Twitter实时搜索系统EarlyBird
- - CSDN博客互联网推荐文章twitter对存档的tweet使用lucene做全量索引,新发的推文则是实时索引,实时检索(10秒之内索引). 实时索引和检索系统叫EarlyBird. 感觉写得比较清楚简洁,只要这些信息足够真实可信,完全可以做实现参考. 1)基于lucene + java,michael busch是lucene committer.
搜索系统作为用户自行使用的引导工具,重要程度不言而喻;本文主要从4步:需求识别、检索、排序、展现来总结搜索系统的工作机制。

搜索是一个比较有年份的功能,他不是一个简单的搜索框,毕竟搜索造就了一个百度帝国。
搜索系统在产品架构中是帮助用户搜索到他们想要的内容,当用户不知道如何通过其他路径直接获取特定内容的时候才会使用,也就是说搜索是用户自行使用最后的一个引导工具,重要程度不言而喻。
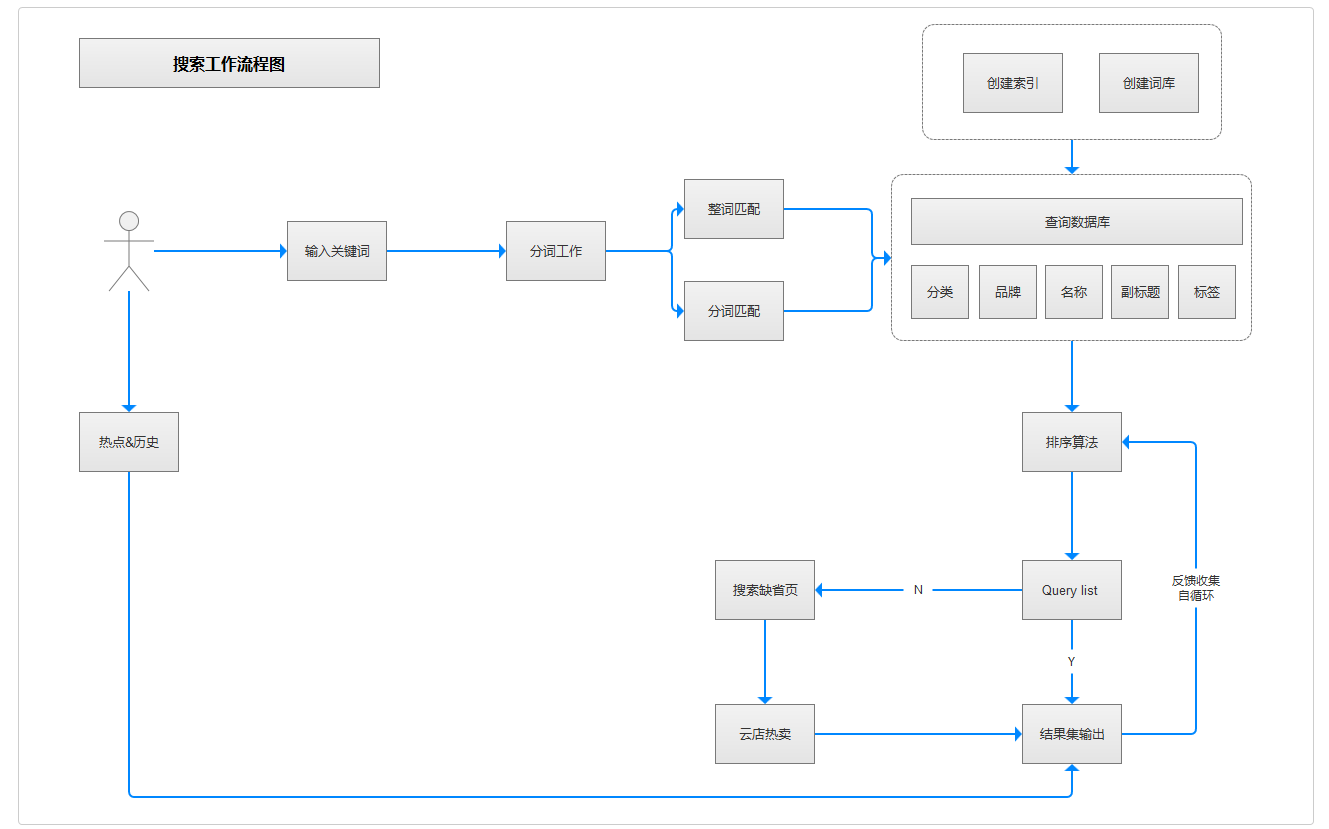
首先对搜索建立一个整体大概的认知,搜索工作机制如上图,主要分为4步:需求识别、检索、排序、展现。
用户在搜索框中输入的关键词即用户想要查询的内容,首先需要机器去识别出用户想要的是什么,才能把用户想要的东西递给用户,首先介入工作就是分词系统,通过对关键词的整分词匹配或通过语义解析尽可能的了解当前用户的需求。
接下来落实到具体的产品方案,坚持一个底层原则:从业务中来,到业务中去。
明确本次搜素策略优化目标,围绕目标高举高打:
如:能够准确识别用户query背后对商品的需求,并根据排序规则在页面反馈结果集。
关键衡量指标:
检验策略效果计算方式:
想要更好的优化方案,可以对现有的搜索关键词和模块数据进行分析,从某交易产品月上万个搜索关键词中,随机抽取了1000条搜索关键词字数分布如下图:
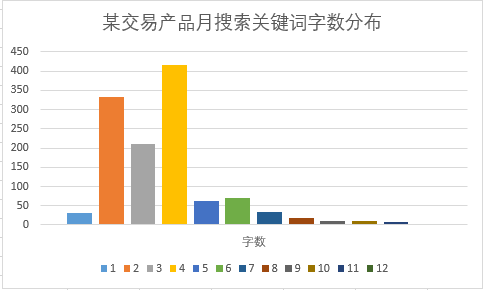
通过对用户输入的关键词进行分析,结论:
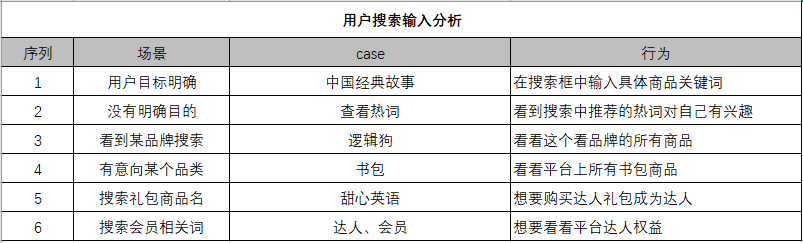
该部分需要考虑到用户在使用搜索时有什么使用场景,在不同场景下有怎样的行为反应:
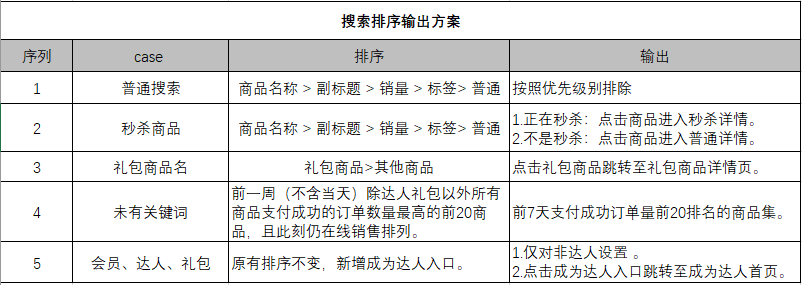
排序是整个搜素平台最为关键的一环,此处需要权衡商家、用户、平台的综合利益考虑,如商品搜索可以将特征维度分为:商品维度、卖家维度、平台维度、个性化、反作弊等维度,通过落地到自身业务的当前状态,可得出关键参考点有:
最后根据用户搜索不同的关键词,使用特定的排序方案,输入机器得出的结果集 :

本文由 @World 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。