Feed消息队列架构分析
- - Tim[后端技术]最近一两年,大部分系统的数据流由基于日志的离线处理方式转变成实时的流式处理方式,并逐渐形成几种通用的使用方式,以下介绍微博的消息队列体系. 当前的主要消息队列分成如图3部分. 1、feed信息流主流程处理,图中中间的流程,通过相关MQ worker将数据写入cache、Redis及MySQL,以便用户浏览信息流.
在过去几年,所在的微博技术团队在一定程度成功解决了feed架构的扩展性与性能的问题,大部分精力已经从应对峰值性能或者数据扩展中解放出来。
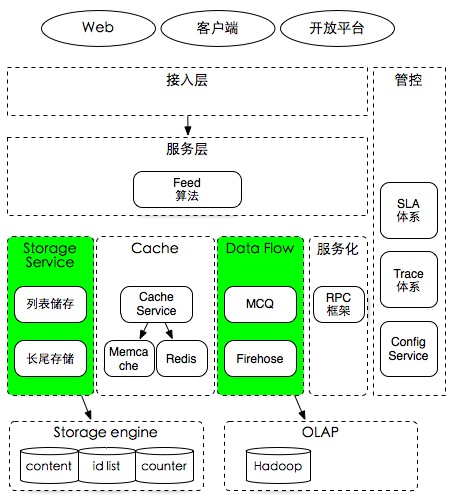
几天前,拿着上面这张架构图问内部一些架构师,目前完成的工作及存在的主要问题是什么?
完成的工作不出意料,大家的观点比较类似,主要在架构的工程成熟度方面。
但是对于不足呢?如果架构重新再来,你会怎么做?这个问题回答比较多元,经过整理一些主要观点如下。
首先是从解决架构的问题说起,上述feed架构主要解决了在社交媒体环境中,实时及可扩展的解决基于关注关系的数据分发问题。
由于微博是一个实时的网络,人们常把Twitter/微博这种社交媒体产品比作是地球的脉搏,它确实无时不刻都在产生海量的数据,并且产生着不可预测的大量随机峰值访问,业界也是首次随着社交网络的出现遭遇这种架构上的scalability问题,记得在2009-2010年左右,Twitter由于压力过大经常出现鲸鱼页面错误。经过几年的努力,包括微博在内的业界主要公司都已经成功解决了关系模型的数据分发架构问题。
但在用户的层面,使用社交媒体产品依旧被信息过载的问题所困扰。
在社交网络中,上述问题,不可能全部像Google的使命那样,通过技术手段得到解决。但是大部分又跟技术密切相关。
社交网络的信息架构和搜索引擎有很大的不同,在浏览feed是并不像使用搜索有明确的搜索意图,Facebook曾经尝试使用 EdgeRank来解决newsfeed算法的效率问题,但是结果并不如预期理想。由于社交关系的存在,用户对出现(及不出现)什么内容的可解释性非常敏感,不能接受好友的信息在排序结果不能看到。因此仅能说feed架构只是解决了初步的问题,更大的问题依旧在思考及寻找解决的途中。
PS:本文上述内容会在12月19日ArchSummit北京 大数据环境的feed架构 演讲中介绍,欢迎参会的同行前来交流。
如想及时阅读Tim Yang的文章,可通过页面右上方扫码订阅最新更新。
Similar Posts: