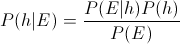



机器学习五步走
- - 我爱机器学习经常会有人问“我该如何在机器学习方面更进一步,我不知道我接下来要学什么了. 一般我都会给出继续钻研教科书的答案. 每当这时候我都会收到一种大惑不解的表情. 但是进步确实就是持续的练习,保持较强的求知欲,并尽你可能的完成具有挑战性的工作. 因为他是为数不多的几种可以让你真真让你获取坚实知识的媒介. 是的,你可以选择选一门课,注册MOOC,参加一些讨论班.
“ 贝叶斯公式是可以支配一切知识,一切信息的法则”. --- Christoph Fuchs
贝叶斯公式我们都学过(如果没学过,请了解一下"条件概率”),就是一个条件概率的转换公式,如下
这么的一个简单的公式为什么能引起科学上的革命? 这是一个统计学上的公式,但是却被证明是人类唯一能够运用自如的东西。伯克利大学心理学家Alison Copnik早在2004年就证明”Bayesian统计法是儿童运用的唯一思考方法,其他方法他们似乎完全不会”。
贝叶斯式的思考是什么样的?
举个例子, 你在北京798艺术区远远地看到一个人在地上爬,你很奇怪那到底是什么。于是你的大脑 可能联想产生了3种假想( 大脑真的就是那么工作的),
h1 = 那是疯子
h2 = 那是狗
h3 = 那是艺术家
那么这三种假想哪个更有可能? 更准确地说就是,在 给出了 事实(Evidence) {某人在798上爬}的情况下,哪种假想更有可能? P(h1|E), P(h2|E), P(h3|E).哪个更大些?
于是你的脑子开始启动贝叶斯程序, 计算比较这三个的概率到底哪个更大.
因为P(E)对于三个式子来说都是一样的,所以贝叶斯公式可以看成
先看看P(h)是什么? P(h)在这个公式里被叫做 先验概率,描述的是你对某个假想h的致信程度.(不用考虑当前的事实是什么)
P(h1) = 出现疯子的可能性,(根据你的经历, 你很少在北京街头看到疯子) 可能性:较小
P(h2) = 在798艺术区出现一条狗的概率,(老看到有人溜狗) 可能性: 高
P(h3) = 在798出现艺术家的概率,(798里应该总能看到) 可能性:高
P(E|h)是什么呢?它表达的是,你的 假想 产生这个 事实的可能性有多大?
P(E|h1) = 人疯了( 假设假想h1成立)可能会在798爬来爬去的概率. 可能性: 高
P(E|h2) = 假如那就是一条狗, 你却能看成一个人在地上爬的景象 可能性: 0(极低)
P(E|h3) = 假如那个人就是艺术家, 他在地上爬进行行为艺术的可能 可能性: 高
最后把两个概率相乘就能得到三个假想在当前事实面前发生的概率。
P(h1 | E ) =小 (你的设想(出现疯子)发生的概率太 小了,虽然疯子很有可能在这爬来爬去,所以最后总的概率还是很小)
P(h2 | E ) =小 (你的假想(出现狗)发生的概率还挺大,但是你没法否认眼前看到的是人这个事实, 所以概率又变得很小)
P(h3 | E ) =高 (你的假想(出现艺术家)的概率挺大,而且艺术家干这种事还是能干得出来的,所以总的概率并不小)
所以人在利用贝叶斯公式进行推测一件事情的时候,其实就是在权衡你脑中 产生假设本身的可能性和这种假设可能产生眼前的事实可能性之间的关系,如果两种可能都很大,那么这件事才会让自己信服。
这些P(h), P(h | E)都是我们从平时经历的事情中总结得到的结果( 经验),而且甚至非常因人而异,比如P(h1) 在疯人院的职工看来,他们对出现疯子这件事情见怪不怪,所以P(h1)在他们的脑里可以是个很大的值。
而P(E | h3) 在某些老人的眼里,艺术家都是那种很正常,每天唱红歌的那种人,所以艺术家很少可能会在街上爬啊爬,所以这些时候,他们更相信眼前出现的人是个疯子。
总而言之,贝叶斯做为一种统计法,善于统计和利用 历史的经验,来对 未遇到过的情况做出推测。你可以使用你历史的记忆的碎片 组合成新的情况。就像你未必见过艺术家在798里匍匐前进,但是你却在798见过艺术家,而且从别的地方(电视上)看到过艺术家一些匪夷所思的艺术行为,所以你真的遇到这种场景的时候,就能够利用联想,并用经验去验证联想的结果,推断出这是一个艺术家的行为。
上一部分介绍的是人们怎么利用一些经验和贝叶斯去解决一些生活中的问题。但是有些问题会使你产生直觉上的错误, 这时候,贝叶斯更能去帮助你 纠正这些直觉上的错误。
问题:
http://yudkowsky.net/rational/bayes 里的一个问题,某地区有一台 乳腺癌检测仪:
一个地区的女性乳腺癌发病率为1%.
已经患乳腺癌的人里面会有80%会被仪器正确地检测出”某指数”呈阳性.
但有9.6%的正常人也被检测出”某指数”成阳性.
此地区一妇女去体检,很不幸被检测出了”某指数”呈阳性。你做为一个医生,你觉得这名女性患乳腺癌的概率是多少?
很多人会 第一时间地认为,既然80%的患者能被正确的检测出来,那么这台机器的准确率也就是80%. 那么既然已经被检测出患病,那么她患病的概率应该为80%左右。即使有9.6%的正常人的误检率,那么患病率的也应该不低于70%. (其实有85%的医生也是这么认为的,如果我去看病我肯定自杀了...)
事实真的是这样吗? 让我们用贝叶斯计算一下,

天呐,才7.76%,为什么这么低?我们的直觉为什么出错了?
如果我 换一种说法,这个问题就不容易产生错觉。
有1000人去体检,有10人真的患病,
这10个人里有8个能被检测出阳性.
还有剩下的990个正常人里, 有95个人也被误检测呈阳性。
现在再问你,有一妇女被检测出了阳性, 那么你觉得这个结果准确的概率是多少? 这时候,你做出判断时就会更加谨慎。你会觉得103个被检测出阳性的人里面,只有8个人真正地得了病,那么这位妇女患病的几率其实并不是太高的。
我们直觉出错的原因在于,我们把 先验概率忽略了。虽然只有9.7%的正常人被误检成阳性了,但是正常人的数量是患者数量的90倍有余,那么误检的人就有很多很多。其数量远远大于80%的患者。
所以这件事情再次告诉我们,如果你在制造一台检测仪的话,不仅要提高 对患者的检测率,而且也需要提高对正常人的 排查率,这样才能使得这台机子的结果让人信服。
再次总而言之,这个部分又告诉了我们一个重要的事实,我们不能对一件事情 因果倒置,两件事不能混为一谈。原因产生结果,但是结果往往是不能对原因起直接作用的。表现在这里,就是因果倒置的概率发生了剧烈的变化。
假如两件事之间存在因果关系,我们能不能用贝叶斯来分析这两件事情之间相互影响的程度呢?当然可以, 条件概率就能说明他们之间的 影响程度。
例如,患病会引起某项指数呈阳性。通过条件概率,就可以知道患病的人,有多少会造成某指数阳性. 那么可以求
P(阳性 | 患病)
相反,引起阳性的众多原因中,想知道患病占多少,于是我们就可以通过求
P(患病 | 阳性)
下图就是分析在产生阳性的原因中,患病产生阳性的比重是多少。
有时候因为因果互换以后的条件概率变化非常大,那么是不是能从统计的概率中就得到这两件事情之间的关系?
很遗憾,概率只能间接地表现因果关系,但是很难从概率中得到准确的关系图表。