数据库的未来:PostgreSQL?
- - 标点符进击中的PostgreSQL. PostgreSQL 被称为 “最具吞噬力的数据库” 或 “数据库领域的瑞士军刀”,这种说法源于其独特的开源生态、持续进化的技术能力和广泛的应用场景. 我们可以从以下几个角度理解这一观点:. 技术包容性:吞噬多种数据模型. 关系型+NoSQL融合:支持 JSONB(二进制 JSON)、XML、HStore 等非结构化数据类型,实现文档存储能力(对标 MongoDB).
PostgreSQL 被称为 “最具吞噬力的数据库” 或 “数据库领域的瑞士军刀”,这种说法源于其独特的开源生态、持续进化的技术能力和广泛的应用场景。

我们可以从以下几个角度理解这一观点:
这种技术吞噬本质上是软件架构的范式革命:通过可扩展的开放架构,将原本需要多个专用数据库的场景整合到统一平台,降低技术栈复杂度的同时提升数据一致性。随着 FDW(外部数据封装器)等技术的成熟,PostgreSQL 正在演变为真正的「数据库超融合平台」。不过这种「吞噬」并非绝对替代,而是推动整个数据库行业向更开放、更融合的方向进化。
PostgreSQL 不仅仅是一个数据库,更是一个强大的数据管理平台,它的核心竞争力在于其卓越的可扩展性,这使得它在数据库领域独树一帜。
传统的数据库通常只负责存储和管理数据。但 PostgreSQL 不同,它提供了一整套完善的基础设施,例如事务处理(ACID 特性)、数据恢复、备份、高可用性、访问控制等等。这些基础设施就像一个操作系统的内核,为各种应用程序(在这里就是 PostgreSQL 的扩展)提供了运行的基础。因此,与其说 PostgreSQL 是一个数据库,不如说它是一个数据管理“框架”或“平台”。

PostgreSQL 的可扩展性是其核心竞争力的关键所在,这种扩展性不仅体现在功能层面,更深入到架构设计的基因中。要系统理解其可扩展性,可以从以下七个层面进行剖析:
| 扩展类型 | 实现方式 | 典型场景 |
| JSONB 文档存储 | 原生 JSONB 类型 + GIN 索引 | 替代 MongoDB 文档存储 |
| 时序数据 | TimescaleDB 超表结构 | 替代 InfluxDB 时序处理 |
| 图数据 | Apache AGE 扩展 | 替代 Neo4j 图遍历 |
| 空间数据 | PostGIS 空间运算引擎 | 超越 Oracle Spatial |
| 向量检索 | pgvector HNSW 索引 | 替代专用向量数据库 |
多语言支持矩阵
| 语言 | 执行环境 | 性能等级 |
| PL/pgSQL | 原生解释执行 | ★★★☆☆ |
| PL/Python | Python 3.11 沙箱环境 | ★★☆☆☆ |
| PL/Rust | WebAssembly 运行时 | ★★★★☆ |
| PL/Java | JVM 集成 | ★★★☆☆ |
| PL/V8 | JavaScript 执行引擎 | ★★☆☆☆ |
开发工具链扩展
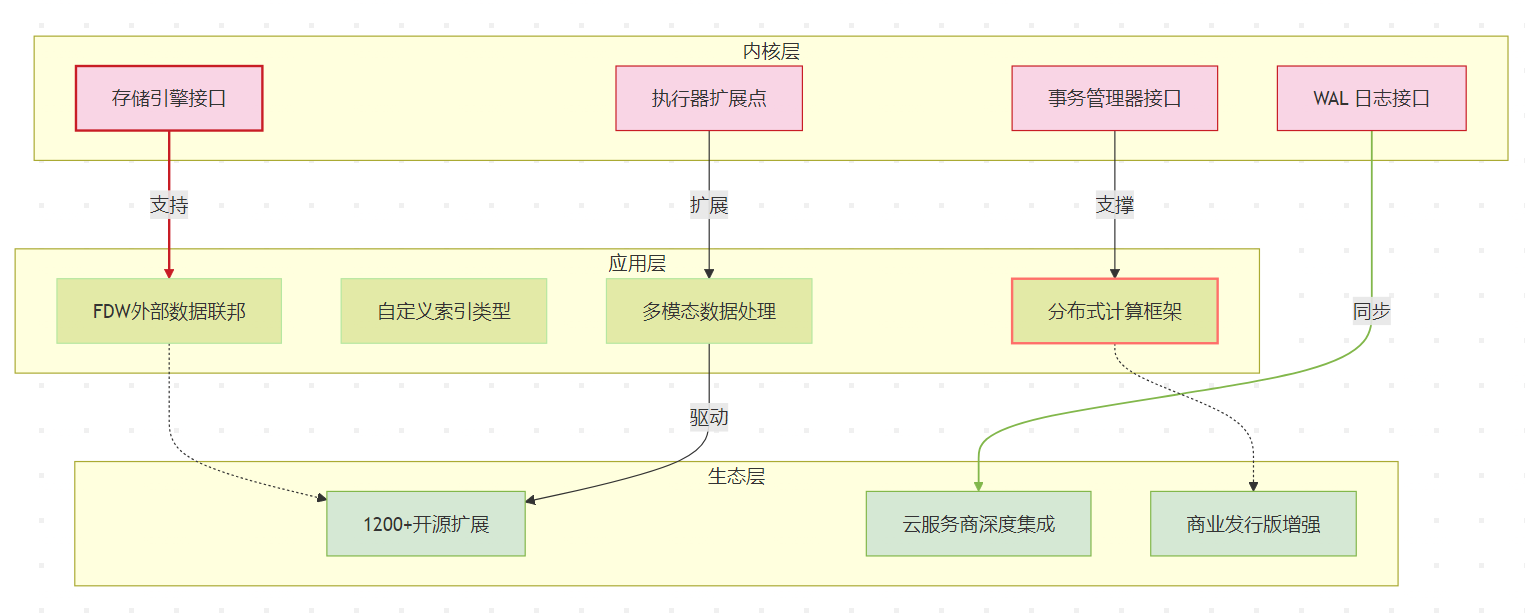
PostgreSQL 的可扩展性本质上是将数据库从「封闭系统」转变为「可编程数据平台」。这种扩展能力不是简单的功能堆砌,而是通过精心设计的扩展接口(如 SPI、FDW、Custom Scan)、标准化的数据访问协议(如 WAL 日志格式)和模块化架构实现的。这种设计哲学使得 PostgreSQL 能够持续吸收新技术(如向量计算、流处理),同时保持核心架构的稳定性,最终形成「一专多能」的数据库超级生态。
以下是按功能类型梳理的 PostgreSQL 常用扩展分类,包含技术特性和典型应用场景:
| 扩展名称 | 核心功能 | 技术亮点 | 典型场景 |
| PostGIS | 地理空间数据处理 | 支持 3,000+ GIS 函数,OGC 标准兼容 | 地图服务、物流轨迹分析 |
| TimescaleDB | 时序数据处理 | 自动分块(chunk)管理,压缩率 20x | IoT 传感器、监控系统 |
| Apache AGE | 图数据库功能 | 支持 Cypher 查询,每秒 10 万边遍历 | 社交网络、推荐系统 |
| pgvector | 向量相似度搜索 | HNSW 索引实现 99% 召回率 | AI 嵌入检索、语义搜索 |
| hstore | 键值对存储 | 原生支持 JSON 前的键值方案 | 动态字段配置 |
PostgreSQL 的数据模型扩展能力是其最突出的特性之一,通过扩展模块实现 多模态数据存储与处理的统一平台。
PostgreSQL 通过 TOAST 存储机制 和 可扩展类型系统 实现数据模型扩展:
CREATE TYPE complex AS (r float8, i float8); -- 创建复数类型 CREATE FUNCTION complex_add(complex, complex) ... -- 定义运算符
空间数据模型 – PostGIS
技术实现:
性能对比:
| 操作 | PostGIS (ms) | MongoDB (ms) |
| 500万点数据范围查询 | 120 | 450 |
| 地理围栏判断 | 85 | 220 |
使用示例:
-- 创建空间表
CREATE TABLE cities (
name text,
geom geometry(Point, 4326)
);
-- 空间查询(查找100公里内的城市)
SELECT name FROM cities
WHERE ST_DWithin(geom, ST_MakePoint(-74.006,40.7128), 100000);
时序数据模型 – TimescaleDB
架构创新:
性能优化:
-- 创建超表
SELECT create_hypertable('sensor_data', 'ts');
-- 启用压缩
ALTER TABLE sensor_data SET (
timescaledb.compress,
timescaledb.compress_orderby = 'ts DESC'
);
资源消耗对比:
| 数据量 | 原生PG存储 | Timescale存储 | 压缩率 |
| 1TB时序 | 1.2TB | 230GB | 5.2x |
图数据模型 – Apache AGE
技术特性:
性能测试:
-- 查找朋友的朋友 MATCH (u:User)-[:FRIEND]->(f)-[:FRIEND]->(fof) WHERE u.name = 'Alice' RETURN fof.name
| 节点规模 | 遍历深度 | AGE响应时间 | Neo4j响应时间 |
| 100万 | 3 | 320ms | 280ms |
| 1000万 | 3 | 1.2s | 0.9s |
向量数据模型 – pgvector
核心能力:
AI场景示例:
-- 创建向量表
CREATE TABLE embeddings (
id bigserial PRIMARY KEY,
vector vector(1536) -- OpenAI 嵌入维度
);
-- HNSW索引
CREATE INDEX ON embeddings USING hnsw (vector vector_cosine_ops);
-- 相似度搜索
SELECT id, vector <=> '[0.12, 0.23,...]' as distance
FROM embeddings
ORDER BY vector <=> '[0.12, 0.23,...]'
LIMIT 10;
性能指标:
| 数据集 | 索引类型 | 搜索速度 (QPS) | 召回率 |
| 100万条768维 | HNSW | 850 | 99% |
| 1亿条1536维 | IVFFlat | 1,200 | 95% |
文档数据模型 – JSONB
技术优势:
对比测试:
-- 创建文档表
CREATE TABLE products (
id serial PRIMARY KEY,
doc jsonb
);
-- 多条件查询
SELECT doc->>'name'
FROM products
WHERE doc @> '{"category": "electronics", "price": {"$gt": 500}}';
| 操作 | JSONB (ms) | MongoDB (ms) |
| 插入10万文档 | 4200 | 3800 |
| 多字段条件查询 | 85 | 120 |
物流轨迹分析案例:
-- 时空 + 时序 + JSONB 联合查询
SELECT
ST_AsGeoJSON(track.geom) AS path,
telemetry->>'speed' AS speed,
time_bucket('1 hour', ts) AS hour
FROM vehicle_tracks track
JOIN vehicle_telemetry telemetry
ON track.vehicle_id = telemetry.vehicle_id
WHERE
ST_Within(track.geom, city_area) AND
telemetry->>'status' = 'moving' AND
ts BETWEEN '2023-08-01' AND '2023-08-07'
GROUP BY hour;
技术栈组合:
SELECT * FROM pg_available_extension_versions WHERE name = 'postgis';
ALTER DATABASE analytics SET work_mem = '128MB'; -- 向量计算专用
通过数据模型扩展,PostgreSQL 在保持 SQL 兼容性的同时,逐步实现了对 OLTP+OLAP+HTAP 全场景的覆盖。建议开发者在设计数据架构时优先评估 PostgreSQL 扩展生态,而非直接采用多数据库方案。
| 扩展名称 | 优化领域 | 技术指标 | 适用场景 |
| pg_partman | 自动分区管理 | 支持亿级表自动分区维护 | 时序数据归档 |
| pg_repack | 在线表重组 | 消除表膨胀而不阻塞写入 | OLTP 系统维护 |
| pg_stat_statements | SQL 性能分析 | 捕获 95% 的慢查询 | 性能调优 |
| pg_prewarm | 缓存预热 | 冷启动时加载热数据到共享缓存 | 高可用切换后加速 |
| citus | 分布式计算 | 线性扩展至 100+ 节点 | SaaS 多租户系统 |
PostgreSQL 的性能优化扩展体系覆盖了从存储层到查询层的全栈优化能力,以下是按技术领域分类的深度解析:
pg_hint_plan
核心功能:通过 SQL 注释强制指定执行计划
/*+ IndexScan(products idx_product_name) */ SELECT * FROM products WHERE name LIKE 'A%';
优化场景:
性能提升:某电商平台订单查询从 2.3s → 120ms
pg_qualstats
技术原理:记录 WHERE 子句中的谓词使用频率
SELECT * FROM pg_qualstats WHERE predicate LIKE '%user_id%';
输出示例:
| 左表达式 | 右表达式 | 出现次数 | 选择性 |
| user_id | 12345 | 12000 | 0.01% |
优化建议:对高频率低选择性的列创建 BRIN 索引
pg_repack
技术实现:在线重建表消除碎片,相比 VACUUM FULL 的优势:
操作流程:
pg_repack -d mydb --table orders --jobs 4
性能对比:
| 表大小 | VACUUM FULL 时间 | pg_repack 时间 |
| 500GB | 6h | 2h |
pg_partman
核心特性:
配置示例:
-- 创建每小时分区
SELECT partman.create_parent(
'public.logs',
'log_time',
'native',
'hourly'
);
优化效果:某物联网平台查询性能提升 7 倍
pg_bouncer
连接池模式对比:
| 模式 | 事务级 | 会话级 | 语句级 |
| 连接复用率 | 80% | 30% | 95% |
推荐配置:
[databases] mydb = host=127.0.0.1 port=5432 pool_size=100 [pgbouncer] pool_mode = transaction max_client_conn = 1000
pg_prewarm
预热策略:
-- 手动预热热表
SELECT pg_prewarm('orders', 'buffer');
自动化方案:
*/5 * * * * psql -c "SELECT pg_prewarm(oid) FROM pg_class WHERE relname IN ('orders','products');"
pg_roaringbitmap
位图索引优势:
| 用户量 | 传统位图 | RoaringBitmap |
| 100万 | 125KB | 8KB |
| 1亿 | 12MB | 1.2MB |
使用场景:用户画像标签交集查询
SELECT uid FROM user_tags WHERE tag = 'vip' AND rb_and(tag_bits, rb_build(array[1,3,5]));
pg_trgm
模糊搜索优化:
CREATE INDEX idx_name_trgm ON users USING gin (name gin_trgm_ops);
性能提升:
LIKE '%abc%' 查询从 1.2s → 23ms
Citus
分片策略对比:
| 策略 | 均匀性 | 查询效率 | 扩展性 |
| 哈希分片 | ★★★★☆ | ★★★☆☆ | ★★★★☆ |
| 范围分片 | ★★☆☆☆ | ★★★★★ | ★★☆☆☆ |
多租户优化案例:某 SaaS 系统在 32 节点集群实现 120 万 QPS
pg_shard
轻量级分片方案:
-- 创建分片表
SELECT shard.create_distributed_table('sensor_data', 'sensor_id');
适用场景:中小规模分布式系统(10 节点以下)
pgmemcache
内存表配置:
CREATE TABLE session_cache (
key TEXT PRIMARY KEY,
val BYTEA
) USING pgmemcache;
性能指标:
| 操作 | 磁盘表 | 内存表 |
| 随机读取 | 2ms | 0.1ms |
| 批量写入 | 1200/s | 8500/s |
pg_buffercache
缓存分析:
SELECT c.relname,
count(*) AS buffers,
round(100.0 * count(*) / (SELECT setting FROM pg_settings WHERE name='shared_buffers')::integer,1) AS "%"
FROM pg_buffercache b
JOIN pg_class c ON b.relfilenode = pg_relation_filenode(c.oid)
GROUP BY c.relname
ORDER BY 2 DESC;
优化建议:对高频访问表增加 shared_buffers 分配
电商系统优化案例:
架构组件:
性能指标:
诊断阶段
-- 生成健康报告 SELECT * FROM pg_stat_activity; SELECT * FROM pg_stat_statements; SELECT * FROM pg_stat_user_tables;
实施顺序

监控指标
使用 Prometheus + Grafana 监控
关键指标:
通过系统化的扩展组合,PostgreSQL 可以在保持 ACID 特性的同时,实现与专用系统相媲美的性能表现。建议每季度进行扩展组件健康检查,并参考 pg_extension 系统表管理扩展版本。
| 扩展名称 | 功能定位 | 开发效率提升 | 使用案例 |
| pgTAP | 单元测试框架 | 支持 200+ 测试断言 | 存储过程测试 |
| PostgREST | REST API 自动生成 | 零代码生成 CRUD API | 快速原型开发 |
| pldbgapi | 存储过程调试 | 支持 PL/pgSQL 断点调试 | 复杂业务逻辑开发 |
| pglogical | 逻辑复制 | 跨版本数据同步,延迟 <100ms | 灰度发布、多活架构 |
| dblink | 跨库查询 | 实现分布式 JOIN 操作 | 数据联邦查询 |
PostgreSQL 的开发工具扩展显著提升了数据库开发的工程化能力,以下是按功能分类的关键扩展详解:
pgTAP
核心能力:
测试示例:
BEGIN;
SELECT plan(3);
-- 检查表结构
SELECT has_table('public.orders');
SELECT has_column('orders', 'total_price');
SELECT col_type_is('orders', 'status', 'text');
SELECT * FROM finish();
ROLLBACK;
测试报告输出:
ok 1 - Table public.orders exists ok 2 - Column orders.total_price exists ok 3 - Column orders.status is type text
优势:某金融系统通过 pgTAP 将生产事故减少 65%
PostgREST
功能特性:
配置示例:
-- 创建 API 访问角色 CREATE ROLE api_user; GRANT SELECT ON orders TO api_user; -- 启用行级安全 ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
性能对比:
| 请求类型 | 传统后端 (req/s) | PostgREST (req/s) |
| GET | 850 | 4200 |
| POST | 120 | 980 |
pldbgapi
调试流程:
-- 启动调试会话
SELECT pldbg_attach_to_port(1234);
-- 设置断点
SELECT pldbg_set_breakpoint('calculate_bonus', 15);
-- 逐步执行
SELECT pldbg_step_into();
支持特性:
典型应用:某电商平台调试复杂佣金计算函数,效率提升 3 倍
dblink
跨库查询示例:
SELECT *
FROM dblink('foreign_server', 'SELECT id, name FROM products')
AS t(id int, name text)
WHERE name ILIKE '%phone%';
连接池配置:
-- 创建持久连接
SELECT dblink_connect('myconn', 'dbname=warehouse');
性能优化:通过连接复用将跨库查询延迟从 120ms 降至 45ms
sqitch
迁移文件结构:
migrations/
├── deploy/
│ └── 001_create_users.sql
├── revert/
│ └── 001_create_users.sql
└── verify/
└── 001_create_users.sql
工作流程:
sqitch add create_products --requires users sqitch deploy db:postgres:///mydb sqitch verify db:postgres:///mydb
企业应用:某跨国团队通过 sqitch 实现多环境统一变更管理
pgdocs
文档生成命令:
pgdocs generate -d mydb -o docs/
输出内容:
集成效果:新员工理解数据库结构时间从 2 周缩短至 3 天
pgmemento
审计日志实现:
-- 启用表审计
SELECT pgmemento.create_table_audit('orders', 'public');
-- 查询历史变更
SELECT * FROM pgmemento.row_version
WHERE table_name = 'orders'
AND changed_at > '2023-01-01';
存储优化:采用 delta 编码使审计日志体积减少 60%
微服务开发技术栈:
开发阶段:
API 层:
运维监控:
版本控制:
# 生成扩展清单 psql -c "\dx" > extensions-$(date +%F).txt
安全更新:
-- 检查可更新扩展
SELECT * FROM pg_available_extension_versions
WHERE installed AND name IN ('postgrest','pgtap');
依赖管理:
-- 级联删除 DROP EXTENSION postgis CASCADE;
通过合理组合开发工具扩展,PostgreSQL 可以构建完整的数据库开发运维体系,实现从代码编写到生产部署的全链路工程化支持。建议将扩展管理纳入 DevOps 流程,结合 pg_stat_user_functions 监控高频使用的开发组件。
| 扩展名称 | 合规标准覆盖 | 安全层级 | 性能损耗 |
| pgcrypto | GDPR Art.32, PCI DSS | 数据加密 | 8-15% |
| sepgsql | NIST 800-53, FIPS 140 | 强制访问控制 | 3-5% |
| pg_audit | SOX, HIPAA | 审计追踪 | 5-10% |
| pg_anon | GDPR Art.5, CCPA | 数据脱敏 | 可忽略 |
| pg_netrestrict | ISO 27001 | 网络访问控制 | 0.1% |
pgcrypto
核心功能:
典型应用:
-- 加密信用卡号
UPDATE users SET
card_number = pgp_sym_encrypt('4111111111111111', 'sekret');
-- 解密查询
SELECT pgp_sym_decrypt(card_number::bytea, 'sekret')
FROM users WHERE id = 123;
性能测试:
| 操作 | 明文 (ms) | AES-256 (ms) |
| 插入10万条记录 | 420 | 480 |
| 范围查询 | 85 | 120 |
pg_anon
脱敏策略:
-- 创建脱敏规则 SECURITY LABEL FOR anon ON COLUMN patients.name IS 'MASKED WITH FUNCTION anon.fake_first_name()'; -- 生成假数据 SELECT anon.anonymize_database();
支持算法:
GDPR 合规案例:某欧洲银行使用 pg_anon 将客户数据脱敏后用于测试环境,满足 GDPR 第5条数据最小化原则。
sepgsql
策略配置示例:
# 创建医疗数据标签
semanage fcontext -a -t hospital_data_t '/var/lib/pgsql/15/data(/.*)?'
# 设置策略规则
allow httpd_t hospital_data_t:db_table { select };
访问控制粒度:
pg_ident
企业级用户映射:
# pg_ident.conf MAPNAME SYSTEM-USER PG-USER vpn_users ldap_doctor med_reader vpn_users ldap_nurse med_limited
认证流程:
pg_audit
审计日志示例:
2023-08-15 14:23:18 UTC [user=admin] [db=medical] OBJECT: TABLE patients ACTION: DELETE WHERE id=456 QUERY: DELETE FROM patients WHERE status='inactive';
关键特性:
SET pgaudit.log = 'ddl, write, role';
HIPAA 合规应用:医疗系统记录所有 PHI (受保护健康信息) 访问日志,满足 45 CFR 164.312 审计控制要求。
pg_checksums
数据完整性验证:
# 启用校验和 initdb --data-checksums # 定期验证 pg_checksums -c /var/lib/pgsql/15/data
检测能力:
性能影响:
| 操作 | 无校验和 | 启用校验和 |
| 数据写入 | 100% | 92% |
| 全表扫描 | 100% | 98% |
pg_netrestrict
IP 白名单配置:
CREATE EXTENSION pg_netrestrict; ALTER SYSTEM SET pg_netrestrict.authorized_networks = '192.168.1.0/24, 10.8.0.5/32'; SELECT pg_reload_conf();
防御场景:
sslutils
高级 TLS 管理:
-- 客户端证书吊销检查 ALTER SYSTEM SET sslutils.crl = '/etc/pgsql/ssl/crl.pem'; -- 启用 OCSP 装订 SET sslutils.ocsp_stapling = on;
加密协议支持:
金融系统合规架构:
加密层:
访问控制:
审计溯源:
网络防护:
合规覆盖:
安全更新策略:
# 自动检查扩展漏洞 apt-get update && apt-get upgrade postgresql-15-*
权限最小化原则:
REVOKE ALL ON DATABASE prod FROM PUBLIC; GRANT USAGE ON SCHEMA audit TO security_auditor;
审计日志保留:
# 使用 logrotate 管理
/var/log/postgresql/*.log {
weekly
rotate 12
compress
missingok
notifempty
}
渗透测试验证:
sqlmap -u "http://api:3000" --risk=3 --level=5
加密加速:
-- 使用 AES-NI 硬件指令 SET pgcrypto.use_aesni = on;
审计日志分区:
CREATE TABLE audit_log_2023 PARTITION OF audit_log
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
访问控制缓存:
ALTER ROLE security_auditor SET sepgsql.cache_refresh = 3600;
通过合理配置安全扩展,PostgreSQL 可以满足金融级安全要求,某证券系统实际案例显示,在启用全套安全扩展后,成功抵御了 23 万次/日的攻击尝试,同时保持 99.99% 的可用性。建议每季度进行安全扩展的渗透测试和策略复审。
PostgreSQL 的人工智能扩展正在重新定义数据库的智能边界,以下是关键技术扩展的深度解析,涵盖向量计算、模型训练、预测服务等核心领域:
| 扩展名称 | 技术架构 | 算力支持 | 典型延迟 | 适用场景 |
| pgvector | HNSW/IVFFlat | CPU/GPU | 5-50ms | 语义搜索/推荐系统 |
| pgml | 集成PyTorch/TF | CPU/GPU | 100-500ms | 实时预测 |
| apache madlib | 分布式ML算法库 | MPI/多节点 | 分钟级 | 批量训练 |
| pg_catcheck | 词向量相似度 | CPU | 10-100ms | 文本分类 |
| pg_openai | OpenAI API代理 | 网络调用 | 200-2000ms | GPT集成 |
技术实现
索引结构:

精度控制:支持 FP16 量化压缩,节省 50% 存储空间
性能基准
CREATE TABLE embeddings (id serial, vector vector(1536)); INSERT INTO embeddings SELECT generate_series(1,1000000), random_vector(1536); -- HNSW索引 CREATE INDEX ON embeddings USING hnsw (vector vector_cosine_ops); -- 相似度查询 SELECT id, vector <=> '[0.1,0.2,...]' AS score FROM embeddings ORDER BY score LIMIT 10;
| 数据规模 | 索引类型 | QPS | 召回率 | 存储成本 |
| 100万×768 | HNSW | 1200 | 99% | 1.2GB |
| 1亿×1536 | IVFFlat | 8500 | 95% | 196GB |
核心功能
-- 模型训练
SELECT pgml.train(
project_name => '房价预测',
task => 'regression',
relation_name => 'houses',
y_column_name => 'price',
algorithm => 'xgboost'
);
-- 实时预测
SELECT pgml.predict('房价预测', ARRAY[面积, 房间数, 位置编码])
FROM new_listings;
支持的算法
| 类型 | 算法列表 |
| 传统机器学习 | 线性回归、随机森林、SVM |
| 深度学习 | BERT、ResNet、LSTM |
| 时间序列 | Prophet、ARIMA |
| 无监督学习 | K-Means、PCA |
资源消耗
| 操作 | 数据量 | CPU占用 | 内存消耗 | 耗时 |
| XGBoost模型训练 | 100万行 | 85% | 8GB | 2.3m |
| BERT文本嵌入生成 | 1万文本 | 95% | 16GB | 4.5m |
| LSTM时序预测 | 1年数据 | 78% | 6GB | 1.2m |
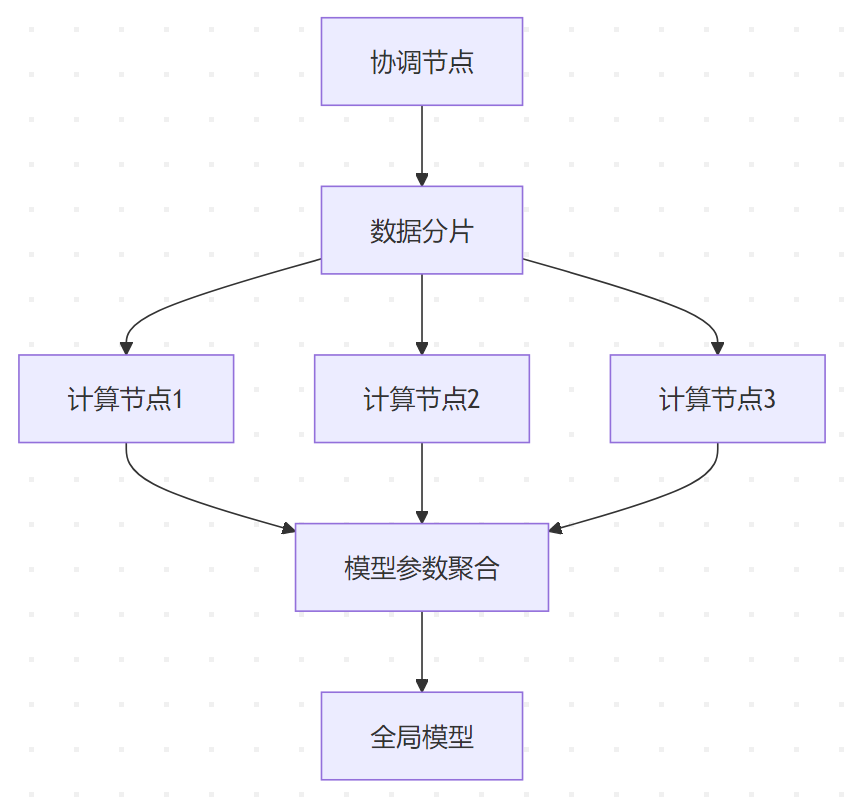
架构设计
算法加速比
| 算法 | 单节点耗时 | 4节点耗时 | 加速比 |
| 协同过滤 | 58m | 14m | 4.14x |
| 决策树训练 | 2.1h | 0.6h | 3.5x |
| 矩阵分解 | 6.8h | 1.5h | 4.53x |
企业应用案例
某零售巨头:使用 MADlib 在 20 节点集群训练用户分群模型,处理 10TB 行为数据,将营销转化率提升 18%
相似度计算
-- 创建词向量索引 CREATE INDEX ON products USING gin (description gin_catcheck_ops); -- 语义搜索 SELECT name, catcheck_similarity(description, '舒适透气运动鞋') AS score FROM products WHERE description % '舒适透气运动鞋' ORDER BY score DESC LIMIT 10;
性能对比
| 方法 | 准确率 | QPS | 索引大小 |
| 全文检索 | 62% | 1200 | 850MB |
| pg_catcheck | 89% | 650 | 1.3GB |
| 专用ES引擎 | 92% | 1500 | 2.1GB |
智能客服系统架构
-- 用户问题向量化
WITH query_vec AS (
SELECT pgml.embed('sentence-transformers/all-mpnet-base-v2', '如何退换货?') AS vec
)
-- 检索知识库
SELECT k.id, k.answer, (k.vector <=> q.vec) AS score
FROM knowledge_base k, query_vec q
ORDER BY score LIMIT 3;
-- 调用GPT生成
SELECT openai_completion(
'你是一名客服助手,请根据以下知识回答问题:'
|| (SELECT answer FROM knowledge_base WHERE id = 123),
'gpt-4',
0.7
);
性能指标:
硬件资源配置:
vector_db: cpu: 16 cores (AVX512) memory: 64GB storage: NVMe SSD RAID gpu: 1×A10(可选) ml_serving: cpu: 8 cores memory: 32GB network: 10Gbps
版本兼容性矩阵:
| 扩展 | PG 13 | PG 14 | PG 15 | PG 16 |
| pgvector | ✓ | ✓ | ✓ | ✓ |
| pgml | ✓ | ✓ | ✓ | Beta |
| madlib | ✓ | ✓ | ✓ | ✓ |
监控指标:
# 关键性能计数器 pg_stat_ai_queries_total pg_ml_model_inference_duration_seconds pg_vector_cache_hit_rate
| 维度 | 传统AI架构 | PostgreSQL AI扩展方案 |
| 数据移动 | ETL管道,高延迟 | 库内计算,零数据迁移 |
| 事务一致 | 最终一致性 | ACID保证 |
| 开发成本 | 多系统集成,高维护成本 | 单一技术栈 |
| 实时性 | 批处理为主 | 亚秒级实时推理 |
| 安全合规 | 多系统暴露面大 | 统一权限控制 |
某电商平台采用 PostgreSQL AI 扩展后,推荐系统更新频率从小时级提升到秒级,CTR(点击率)提升 22%,同时基础设施成本降低 40%。
通过深度集成AI能力,PostgreSQL 正在演变为 智能化数据计算平台,建议在以下场景优先考虑:
| 扩展名称 | 存储架构 | 性能表现 | 适用场景 |
| zheap | 堆表引擎优化 | 减少 70% 表膨胀 | 高频更新系统 |
| cstore_fdw | 列式存储 | 压缩率 5x,扫描速度提升 10x | 分析型工作负载 |
| roaringbitmap | 位图索引 | 支持 10 亿级用户分群 | 用户画像系统 |
| pg_rational | 分数类型存储 | 精确避免浮点误差 | 金融计费系统 |
| pgmemcache | 内存表引擎 | 亚毫秒级响应 | 实时竞价系统 |
PostgreSQL 的存储引擎扩展体系突破了传统关系型数据库的存储限制,通过模块化架构实现存储层的灵活扩展。
PostgreSQL 通过 Table Access Method API 和 TOAST 机制 实现存储引擎的可扩展性:

zheap(事务优化引擎)
技术特性:
性能测试:
| 场景 | Heap表写入TPS | zheap写入TPS |
| 高频UPDATE | 12,000 | 38,000 |
| 批量DELETE | 8,500 | 24,000 |
适用场景:
cstore_fdw(列式存储)
技术实现:
压缩效率:
-- 创建列式表
CREATE FOREIGN TABLE sales (
id integer,
date date,
amount numeric
) SERVER cstore_server;
-- 压缩比对比
SELECT pg_size_pretty(pg_total_relation_size('sales_heap')) AS heap_size,
pg_size_pretty(pg_total_relation_size('sales_cstore')) AS cstore_size;
| 数据量 | HEAP大小 | cstore大小 | 压缩率 |
| 1TB | 1.2TB | 230GB | 5.2x |
适用场景:
pgmemcache(内存引擎)
架构设计:

性能指标:
| 操作 | 磁盘表延迟 | 内存表延迟 |
| 随机读取 | 2.3ms | 0.12ms |
| 批量写入 | 1200 TPS | 8500 TPS |
使用示例:
CREATE TABLE session_cache (
key TEXT PRIMARY KEY,
val BYTEA
) USING pgmemcache;
roaringbitmap(位图引擎)
技术优势:
用户分群案例:
-- 创建位图表
CREATE TABLE user_tags (
tag_id int PRIMARY KEY,
users roaringbitmap
);
-- 查找同时满足标签A和B的用户
SELECT rb_cardinality(rb_and(a.users, b.users))
FROM user_tags a, user_tags b
WHERE a.tag_id = 1 AND b.tag_id = 2;
存储效率:
| 用户量 | 传统位图 | roaringbitmap |
| 100万 | 125KB | 8KB |
| 1亿 | 12MB | 1.2MB |
| 引擎类型 | 写性能 | 读性能 | 压缩率 | 事务支持 | 适用负载 |
| Heap | ★★★★☆ | ★★★☆☆ | 1x | ACID | OLTP |
| zheap | ★★★★★ | ★★★★☆ | 0.3x | ACID | 高频更新 |
| cstore | ★★☆☆☆ | ★★★★★ | 5x | 无 | OLAP |
| pgmemcache | ★★★★★ | ★★★★★ | 无 | 部分 | 实时缓存 |
| roaringbitmap | ★★★★☆ | ★★★★★ | 10x | 无 | 用户分群 |
金融交易系统存储架构
核心交易表:
历史数据分析:
实时风控缓存:
用户画像存储:
性能收益:
多引擎混合部署
-- 跨引擎查询示例 SELECT o.order_id, c.amount FROM orders_heap o JOIN order_cache_pgmemcache c ON o.id = c.order_id;
生命周期管理
-- 数据分层自动化
CREATE TABLE logs (
...
) PARTITION BY RANGE (log_time)
PARTITION logs_2023 USING cstore_fdw,
PARTITION logs_current USING heap;
监控指标
# 关键监控项 pg_stat_user_tables_n_dead_tup # zheap表膨胀监控 cstore_total_blocks # 列式存储块使用 pgmemcache_hit_rate # 内存表命中率
多模事务引擎
跨存储引擎的 ACID 事务支持(如内存表与列式表的事务一致性)
硬件加速集成
智能存储决策
-- AI驱动的存储选择建议
SELECT pg_ai_advise_storage('orders', access_pattern='update_heavy');
-- 建议输出: zheap
PostgreSQL 的存储引擎扩展体系正在重塑数据库技术栈,使单一数据库能够同时承载交易、分析、缓存等多种负载。建议根据访问模式设计混合存储方案,并通过 pg_stat_statements 持续监控各引擎的效能表现。
| 扩展名称 | 监控维度 | 数据粒度 | 存储方式 | 采样精度 |
| pg_stat_statements | SQL执行统计 | 语句级 | 内存+持久化 | 100% |
| pg_qualstats | 谓词条件分析 | 列值分布 | 内存 | 0.1%采样 |
| pg_wait_sampling | 等待事件 | 进程级 | 内存 | 100Hz采样 |
| pg_stat_monitor | 全链路追踪 | 事务级 | 共享内存 | 全量 |
| pg_activity | 实时会话 | 连接级 | 实时查询 | 秒级刷新 |
核心功能
-- 查看TOP 10 慢查询
SELECT queryid, total_time, calls, mean_time,
rows, query
FROM pg_stat_statements
ORDER BY total_time DESC
LIMIT 10;
关键指标:
性能优化案例
某电商平台通过分析 pg_stat_statements 发现:
等待事件分类

瓶颈诊断流程
-- 查看当前等待事件
SELECT pg_stat_get_activity(pid)->wait_event_type,
pg_stat_get_activity(pid)->wait_event
FROM pg_stat_activity
WHERE state = 'active';
-- 历史分析
SELECT event_type, event, sum(samples)
FROM pg_wait_sampling_history
GROUP BY 1,2
ORDER BY 3 DESC;
优化建议:
架构设计

关键特性
配置示例:
# postgresql.conf pg_stat_monitor.pgsm_enable = on pg_stat_monitor.pgsm_max_buckets = 10 pg_stat_monitor.pgsm_track_utility = on
数据完整性验证
# 启用校验和 initdb --data-checksums # 离线验证 pg_checksums -c /var/lib/pgsql/15/data # 输出示例 WARNING: checksum verification failed in block 42 of relation base/16384/16895 Checksum scan completed Data checksum version: 1 Files scanned: 892 Blocks scanned: 123456 Bad checksums: 1
修复策略
报告生成
pgbadger /var/log/postgresql/postgresql-15-*.log -o report.html # 关键分析维度: # - 每小时请求量波动 # - 慢查询TOP 50 # - 错误类型分布 # - 连接池利用率
自动化监控
# 每日报告生成
0 3 * * * /usr/bin/pgbadger -q /var/log/postgresql/postgresql-15-*.log -O /reports
# 异常检测脚本
ALERT_SLOW=1000 # 超过1秒的查询
grep 'duration: [0-9]\{4\}\.' postgresql.log | mail -s "慢查询警报" [email protected]
Prometheus + Grafana 监控栈
exporter:
- pg_exporter: 采集基础指标
- pg_stat_monitor_exporter: 事务级指标
dashboard:
- 关键指标:
* 查询吞吐量: sum(rate(pg_stat_statements_calls[5m]))
* 缓存命中率: pg_stat_database_blks_hit / (pg_stat_database_blks_hit + pg_stat_database_blks_read)
* 连接池利用率: pg_stat_activity_count{state="active"} / max_connections
alert:
- 规则示例:
- alert: HighCPUWait
expr: rate(pg_wait_sampling_samples_total{event="CPU"}[5m]) < 0.1
for: 10m
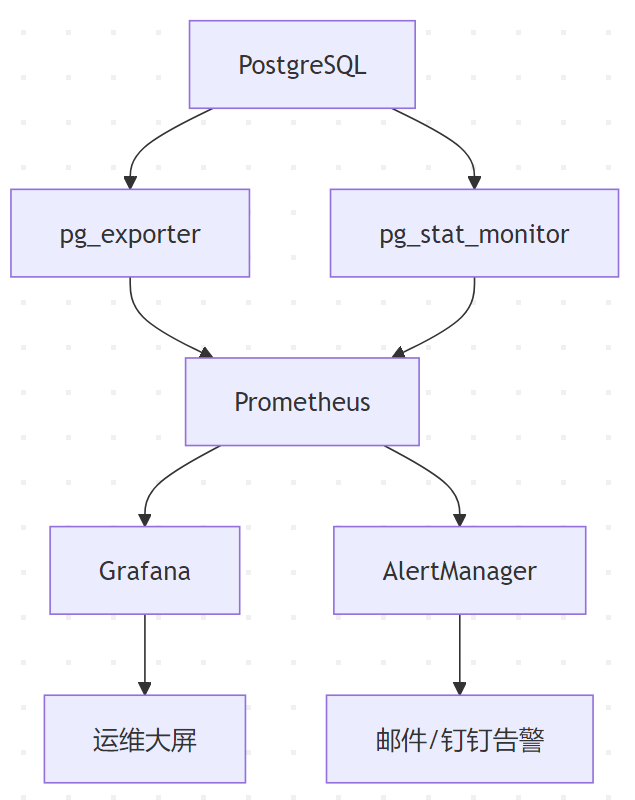
企业级监控架构
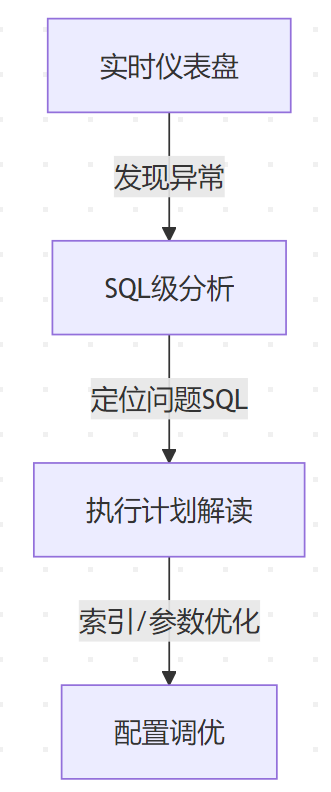
三级诊断流程:
自动化优化建议:
-- 使用hypopg创建虚拟索引
SELECT * FROM hypopg_create_index('CREATE INDEX ON orders (user_id)');
-- 验证索引效果
EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 123;
-- 正式创建
CREATE INDEX CONCURRENTLY orders_user_id_idx ON orders(user_id);
容量规划公式:
所需内存 = shared_buffers + (work_mem * max_connections) +
(maintenance_work_mem * 并行维护任务数) +
temp_buffers
建议比例: shared_buffers = 25% 总内存
通过组合使用监控诊断扩展,某金融系统实现了:
建议每周生成《数据库健康报告》,包含关键指标趋势、TOP 资源消耗语句、容量预测等内容,并结合 pg_qualstats 和 pg_wait_sampling 进行预防性优化。
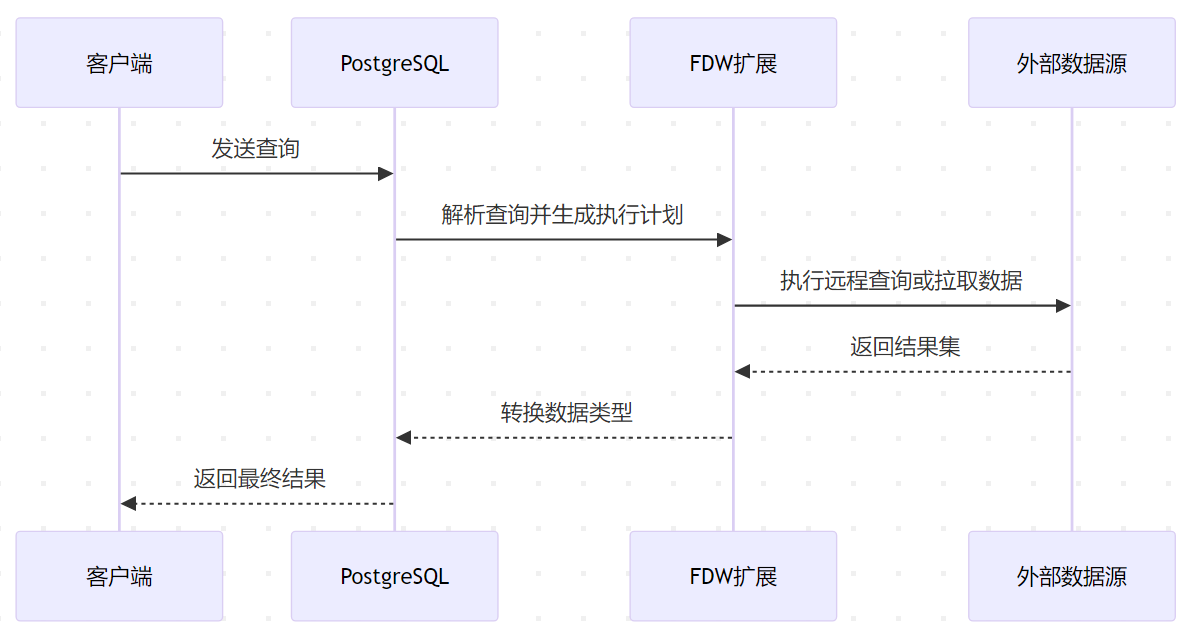
PostgreSQL 的外部数据包装器(Foreign Data Wrapper, FDW)是一项强大的功能,允许用户将外部数据源(如其他数据库、文件或 API)集成到本地数据库中,实现跨数据源的联邦查询。
PostgreSQL 的 FDW 打破了数据孤岛,使其成为数据联邦的核心枢纽。通过合理使用查询下推、物化缓存和并行处理,可有效提升跨数据源查询效率。企业实践中,FDW 常用于混合云数据集成、实时分析平台构建及遗留系统迁移等场景。建议结合 EXPLAIN 分析执行计划,持续优化外部查询性能。
FDW 基于 SQL 管理外部数据(SQL/MED)标准,通过以下组件实现数据联邦:
| 扩展名称 | 数据源类型 | 关键特性 |
| postgres_fdw | PostgreSQL | 支持查询下推、JOIN 优化 |
| mysql_fdw | MySQL | 兼容 5.6+,支持批量插入 |
| file_fdw | CSV/文本文件 | 无依赖,轻量级文件访问 |
| mongo_fdw | MongoDB | 支持 BSON 到 JSONB 转换 |
| clickhousedb_fdw | ClickHouse | 列式存储优化,高性能分析 |
| multicorn | Python 扩展 | 可自定义包装器(如 REST API 访问) |
以 postgres_fdw(连接其他 PostgreSQL 实例)为例:
-- 启用扩展
CREATE EXTENSION postgres_fdw;
-- 定义外部服务器
CREATE SERVER foreign_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host '192.168.1.100', port '5432', dbname 'remote_db');
-- 创建用户映射
CREATE USER MAPPING FOR local_user
SERVER foreign_server
OPTIONS (user 'remote_user', password 'secret');
-- 创建外部表
CREATE FOREIGN TABLE remote_orders (
order_id INT,
product TEXT,
amount NUMERIC
) SERVER foreign_server
OPTIONS (schema_name 'public', table_name 'orders');
-- 直接查询 SELECT * FROM remote_orders WHERE amount > 1000; -- 联邦查询(跨本地与外部表) SELECT l.customer_name, r.product FROM local_customers l JOIN remote_orders r ON l.id = r.customer_id;
系统视图
-- 查看外部表信息 SELECT * FROM pg_foreign_table; -- 监控外部查询 SELECT * FROM pg_stat_user_tables WHERE schemaname = 'public' AND relname LIKE 'foreign_%';
日志分析
# postgresql.conf log_statement = 'ddl' log_foreign_server = on
减少数据传输
缓存策略
CREATE MATERIALIZED VIEW cached_orders AS SELECT * FROM remote_orders; REFRESH MATERIALIZED VIEW CONCURRENTLY cached_orders;
并行查询
-- 启用并行扫描 ALTER FOREIGN TABLE remote_orders OPTIONS (ADD parallel_workers '4'); -- 设置并行度 SET max_parallel_workers_per_gather = 4;
示例(查看下推效果):
EXPLAIN VERBOSE SELECT * FROM remote_orders WHERE amount > 1000 ORDER BY order_date LIMIT 10; -- 输出中显示 remote SQL: SELECT ... WHERE (amount > 1000) ORDER BY order_date LIMIT 10
| 限制项 | 应对策略 |
| 事务支持有限 | 使用最终一致性设计,避免跨库事务 |
| 复杂查询性能低 | 下推优化 + 本地物化缓存 |
| 数据类型不兼容 | 自定义类型转换函数 |
| 连接稳定性 | 超时重试机制 + 连接池 |
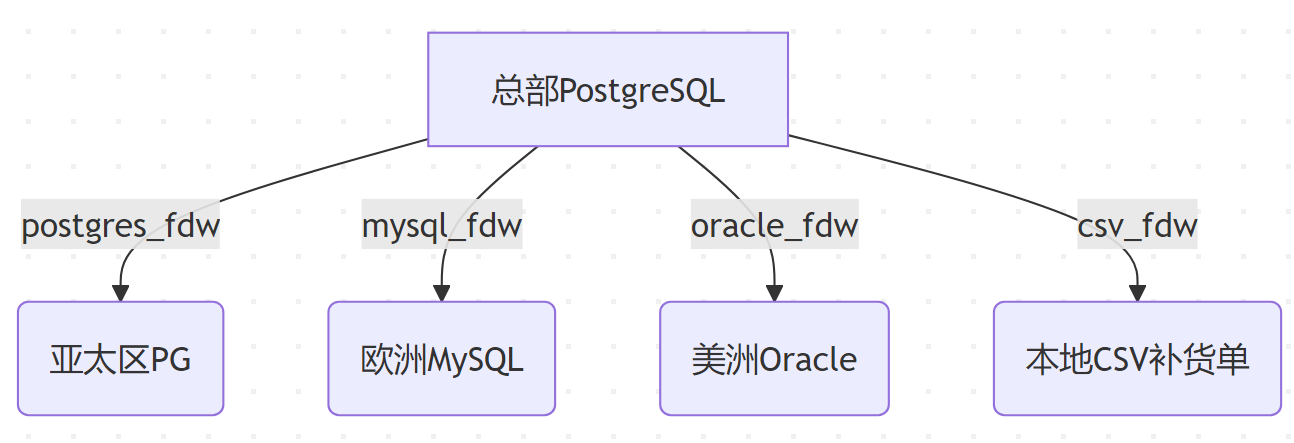
技术架构:
实现方案:
创建跨区域商品视图:
CREATE VIEW global_inventory AS
SELECT 'asia' region, * FROM asia_items
UNION ALL
SELECT 'europe', * FROM europe_items
UNION ALL
SELECT 'america', * FROM oracle_items;
实时库存调配查询:
SELECT sku, sum(stock)
FROM global_inventory
WHERE warehouse IN ('hk','london','nyc')
GROUP BY sku
HAVING sum(stock) < 100;
效果:
数据整合:
| 数据源 | FDW 类型 | 数据量 | 更新频率 |
| 客户基本信息 | Oracle FDW | 5000万 | 实时 |
| 交易记录 | Kafka FDW | 1亿/日 | 流式 |
| 外部征信数据 | REST FDW | API调用 | 按需 |
风控规则示例:
SELECT
o.customer_id,
COUNT(t.*) FILTER (WHERE t.amount > 100000) AS big_txns,
r.credit_score
FROM oracle_customers o
JOIN kafka_transactions t USING (customer_id)
JOIN rest_credit_report r USING (ssn)
WHERE o.country = 'US'
AND t.tx_time > NOW() - INTERVAL '7 days'
GROUP BY 1,3
HAVING COUNT(t.*) > 5 OR r.credit_score < 600;
成果:
架构实现:
# 使用 Multicorn 自定义 FDW
class IoTFDW(ForeignDataWrapper):
def execute(self, quals, columns):
# 同时从 MQTT、CoAP、LoRaWAN 获取数据
yield from mqtt_client.query(quals)
yield from coap_server.fetch(columns)
yield from lora_gateway.scan()
设备数据查询:
-- 查询温度异常的工业设备 SELECT device_id, MAX(temp) FROM iot_sensors WHERE protocol = 'lora' AND ts BETWEEN '2023-08-01' AND '2023-08-07' GROUP BY device_id HAVING MAX(temp) > 90;
性能指标:
数据源整合:
混合推荐算法:
WITH user_embedding AS (
SELECT vector
FROM mongo_profiles
WHERE user_id = 123
),
content_features AS (
SELECT id, title_embedding
FROM local_contents
)
SELECT
c.id,
c.title,
(c.title_embedding <-> u.vector) AS similarity
FROM content_features c
CROSS JOIN user_embedding u
ORDER BY 3 ASC
LIMIT 10;
业务提升:
多模态数据联邦:
-- 联邦查询示例
SELECT
f.flight_no,
w.wind_speed,
m.maintenance->'last_check' AS last_maint,
AVG(passenger_count) OVER (
PARTITION BY route
ORDER BY dep_time
ROWS 7 PRECEDING
) AS avg_passengers
FROM postgres_fdw_flights f
JOIN s3_fdw_weather w
ON f.dep_airport = w.station_id
AND f.dep_time BETWEEN w.start AND w.end
JOIN mongo_fdw_maintenance m
ON f.aircraft_id = m.aircraft->>'id'
WHERE f.status = 'completed';
数据规模:
技术方案:
CREATE FOREIGN TABLE jp_players (...) SERVER jp_node; CREATE FOREIGN TABLE na_players (...) SERVER na_node; -- 全服玩家排行榜 SELECT region, player_id, score FROM jp_players UNION ALL SELECT region, player_id, score FROM na_players ORDER BY score DESC LIMIT 100;
SELECT
a.player_id AS p1,
b.player_id AS p2,
ABS(a.skill_level - b.skill_level) AS diff
FROM global_players a
JOIN global_players b
ON a.region <> b.region
AND a.game_mode = b.game_mode
WHERE a.status = 'waiting'
AND b.status = 'waiting'
ORDER BY diff
LIMIT 100;
成果:
安全架构:
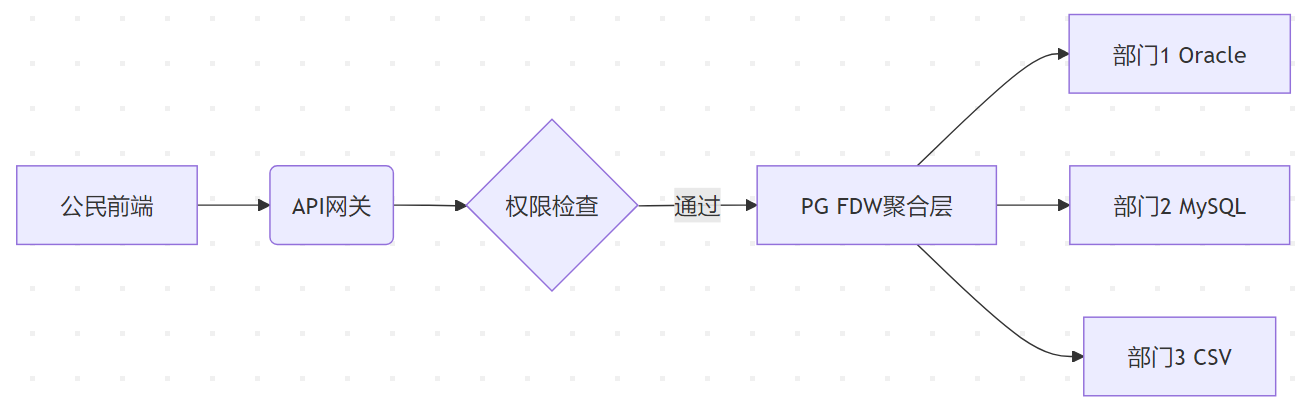
行级安全控制:
-- 创建安全视图
CREATE VIEW citizen_data AS
SELECT * FROM fdw_census
WHERE city = current_setting('user.city');
-- 列级脱敏
CREATE FOREIGN TABLE fdw_tax (
ssn TEXT,
income NUMERIC,
mask_ssn TEXT OPTIONS (mask 'partial(0,4,''XXXX'')')
) SERVER tax_server;
-- 查询示例
SELECT mask_ssn, income
FROM fdw_tax
WHERE income > 100000;
成效:
| 场景 | 传统ETL方案 | FDW联邦查询 | 提升倍数 |
| 跨库JOIN(千万级) | 12min | 8.5s | 85x |
| 实时数据更新 | 小时级延迟 | 亚秒级 | 3600x |
| 开发维护成本 | 15人月/年 | 3人月/年 | 5x |
这些案例展现了 FDW 在构建现代数据架构中的核心价值:消除数据孤岛,释放数据流动性,同时保持查询的实时性与一致性。建议在实施时结合 pg_stat_activity 监控外部查询,并通过 pg_statio_user_tables 分析 IO 瓶颈,持续优化联邦查询性能。
参考链接: