大数据下的用户画像
- - 人月神话的BLOG简单点来说用户画像,即是 根据用户的静态基本属性和动态行为数据来构建一个可标签化的用户模型. 静态属性:个人基本信息(地域,年龄,性别,婚姻),家庭信息,工作信息等. 动态行为:购买行为,点击行为,浏览,评论,营销活动参与行为,退换货行为,支付行为等. 为何要进行用户画像,核心还是后续的针对性营销,当我们组织一次针对性营销的时候,首先要确定的就是营销的用户群体,那么就要从用户标签中精确定位这个群体.
本文作者从0到1规划头条产品,在此想把自己的实操经验分享出来,值得一阅。

本来默默划船,在交流会上谈个性化推荐都不惹人注意的今日头条,毫无置疑现在已经被整个BAT围剿,内容领域的企业不自觉把今日头条当做竞争对手,非内容领域的互联网公司也都想来分一杯内容的羹,一夜间,互联网遍地都是feed流,不谈内容推荐算法都不好意思上桌了。
笔者近期有幸从0到1规划头条产品,想把自己的实操经验分享出来,如果对感兴趣的朋友有帮助自然开心,更希望得到业界大佬的批评和指正,毕竟一个人摸索前进,还是很危险的。
经常使用阅读产品很大的感受是大平台很容易出现资讯没深度,垂直的内容资讯只在某几个如科技,互联网等几个领域做的还不错,我当时的设想是有没有可能做行业内深度资讯,尤其是一开始切入那些并未互联网化过深的行业,通过一个行业的试点,形成行业头条,在沉淀优质行业知识的同时,以最低成本去复制到其他行业。
思考了挺久之后开始和老板汇报了,省去10000字具体说服过程,最终同意了,因为团队某公司与一个传统行业A有交集,所以一开始的切入行业就是行业A了,下面开始具体执行了,看着一共10多个技术人员,我陷入了深思……
劣势简直不要太明显:
我要开始作死地做头条产品了……
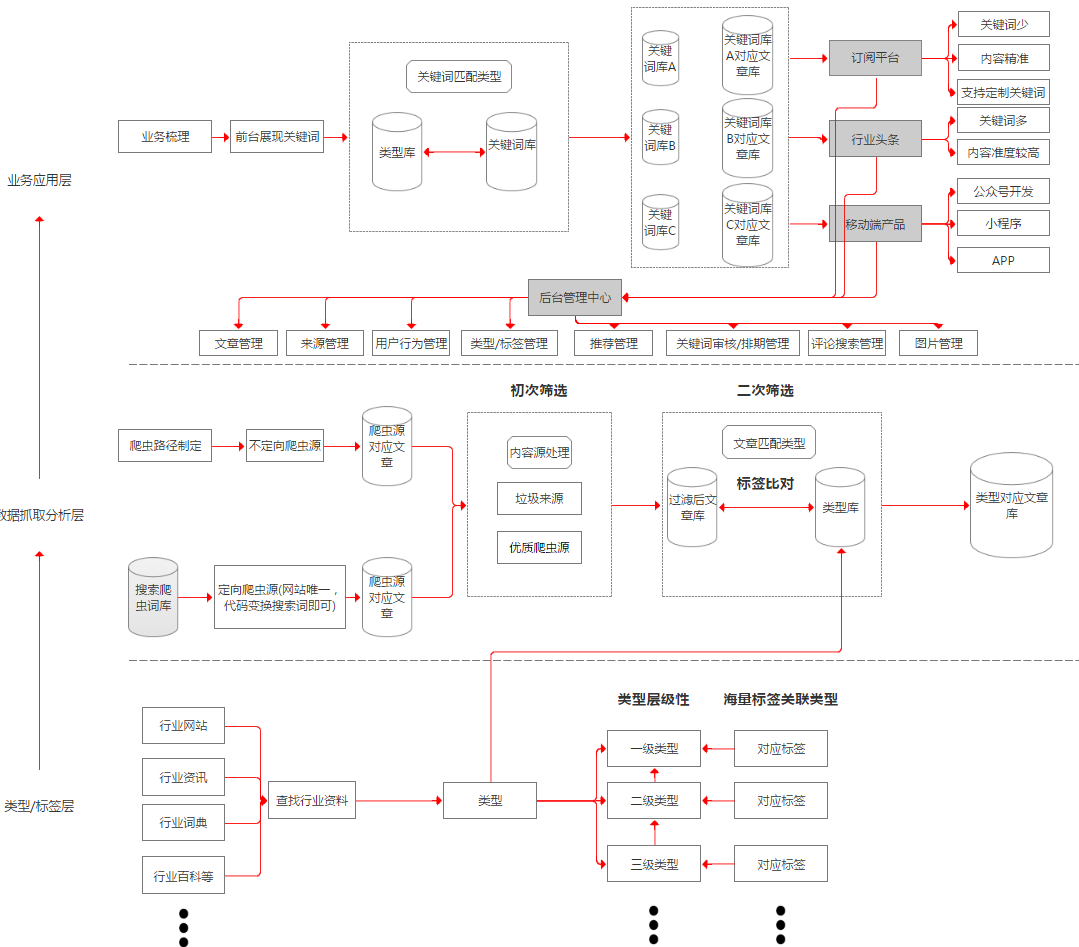
我开始从三个层面去搭建产品,底层类型标签层,中层数据抓取分析层,顶层业务应用层。
底层根据具体行业进行梳理,本来这个过程应该产品和具体行业从业人员配合梳理,但是碍于资源有限,那就我来吧,肯定不足够详尽,但是一开始可以先跑起来。
底层类型标签层分为类型和标签,类型有层级性,数据库预留到7级,实际梳理到3级就差不多了,如行业A,A公司是一个一级类型,A行业制造公司是二级分类,具体制造公司名称是3级类型,每个类型独立建表,每个表里关联海量标签到类型上,如行业A技术这个类型里我们找到行业A技术术语词典,删选后就作为标签关联到A技术这个类型下面,类型数最后梳理了600多,标签数量有10万多,数据库预留状态位,可以视情况进行启用关闭。
数据抓取分析层分为爬虫部署,内容来源处理,数据归类。
1、爬虫部署
我以一个技术外行的角度把爬虫分为两类,一类是不定向爬虫,都是一个个单独网站,这种技术消耗较大,需挨个处理,如各个A行业公司的官网新闻中心和行业A平台网站,需单独处理,另一类定向爬虫,主要是有搜索功能的大资讯平台,如今日头条等,代码可复用,写好之后我直接建了一张表,专门放搜索爬虫的关键词,一堆关键词一套代码就可以实现,输入进去就把含有这些关键词的新闻抓取出来了,现在这张表关键词也有700多了,爬取来的内容量实在太大,建议用mongedb处理。
2、内容来源处理
数据过来后先进行来源梳理,划分优质来源和垃圾来源,提升优质来源内容的权重,优质来源主要是各公司官网,垃圾来源是指对具体行业而言,大量无意义的内容来自同一个来源,那么将他认定为垃圾来源,比如一个叫xx说车的来源在建筑行业被认定为垃圾来源,但是将来复制到汽车这个领域的时候,就不再是垃圾来源了,垃圾来源是一个长期的活,现在大概700多了,大部分垃圾来源是今日头条的头条号。
3、数据归类
过滤完垃圾源之后,就开始数据归类了,本质上是将新闻内容归到我们建立的一个个类型上,因为做行业资讯,希望一开始数据准度较高,我当时想了两种方案,第一种是将类型根据自己关联的海量标签按权重建立一个个模型,所有抓取来的文章做全文的分词处理,大量文章统计词频,每篇文章所有分词就有一个总的频率值,和类型模型比对,取相关性较高的,另一种就是把类型下面所属的标签和所有筛选过垃圾源的文章比对,含有标签的文章归到所属类型下面,含有同一类型标签越多,说明该文章相关性越高,为了快速上线就用第二种方案,但是相对,精度就差了一些,当然随着人工的介入,筛出一系列垃圾源,类型和标签维护工作的持续,内容准度好了一些。
业务展现层主要是梳理目标用户感兴趣的关键词,将这些关键词关联到类型标签层的类型,这样,用户订阅关键词之后就可以看到这个关键词所属的内容,前台现在以及上线2个产品,一个订阅平台,行业头条,与之配套的是后台管理中心。
1、订阅平台
订阅平台半封闭,面向行业A企业用户和行业A自媒体从业者,释放出他们感兴趣的关键词,内容准度更高,企业用户订阅关键词,可以看到相关的资讯,看到平台具有的能力后,有欲望定制更多关键词,后台审核后继续部署爬虫,推送数据给用户,同时记录用户的所有行为数据。
2、行业头条
行业头条完全开放,面向准行业从业者以及泛行业爱好者,释放出更多关键词,但是较订阅平台,内容质量稍差,但是目标用户较广,所以寄希望记录用户的所有行为数据(如评论,阅读量,换一批事件,关注关键词等),得到用户反馈,建立用户画像,以达到根据不同用户画像推荐关键词的效果,为真正的推荐做准备。
3、后台管理中心
含有新闻管理,来源管理(优质来源,垃圾来源),类型/标签管理,用户行为管理,推送管理,关键词审核排期管理,评论搜索管理等,具体就不再详述了,有机会再详细介绍,简单的把产品框架梳理了一张图,和上面的论述结合起来,可能更方便理解。
(注:侵权必究)
不要动不动就要再造个今日头条,如果你的体验和算法做不到比他强百分之五十以上,正面硬刚基本没戏,找准自己的切入点,认清自己的优势;
内容推荐从来都很危险,如果用户不需要的时候推荐,除非做到让用户惊喜,否则就是减分,用户一定要用的产品,用户只能忍着,可有可无的产品,极有可能被用户卸载,这点做公众号的朋友肯定深有感触,每次推送内容都怕掉粉。。
因为对搜索一直比较有兴趣,所以简单阐述一下自己对输入法产品想做内容的建议吧。
用户有自己了解资讯的需求:
这一类需求竞争极其大,还有一类是基于特定场景下,对资讯的了解诉求。
比如找工作时,想了解某家公司;吃饭时,想了解附近餐馆的情况。
这一类诉求特别长尾,目前多是怎么被满足的呢?
主动搜索,到百度,知乎等平台搜索,但得到想要的资讯路径很长,比如你和朋友吃饭,你想知道附近有哪些好馆子,搜到的代价就就极高这种场景大量发生在哪里?聊天和查询的时候!这正是我觉得输入法切入资讯的机会,具体来讲:
这些诉求的背后数据,词汇出现的频率,输入法公司应该有足够的积累,大可根据词频做内容准备,当用户在输入东西的时候,给用户一个意外的惊喜,来达到资讯推荐的目的,希望有从事输入法这块的朋友能给予指导吧。
作者:小呆(公众号:小呆自留地),野路子出身的产品,非常诚恳的希望有同行能够给出批评和建议~谢谢
本文由 @小呆 原创发布于人人都是产品经理。未经许可,禁止转载。
