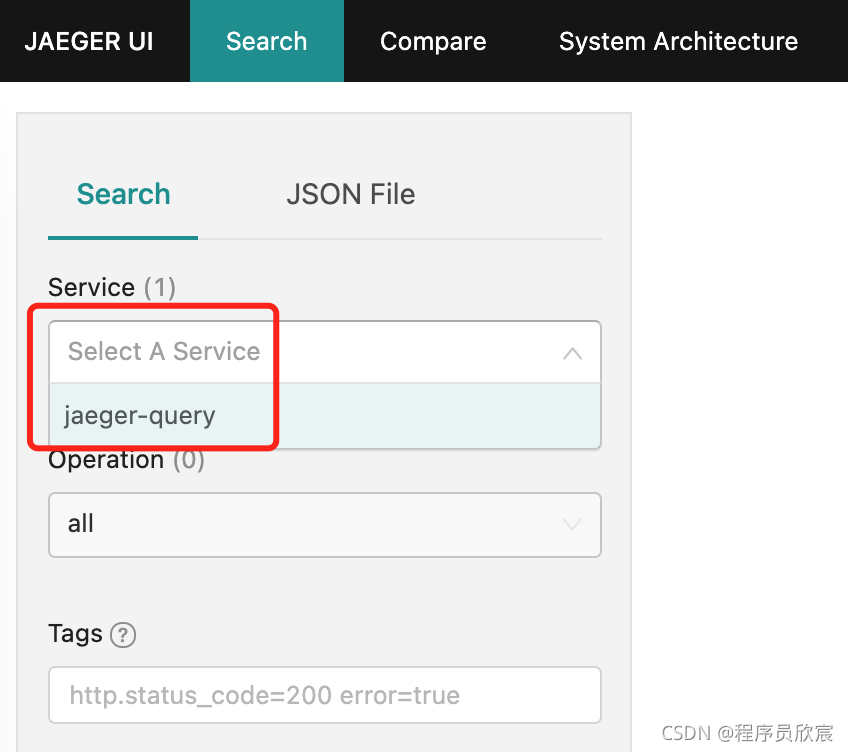
去Jaeger的web页面看看,空空如也,连服务列表中都没有jaeger-service-consumer和jaeger-service-provider:
试过了全部不采样,再来试试全部采样的配置,如下图红框:
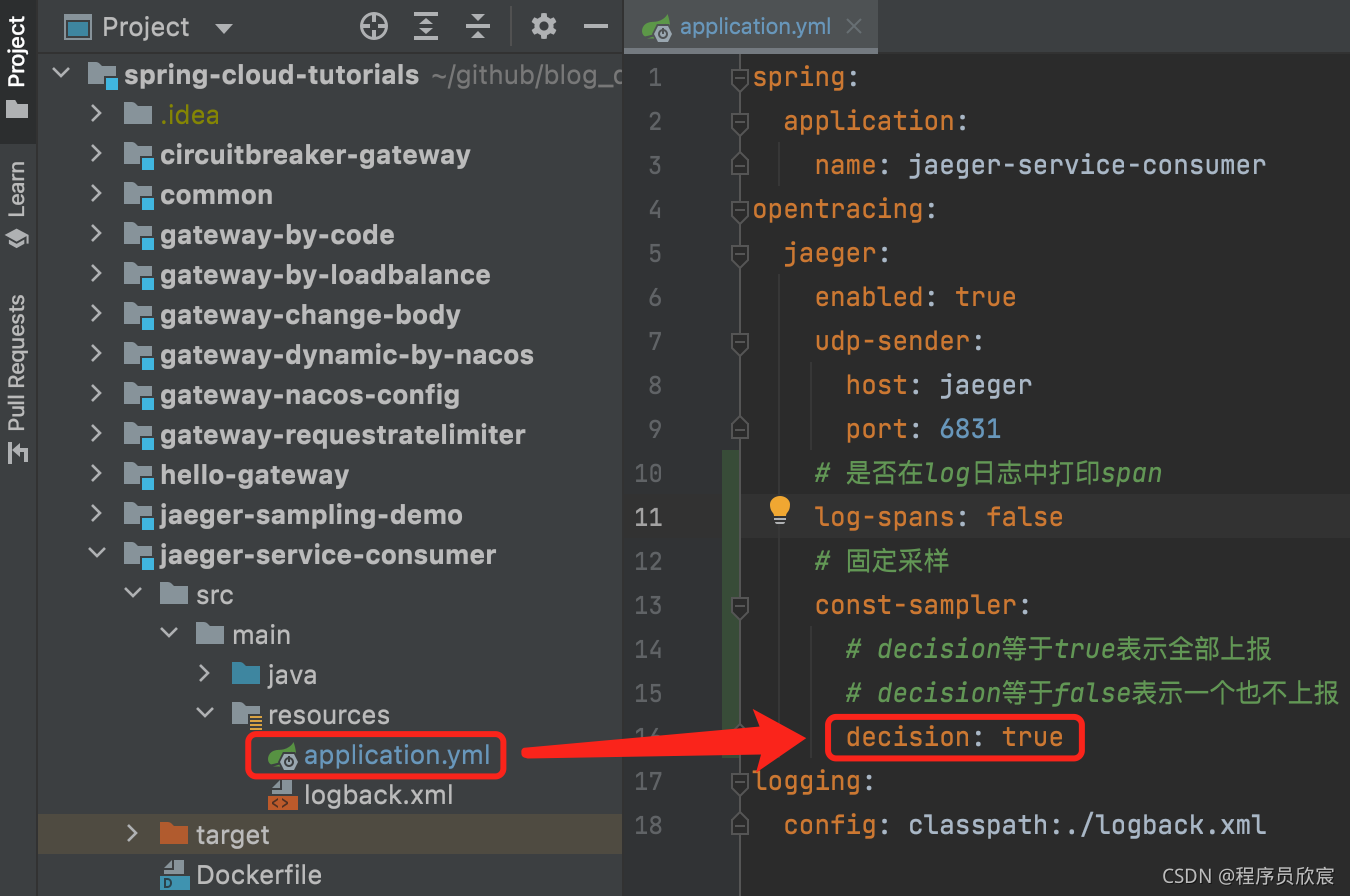
重新部署,再产生几次请求,去看jaeger-service-consumer容器的日志,如下图红框,全部都被采样了:

去看jaeger-service-provider容器的日志,也是如此,所有trace都被采样:

打开Jaeger的web页面,可见jaeger-service-consumer的三次请求对应的trace全部上报:
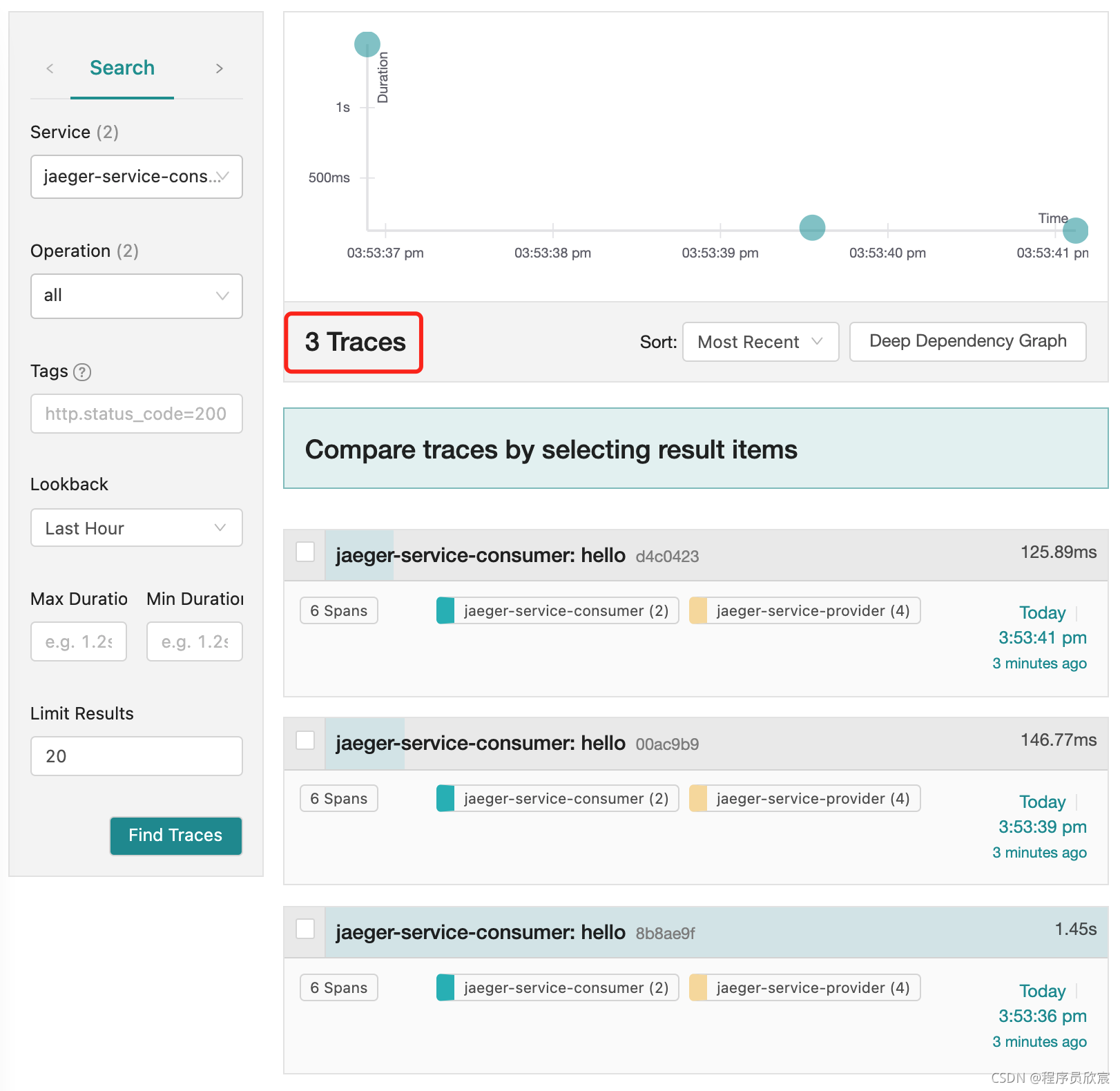
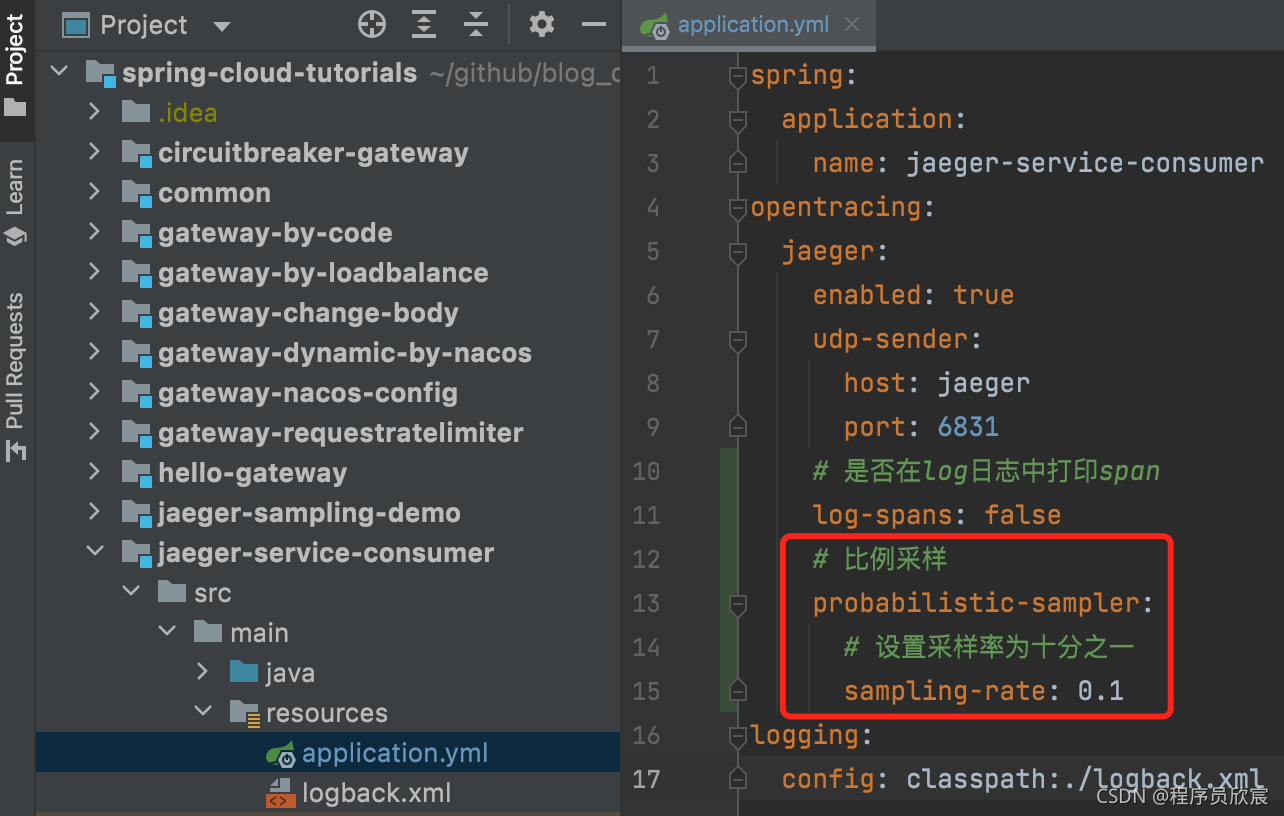
至此,最简单的固定采样已完成,来看看更实用的比例采样
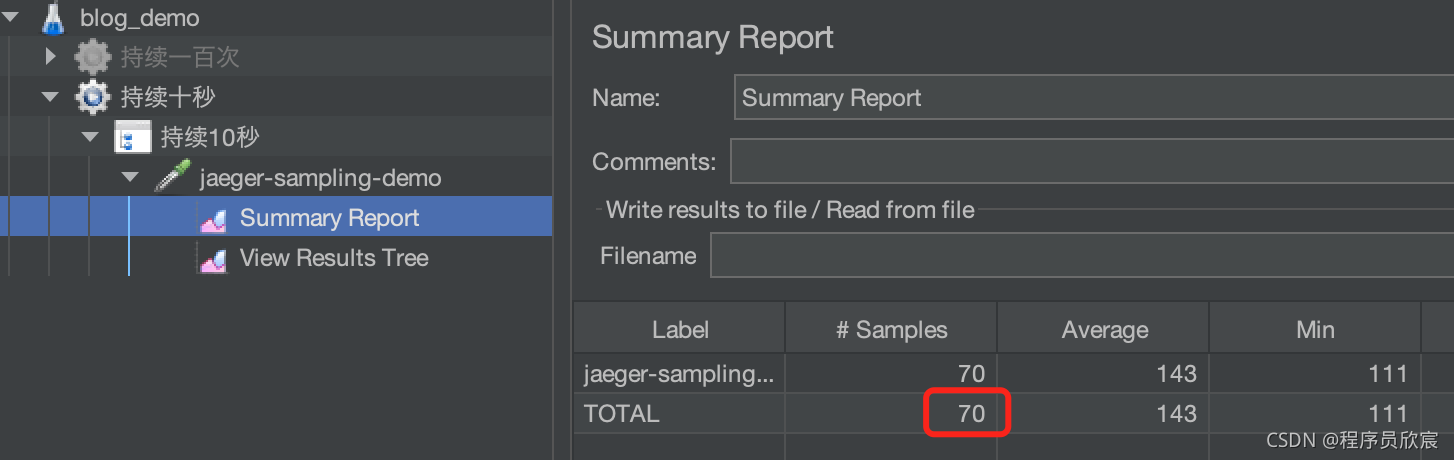
docker logs jaeger-service-consumer| grep 'sampled=true'|wc -l






docker exec jaeger cat /etc/jaeger/sampling_strategies.json
{
"default_strategy": {
"type": "probabilistic",
"param": 1
}
}