

工业环境中对机器学习的行业视角
- - 机器之心Google Applied Science 是 Google Research 的一个部门,将计算方法,尤其是机器学习,应用于广泛的科学问题. 不久前帕特里克·莱利(Patrick Riley)还是该部门软件工程师之一,现在是 Relay Therapeutics 的人工智能负责人,他与《Nature Reviews Materials》谈论了他在工业环境中从事机器学习项目的经验.
编辑/凯霞
Google Applied Science 是 Google Research 的一个部门,将计算方法,尤其是机器学习,应用于广泛的科学问题。不久前帕特里克·莱利(Patrick Riley)还是该部门软件工程师之一,现在是 Relay Therapeutics 的人工智能负责人,他与《Nature Reviews Materials》谈论了他在工业环境中从事机器学习项目的经验。
你能告诉我们一些关于你所做的事情以及谷歌机器学习研究的事情吗?
我在 Google Applied Science (
https://research.google/teams/applied-science/) 的小组致力于计算方法的各种应用,尤其是机器学习,以解决自然科学问题。我们是更广泛的 Google Research 组织的一部分,该组织在许多计算领域开展工作。我们定期在学术期刊上发表文章,发布开源项目,直接影响 Google 产品。这实际上意味着我们与学术界和工业界以及跨领域的许多不同科学家合作,共同尝试新的想法和方向。
Robert Gonzalez, Google。
你能举一些谷歌 Applied Science 所从事的项目类型的例子吗?
我们的工作范围非常广泛。例如,我们与 TAE Technologies 公司合作,优化了他们核聚变实验的参数 (
https://www.nature.com/articles/s41598-017-06645-7)。他们拥有独特的设备、大量数据,并能够进行多次迭代实验。通过与他们的科学家的密切互动,我们将机器推向了新的性能体系。
C-2U 的中央约束室,一个等离子体约束实验。
另一个例子是我们与 Calico 合作探索酵母基因调控的工作 (
https://www.embopress.org/doi/full/10.15252/msb.20199174)。有了大量细胞对特定遗传扰动反应的数据集,我们能够重新发现一些已知的生物相互作用并发现新的相互作用。
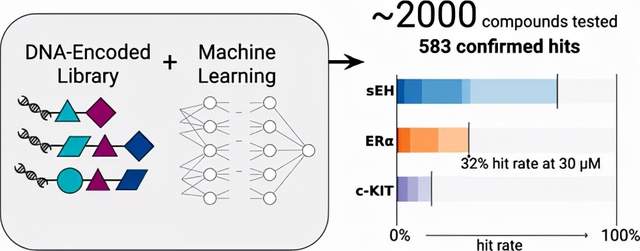
我要举的最后一个例子是我们与 X-Chem Pharmaceuticals (
https://pubs.acs.org/doi/abs/10.1021/acs.jmedchem.0c00452) 合作的 DNA 编码小分子文库的工作。这些小分子可以为开发药物提供起点。使用来自这些 DNA 编码分子库的数据,我们能够构建出令人惊讶的有效机器学习模型,以找到用于药物开发的有前途的小分子。
你如何选择要研究的主题,如何选择学术合作者?
这个过程有两个不同的部分。首先,我们如何接触到正确的可能性和人?我们这样做的方式与大多数学者的做法相同:通过我们认识的科学家建立联系、阅读有趣的论文并与作者联系、参加会议,以及偶尔与组织中的科学家或领导者打个电话。
其次,我们与合作伙伴一起提出的基本问题是:我们是否有一种方法或想法,能够让我们利用我们的计算技能来真正影响对该领域至关重要的问题?重要的是,这不是一个我们一次就可以提出和回答的问题;相反,这是一个我们不断重新审视的问题。我有许多项目一开始看起来很令人兴奋,但是当我们深入细节时,我们失去了对我们的方法是否真的有效的信念。相反,有时我们开始时没有清晰的蓝图,当我们与合作伙伴一起工作时,机会就会成为焦点。
我们如何知道机器学习模型何时出现问题?
这是一个非常重要的问题。任何做过实际机器学习工作的人都知道,95% 的实际工作不是在构建和拟合模型上。这是所有其他工作,仔细检查输入和输出,构成一个真正有用的模型。我们必须以怀疑的态度对待我们的所有模型并质疑它们,就像我们对待任何科学结果一样。这种谨慎的怀疑是必不可少的。我在《自然》的评论和谷歌机器学习指南 (https://developers.
google.com/machine-learning/guides/good-data-analysis)中写过关于这些主题的实用建议。
文章地址:https://www.nature.com/articles/d41586-019-02307-y
你认为机器学习研究中最有前途的方向是什么?
让我感到兴奋的一个方向是,不再将机器学习视为系统的单独模型或组件,而是将其紧密集成到整个算法或系统中。「可微分编程」一词通常用于表达这样一种想法,即我们可以构建系统,其中学习的组件与结构化代码和易于理解的算法紧密集成。换句话说,机器学习模型和学习过程被编织到整个算法的所有其他组件中,而不是作为一个单独的系统被分割出来。例如,在运行良好的分子动力学模拟的基本技术基础上有数十年的工作。我们可以利用现有的工作,通过已知算法添加自动微分,然后将机器学习组件作为整个系统的一部分连接起来。
切换到机器学习的使用方式,我们看到很多情况下,我们的机器学习算法可以更直接地控制下一步要做的实验,例如机械测试和化学反应优化。让科学家定义一个探索区域,算法在有限的空间中找到最有趣的点,这是一个很好的职责分工。不幸的是,这也是一个大肆炒作的领域。许多集成系统还处于早期开发阶段,价值主张没有明确定义。什么时候节省一定比例的实验以达到所需的性能水平是有价值的?通过实施这个复杂的系统,你的产出会提高多少?在研究中超越范例系统时,需要更好地理解这些类型的问题。
根据你的经验,你对进入该领域的研究人员有何启示?
我上面提到的怀疑主义确实需要培养。现代机器学习方法很强大,但这也意味着这些方法有很多与我们预期不同的功能。我们必须将我们的模型视为可以研究的东西,而不仅仅是真理的神奇来源。希望每个从事机器学习工作的人都需要建立数据技能,以便能够进行此类调查。
将机器学习应用于非常不同的系统有哪些优势和挑战?
多选题的好处是有机会了解许多不同的领域。我真的很喜欢这种广泛的接触。它还使我们能够专注于看起来最有希望的领域。如果我们在一个领域没有完全正确的问题或合作伙伴,我们可以将精力集中在另一个领域。当然,这也是一个挑战。不同的领域有不同的技术栈需要理解,一开始并不是很清楚什么是好的问题。这就是为什么我们认为与已深入该领域的伟大科学家合作至关重要的部分原因。
对于那些对机器学习感兴趣并考虑进入行业的学术研究人员,你有什么建议?
首先,「行业」可以有不同的含义。一些工业研究很像学术界,重点是影响整个研究界。其他职位有更实际的关注点:你如何在未来几年帮助该公司或行业?与这些公司的研究人员和潜在的未来经理交谈,找出他们真正的优先事项。同样需要注意的是,大多数行业研究更侧重于一起工作的同行小组,而不是 PI 领导自己小组。了解在新环境中你的同龄人是谁是很重要的。这种团体模式有很多优点,但它是对学术界的改变。
参考内容:https://www.nature.com/articles/s41578-021-00349-1