Python地理数据分析工具MovingPandas
- - 标点符MovingPandas 是一个用于分析轨迹数据的 Python 库. 它在处理和分析移动对象的时空数据方面非常强大,适用于地理信息系统(GIS)、时空数据分析和可视化等领域. 它是在热门的地理数据处理库 GeoPandas 的基础上构建的,GeoPandas 本身是建立在Pandas数据处理库之上的.
MovingPandas 是一个用于分析轨迹数据的 Python 库。它在处理和分析移动对象的时空数据方面非常强大,适用于地理信息系统(GIS)、时空数据分析和可视化等领域。它是在热门的地理数据处理库 GeoPandas 的基础上构建的,GeoPandas 本身是建立在Pandas数据处理库之上的。MovingPandas 旨在提供高效、易于使用的工具,以便分析和处理包含位置信息的时间序列数据。MovingPandas使得研究移动模式、路径分析、时空聚类等任务变得更加高效和直观。

核心功能:
MovingPandas作者推荐在Python 3.7及以上环境下安装。请确保你的Python版本符合这一要求。如果你已经安装了Anaconda,可以使用conda命令来安装MovingPandas及其依赖包。
conda install -c conda-forge movingpandas
MovingPandas同样可以使用pip进行安装,但是不推荐,主要原因是其依赖环境较为复杂,使用pip安装可能会出现依赖项缺失或版本冲突的问题。因此,推荐使用conda进行安装。
在 MovingPandas 中,Trajectory 类是核心组件之一,主要用于表示和处理单个轨迹。Trajectory 对象是一个时间序列的集合,其中每个数据点代表轨迹上的一个位置,包含了位置信息(经纬度或其他地理空间参考)、时间戳和其他可能的属性(如速度、方向等)。因此,一个 Trajectory 对象是连续移动的点组成的线,这些点按照时间顺序排列。
Trajectory 对象的主要特性:
创建 Trajectory 对象通常涉及几个步骤,首先你可能需要有一个包含时空数据的pandas DataFrame。这个DataFrame应该至少包含三列:表示时间戳的列(通常会被设置为索引)、表示X坐标的列(如经度)、表示Y坐标的列(如纬度)。然后,你可以使用 MovingPandas 提供的函数或方法(如TrajectoryCollection.from_geodataframe())来创建一个或多个 Trajectory 对象。
class movingpandas.Trajectory(df, traj_id, traj_id_col=None, obj_id=None, t=None, x=None, y=None, crs=’epsg:4326′, parent=None)
参数说明:
基本信息与操作
轨迹分析与聚合统计
TrajectoryCollection 类是 MovingPandas 中用于表示多条轨迹的集合。它允许用户以集合的形式操作多条轨迹,支持对这些轨迹的批量处理和分析。
可以通过传递一系列 Trajectory 对象来创建一个 TrajectoryCollection。每个 Trajectory 对象代表一条轨迹,包含了时间和位置的信息。
class movingpandas.TrajectoryCollection(data, traj_id_col=None, obj_id_col=None, t=None, x=None, y=None, crs=’epsg:4326′, min_length=0, min_duration=None)
参数说明:
相比MovingPandas.Trajectory多了一些方法:
MovingPandas.TrajectoryCollectionAggregator 是 MovingPandas 库中的一个类,主要用于对轨迹集合进行聚合操作。通过对轨迹数据进行空间和时间上的聚合,可以帮助用户有效地分析和总结移动模式。
class movingpandas.TrajectoryCollectionAggregator(traj_collection, max_distance, min_distance, min_stop_duration, min_angle=45)
参数说明
相关方法:
MovingPandas.TrajectoryCleaner 是 MovingPandas 库中的一个类,专门用于清理轨迹数据。清理操作可以帮助去除数据中的噪声、填补缺失值以及进行其他预处理步骤,确保轨迹数据的质量和一致性。
MovingPandas.TrajectoryGeneralizer 是 MovingPandas 库中的一个类,用于对轨迹数据进行简化和概括。通过轨迹数据的概括,可以减少数据量,提高处理效率,并且在某些应用场景下有助于更清晰地展示轨迹特征。
MovingPandas.TrajectorySmoother 是一个类,用于对轨迹数据进行平滑处理。轨迹平滑通常是为了减少由于数据采集误差和噪声导致的轨迹抖动和异常点,从而得到更加平滑和准确的轨迹线条。
MovingPandas.TrajectorySplitter 是一个类,用于将轨迹数据根据特定条件进行分割。这在处理长时间、多段的轨迹数据时特别有用,比如在分析车辆行驶路径、运动员运动轨迹或动物迁徙路径时,可以根据特定的规则将连续的轨迹分割成多个部分,以便进行更细致的分析。
TrajectoryStopDetector 通过分析轨迹点的时空属性来识别停留点。它会检查一个轨迹对象中的每个点,并根据设定的阈值参数(如最小速度、最小停留时间和最小停留距离等)来鉴定轨迹中是否存在停留段。
class movingpandas.TrajectoryStopDetector(traj, n_threads=1)
方法介绍:
加载需要的库
import pandas as pd import geopandas as gpd import movingpandas as mpd from datetime import datetime, timedelta import matplotlib.pyplot as plt import folium import bokeh.io bokeh.io.output_notebook() from holoviews import opts opts.defaults(opts.Overlay(active_tools=["wheel_zoom"], frame_width=500, frame_height=400))
加载数据
df = pd.read_excel("driver_log.xlsx")
# 将DataFrame 转换为 GeoDataFrame
gdf = gpd.GeoDataFrame(df, geometry=gpd.points_from_xy(df.lon, df.lat), crs='EPSG:4326')
# 将GeoDataFrame转化为TrajectoryCollection对象
tc = mpd.TrajectoryCollection(gdf, traj_id_col='session_id', obj_id_col = 'driver_no', t='log_time')
# 过滤某个司机的轨迹
df['driver_no'].value_counts()
df['driver_no'].value_counts().plot(kind='bar', figsize=(15,3))
driver_tc = tc.filter('driver_no', 'DR202407021504081000000')
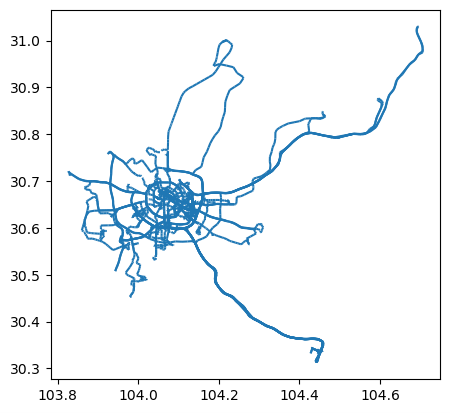
# 展示司机轨迹
driver_tc.plot()
# 获取单个轨迹
my_traj = driver_tc.trajectories[0]
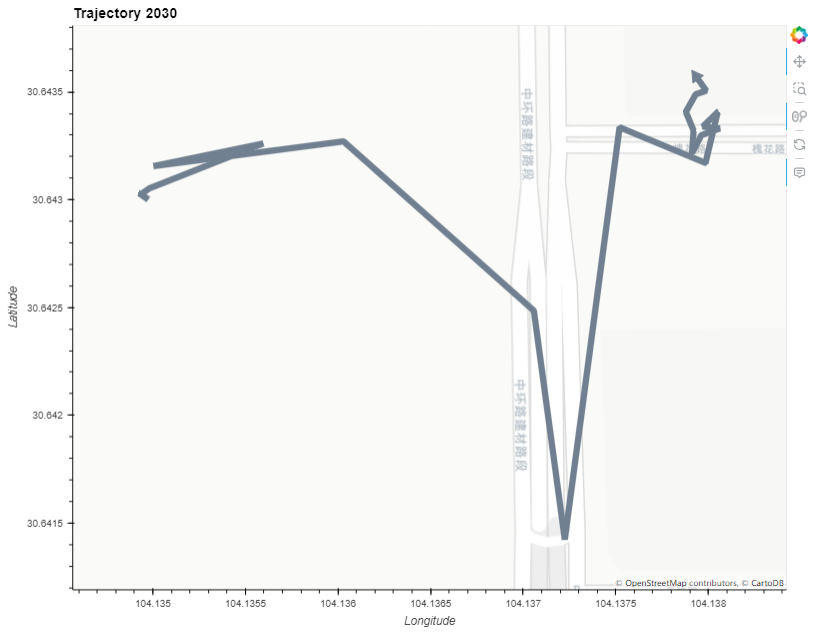
# 展示单个轨迹
traj_plot = my_traj.hvplot(title="Trajectory {}".format(my_traj.id),line_width=7.0, tiles="CartoLight", color="slategray")
traj_plot
针对单轨迹停留点检测
detector = mpd.TrajectoryStopDetector(my_traj)
## 检测停留的时间(这里检测5分钟位移100米以内)
stop_time_ranges = detector.get_stop_time_ranges(min_duration=timedelta(seconds=300), max_diameter=100)
## 检测停留的时间
for stop_time in stop_time_ranges:
print(stop_time)
## 检测停留点
stop_points = detector.get_stop_points(min_duration=timedelta(seconds=300), max_diameter=100)
stop_points
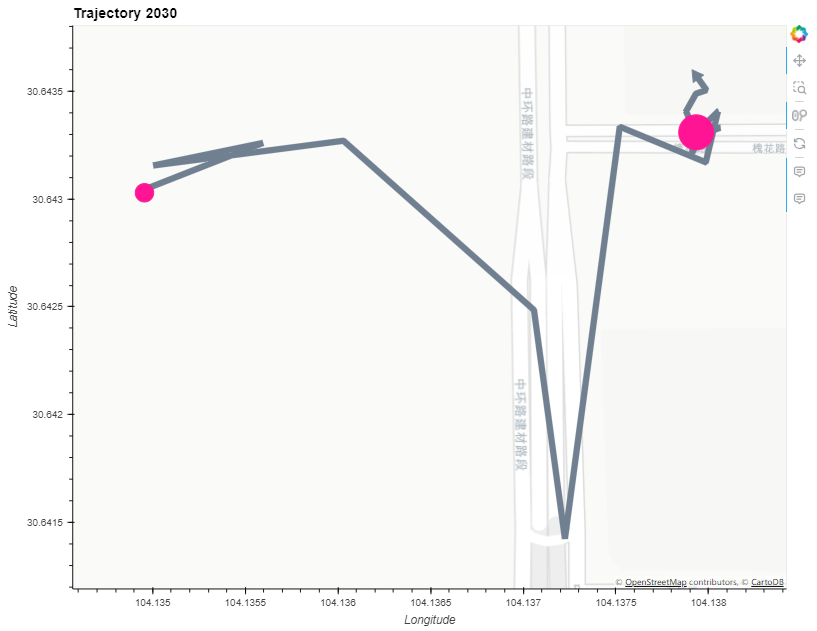
## 展示停留点
stop_point_plot = traj_plot * stop_points.hvplot(geo=True, size="duration_s", color="deeppink")
stop_point_plot
## 停留点信息
stop_points_gdf = gpd.GeoDataFrame(stop_points, geometry="geometry", crs="EPSG:4326")
stop_points_gdf
## 使用folium展示停留点
# m = my_traj.explore(color="blue",style_kwds={"weight": 4},name="Trajectory")
# stop_points_gdf.explore(m=m,color="red",style_kwds={"style_function": lambda x: {"radius": x["properties"]["duration_s"] / 10 }},name="Stop points")
# folium.TileLayer("OpenStreetMap").add_to(m)
# folium.LayerControl().add_to(m)
# m
## 停留轨迹
stop_segments = detector.get_stop_segments(min_duration=timedelta(seconds=60), max_diameter=100)
stop_segments.to_traj_gdf()
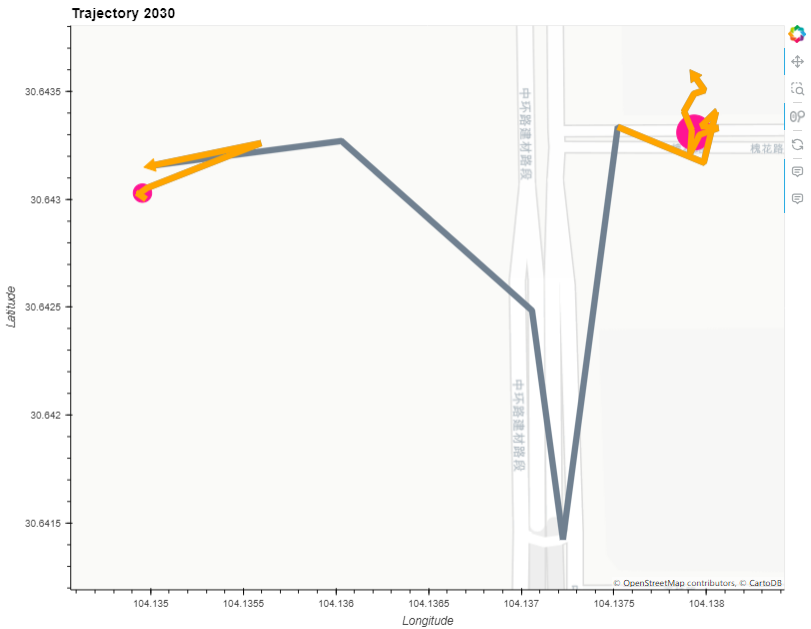
## 停留轨迹
stop_segment_plot = stop_point_plot * stop_segments.hvplot(line_width=7.0, tiles=None, color="orange")
stop_segment_plot
## 使用folium绘图
# m = my_traj.explore(
# color="blue",
# popup=True,
# style_kwds={"weight": 4},
# name="Trajectory",
# )
# stop_segments.explore(
# m=m,
# color="orange",
# popup=True,
# style_kwds={"weight": 4},
# name="Stop segments",
# )
# stop_points_gdf.explore(
# m=m,
# color="red",
# tooltip="stop_id",
# popup=True,
# marker_kwds={"radius": 3},
# name="Stop points",
# )
# folium.TileLayer("CartoDB positron").add_to(m)
# folium.LayerControl().add_to(m)
# m
## 行驶线路
split = mpd.StopSplitter(my_traj).split(min_duration=timedelta(seconds=300), max_diameter=100)
split.to_traj_gdf()
## 可视化行驶线路
split.explore(column="session_id", tiles="CartoDB positron", style_kwds={"weight": 4})
## 整体可视化
stop_segment_plot + split.hvplot(title="Trajectory {} split at stops".format(my_traj.id),line_width=7.0,tiles="CartoLight")
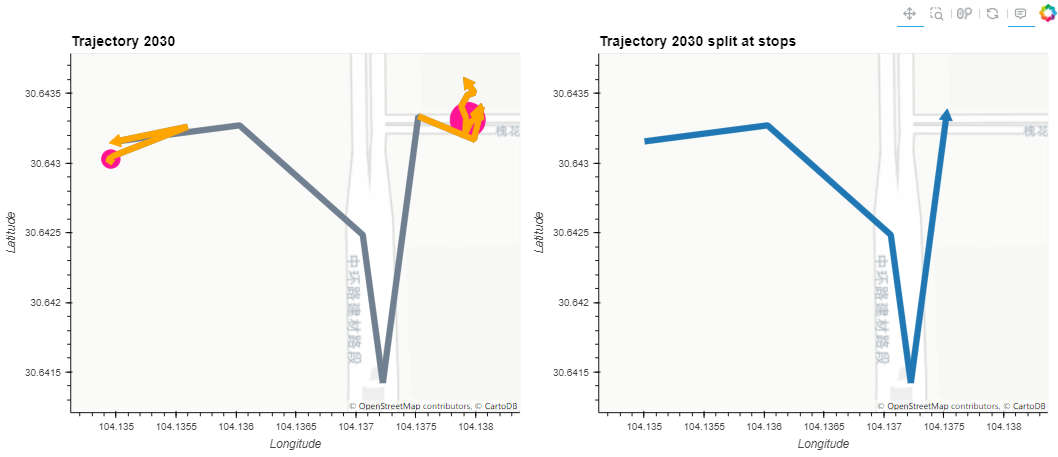
轨迹合集的经停点检测
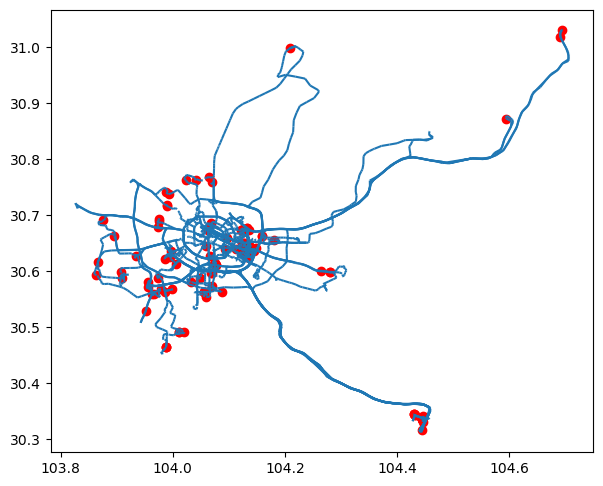
## 停留点检测 detector = mpd.TrajectoryStopDetector(driver_tc) stop_points = detector.get_stop_points(min_duration=timedelta(seconds=300), max_diameter=100) stop_points ## 停留点可视化 ax = driver_tc.plot(figsize=(7, 7)) stop_points.plot(ax=ax, color="red")
## 使用folium可视化
## 使用方folium可视化
# m = driver_tc.explore(
# column="session_id",
# popup=True,
# style_kwds={"weight": 4},
# name="Trajectories",
# )
# stop_points.explore(
# m=m,
# color="red",
# tooltip="stop_id",
# popup=True,
# marker_kwds={"radius": 5},
# name="Stop points",
# )
# folium.TileLayer("CartoDB positron").add_to(m)
# folium.LayerControl().add_to(m)
# m
## 单轨迹增加速度
my_traj.add_speed(overwrite=True,units=("km", "h"))
my_traj.df.head()
## 展示速度
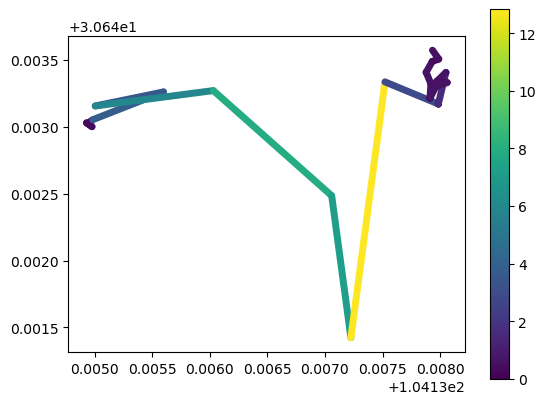
my_traj.plot(column="speed", linewidth=5, capstyle='round', legend=True)
# my_traj.hvplot(c='speed', clim=(0,20), line_width=7.0, tiles='CartoLight', cmap='Viridis', colorbar=True)
## 添加方向
my_traj.add_direction(overwrite=True)
my_traj.df.head()
## 添加时差
my_traj.add_timedelta(overwrite=True)
my_traj.df.head()
## 添加距离
my_traj.add_distance(overwrite=True, name="distance (km)", units="m")
my_traj.df.head()
## 添加加速度
my_traj.add_acceleration(overwrite=True, name="acceleration (mph/s)", units=("mi", "h", "s"))
my_traj.df.head()
## 轨迹集增加速度
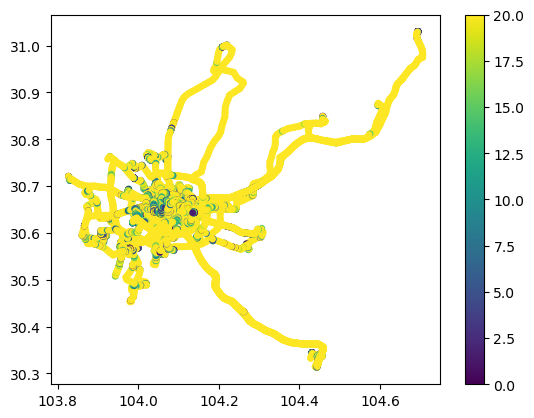
driver_tc.add_speed(overwrite=True,units=("km", "h"))
driver_tc.plot(column='speed', linewidth=5, capstyle='round', legend=True, vmax=20)
## 获取起点与终点 ax = my_traj.plot() gpd.GeoSeries(my_traj.get_start_location()).plot(ax=ax, color='blue') gpd.GeoSeries(my_traj.get_end_location()).plot(ax=ax, color='red')
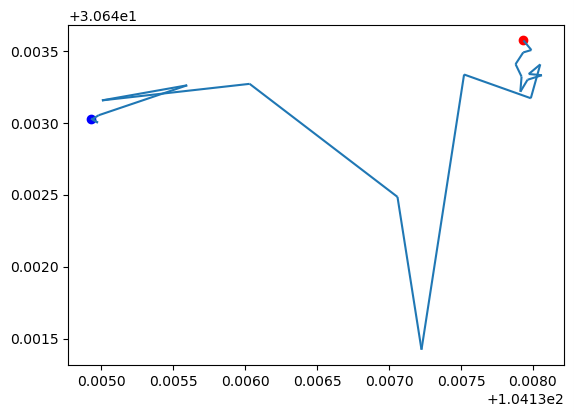
## 获取特定时间点的位置 t = datetime(2024,7,3,9,30,0) print(my_traj.get_position_at(t, method="nearest")) print(my_traj.get_position_at(t, method="interpolated")) print(my_traj.get_position_at(t, method="ffill")) # from the previous row print(my_traj.get_position_at(t, method="bfill")) # from the following row point = my_traj.get_position_at(t, method="interpolated") ax = my_traj.plot() gpd.GeoSeries(point).plot(ax=ax, color='red', markersize=100)
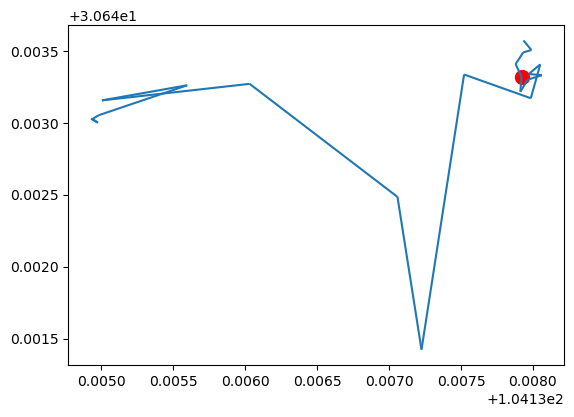
## 获取特定时间区间的位置 segment = my_traj.get_segment_between(datetime(2024,7,3,9,10,0), datetime(2024,7,3,9,30,0)) print(segment) ax = my_traj.plot() segment.plot(ax=ax, color='red', linewidth=5)
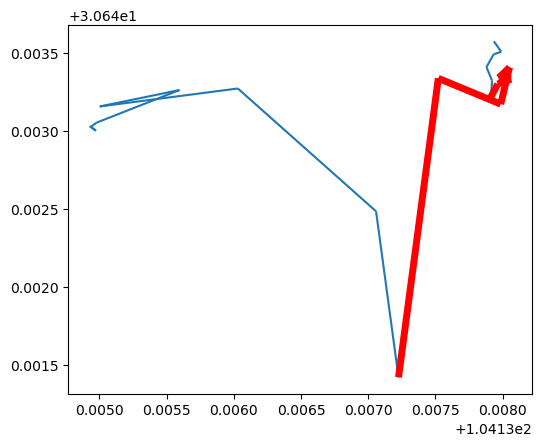
## 获取特定区域内的轨迹 from shapely.geometry import Polygon xmin, xmax, ymin, ymax = 104.135, 104.137, 30.642, 30.643 polygon = Polygon([(xmin, ymin), (xmin, ymax), (xmax, ymax), (xmax, ymin), (xmin, ymin)]) intersections = my_traj.clip(polygon) ax = my_traj.plot() gpd.GeoSeries(polygon).plot(ax=ax, color='lightgray') intersections.plot(ax=ax, color='red', linewidth=5, capstyle='round')
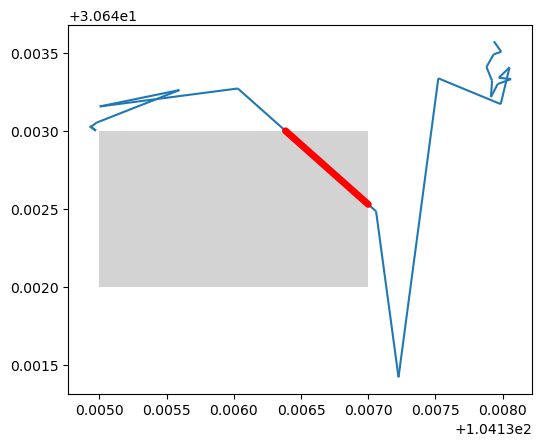
## 返回 GeoDataFrame
driver_tc.to_point_gdf()
driver_tc.to_line_gdf()
driver_tc.to_traj_gdf(wkt=True) # 生成wkt格式的聚合
# 聚合数据
driver_tc.add_speed(overwrite=True,units=("km", "h"))
driver_tc.to_traj_gdf(agg={'speed':['min', 'max','mode']})
# 导出数据
export_gdf = driver_tc.to_traj_gdf(agg={'speed':['min', 'max','mode']})
export_gdf.to_file("temp.gpkg", layer='trajectories', driver="GPKG")
gpd.read_file('temp.gpkg').plot()
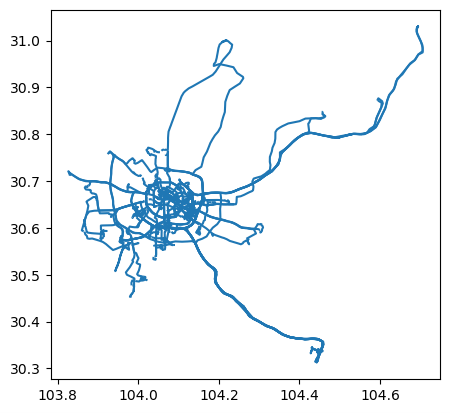
## 数据准备
my_traj.add_speed(overwrite=True,units=("km", "h"))
my_traj.plot(column='speed', vmax=20, linewidth=5, capstyle='round', figsize=(9,3), legend=True )
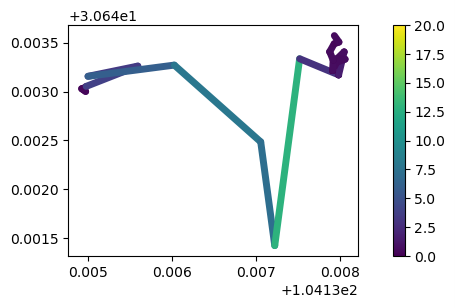
## 根据观测数据中的时间间隙对轨迹进行分割
split = mpd.ObservationGapSplitter(my_traj).split(gap=timedelta(minutes=1))
split.to_traj_gdf()
fig, axes = plt.subplots(nrows=1, ncols=len(split), figsize=(19,4))
for i, traj in enumerate(split):
traj.plot(ax=axes[i], linewidth=5.0, capstyle='round', column='speed', vmax=20)
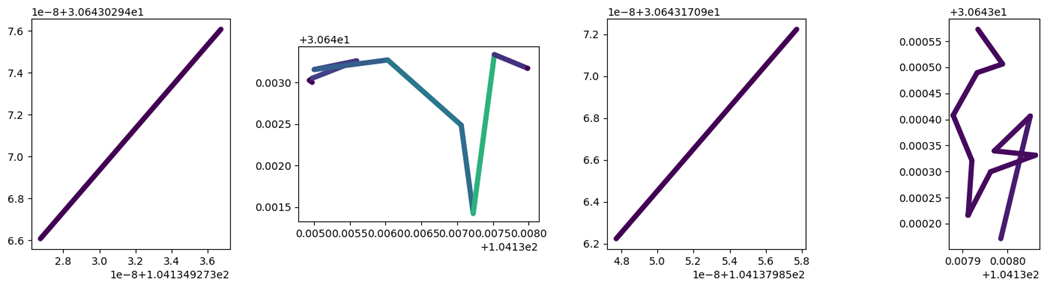
## 根据停留点(长时间停留的点)对轨迹数据进行分割
split = mpd.StopSplitter(my_traj).split(max_diameter=10, min_duration=timedelta(minutes=1), min_length=20)
split.to_traj_gdf()
fig, axes = plt.subplots(nrows=1, ncols=len(split), figsize=(19,4))
for i, traj in enumerate(split):
traj.plot(ax=axes[i], linewidth=5.0, capstyle='round', column='speed', vmax=20)
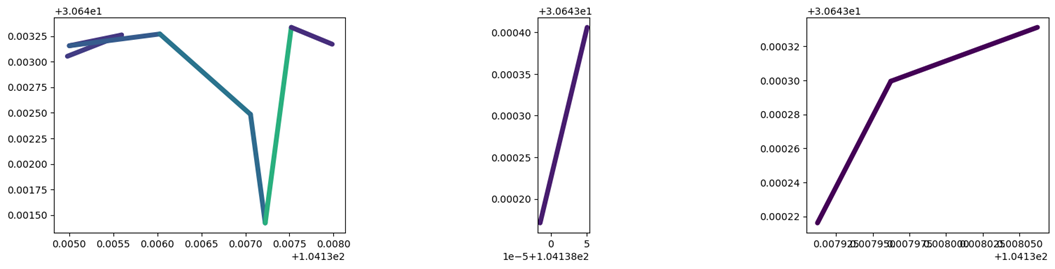
## 根据速度阈值对轨迹数据进行分割
split = mpd.SpeedSplitter(my_traj).split(speed=0, duration=timedelta(minutes=1))
split.to_traj_gdf()
fig, axes = plt.subplots(nrows=1, ncols=len(split), figsize=(19,4))
for i, traj in enumerate(split):
traj.plot(ax=axes[i], linewidth=5.0, capstyle='round', column='speed', vmax=20)
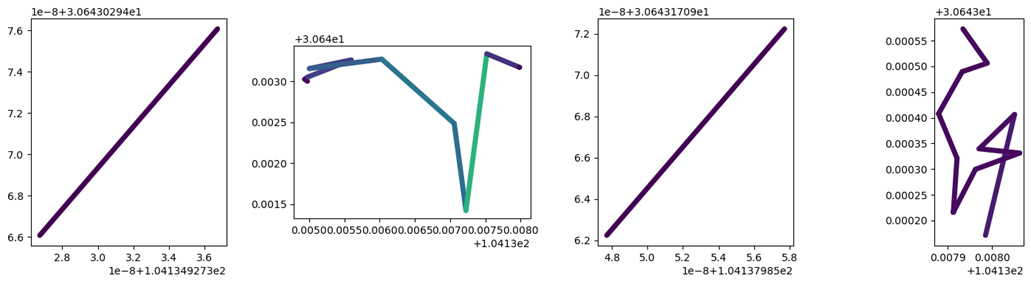
## 展示原始轨迹
plot_defaults = {'linewidth':5, 'capstyle':'round', 'figsize':(9,3), 'legend':True}
my_traj.add_speed(overwrite=True,units=("km", "h"))
my_traj.plot(column='speed', vmax=20, **plot_defaults)
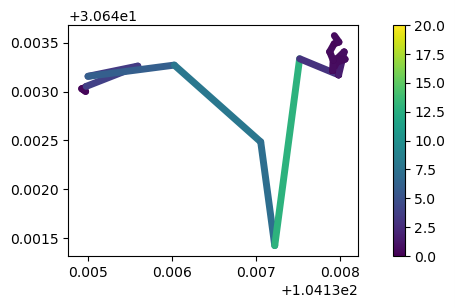
## 使用 Douglas-Peucker 算法对轨迹数据进行简化 dp_generalized = mpd.DouglasPeuckerGeneralizer(my_traj).generalize(tolerance=0.0001) dp_generalized.plot(column='speed', vmax=20, **plot_defaults)
print('Original length: %s'%(my_traj.get_length()))
print('Generalized length: %s'%(dp_generalized.get_length()))
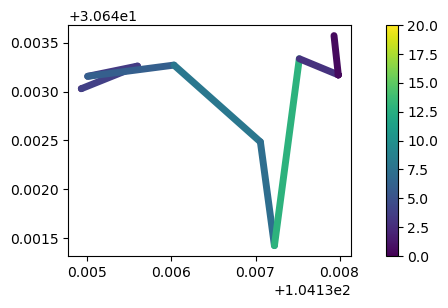
## 根据最小时间间隔对轨迹数据进行简化
time_generalized = mpd.MinTimeDeltaGeneralizer(my_traj).generalize(tolerance=timedelta(minutes=3))
time_generalized.plot(column='speed', vmax=20, **plot_defaults)
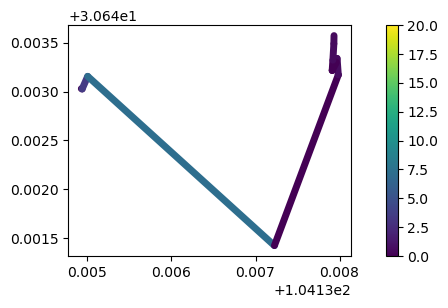
## 通过时间比率算法对轨迹数据进行简化 tdtr_generalized = mpd.TopDownTimeRatioGeneralizer(my_traj).generalize(tolerance=0.001) fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(19,4)) tdtr_generalized.plot(ax=axes[0], column='speed', vmax=20, **plot_defaults) dp_generalized.plot(ax=axes[1], column='speed', vmax=20, **plot_defaults)

fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(19,4)) tdtr_generalized.plot(ax=axes[0], column='speed', vmax=20, **plot_defaults) time_generalized.plot(ax=axes[1], column='speed', vmax=20, **plot_defaults)

split = mpd.ObservationGapSplitter(my_traj).split(gap=timedelta(minutes=1))
smooth = mpd.KalmanSmootherCV(split).smooth(process_noise_std=0.1, measurement_noise_std=10)
hvplot_defaults = {'tiles':'CartoLight', 'frame_height':320, 'frame_width':320, 'cmap':'Viridis', 'colorbar':True}
kwargs = {**hvplot_defaults, 'line_width':4}
(split.hvplot(title='Original Trajectories', **kwargs) + smooth.hvplot(title='Smooth Trajectories', **kwargs))
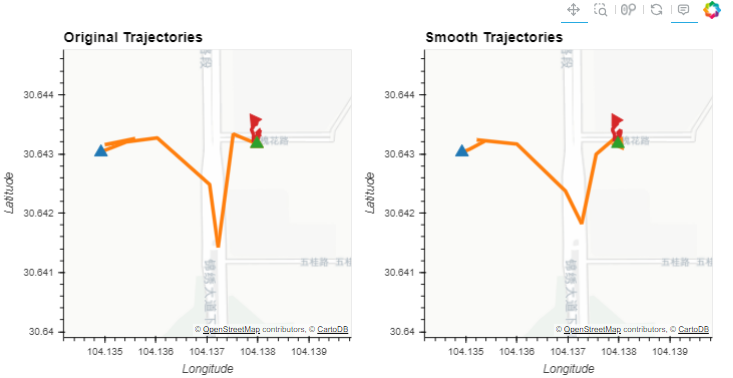
kwargs = {**hvplot_defaults, 'c':'speed', 'line_width':7, 'clim':(0,20)}
(split.trajectories[1].hvplot(title='Original Trajectory', **kwargs) + smooth.trajectories[1].hvplot(title='Smooth Trajectory', **kwargs))
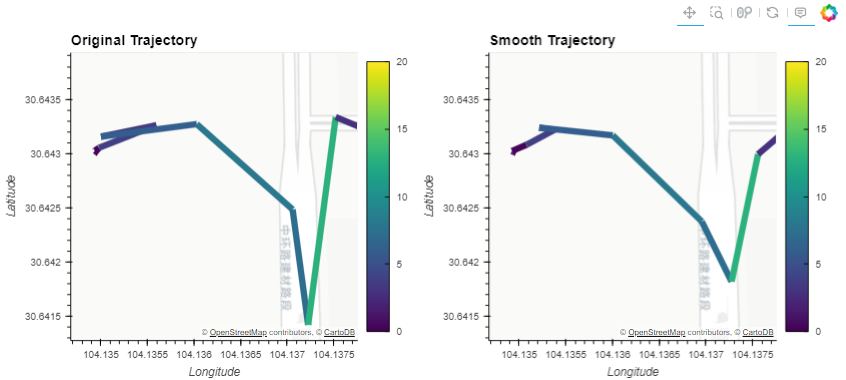
traj = split.trajectories[1]
cleaned = traj.copy()
cleaned = mpd.OutlierCleaner(cleaned).clean(alpha=2)
smoothed = mpd.KalmanSmootherCV(cleaned).smooth(process_noise_std=0.1, measurement_noise_std=10)
(traj.hvplot(title='Original Trajectory', **kwargs) +
cleaned.hvplot(title='Cleaned Trajectory', **kwargs) +
smoothed.hvplot(title='Cleaned & Smoothed Trajectory', **kwargs))
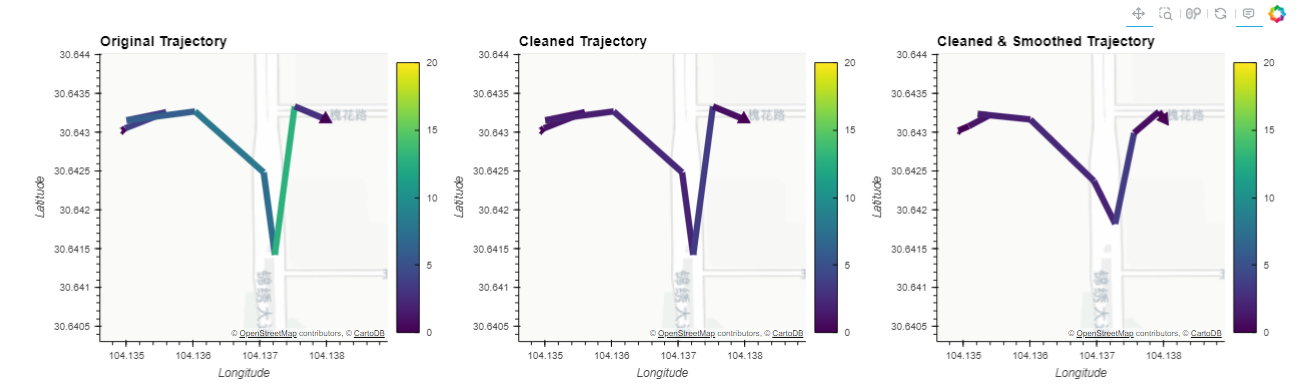
## 查看数据
driver_tc.explore(column="session_id", cmap="plasma", style_kwds={"weight": 4})
## 根据最小距离间隔对轨迹数据进行简化
generalized = mpd.MinDistanceGeneralizer(driver_tc).generalize(tolerance=100)
generalized.to_traj_gdf()
## 对轨迹进行聚合操作
aggregator = mpd.TrajectoryCollectionAggregator(
generalized,
max_distance=1000,
min_distance=100,
min_stop_duration=timedelta(minutes=10),
)
## 提取显著点
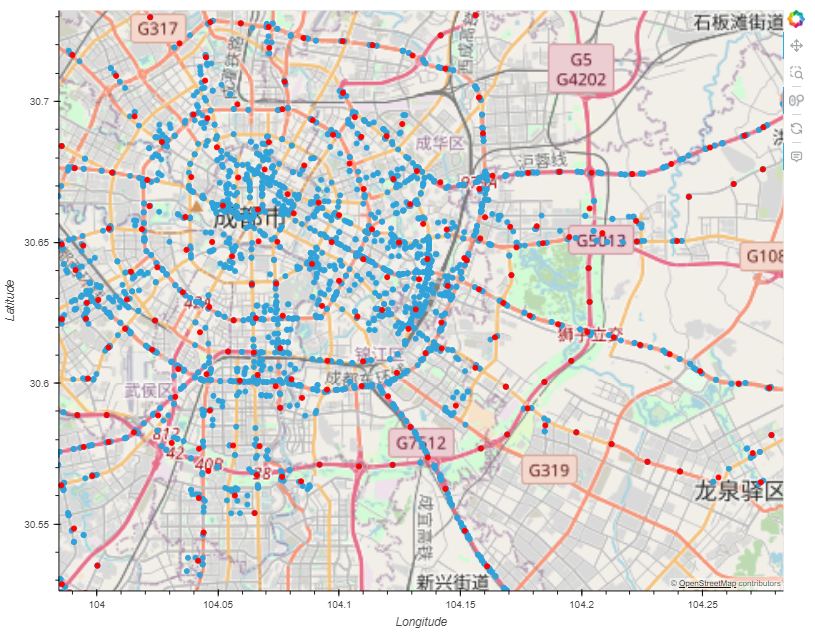
pts = aggregator.get_significant_points_gdf()
pts.hvplot(geo=True, tiles="OSM")
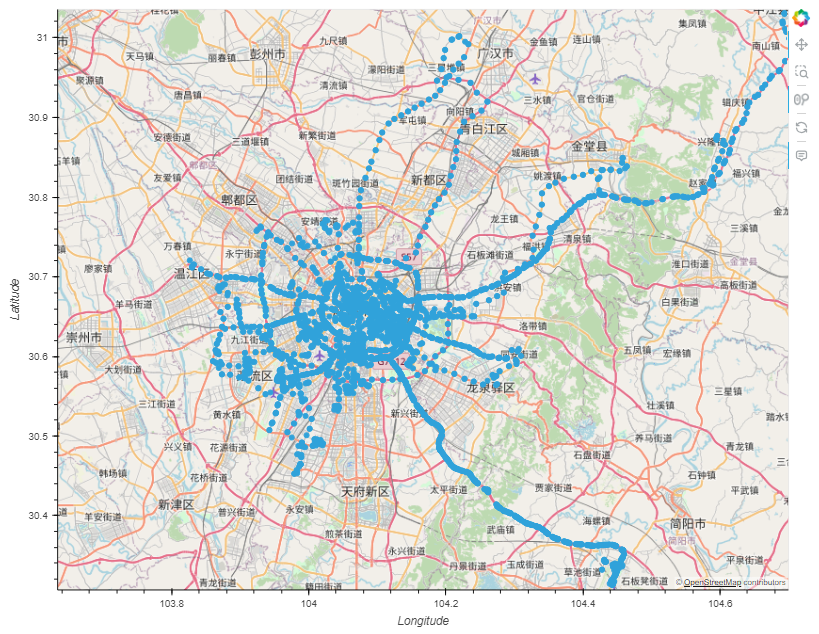
## 获取聚合轨迹的簇 clusters = aggregator.get_clusters_gdf() (pts.hvplot(geo=True, tiles="OSM") * clusters.hvplot(geo=True, color="red"))
## 使用folium绘制
# m = pts.explore(marker_kwds={"radius": 3}, name="Significant points")
# clusters.explore(m=m, color="red", marker_kwds={"radius": 3}, name="Cluster centroids")
# folium.TileLayer("CartoDB positron").add_to(m)
# folium.LayerControl().add_to(m)
# m
## 获取聚合后的轨迹数据的流动
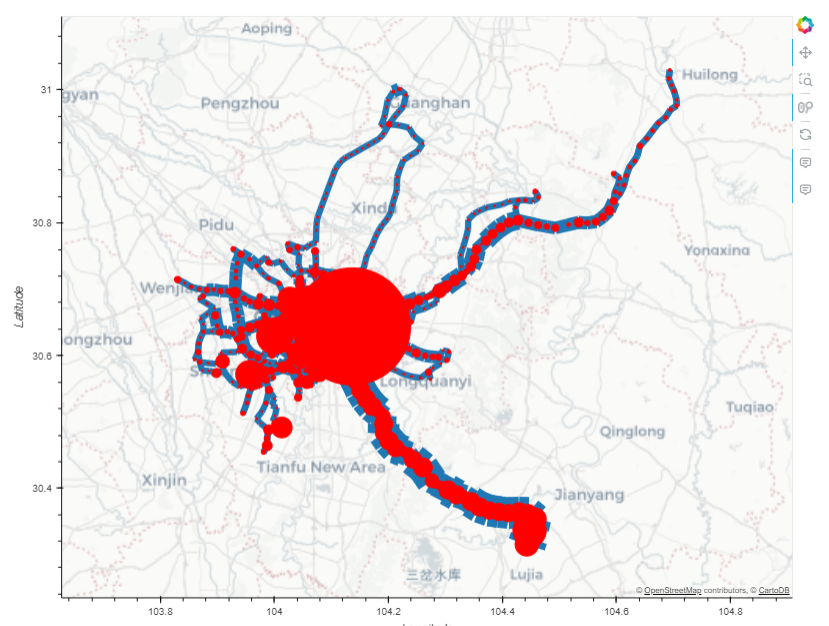
flows = aggregator.get_flows_gdf()
(flows.hvplot(geo=True, hover_cols=["weight"], line_width=dim("weight") * 7, color="#1f77b3",tiles="CartoLight") * clusters.hvplot(geo=True, color="red", size=dim("n")))
## 使用Folium绘制
# m = flows.explore(style_kwds={"weight": 5},name="Flows")
# clusters.explore( m=m,color="red",style_kwds={"style_function": lambda x: {"radius": x["properties"]["n"]}}, name="Clusters")
# folium.TileLayer("OpenStreetMap").add_to(m)
# folium.LayerControl().add_to(m)
# m
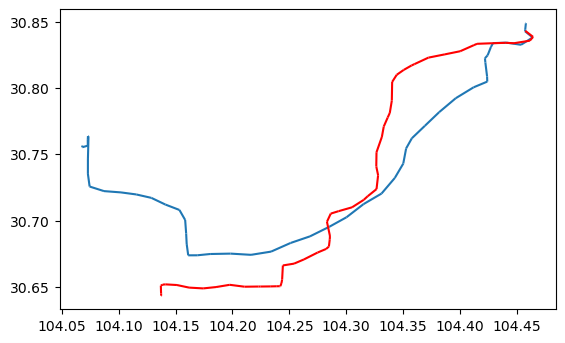
## 选择2个轨迹 my_traj = driver_tc.trajectories[3] toy_traj = driver_tc.trajectories[1] ## 呈现数据 ax = my_traj.plot() toy_traj.plot(ax=ax, color='red')
## 计算记录
print(f'Distance: {toy_traj.distance(my_traj)} meters') # 返回最短距离
print(f'Hausdorff distance: {toy_traj.hausdorff_distance(my_traj):.2f} meters') # 返回Hausdorff距离
Hausdorff距离可以理解为:对于集合A 中的每个点,计算它到集合B的最近距离,然后在这些距离中找到最大值;反过来对于集合 B 中的每个点,计算它到集合A 的最近距离,然后在这些距离中找到最大值。Hausdorff距离是这两个最大值中的较大者。
参考链接: