theme: cyanosis
前言
不知道你有没有这样的经历,线上的系统突然来了很大的流量,有可能是黑客的攻击,也有可能是业务量远远大于你的预估,如果你的系统没有做任何的防护措施,这时候系统负载过高,系统资源慢慢耗尽,接口响应越来越慢,直至不可用,这又导致了调用你接口的上游系统发生资源耗尽的情况,最终导致系统雪崩。想想就知道,这是一个灾难性的后果,那么有什么方法呢?
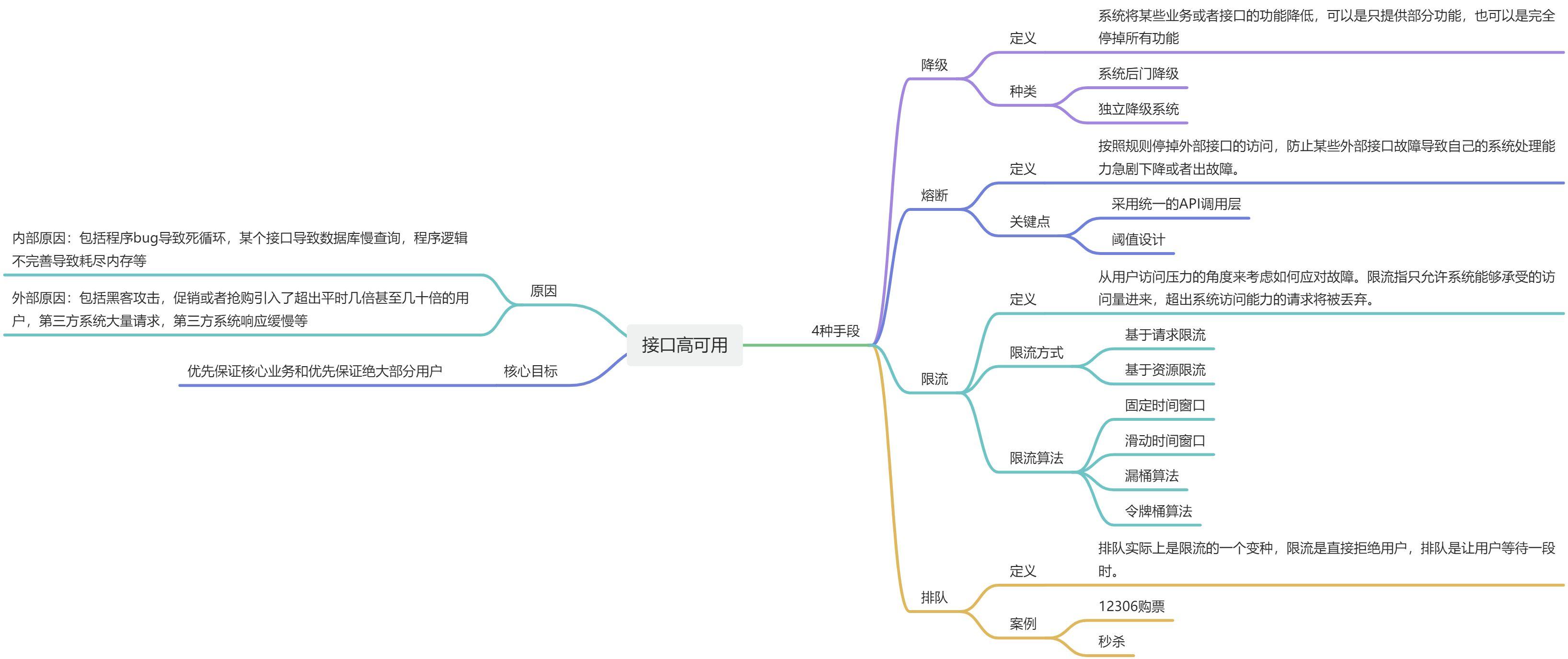
面对这种突发流量的场景,核心思路就是要优先保证优核心业务和优先保证绝大部分用户。常见的应对手段有四种,降级、熔断、限流和排队,下面我会一一讲解。
1. 降级
降级指系统将某些业务或者接口的功能降低,可以是只提供部分功能,也可以是完全停掉所有功能,优先保证核心功能。
比如淘宝双11零点抢购的时候你会发现商品的退货功能不可以使用了。又比如论坛可以降级为只能看帖子,不能发帖子;也可以降级为只能看帖子和评论,不能发评论;
常见的实现降级的方式有两种:
简单来说,就是系统预留了后门用于降级操作。例如,系统提供一个降级URL,当访问这个URL时,就相当于执行降级指令,具体的降级指令通过URL的参数传入即可。这种方案有一定的安全隐患,所以也会在URL中加入密码这类安全措施。
系统后门降级的方式实现成本低,但主要缺点是如果服务器数量多,需要一台一台去操作,效率比较低,这在故障处理争分夺秒的场景下是比较浪费时间的。
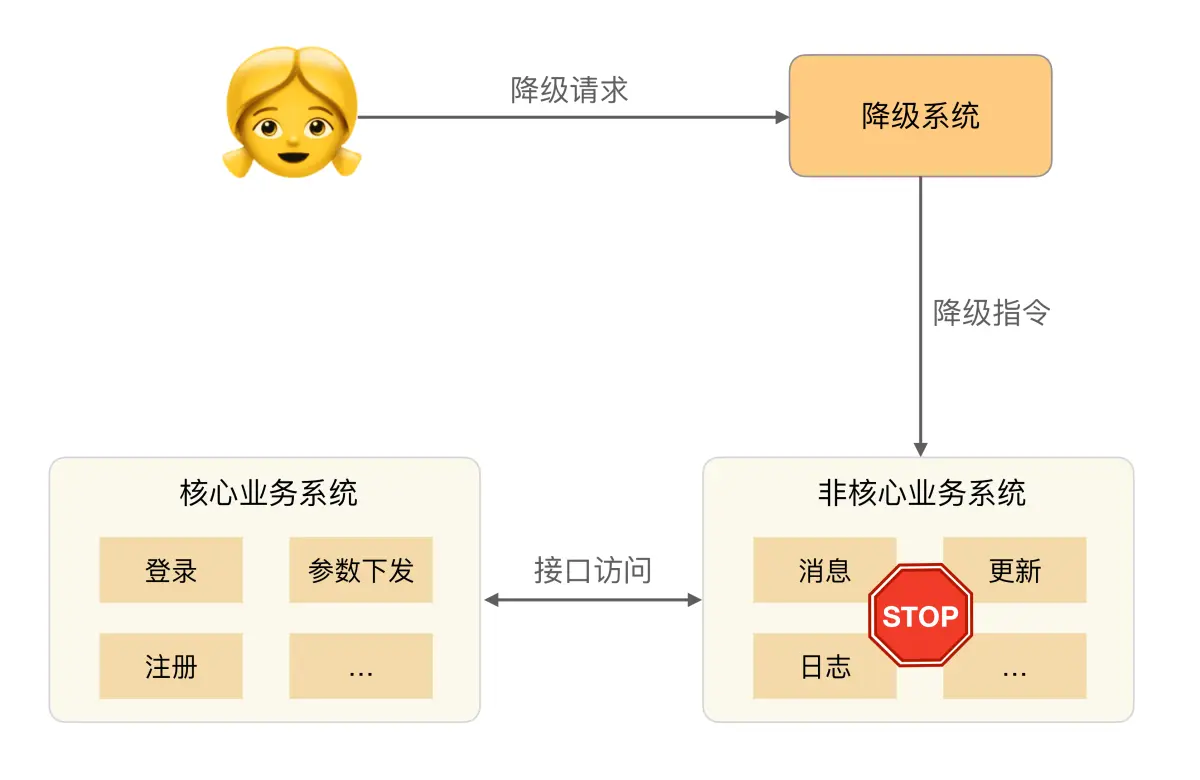
为了解决系统后门降级方式的缺点,我们可以将降级操作独立到一个单独的系统中,实现复杂的权限管理、批量操作等功能。
基本架构如下:
2. 熔断
熔断是指按照一定的规则,比如1分钟内60%的请求响应错误就停掉对外部接口的访问,防止某些外部接口故障导致自己的系统处理能力急剧下降或者出故障。
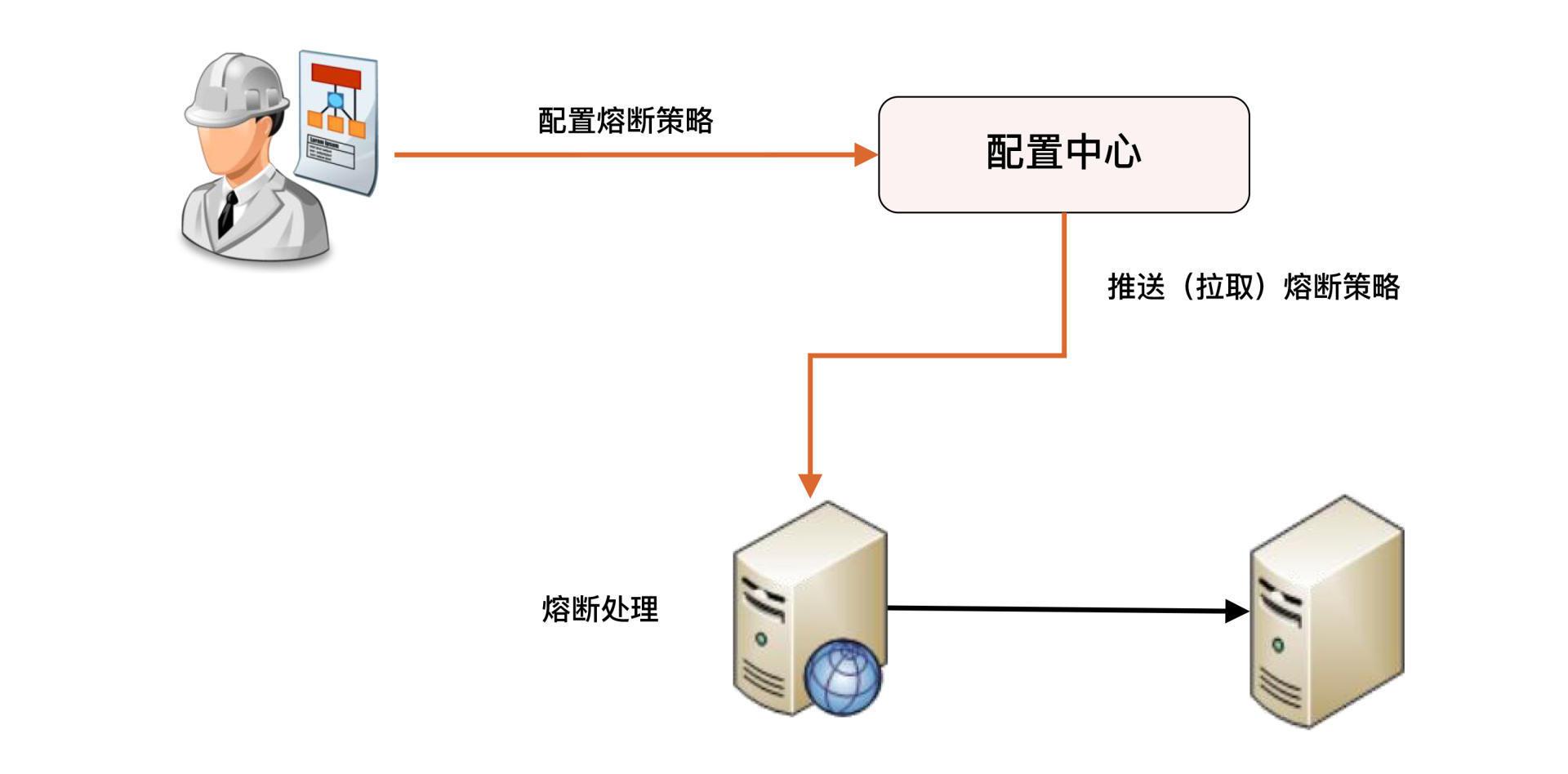
熔断和降级是两个比较容易混淆的概念,因为单纯从名字上看,好像都有禁止某个功能的意思。但它们的内涵是不同的,因为降级的目的是应对系统自身的故障,而熔断的目的是应对依赖的外部系统故障的情况。
关于服务熔断的实现,比较主流的有两种方案, Spring Cloud Netflix Hystrix和阿里的 Sentinel,我们公司的项目用的是 Sentinel。
- Hystrix是一个用于处理分布式系统的延迟和容错的一个开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能保证在一个依赖出现问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的稳定性。
- Sentinel 是阿里中间件团队开源的,面向分布式服务架构的轻量级高可用流量控制组件,主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助用户保护服务的稳定性。
3. 限流
每个系统都有服务的上线,所以当流量超过服务极限能力时,系统可能会出现卡死、崩溃的情况,所以就有了降级和限流。限流其实就是:当高并发或者瞬时高并发时,为了保证系统的稳定性、可用性,系统以牺牲部分请求为代价或者延迟处理请求为代价,保证系统整体服务可用。
限流一般都是系统内实现的,常见的限流方式可以分为两类:基于请求限流和基于资源限流。
基于请求限流指从外部访问的请求角度考虑限流,常见的方式有两种。
第一种是限制总量,也就是限制某个指标的累积上限,常见的是限制当前系统服务的用户总量,例如:某个直播间限制总用户数上限为100万,超过100万后新的用户无法进入;某个抢购活动商品数量只有100个,限制参与抢购的用户上限为1万个,1万以后的用户直接拒绝。
第二种是限制时间量,也就是限制一段时间内某个指标的上限,例如1分钟内只允许10000个用户访问;每秒请求峰值最高为10万。
无论是限制总量还是限制时间量,共同的特点都是实现简单,但在实践中面临的主要问题是比较难以找到合适的阈值。例如系统设定了1分钟10000个用户,但实际上6000个用户的时候系统就扛不住了;或者达到1分钟10000用户后,其实系统压力还不大,但此时已经开始丢弃用户访问了。
即使找到了合适的阈值,基于请求限流还面临硬件相关的问题。例如一台32核的机器和64核的机器处理能力差别很大,阈值是不同的,可能有的技术人员以为简单根据硬件指标进行数学运算就可以得出来,实际上这样是不可行的,64核的机器比32核的机器,业务处理性能并不是2倍的关系,可能是1.5倍,甚至可能是1.1倍。
为了找到合理的阈值,通常情况下可以采用性能压测来确定阈值,但性能压测也存在覆盖场景有限的问题,可能出现某个性能压测没有覆盖的功能导致系统压力很大;另外一种方式是逐步优化:先设定一个阈值然后上线观察运行情况,发现不合理就调整阈值。
基于上述的分析,根据阈值来限制访问量的方式更多的适应于业务功能比较简单的系统,例如负载均衡系统、网关系统、抢购系统等。
基于请求限流是从系统外部考虑的,而基于资源限流是从系统内部考虑的,也就是找到系统内部影响性能的关键资源,对其使用上限进行限制。常见的内部资源包括连接数、文件句柄、线程数和请求队列等。
例如,采用Netty来实现服务器,每个进来的请求都先放入一个队列,业务线程再从队列读取请求进行处理,队列长度最大值为10000,队列满了就拒绝后面的请求;也可以根据CPU的负载或者占用率进行限流,当CPU的占用率超过80%的时候就开始拒绝新的请求。
基于资源限流相比基于请求限流能够更加有效地反映当前系统的压力,但实际设计时也面临两个主要的难点:如何确定关键资源,以及如何确定关键资源的阈值。
通常情况下,这也是一个逐步调优的过程:设计的时候先根据推断选择某个关键资源和阈值,然后测试验证,再上线观察,如果发现不合理,再进行优化。
4. 排队
排队这种方式,想必大家在熟悉不过了。大家在12306买火车票的时候,是不是会告诉你在排队中,等待一段时间后才会锁定车票,付款。年底时,全中国那么多人买票,12306就是通过排队机制来搞定的。但是也有缺点,那就是用户体验没那么好。
由于排队需要临时缓存大量的业务请求,单个系统内部无法缓存这么多数据,一般情况下,排队需要用独立的系统去实现,例如使用Kafka这类消息队列来缓存用户请求。
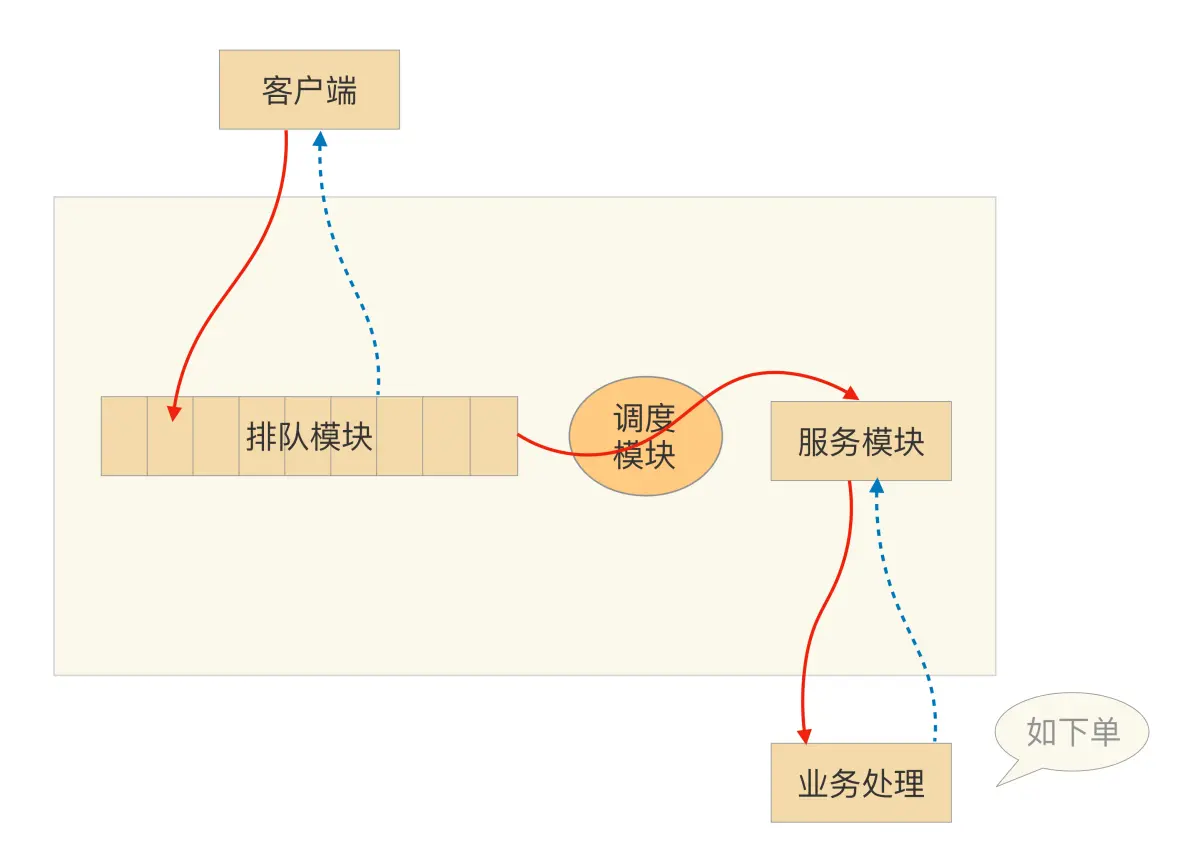
负责接收用户的抢购请求,将请求以先入先出的方式保存下来。每一个参加秒杀活动的商品保存一个队列,队列的大小可以根据参与秒杀的商品数量(或加点余量)自行定义。
负责排队模块到服务模块的动态调度,不断检查服务模块,一旦处理能力有空闲,就从排队队列头上把用户访问请求调入服务模块,并负责向服务模块分发请求。这里调度模块扮演一个中介的角色,但不只是传递请求而已,它还担负着调节系统处理能力的重任。我们可以根据服务模块的实际处理能力,动态调节向排队系统拉取请求的速度。
负责调用真正业务来处理服务,并返回处理结果,调用排队模块的接口回写业务处理结果。
总结
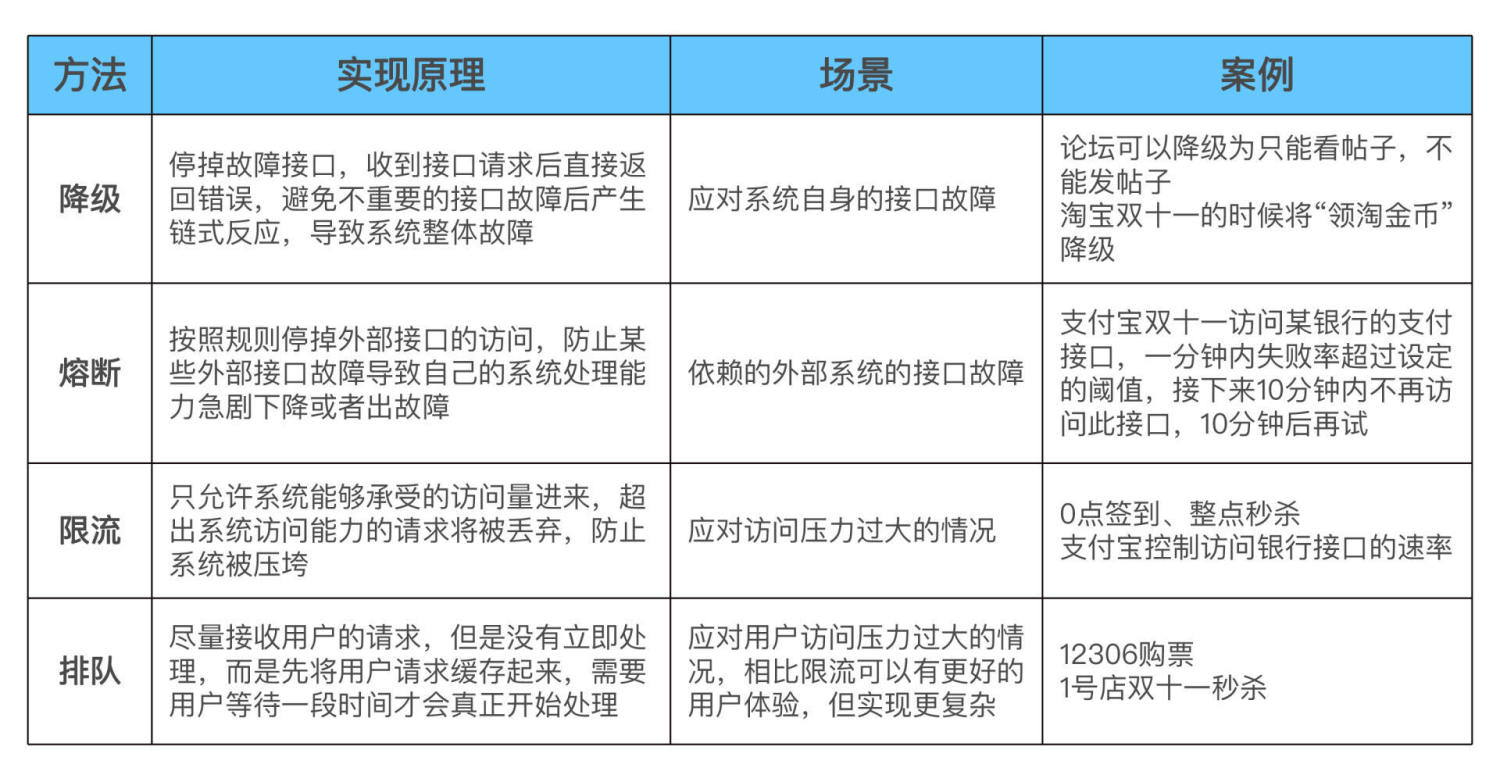
最后我们通过一个表格在总结以下上面4种保证服务高可用的手段。
 参考:
参考: https://freegeektime.com/100006601/10312/
欢迎关注个人公众号【JAVA旭阳】交流沟通