




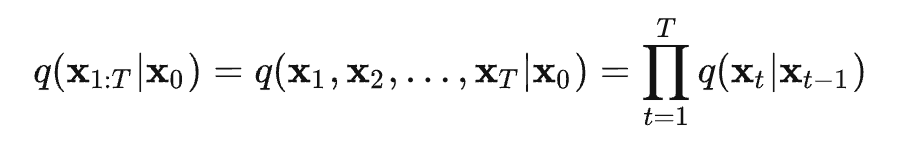
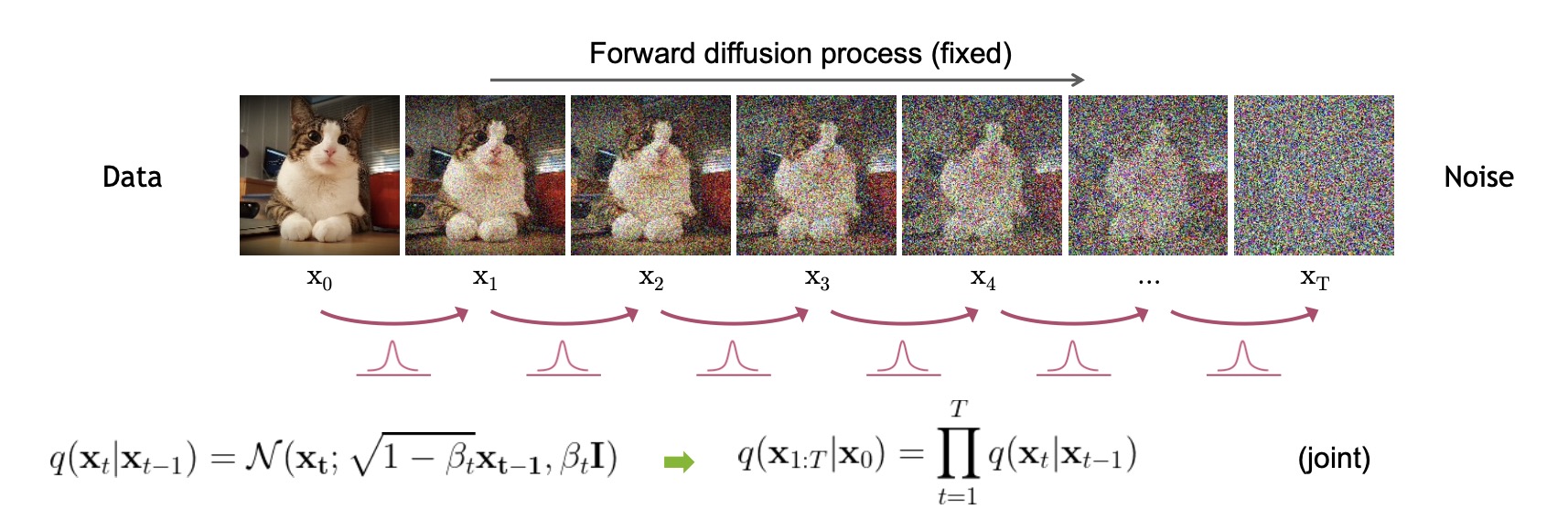
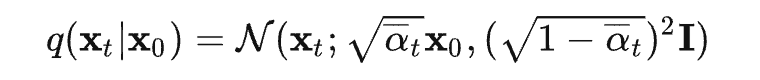
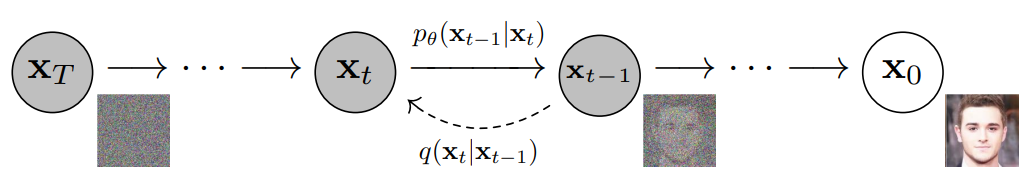
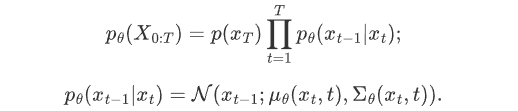
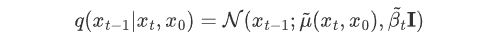

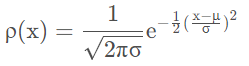
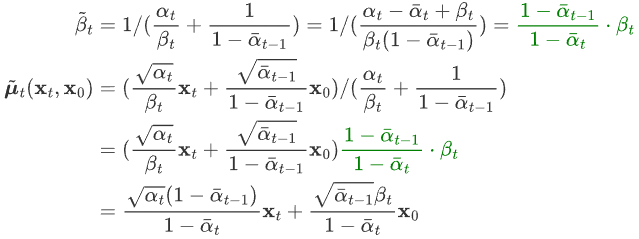
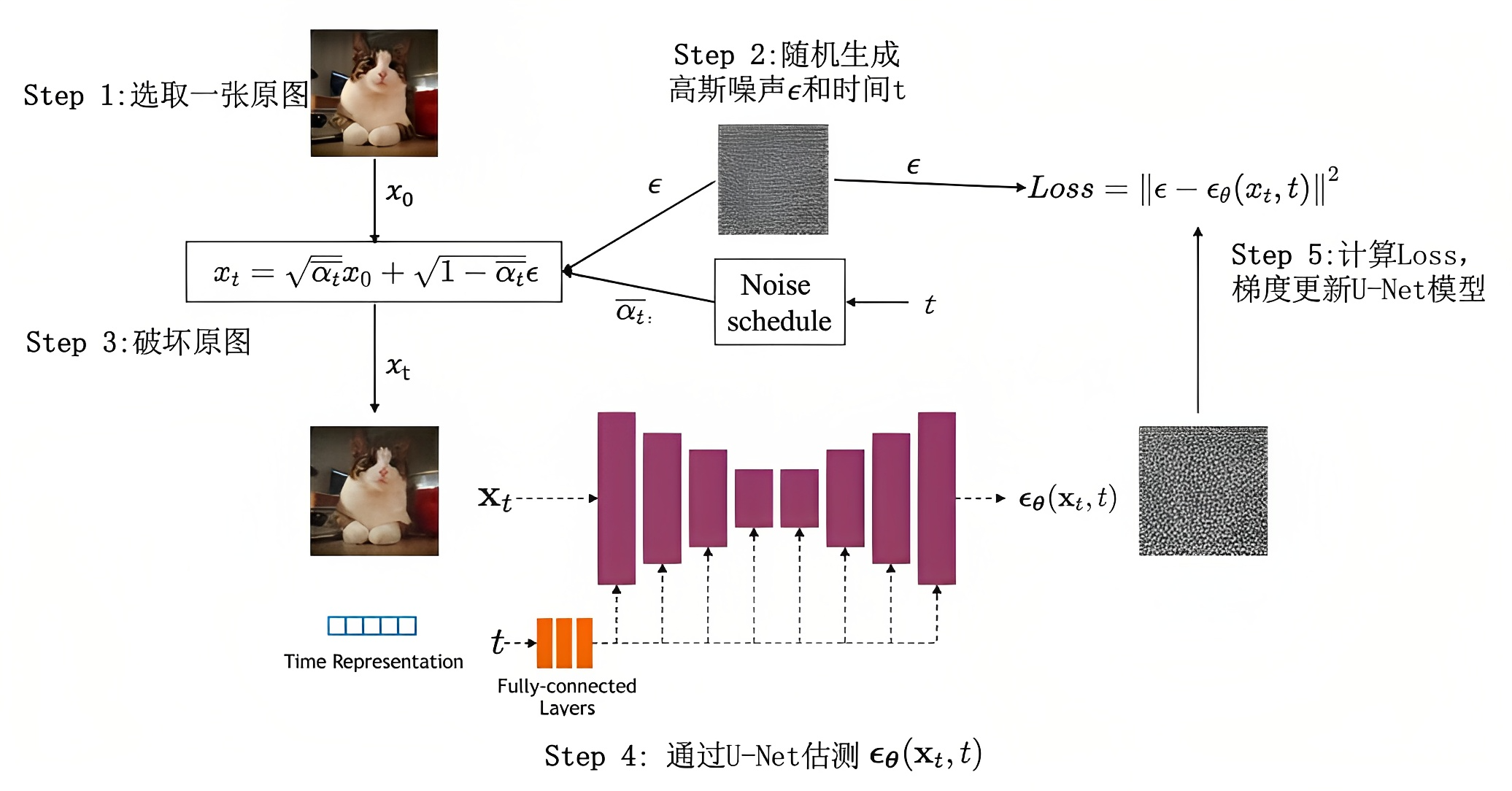
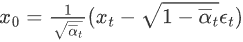 ,代入上式 可得
,代入上式 可得 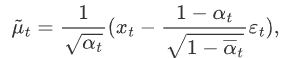
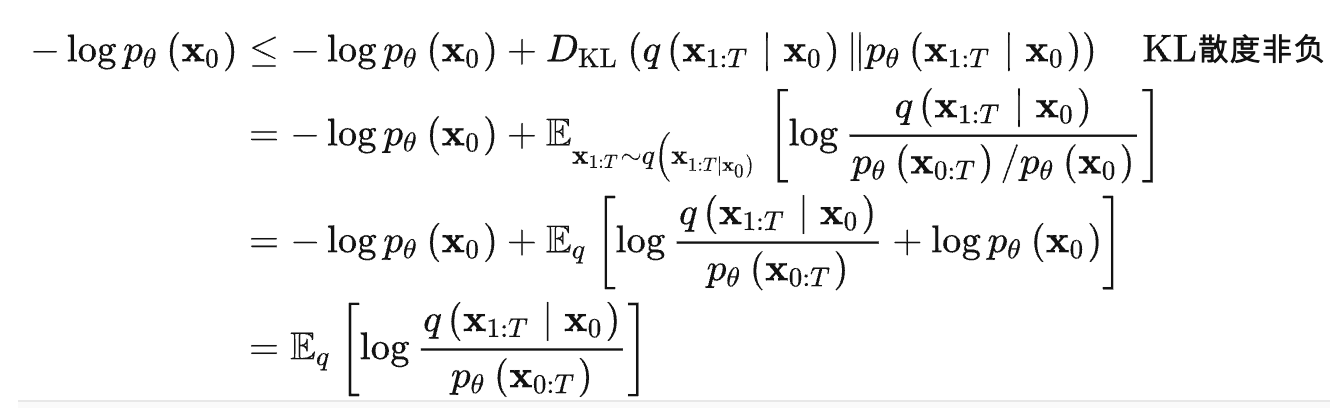
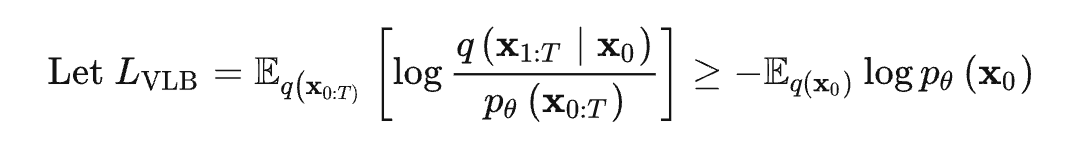

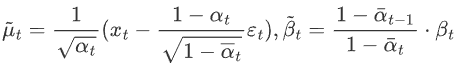
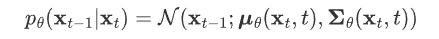
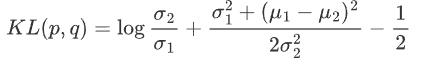


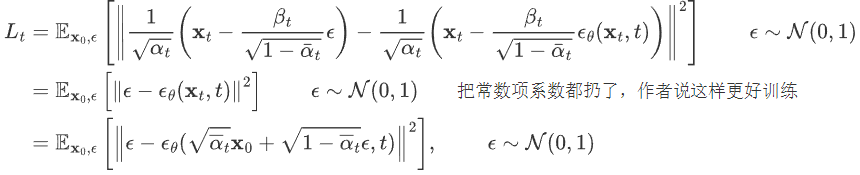
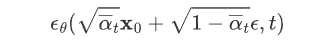

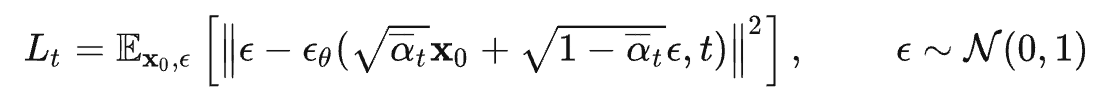

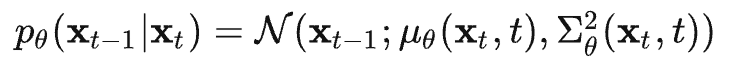
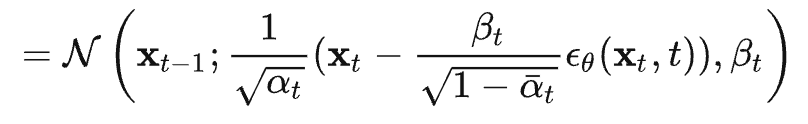
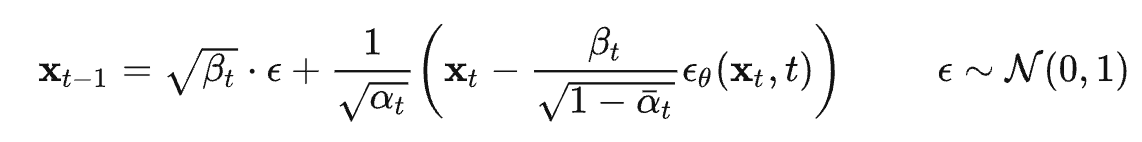
AI绘画能力的起源:通俗理解VAE、扩散模型DDPM、ViT/Swin transformer_v_JULY_v的博客-CSDN博客
- -2018年我写过一篇博客,叫:《. 一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD》,该文相当于梳理了2019年之前CV领域的典型视觉模型,比如. 随着2019 CenterNet的发布,特别是2020发布的DETR(End-to-End Object Detection with Transformers)之后,自此CV迎来了生成式下的多模态时代.