觉得不错请按下图操作,掘友们,哈哈哈!!!

概述
博主最近在做分布式事务这块业务,所以在选型的过程中,对比了当下比较流行的解决方案,在这里坐下记录,欢迎jym提出更好的方案哦。
一:分布式消息怎么保证数据的最终一致性:
1.1 添加消息中间表方案:
为了保证原子性,我们可以变通一下,添加一个消息表,A不直接往消息中间件中发消息,而是把消息写入消息表,然后通过一个后台程序不断的把消息写入消息中间件。比如转账流程,如下图:
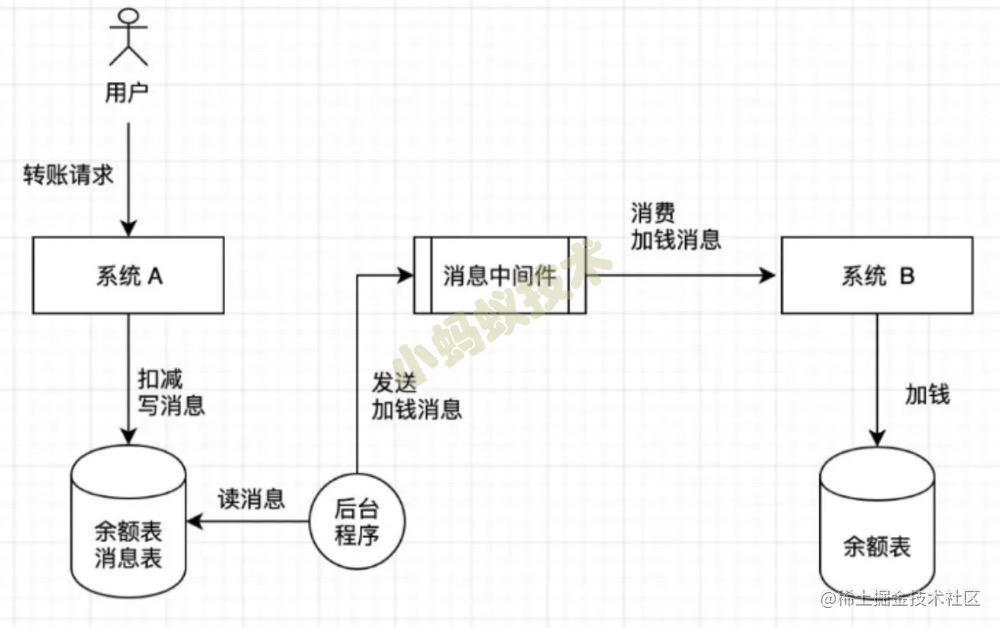
这个后台应用会把消息表中的数据发送到消息中间件中,当然这里边我们要有一个字段标识出消息的状态,然后提供接口给消息中间件回调(ACK)来知道消息是否发送成功,如果失败就重试,可以保证:消息不会丢失顺序不乱但会有消息重复的情况,因为消息发送失败可能是写入失败,也可能是写入成功但响应失败,所以消息可能会重复,这个问题需要系统 B来处理。
1.2 那么系统B要考虑那些问题呢:
1.2.1 消息丢失
系统B从消息中间件中拿到消息,还没处理完就宕机了,这条消息怎么办?
需要通过 ACK机制处理,消费成功的发送ACK,对于没有ACK的消息,消息中间件会再次推送。
1.2.2 消息重复:
即使有ACK机制也存在消息重复的情况,比如B已经处理完一条消息,发ACK时失败了,那么这条消息就还会被推过来。还有就是上面说的后台程序发消息时可能重复。对于重复消息问题,可以加一个判重操作,记录处理成功的消息,每次收到消息时,先通过判重操作判断一下,如果重复了就不处理,实现幂等性。
判重操作 可以放一张表里,也可以放到redis里,存储一定时间,在相应时间里如果有重复消息进来,就认为消息重复,但是也要来考虑业务,比如订单有好多操作,可能要加各种场景的校验,为而不是简单的以订单号来判断重复,具体要细到什么维度就要看自己实际的真实业务来设定了。改造后流程图如下:
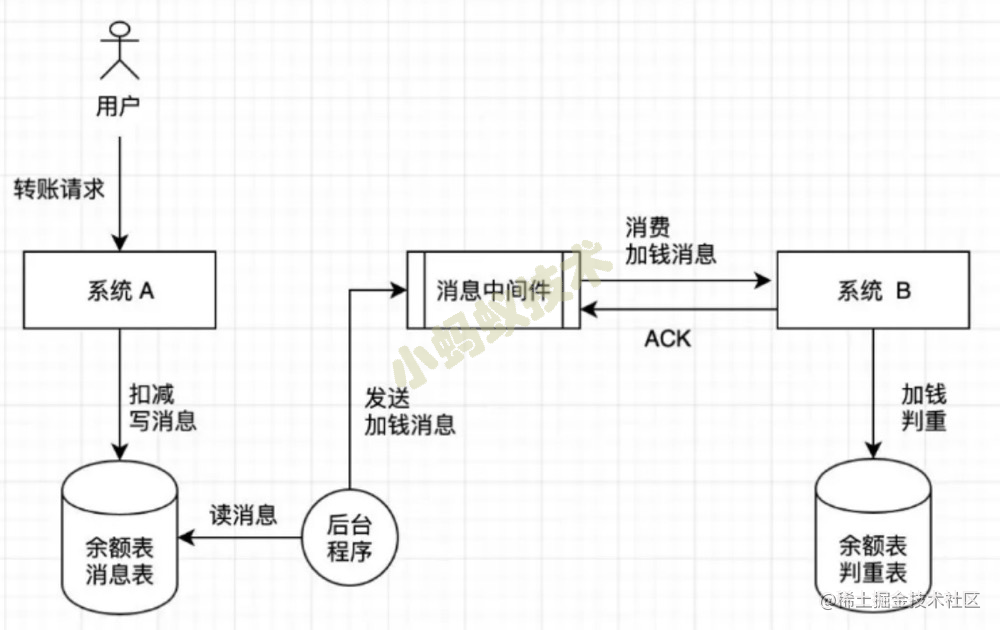
二:分布式事务保证数据一致性
常见分布式事务有 2PC、3PC、TCC、Saga、本地事务表、MQ事务消息、最大努力通知,我们这里重点介绍下主流的TCC和最大努力通知这两个
2.1 TCC
如果要用TCC 分布式事务的话:首先需要选择某种 TCC 分布式事务框架,各个服务里就会有这个 TCC 分布式事务框架在运行。
- 所以你原本的一个接口,要改造为 3 个逻辑,Try-Confirm-Cancel:先是服务调用链路依次执行 Try 逻辑。如果都正常的话,TCC 分布式事务框架推进执行 Confirm 逻辑,完成整个事务。如果某个服务的 Try 逻辑有问题,TCC 分布式事务框架感知到之后就会推进执行各个服务的 Cancel 逻辑,撤销之前执行的各种操作这就是所谓的CC 分布式事务。
- TCC 分布式事务的核心思想大白话的来说就是当遇到下面这些情况时:某个服务的数据库宕机了;某个服务自己挂了;那个服务的 Redis、Elasticsearch、MQ 等基础设施故障了。某些资源不足了,比如说库存或者限购不够这些。先来 Try 试一下,不要把业务逻辑完成,先试试看,看各个服务能不能基本正常运转,能不能先冻结我需要的资源。如果 说Try的过程都 OK,也就是说,底层的数据库、Redis、Elasticsearch、MQ 都是可以写入数据的,并且你保留好了需要使用的一些资源(比如冻结了一部分库存或者限购)。
- 接着,再执行各个服务的 Confirm 逻辑,基本上 Confirm 就可以很大概率保证一个分布式事务的完成了。那如果 Try 阶段某个服务就失败了,比如说底层的数据库挂了,或者 Redis 挂了,等等。
此时就自动执行各个服务的 Cancel 逻辑,把之前的 Try 逻辑都回滚,所有服务都不要执行任何设计的业务逻辑。保证大家要么一起成功,要么一起失败。
- 这里还有一个问题?如果有一些意外的情况发生了,比如说下单服务突然挂了,然后再次重启, TCC 分布式事务框架是如何保证之前没执行完的分布式事务继续执行的呢? 所以,TCC 事务框架都是要记录一些分布式事务的活动日志的,可以在磁盘上的日志文件里记录,也可以在数据库里记录。保存下来分布式事务运行的各个阶段和状态。
- 另外一个问题,万一某个服务的 Cancel 或者 Confirm 逻辑执行一直失败怎么办呢?那也很简单,TCC 事务框架会通过活动日志记录各个服务的状态。
- 就比如下边例子,比如发现某个服务的 Cancel 或者 Confirm 一直没成功,会不停的重试调用它的 Cancel 或者 Confirm 逻辑,务必要它成功!如果是有相应bug,那无限重试也是不行的,这时候我们就要添加相应报警,然后就要人工介入了。
TCC- Try confirm 阶段 正常情况:
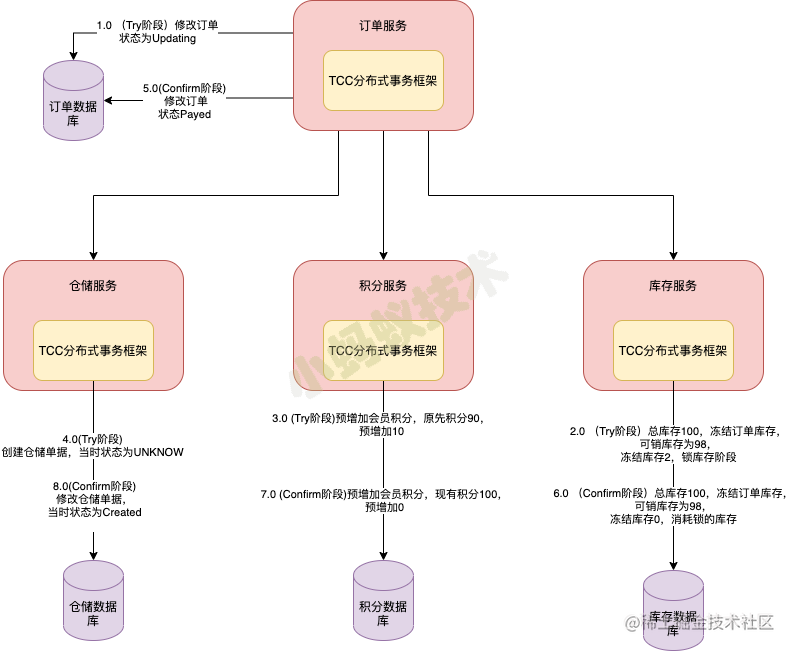
TCC- Try cancel 阶段,异常情况
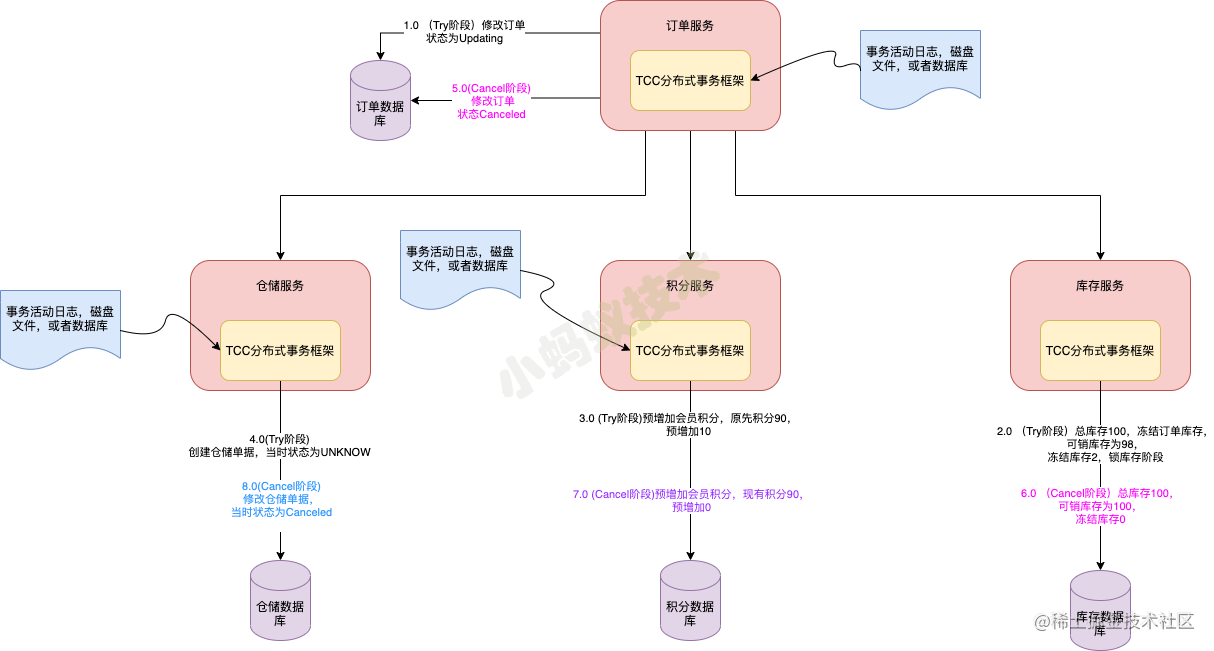
2.2 TCC如何保证最终一致性
- TCC 事务机制最重要的还是Try,Confirm 确认操作和 Cancel 取消操作都是围绕 Try 而展开的。因此,Try中的操作其保障性是最好的,即使失败了,仍然有 Cancel 取消操作将已经执行的操作撤销。
- Try阶段执行成功并开始执行 Confirm 阶段时,一致认为 Confirm 阶段是不会出错的,也就是说只要 Try 成功,Confirm 一定成功,这是设计之初的定义。
- Confirm 与 Cancel 如果失败,由TCC框架进行重试补偿 存在极低概率在Confirm和Cancel 环节彻底失败,则需要上边说的报警和人为介入了。
2.3 TCC的要注意的事项
允许空回滚 :什么是空回滚,比如 Try 超时或者丢包,导致 TCC 分布式事务二阶段的回滚触发 Cancel 操作,此时事务参与者未收到Try,但是却收到了Cancel 请求。也就是由于网络原因,下游服务没有收到Try 操作,后续比如网络正常后 收到了Cancel请求了。
做好幂等 :由于网络原因或者重试操作都有可能导致 Try ,Confirm , Cancel 3个操作重复执行,所以在使用 TCC 时要考虑到这三个操作相应的幂等控制,通常我们可以使用事务 xid 或业务主键判重来控制,避免影响业务。
2.4 TCC方案的优缺点
优点:
- 性能提升:由业务来实现,资源的控制粒度变小,不会锁定整个资源。
- 保证了数据最终一致性:基于 Confirm 和 Cancel 的幂等性,保证事务最终完成确认或者取消,保证数据的一致性。
- 可靠性:由主业务方发起并控制整个业务活动,业务活动管理器也变成多点,引入集群概念。
缺点:
TCC 中 Try、Confirm 和 Cancel 操作功都是基于业务来实现,业务耦合度较高,提高了开发成本。
三:基于本地消息的最终一致性:
3.1 解释:
本地消息表的核心思想就是将分布式事务拆成本地事物来处理,在方案执行中束腰有两种角色:事务发起方和事务被动接收方。事务主动发起方需要额外新建事务消息储存表,并在本地事务中完成业务处理和记录事务消息,并轮询事务消息表的数据发送事务消息,事务被动接收方则是基于消息中间件消费事务消息表中的事务,处理自己的业务。
这样可以避免以下两种情况导致的数据不一致性:
业务处理成功、事务消息发送失败
业务处理失败、事务消息发送成功
3.2 简化流程图
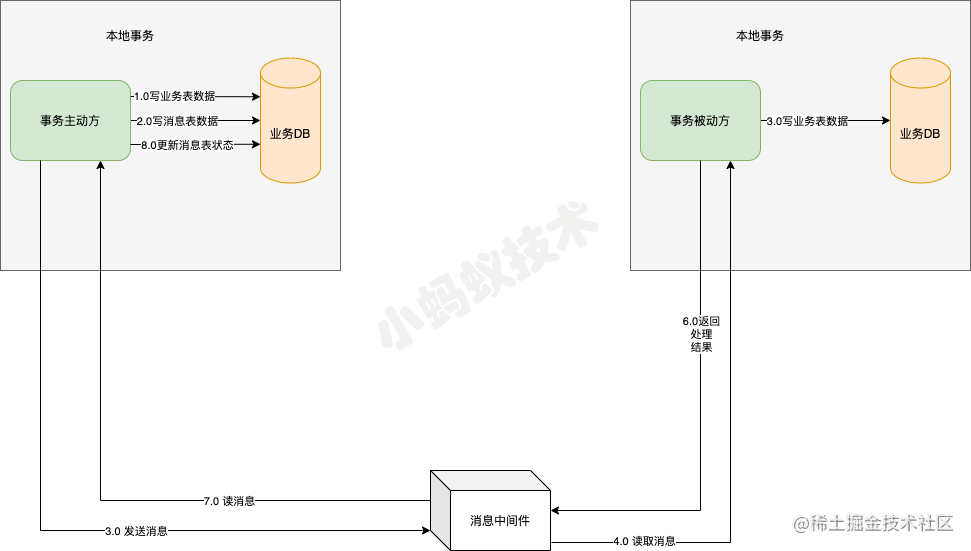
- 1 事务发起方在同一个本地事务中处理业务和写消息表操作
- 2 事务发起方通过消息中间件,通知事务被动方处理事务消息。消息中间件可以基于 Kafka、RocketMQ 等消息队列,事务主动方主动写消息到消息队列,事务消费方消费并处理消息队列中的消息。
- 3 事务接收方通过消息中间件,通知事务主动方事务已处理的消息。
- 4 事务接收方接收中间件的消息,更新消息表的状态为已处理。
一些必不可少的容错机制如下:
- 当1 步骤处理出错,由于还在事务主动方的本地事务中,直接回滚即可。
- 当2,3 步骤 处理出错,由于事务主动发起方本地保存了消息,只需要轮询消息重新通过消息中间件发送,通知事务被动方重新读取消息处理业务即可。
- 如果是业务上处理失败,事务被动接收方可以发消息给事务主动方回滚事务。
- 如果事务被动接收方已经消费了消息,事务主动发起方需要回滚事务的话,需要发消息通知事务主动发起方进行回滚事务。
本地消息表的优缺点:
优点:
- 从业务设计的角度实现了消息数据的可靠性,消息数据的可靠性不依赖于消息中间件,弱化了对 MQ 的依赖。
- 方案比较轻量,容易实现。
缺点:
- 耦合了具体场景的业务,不可公用
- 消息数据与业务数据同库,业务数据量大的时候会有影响
- 业务系统在使用关系型数据库的情况下,消息服务性能会受到关系型数据库并发性能的局限
这个版本相对比较简陋,只是大体的显现出来了轮廓,下图是改进版本。
3.3 本地消息一致性升级版本
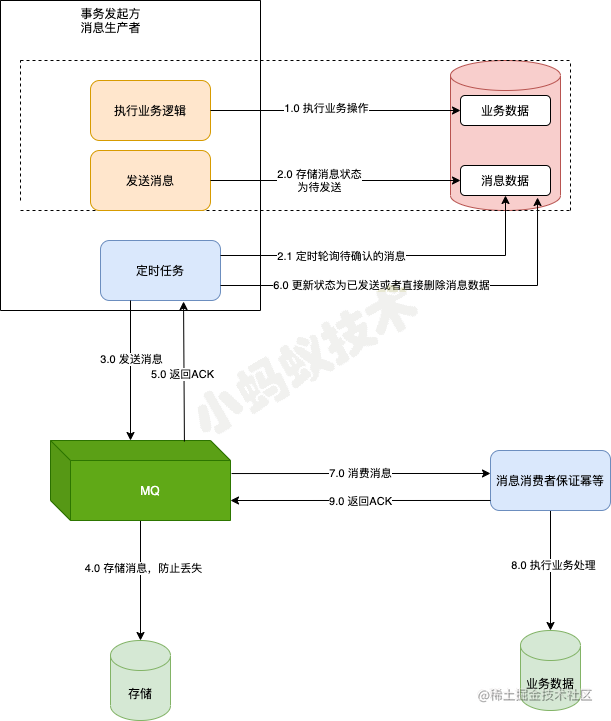
- 基于本地消息的最终一致性方案的最核心做法就是在执行业务操作的时候, 记录一条消息数据到DB,而且消息数据的记录一定要和业务数据的记录在同一个事务内完成,这是该方案的前提核心保障。
- 在记录完成后消息数据后,我们就可以通过一个定时任务到DB中去轮询状态为待发送的消息,然后将消息投递给MQ。
- 这个过程中可能存在消息投递失败的可能,此时就依靠重试机制来保证,直到成功收到MQ的ACK确认之后,再将消息状态更新或者消息清除;
- 而后面消息的消费失败的话,则依赖MQ本身的重试来完成,其最后做到两边系统数据的最终一致性。基于本地消息服务的方案虽然可以做到消息的最终一致性,但是它有一个比较严重的弊端,每个业务系统在使用该方案时,都需要在对应的业务库创建一张消息表来存储消息。针对这个问题,我们可以将该功能单独提取出来,做成一个消息服务来统一处理,因而就衍生出了我们下面将要讨论的方案。
四:独立消息服务的最终一致性
-
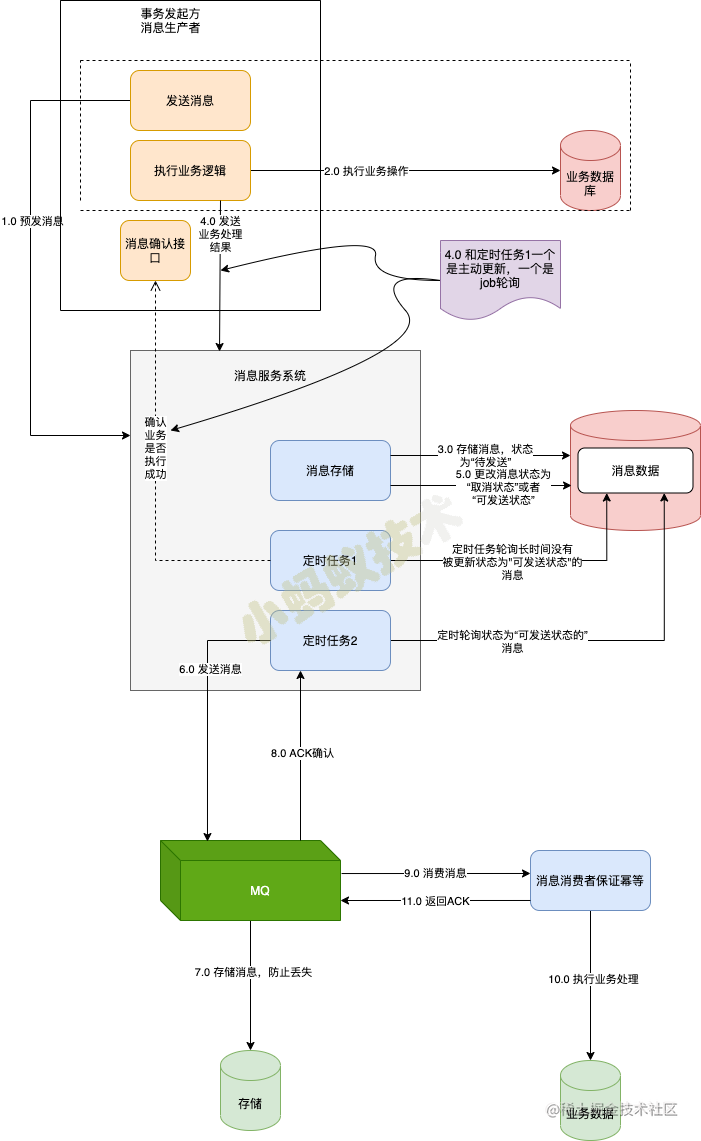
- 事务主动方在执行业务前预发消息
-
- 事务发起方 ,执行相应业务
-
- 消息服务系统接受到消息存储,并且将消息状态置为 “待发送状态”
-
- 事务主动方主动发送业务处理结果,或者消息服务系统定时去轮询事务发起方业务处理结果
-
- 得到事务发起方业务处理结果
-
- 发送消息到MQ
-
- MQ消息持久化防止丢失
-
- 确认消息被投递到MQ,得到ACK信息
-
- 事务接收方得到投递的消息
-
- 事务接收放得到投递的消息执行相应业务
-
- 执行完后返回ACK信息
- 独立消息服务最终一致性与本地消息服务最终一致性最大的差异就在于将消息的存储单独地做成了一个RPC的服务;
- 这个过程其实就是模拟了事务消息的消息预发送过程,如果预发送消息失败,那么生产者业务就不会去执行业务,因此对于生产者的业务而言,它是强依赖于该消息服务的。
- 不过要保证好独立消息服务高可用则要做成HA的集群模式,就能够保证其可靠性。在消息服务中,还有一个单独地定时任务,它会定期轮训长时间处于待发送状态的消息,通过一个check补偿机制来确认该消息对应的业务是否成功,如果对应的业务处理成功,则将消息修改为可发送,然后将其投递给MQ;如果业务处理失败,则将对应的消息更新或者删除即可。
- 因此在使用该方案过程中,事务发起方必须同时实现一个check服务,来供消息服务做消息的确认。对于消息的消费,该方案与上面的处理是一样,都是通过MQ自身的重发机制来保证消息被消费。
五:总要有总结
使用场景:
本章讲述了常见分布式系统数据一致性方案,从数据库,到MQ,从TCC 到 本地消息最终一致性方案,再到 独立消息服务最终一致性,系统复杂性也随之增强,但是业务得到了解耦专注于某一块业务。但是实际应用中要根据自己系统的真实情况去选用方案,才能做到因地制宜,得到相对比较好的结果。
本文正在参加 「金石计划」