DeepSeek再放大招,推理速度狂飙85% 怎么做到的?
- - cnBeta全文版6月27日,DeepSeek公开DSpark技术报告和DeepSpec代码库. DeepSeek-V4的底座模型没有变,新增的是一个服务端推测解码模块:DSpark. DeepSeek在HuggingFace模型页里把话说得很直白:V4-Pro-DSpark和V4-Flash-DSpark"不是新模型".
6月27日,DeepSeek公开DSpark技术报告和DeepSpec代码库。DeepSeek-V4的底座模型没有变,新增的是一个服务端推测解码模块:DSpark。DeepSeek在HuggingFace模型页里把话说得很直白:V4-Pro-DSpark和V4-Flash-DSpark"不是新模型"。这两个页面指向的是同一个模型检查点,加上推测解码模块后的服务版本。

这意味着,DSpark没有让模型突然变聪明。它瞄准的是模型上线之后,怎样更快、更便宜地把答案吐出来。
技术报告称,DSpark已部署在DeepSeek-V4的线上服务系统中。在真实用户流量下,相比此前的MTP-1生产基线,也就是DeepSeek上一代线上推测生成方案,V4-Flash的每用户生成速度提升60%到85%,V4-Pro提升57%到78%,前提是匹配吞吐条件。
这里的"快"也要收住口径。 它主要指生成阶段,也就是模型持续输出token的那一段速度,不等于所有用户请求的端到端响应时间都同步快了85%。 长提示词的预填充、检索、工具调用、排队和网络延迟,仍然会影响用户实际等多久。
模型上线后,还有一笔推理账
这件事没有新模型发布热闹,但它更接近AI公司每天面对的现实: 模型训练完之后,成本没有结束。
聊天机器人、代码助手、智能体和搜索式产品,每一次调用都在继续消耗GPU时间。模型慢一点,用户等得久一点;推理贵一点,厂商就更难把高质量模型开放给更多场景。
AI行业过去两年更习惯讨论训练成本:一家公司要买多少GPU、建多大的集群、花多少钱训练下一代模型。但模型真正变成产品之后,另一类成本会不断冒出来:推理。
训练像一次大工程,推理更像水电费。 只要用户还在问问题、智能体还在跑任务、代码助手还在生成补丁,模型就要继续消耗算力。
大模型服务最后都会回到两个指标:速度和单位token成本。API定价页面通常按输入token和输出token收费,企业内部也会把不同模型、缓存、路由和上下文长度拆成成本项。
DSpark不能直接等同于降价,但如果同样的GPU集群能在相近吞吐下让用户更快拿到答案,它意味着同样的硬件可以服务更多用户,或者同样的用户体验可以用更少的卡来提供。
"先猜,再验"
推测解码的思路,可以粗略理解成"先猜,再验"。
大模型生成文本时,通常是一个token接一个token往外吐。前一个token出来,后一个token才知道该接什么。这种方式稳,但慢。推测解码会让一个更轻的草稿模块提前猜出一段候选token,目标大模型再批量验证。猜对的部分直接接受,猜错的位置再修正。
小模型不能替大模型做决定。最终接受哪些token,仍然由目标模型校验;正确实现下,它改变的是生成方式,不改变目标模型的输出分布。 加速来自让大模型批量验证候选,而非逐步生成。
DSpark改的,是草稿怎么生成
论文没有只停在"先猜,再验"这层解释。它重点处理了草稿怎么生成。

现有的草稿策略大致分两类。自回归草稿器更稳,因为后一个token会看见前一个token,但草稿变长,延迟也就跟着上去。而并行草稿器更快,可以一次猜出一整段,但每个位置各猜各的,后面的token容易和前面脱节,接受率越往后越容易下滑。
DSpark选择折中。 论文题目里的关键词是"半自回归生成(Semi-Autoregressive Generation)",它先用并行方式提出一段候选,再用一个轻量顺序层修正后续token的条件关系。这样既保留并行生成的速度,又让后面的候选能看到前面已经猜了什么。

另一个关键点,是验证多长一段。
候选token猜得越多,不一定越省。如果明知道后半段很可能被拒绝,还交给大模型验证,就是把GPU时间花在低价值位置上。 DSpark会看候选的置信度,也看当前系统负载,动态决定验证长度。 GPU空一些,可以多验;负载高时,就把算力留给更可能被接受的部分。
论文标题里的"置信度调度(Confidence-Scheduled)",说的就是这件事。

DSpark站在已有技术路线之上
DSpark站在推测解码已有路线之后,更像是DeepSeek把这条技术路线推到线上服务后的公开参照。
SpecInfer早在2023年就把小模型预测、token树(token tree)和并行验证放进大模型服务系统里;Medusa在2024年提出给模型加多个解码头,一次预测多个后续token;EAGLE系列则围绕草稿模型和动态草稿树(draft tree)继续提高接受率。vLLM、SGLang、TensorRT-LLM这类推理框架,也早就把推测解码当作降低延迟的重要工具。
DSpark的位置,在于它把几个生产问题放到一起处理:草稿怎么生成,候选怎么保持连贯,验证长度怎么随负载变化,线上真实流量下速度到底能提高多少。
论文里反复出现的关键词,也从"模型能力提升"转向每用户生成速度(per-user generation speed)、匹配吞吐(matched throughput)、服务等级协议(SLA)这些服务侧词汇。
这也解释了为什么不能只挑最大的数字看。论文里确实还有661%、406%这样的高倍吞吐数据,但它们来自更严苛的每用户速度目标:在那种设定下,旧基线本身已经接近服务能力的边界,DSpark的相对优势会被放大。
真正能说明常态收益的,还是前面那组数字:匹配吞吐、真实流量分布、对比对象是MTP-1。
DeepSpec能复现什么
DeepSeek同时开源了DeepSpec。这是一套用于训练和评估推测解码草稿模型的代码库,包含数据准备、训练和评估流程,也放出了Qwen3、Gemma等模型上的相关检查点。
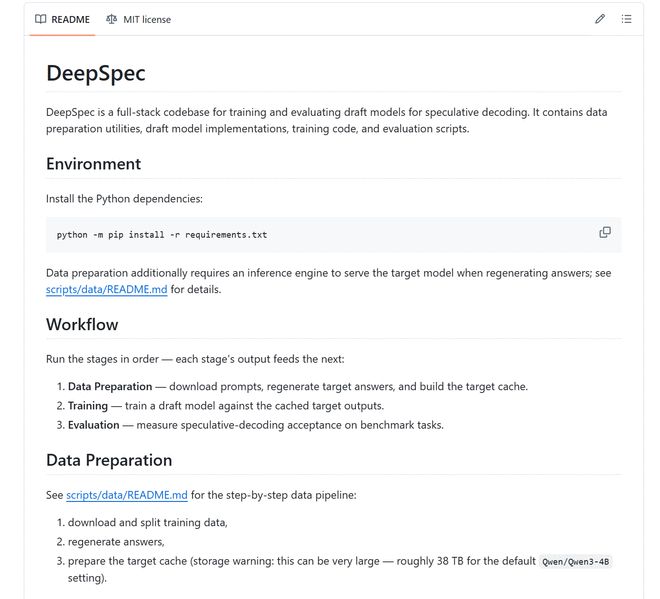
不过, 开源不等于"下载即复现"。 项目文档里提示,默认Qwen3-4B配置下,目标模型缓存可能接近38TB;默认训练脚本假设单节点8张GPU;如果要对齐论文结果,训练设置必须严格一致,特定领域还需要对草稿模型做额外微调。
外界可以验证方法的一部分,也可以把DeepSpec移植到其他开源模型上,但DeepSeek-V4线上服务里的那组速度提升数字,仍然来自DeepSeek自己的硬件规模、流量分布和生产系统调度。
开源的是方法,不是环境。
社区最关心的是复现边界
X上的讨论没有停在叫好,更像一群工程师在追问:这套办法到底怎么跑、能不能复现、边界在哪里。
AI研究者Ravid ShwartzZiv把DSpark概括为两类草稿器的折中:并行草稿器快,但接受率沿候选块衰减;自回归草稿器稳,但延迟随草稿长度上升。他特别提到DSpark加入的两个组件:置信度判断头和负载感知调度器,并补了一句关键边界:"和所有推测解码一样,它是无损的。"
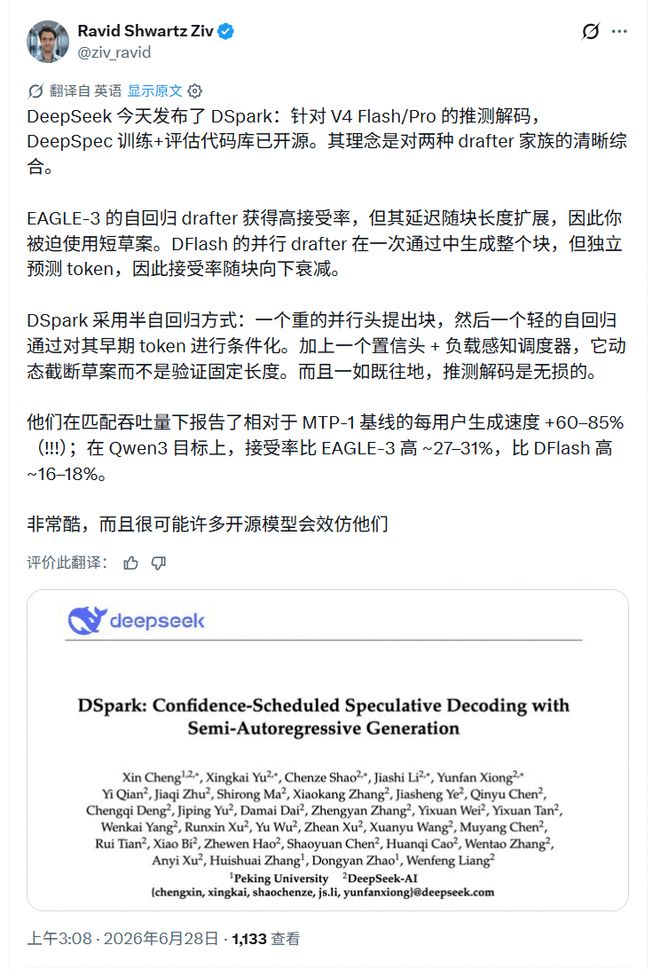
工程师更关心的是能不能跑起来。vLLM贡献者Rafael Caricio称自己在双DGX Spark GB10上把DeepSeek-V4-Flash的DSpark模式跑通,单流解码约60 tok/s,大约是MTP-1的1.5倍。
他同时提到,真实代码会话暴露了合成基准测试看不到的问题:瓶颈不只是计算核心的速度,而是长上下文下草稿接受率会明显下滑。
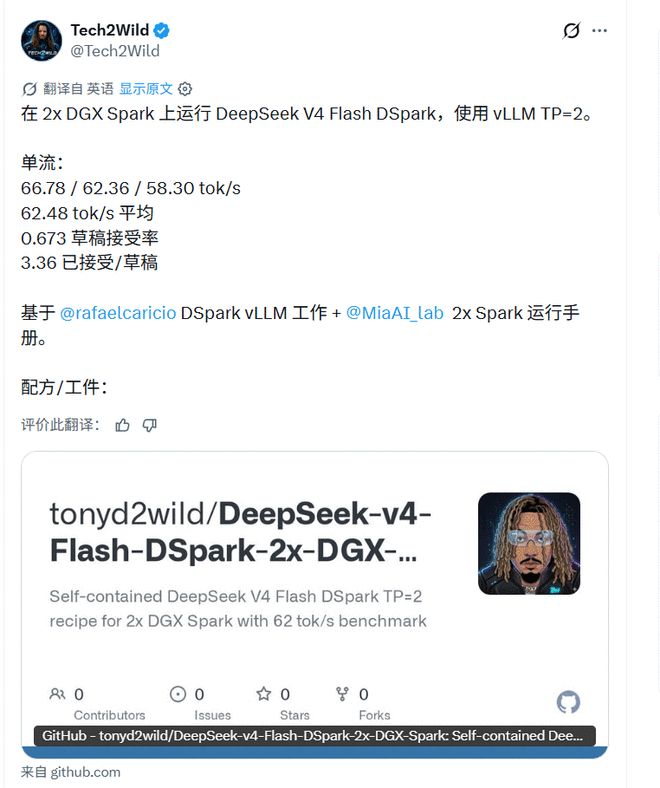
Tech2Wild也给出了相近方向的现场数据,显示V4-Flash-DSpark已有人在特定vLLM环境里试跑。但这类结果高度依赖硬件型号、框架补丁版本、上下文长度和并发设置,换一套环境结果可能完全不同。
也有人专门提醒边界。AcingAI在X上指出,DeepSeek报告里的高倍数仍然是"自家硬件、自家MTP-1基线、匹配吞吐条件下"的结果,外部尚未完整复现。
这提醒我们,DSpark的一部分优势来自负载感知调度,而调度效果天然依赖生产环境的流量规模和硬件配置。
同样的能力,更少的算力
南华早报在6月28日的报道中,把DSpark放在推理瓶颈、芯片压力和用户等待时间里看。这个角度比"DeepSeek又发了什么模型"更接近产品现实。
AI公司还会继续比模型能力,但当能力差距被压缩,谁能把同样的能力更快、更便宜地交付出去,也会成为竞争的一部分。
DeepSeek这类公司尤其需要把这件事讲清楚。DeepSeek一直把低成本、高效率作为外界理解它的重要入口,从模型训练叙事到API价格,最被关注的不是它有没有再堆一个更大的参数规模,而是它能不能把同等能力做得更便宜。
DSpark延续的正是这条线:它不证明V4突然更聪明,它证明V4在服务用户时可以少浪费一部分推理算力。
如果把视角再放宽一点,推理优化也会影响开源模型生态。开源模型过去常被认为"便宜",但真正部署时,显存、吞吐、并发、延迟和运维复杂度都会变成成本。
一个模型能开源,只说明大家能拿到它;能不能便宜地服务大量用户,还要看推理栈能不能跟上。
DeepSpec放出Qwen3、Gemma等检查点,说明这件事已经不只停在DeepSeek-V4自己身上。迁移到什么程度,还要看社区适配、框架支持和硬件兼容的实际进展;但从目前公开信息看,DeepSeek已经让这条路线走出了自家模型。
DSpark的价值就在这里。 它给V4增加了一层更接近生产系统的推理服务工具,而不只是一个新能力标签。
接下来值得看的,已经不止是DeepSeek自己能跑多快,还包括这条路线能被多少人走通。DeepSpec已经放出检查点和训练流程,推测解码正在从一家公司的工程选择,变成开源推理降低成本的通用手段, 前提是其他框架和硬件能跟上。