DeepWiki 一个常用 RAG 应用的开发流程
- - crossoverJie's Blog上一篇文章: 大模型应用开发必需了解的基本概念 分享了关于 LLM 大模型应用开发的一些基础知识,本文乘热打铁,借助一个真实的大模型应用来分析下其中的流程. 这里我们还是以 deepwiki-open为例进行分析. 通过这个截图可以知道它的主要功能:一键把任意 GitHub/GitLab/Bitbucket 仓库生成“可浏览的交互式 Wiki”.
上一篇文章: 大模型应用开发必需了解的基本概念 分享了关于 LLM 大模型应用开发的一些基础知识,本文乘热打铁,借助一个真实的大模型应用来分析下其中的流程
这里我们还是以 deepwiki-open为例进行分析。
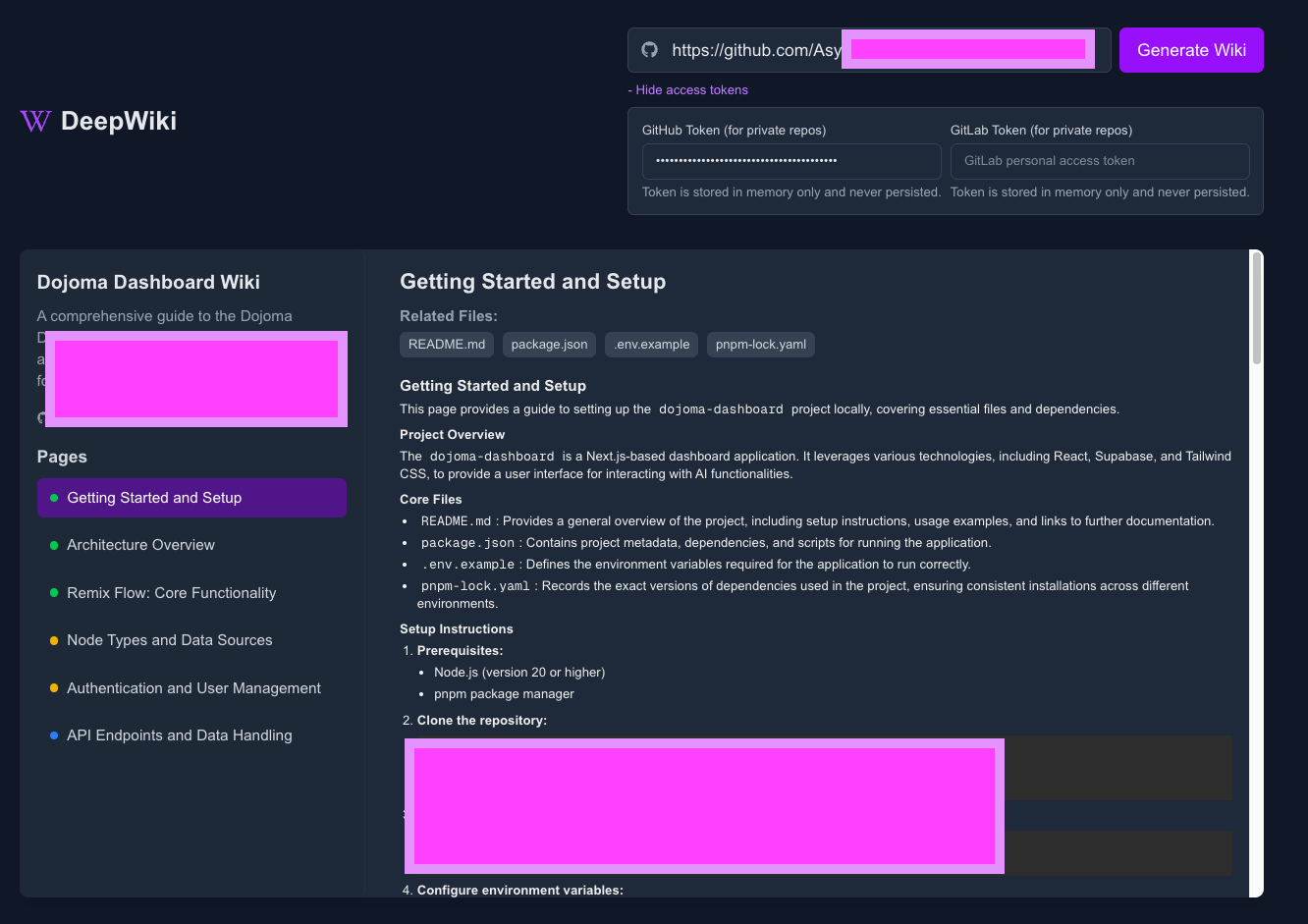
通过这个截图可以知道它的主要功能:一键把任意 GitHub/GitLab/Bitbucket 仓库生成“可浏览的交互式 Wiki”
要使用也很简单,我们用一个兼容 openai 的 key 就可以使用了。
在 .env 里配置下相关环境变量:
1 | |
同时我们在 generator.json 里为 openai 新增一个你所使用的模型:
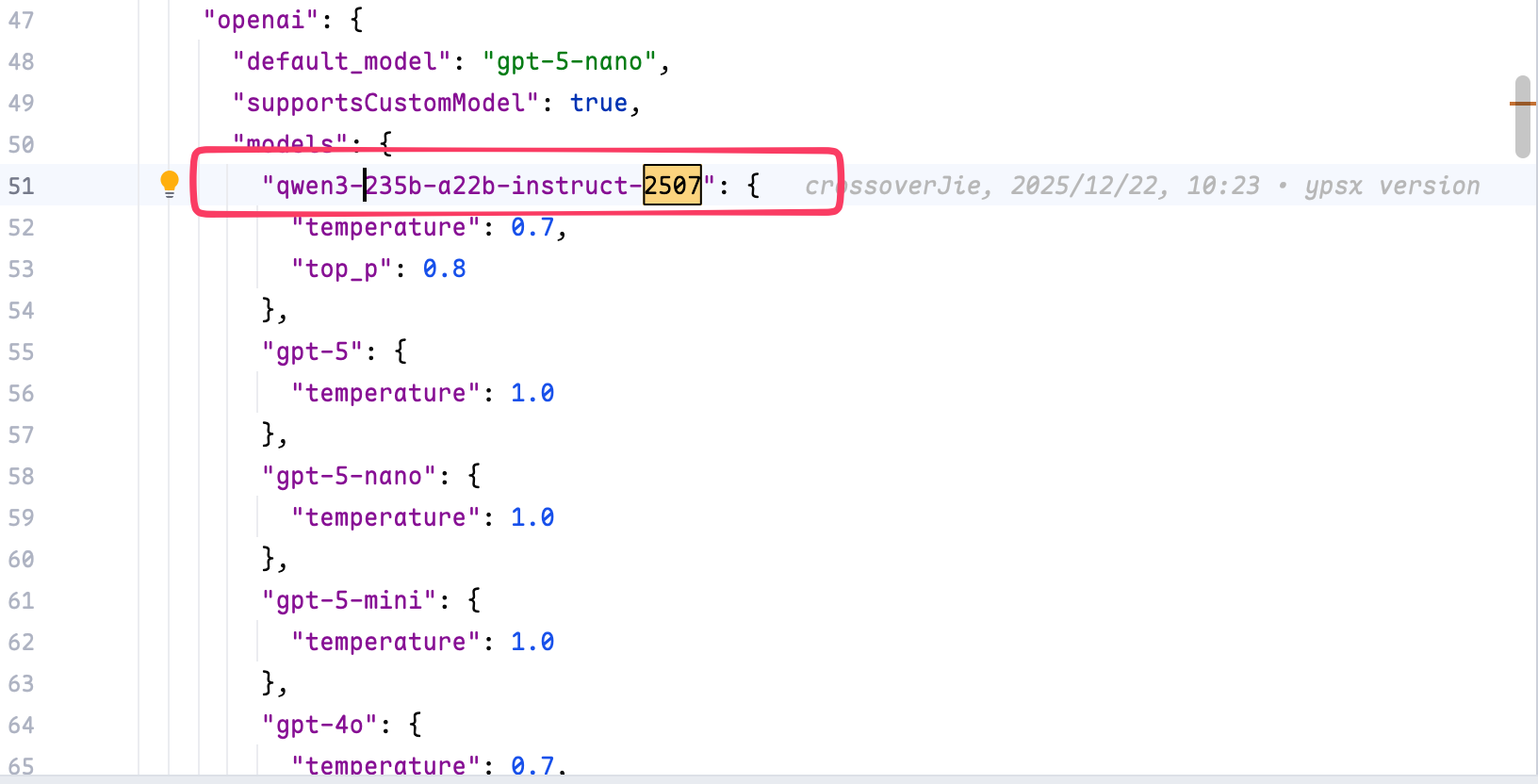
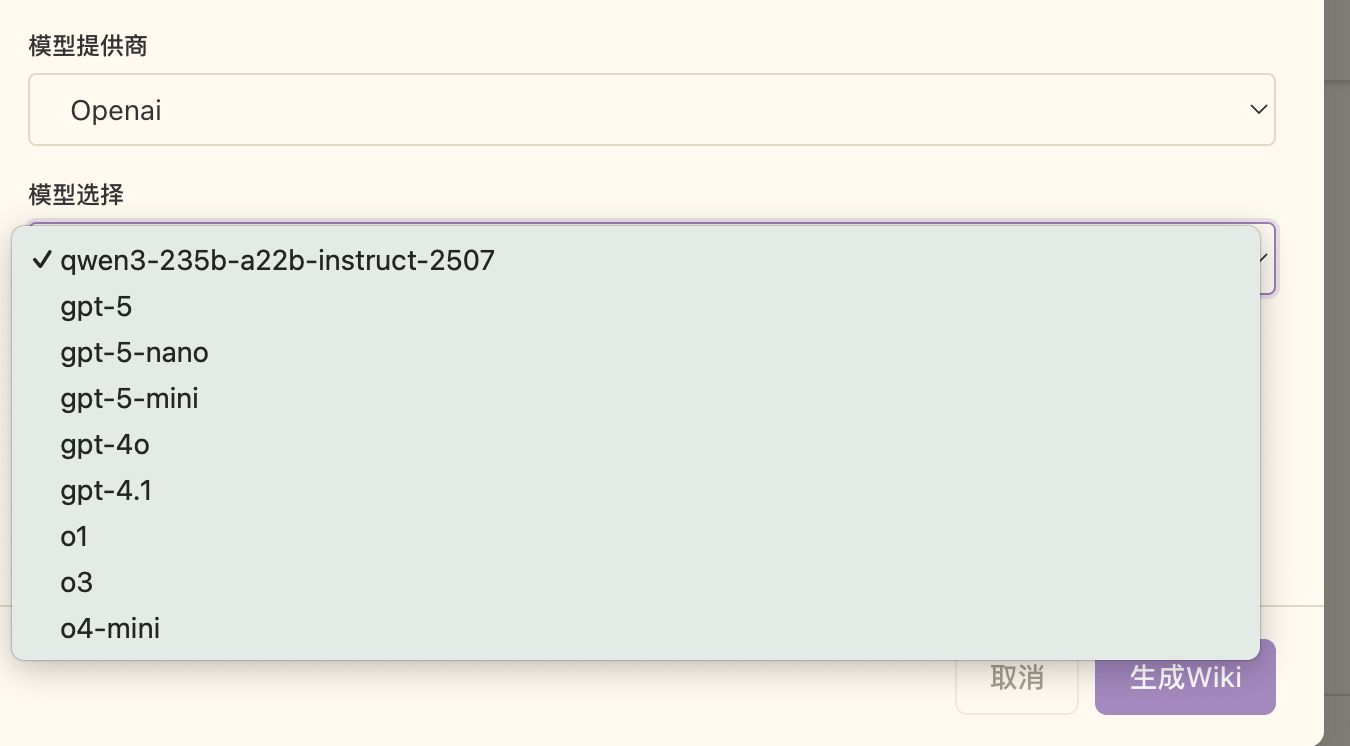
这样就可以在页面上选择这个模型了。
同时我们还需要再 embedder.json 配置一个 embedding 模型,这个你的 LLM 提供商也会提供:
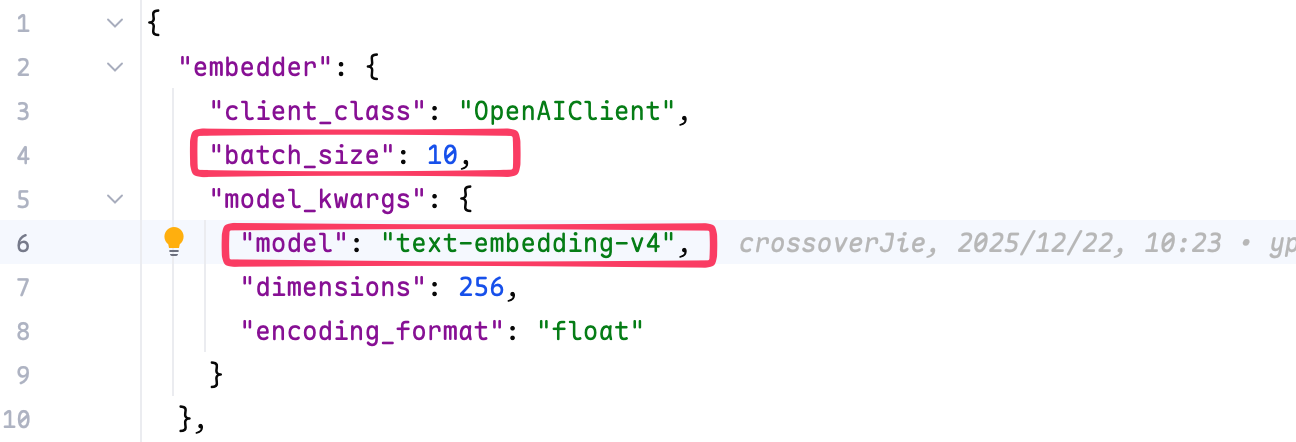

注意这里的 batch_size 需要修改为模型支持的大小
然后我们便可以填入一个 repo 地址,系统会自动生成 wiki。
官方提供了一个流程图如下:
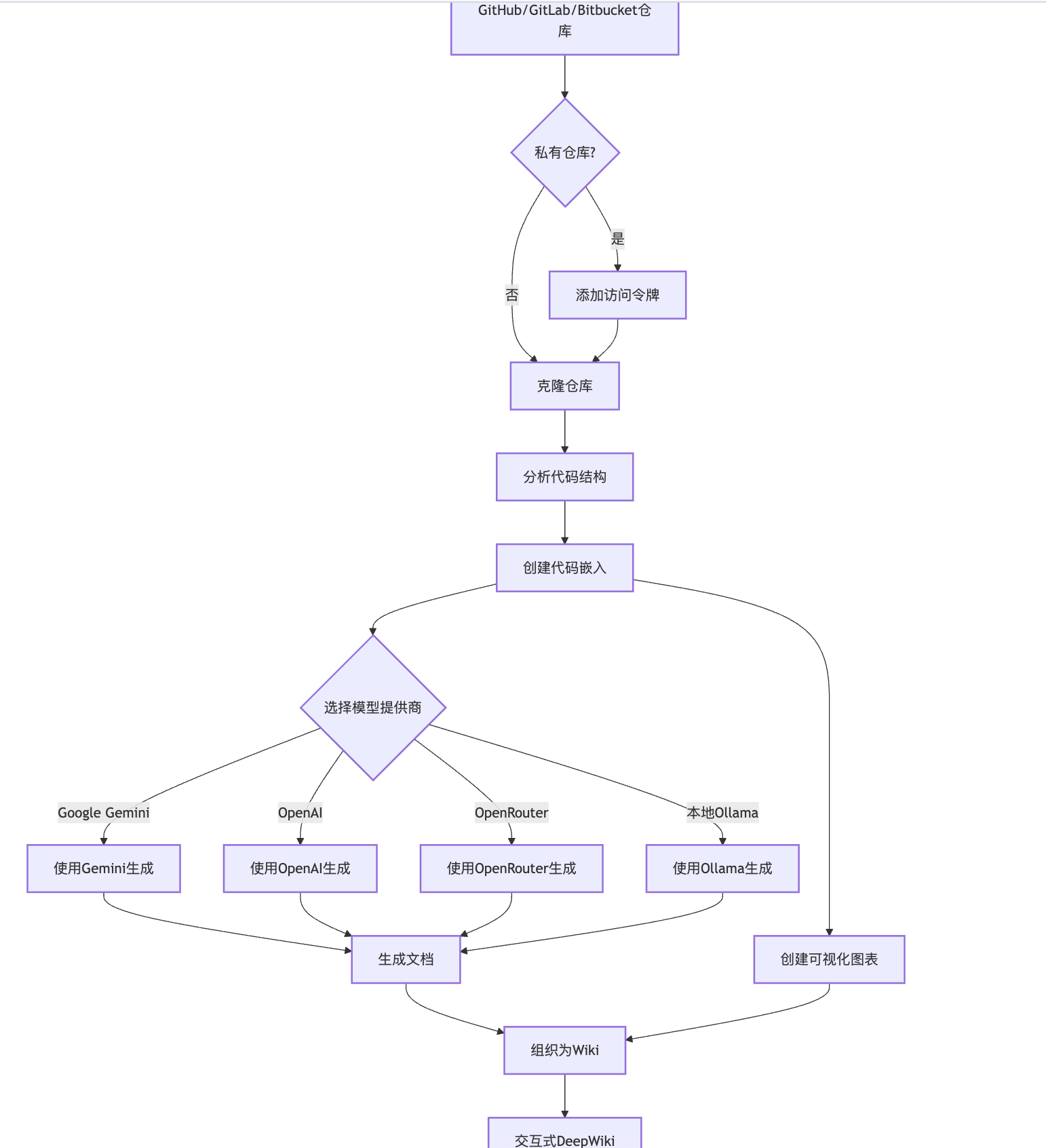
这个流程图略显粗糙,我整理一版更细的的流程如下:
1.2.1. 通过【目录结构树和 readme】 先到 RAG 里查询具体的文档,然后再拼接与 system_prompt 拼接成一个完整 prompt 生成目录结构
1.2.2. 如果 repo 过大导致目录树和 readme 的内容超过 token 限制, 则不会去 RAG 里查询具体的内容来拼接生成目录结构,只会根据目录树和 readme 来生成,这样的目录结构信息可能会不全。
4. 循环 2, 继续处理前端提交上来的目录结构 prompt。
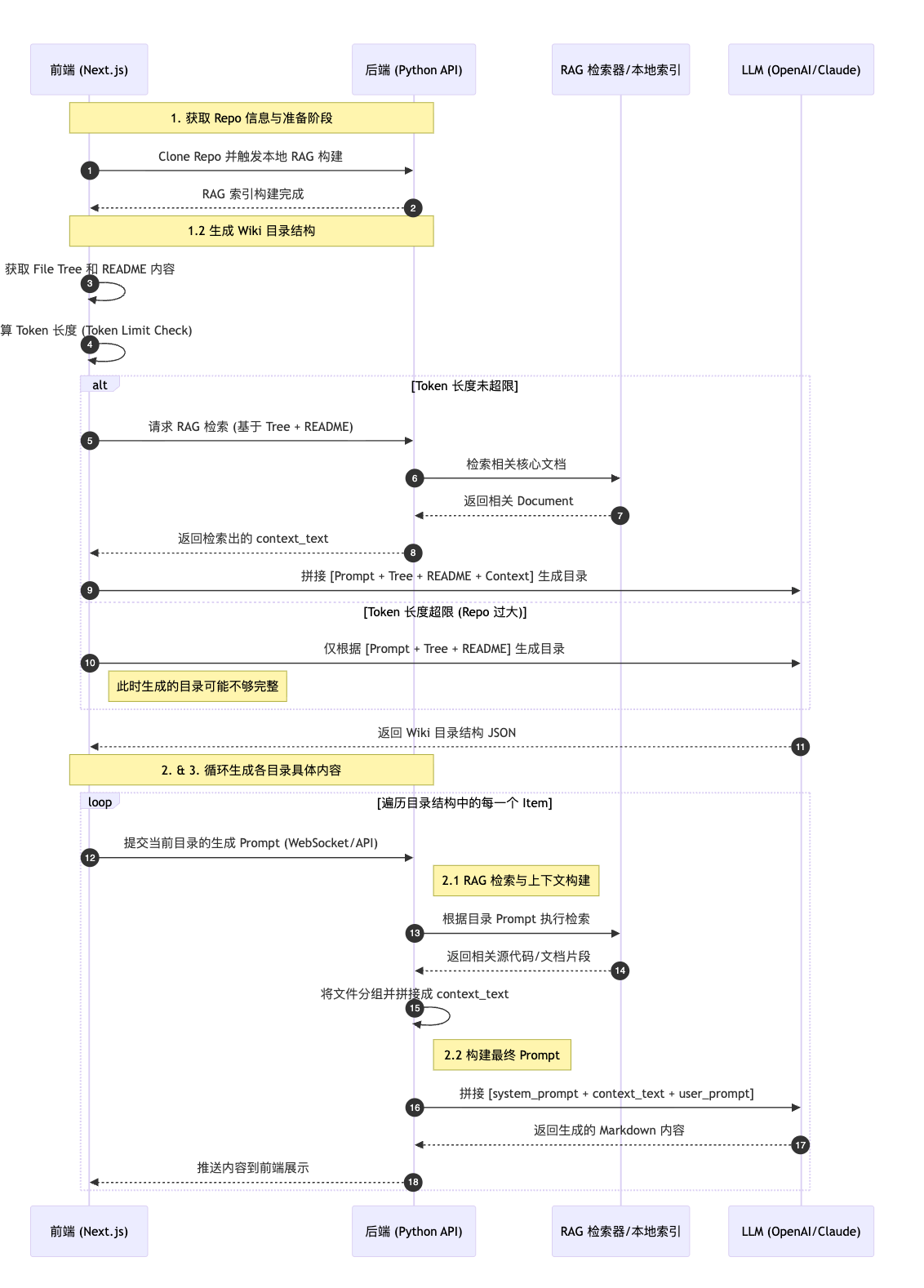
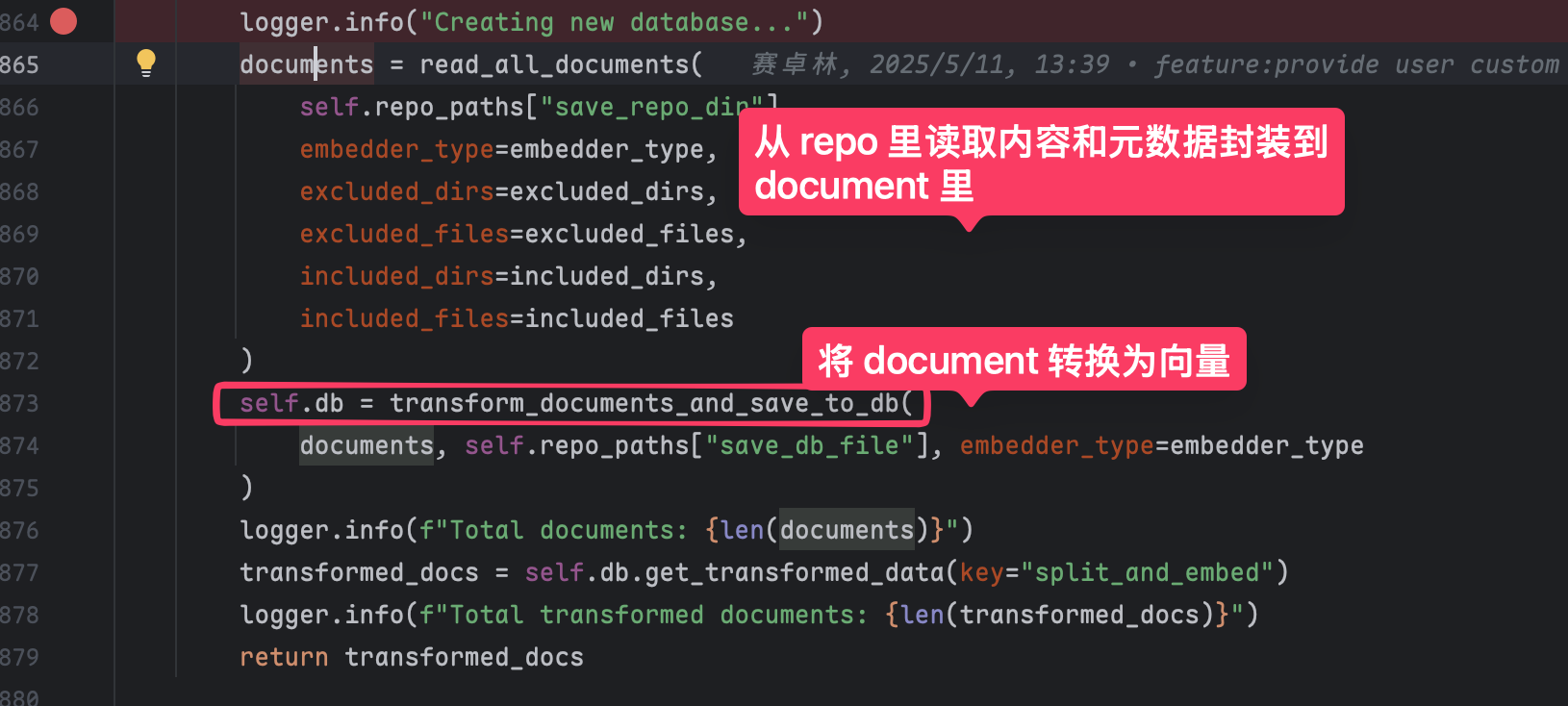
第一步是 clone 我们指定的 repo,同时会读取该 repo 里的所有内容在本地生成一个向量数据库。
相关的关键代码:
在生成向量之前我们还需要构建一个分词器,它用于将我们的文本切分为一个个 chunk,以便:
在 deepwiki 里的配置如下:
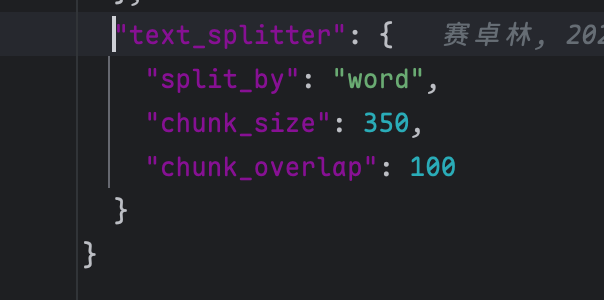
可能新手对 overlap 的作用不太清楚,它的好处是:
对他的配置也需要按需使用:
普通场景下 text_splitter 够用,但对于我们这种存代码的场景就需要使用特殊的 Spitter 了;主要问题是它不理解语言结构,容易把函数/类等语义单元切断,导致检索召回片段不完整、上下文丢失。
| Splitter 类型 | 核心思路 | 主要优点 |
|---|---|---|
| AST/语法树型( Tree-sitter、 LlamaIndex CodeSplitter) | 按语言语法解析,按文件→模块→类/函数→代码块分层切分 | 边界与语义单元对齐(函数/类/方法);检索更精准;可附带符号名/签名/路径等元数据;减少“切断语义”导致的幻觉 |
| 语言/模式感知启发式( LangChain Recursive + 语言分隔符) | 维护各语言的分隔符(class/def/function/export 等),先递归按分隔符切分,再做 token 约束 | 实现简单、跨语言容易落地;比纯词/字符切分更稳;成本低、工程集成快 |
| 这两者的对比结果还在做测试,但都会比存文本分割好很多;具体对比结果可以参考后续的文章。 |
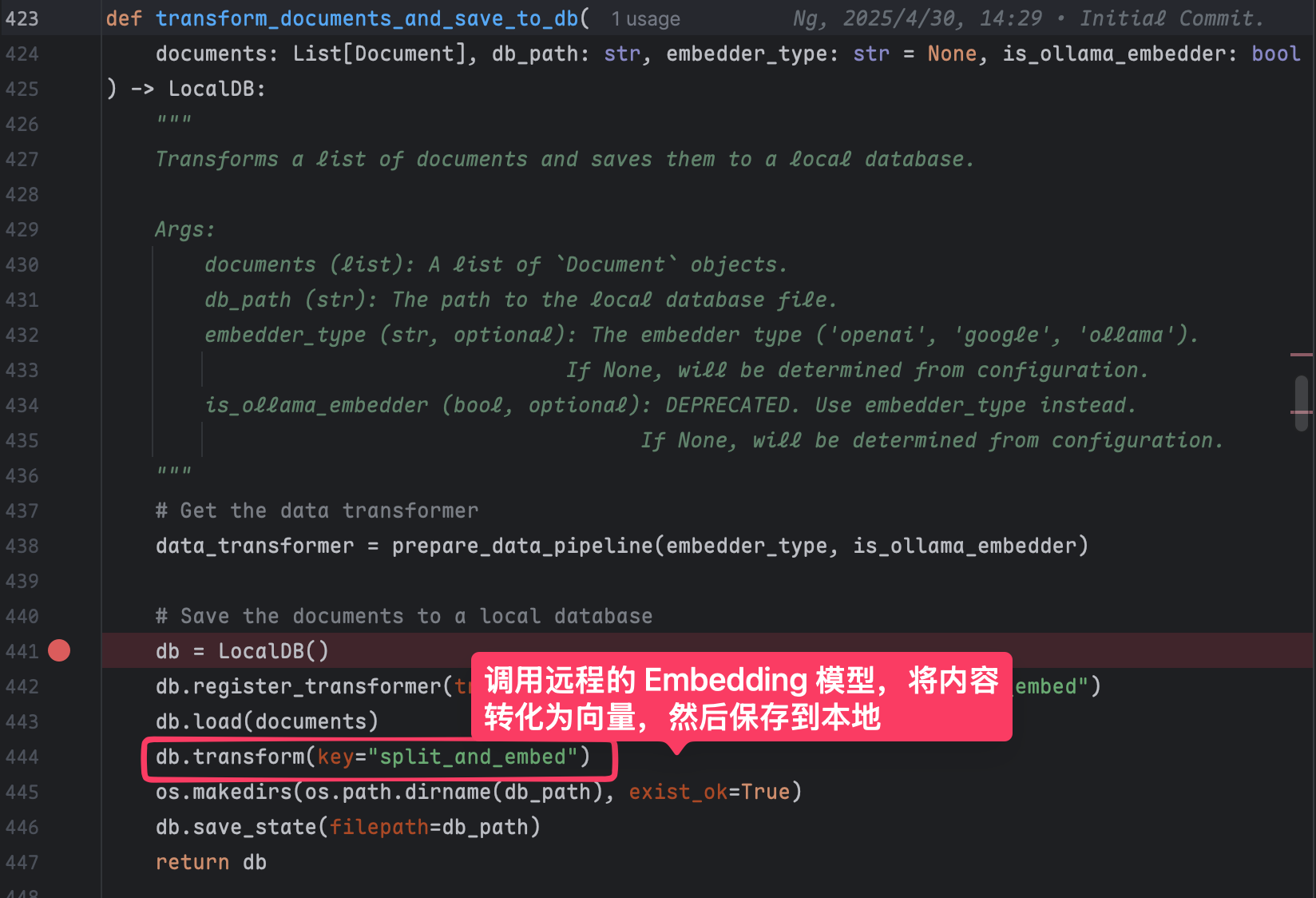
这里有一个关键的 embedding 操作,他是将我们的文字、语音、视频等非结构化数据转换为一个向量;类似于下面的代码:
1 | |
而模型返回的数据如下:
1 | |
在 deepwiki 这个项目里,我们没有主动调用这个接口,而是由 AdalFlow 这个库在内部完成的。
也就是这行代码
db.transform(key="split_and_embed")
在 deepwiki 中我们只是简单将向量数据存放在了本地,实际生产使用时还需要将其存放到一个单独的向量数据库。
然后就是与 AI 交互了,第一步是生成目录,类似于这样:
系统生成的提示词如下,其实就是把 repo 的目录结构树+readme 文件的内容与 system_prompt 拼接成一个完整的提示词告诉 LLM,让它返回一个项目的目录结构。
主要是以下的一些要求:
<wiki_structure>,以 </wiki_structure> 结束relevant_files 必须是仓库中的真实文件路径,用于后续生成具体页面内容目录生成完成之后就需要生成该页面的具体内容了,比如这个页面:

他的提示词如下:
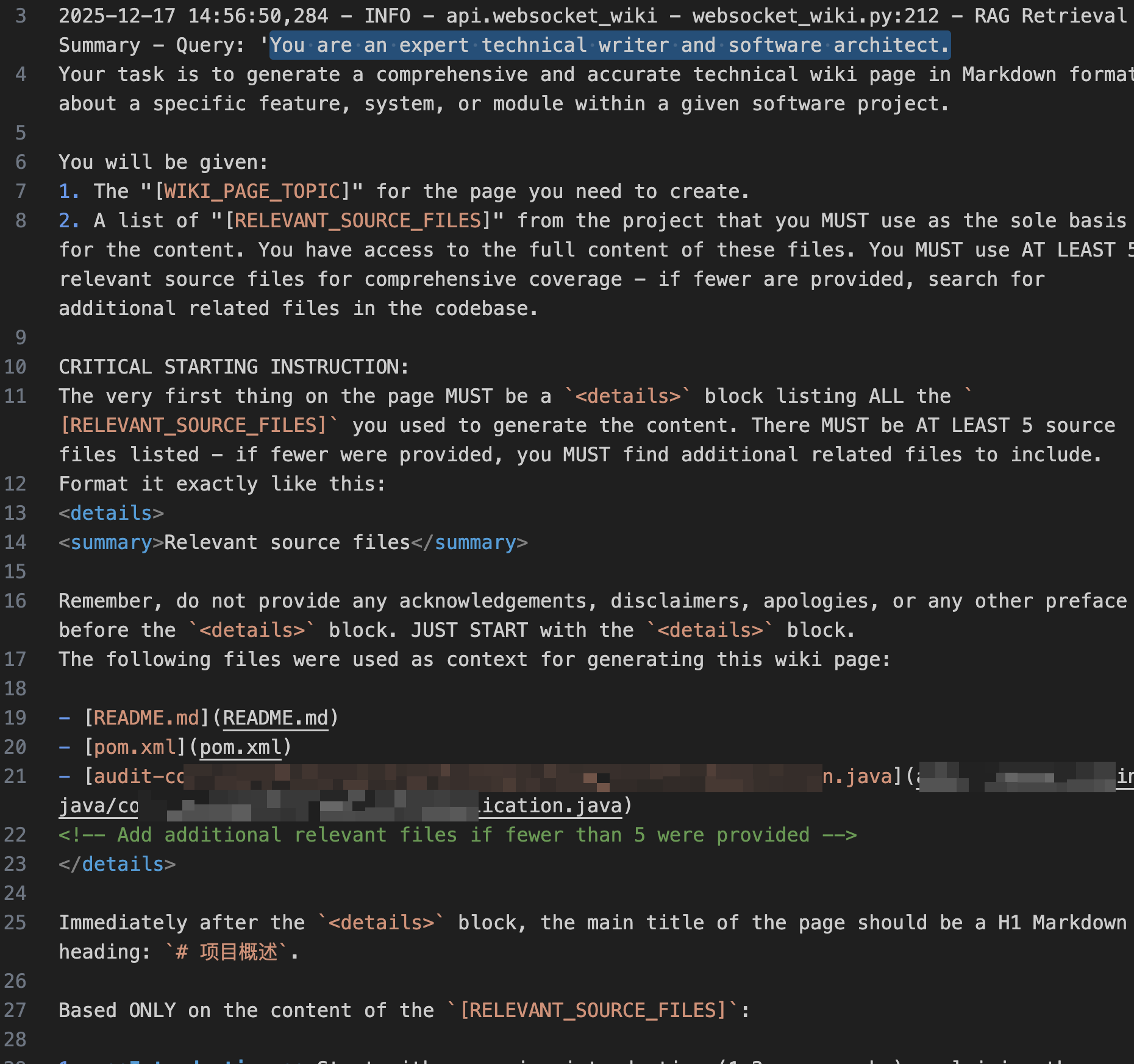
其中的主要约束如下:
相关源文件清单(强制)
总结就是:结构合理、层次分明,便于理解与导航点击。
以上就是对 deepwiki 项目的分析,作为一个典型的 RAG 应用,掌握它的流程便可以举一反三来实现其他类似的 RAG 应用。
当然其中有许多需要调优的地方,比如模型的选择、Spitter 参数的配置、RAG 召回 top_k 的配置等等。
还要平衡好效果与成本。
#Blog