- - 企业架构 - ITeye博客
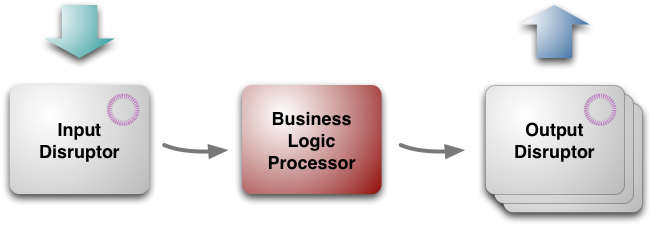
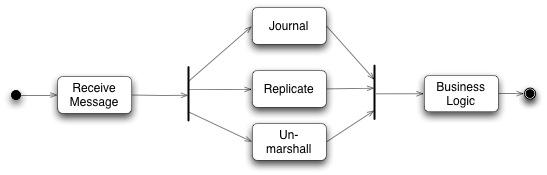
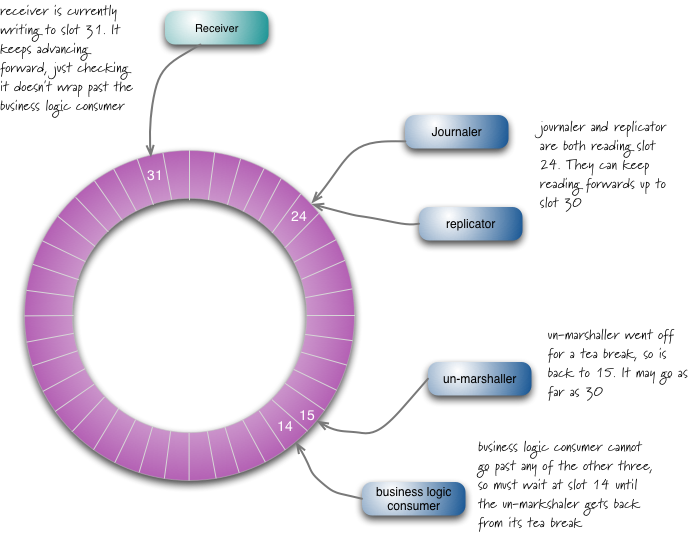
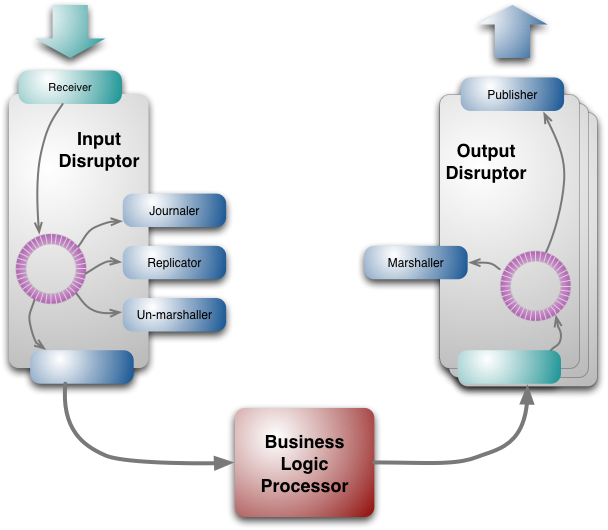
LMAX是一种新型零售金融交易平台,它能够以很低的延迟(latency)产生大量交易(吞吐量). 这个系统是建立在JVM平台上,核心是一个业务逻辑处理器,它能够在一个线程里每秒处理6百万订单. 业务逻辑处理器完全是运行在内存中(in-memory),使用事件源驱动方式(event sourcing).
- - IT瘾-dev
网关:Nginx、Kong、Zuul. 缓存:Redis、MemCached、OsCache、EhCache. 搜索:ElasticSearch、Solr. 熔断:Hystrix、resilience4j. 负载均衡:DNS、F5、LVS、Nginx、OpenResty、HAproxy. 注册中心:Eureka、Zookeeper、Redis、Etcd、Consul.
- Michael - Tony-懒得设计
写几篇关于信息架构的文章,系统地输出我理解的信息架构. 发了一篇关于招信息架构实习生的博客,收到不少简历. 但谈起信息架构,多数不了解,稍微了解的扯了很多很偏的东西. 随手搜索了一下,我发现了原因:. 1 《web信息架构》这本书太概念,太学术. 2 有人绑架了“信息架构”这个词,拿出去唬人,内容都是皮毛或者是根本和信息架构不沾边的东西.
- - 博客 - 伯乐在线
英文原文: CSS Architecture,编译: CSDN-张红月. Philip Walton 在AppFolio担任前端工程师,他在Santa Barbara on Rails的聚会上提出了CSS架构和一些最佳实践,并且在工作中一直沿用. 擅长CSS的Web开发人员不仅可以从视觉上复制实物原型,还可以用代码进行完美的呈现.
- - 博客园_首页
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明. 我们以下图为基础,说明Linux的架构(architecture). (该图参考《 Advanced Programming in Unix Environment》). 最内层是我们的硬件,最外层是我们常用的各种应用,比如说使用firefox浏览器,打开evolution查看邮件,运行一个计算流体模型等等.
- - 研发管理 - ITeye博客
对于外包业务类型的项目,软件架构设计的目的与产品类型的项目有所不同,在这里主要讨论外包类型项目的软件架构设计目的. 1、为大规模开发提供基础和规范,并提供可重用的资产,软件系统的大规模开发,必须要有一定的基础和遵循一定的规范,这既是软件工程本身的要求,也是客户的要求. 架构设计的过程中可以将一些公共部分抽象提取出来,形成公共类和工具类,以达到重用的目的.
- - 夏清然的日志
现在开始补日志,逐步的扫清以前写了一半的和“欠账未还的”. 半年之前开的头,今天先把NUMA说完. PC硬件结构近5年的最大变化是多核CPU在PC上的普及,多核最常用的SMP微架构:. 多个CPU之间是平等的,无主从关系(对比IBM Cell);. 多个CPU平等的访问系统内存,也就是说内存是统一结构、统一寻址的(UMA,Uniform Memory Architecture);.
- - 数据库 - ITeye博客
在阅读了GFS的论文之后,对GFS的框架有了基本的了解,进一步学习自然是对HDFS的解析,不得不说,之前对GFS的一些了解,对理解HDFS还是很有帮助的,毕竟后者是建立在前者之上的分布式文件系统,二者在框架上可以找到很多的共同点,建议初次接触HFDS的技术人员可以先把GFS的那篇论文啃个两三遍,毕竟磨刀不砍柴工.
- - 人月神话的BLOG
前面已经谈到过企业架构的层次和维度方面的问题,在这里简单谈下企业架构中的业务架构和业务价值链方面的内容. 随着企业不断的发展和演进,各个业务功能单元会逐步成熟,也会形成多个端到端的流程,这些流程涉及到工程项目管理,供应链,财务,人力资源,产品研发等多个方面的内容. 我们再进行高端业务架构建模的时候采用的方法也基本是参考业界标准的价值链模型进行展开.