原生Js封装的动画类 - dtdxrk - 博客园
算法用的是Tween类,需要研究的参考这篇文章:
http://www.cnblogs.com/cloudgamer/archive/2009/01/06/Tween.html
网页里常用的动画 放大缩小 位置移动 透明度改变
ssh - Invalid users trying to log in to my server - Information Security Stack Exchange
It is very common. Many botnets try to spread that way, so this is a wide scale mindless attack. Mitigation measures include:
- Use passwords with high entropy which are very unlikely to be brute-forced.
- Disable SSH login for
root. - Use an "unlikely" user name, which botnets will not use.
- Disable password-based authentication altogether.
- Run the SSH server on another port than 22.
- Use fail2ban to reject attackers' IP automatically or slow them down.
- Allow SSH connections only from a whitelist of IP (beware not to lock yourself out if your home IP is nominally dynamic !).
Most of these measures are about keeping your log files small; even when the brute force does not succeed, the thousands of log entries are a problem since they can hide actual targeted attacks. A bit of security through obscurity (such as the unlikely user name and the port change) works marvels against mindless attackers: yeah, security through obscurity is bad and wrong and so on, but sometimes it works and you will not get fried by a vengeful deity if you use it sensibly.
A high entropy password will be effective against intelligent attackers, though, and can only be recommended in all situations.
IE下iframe显示空白 - 木子丰咪咕晶 - 开源中国社区
在使用tab标签页动态添加iframe内容的标签页,IE9,IE10下在切换标签页时会出现含有iframe或frameset的页面显示为空白问题,升级到IE11最新版本问题解决,另外,如果不是动态的添加tab页,而采用静态的tab页里包含iframe也不会有在切换tab页面空白的问题;而且不管怎么样其他的浏览器都不会有该问题。这个问题应该是IE的bug。
IE8下iframe显示正常,IE9下却是空白
这个问题搞了几天了(根本原因也不清楚,反正与IE的兼容问题离不开)总之就觉得IE越来越垃圾了;
中间的坎坷就不说了,直接说出解决问题的方法吧:
页面加上如下头信息:
1 |
<meta http-equiv="X-UA-Compatible" content="IE=EmulateIE8" /> |
IE 的文档兼容模式(X-UA-Compatible),指定浏览器以哪个版本来渲染页面,content可以是IE=5/IE=6/IE=7/IE=8/IE=9/IE=edge/chrome=1
无用代码扫描工具UCDetector - 迁移到www.trinea.cn @Android @Java @性能优化 @开源 - ITeye技术网站
对于沉积或多方接手开发的项目经常会遇到一坨一坨无用的代码,但一个一个类查找又相当费时,这里介绍一个eclipse插件扫描没有引用的类、方法、常量。
插件名为UCDetector,介绍地址为http://www.ucdetector.org/index.html
eclipse update site为:http://ucdetector.sourceforge.net/update
使用方法为在工程上(可以shift选择多个模块)右击选择UCDetector->Detect unnecessary code
扫描完成后在eclipse安装目录的ucdetector_reports文件夹下生成html报告,可以进入查看
html中java type指示扫描出来的类型,截图如下

插件局限:即以下代码引用方式UCDetector无法扫描到,需要手动判断:
1、反射
2、类似spring的在xml中配置注入方式
3、第三方调用
4、jar调用
Oracle SOA Suite: Adapter - 实用主义 - ITeye技术网站
SOA架构的一个核心的使命是整合企业现存的各式各样的计算资源,它不仅仅是代码层面的整合,更是硬件,计算能力,服务能力的整合。Oracle SOA Suite在这方面做得特别的贴切,它提供了一组Adapter的组件用来包装现存的资源。
现存资源被使用的情景一般都能涵括在如下的一些方式:
* 文件交互方式,外界往相应的目录传入一个文件,系统扫描目录,获取文件指令,计算完毕后,向指定目录生成新的文件。
* 数据库访问方式,暴露一个存储过程,或者是一个Interface Table, 外界写入数据,然后触发计算。
* 队列方式 MQ 或者 AQ.
* JMS方式
* Socket方式
* EJB方式
SOA Suite的实现方式就是对于每种访问方式,都提供一个Adapter Wizard,通过图形界面程序配置就能轻易的生成这些Adapter的Web Service。 然后这些Service就可以被集成到BPEL里面去。
中国开源工作流引擎 fixteam/fixflow · GitHub
Fixflow是一款开源的基于BPMN2.0标准的工作流引擎,引擎底层直接支持BPMN2.0国际标准, 吸纳了 jBPM3 、 Activiti5、BonitaBPM 等国际开源流程引擎的精髓, 同时提供了强大的中国式流程流转处理,引擎采用微内核+插件形式设计,提供灵活的扩展模式, 建模采 用基于BPMN2.0标准的Eclipse设计器和基于Web的流程设计器,不仅仅为审批流程提供了解决方案, 同时还为复杂业务流程编排提供了强大的支持。
FixFLow本身并不具备完整的开发平台功能,它的定位是专门用于集成到现有系统的引擎。
其他Git仓库
国内访问速度比较慢的朋友可以考虑从国内的Git仓库拉取代码:
开源中国社区-中国:(https://git.oschina.net/kenshinnet/fixflow)
GitHub-美国:(https://github.com/fixteam/fixflow)
csdn_code -中国:(https://code.csdn.net/fixflow/fixflow)
贡献企业
Fixflow 项目是由社区驱动的,它的快速发展离不开企业的支持,我们欢迎更多的企业来使用Fixflow,并为社区做出贡献。
为什么选择FixFlow?
• 开源以及强大的社区支持
• 基于国际业务流程标准BPMN2.0
• 支持复杂式的中国流程流转处理
• 强大的基于BPMN2.0建模的Eclipse插件设计器
• 基于Web的流程设计器
• 强大灵活的扩展模式
• 基于图形化设计的外部系统调用连接器
• 基于Web的流程管控中心
• 专门用于集成的BPM产品
• 支持Groovy、BeanShell等多种动态
淘宝网的9.9元包邮是怎么挣钱的?商品质量好吗? - 知乎
本人是淘宝店主,发个言。
1,如果是商城,就是纯粹的冲销量,这样当买家按照销量排序的时候,或者是默认搜索的时候,销量大的商品,都会展示的比较靠前,这样以后正价销售的生意会好很多。
2,收集用户资料,得到了完整了用户联系方式,地址等信息,方便自己做二次营销。
3,对于消费者来说,有一个买熟不买生的偏好,就是如果卖手机套的这家同时也有你老婆。你老妈,你小情人的手机的壳子,你以后要买的话,也会偏向于在这家店购买,而不是换一家其他的店。
4,在淘宝后的买家界面,会自动收藏加载这家店铺的最新消息,界面有点类似微博的关注,当这家店铺上新或者主动推广一些销售信息的时候,你会优先看到,这样也是增加了购买几率。
5,虽然是9.9元包邮,但是大多数卖家还会再次赠送10元优惠劵在这个包裹里面,让你非常惊喜,除了不好意思给差评以外,也会再次在这家店购买更多的东西。赠送的消费卷一般有最低使用额度,比如100元以上订单可以使用一次10元抵扣卷。
6,卖给你的壳子和贴膜成本也许只有1元钱,扣除和快递协商的运费6元和包装费0.5元,其实已经是赚了你的钱了。赚了你的钱还让你担心卖家亏大了,这就是营销。
7,以上是卖家都知道的常识,只是大多数买家不知道而已。信息的不对称注定了大多数人就是被营销的对象。
8,本店最近也在开展类似的活动,买滑板的找我,代步或者自己锻炼都蛮好的。
本文介绍Android及IPhone手机上如何进行网络数据抓包,比如我们想抓某个应用(微博、微信、墨迹天气)的网络通信请求就可以利用这个方法。
相对于tcpdump配合wireshark抓包的优势在于:(1)无需root (2)对Android和Iphone同样适用 (3)操作更简单方便(第一次安装配置,第二次只需设置代理即可) (4)数据包的查看更清晰易懂,Fiddler的UI更简单明了 (5) 可以查看https请求。如果你坚持使用tcpdump也可见:利用tcpdump和wireshark抓取网络数据包。
PS:需要1台PC做辅助,且PC需要与手机在同一局域网内或有独立公网ip
1、PC端安装Fiddler
下载地址:Fiddler.exe,下面是Fiddler的简单介绍(不感兴趣的可以直接跳过):
Fiddler是强大且好用的Web调试工具之一,它能记录客户端和服务器的http和https请求,允许你监视,设置断点,甚至修改输入输出数据,Fiddler包含了一个强大的基于事件脚本的子系统,并且能使用.net语言进行扩展,在web开发和调优中经常配合firebug使用。
Fiddler的运行机制其实就是本机上监听8888端口的HTTP代理。 对于PC端Fiddler启动的时候默认IE的代理设为了127.0.0.1:8888,而其他浏览器是需要手动设置的,所以如果需要监听PC端Chrome网络请求,将其代理改为127.0.0.1:8888就可以监听数据了,手机端按照下面的设置即可完成整个系统的http代理。
2、 配置PC端Fiddler和手机
(1) 配置Fiddler允许监听https
打开Fiddler菜单项Tools->Fiddler Options,选中decrypt https traffic和ignore server certificate errors两项,如下图:
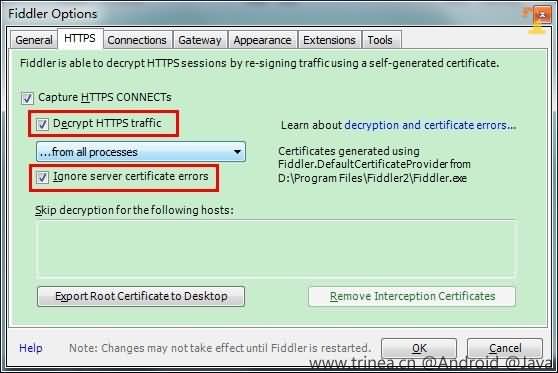
第一次会提示是否信任fiddler证书及安全提醒,选择yes,之后也可以在系统的证书管理中进行管理。
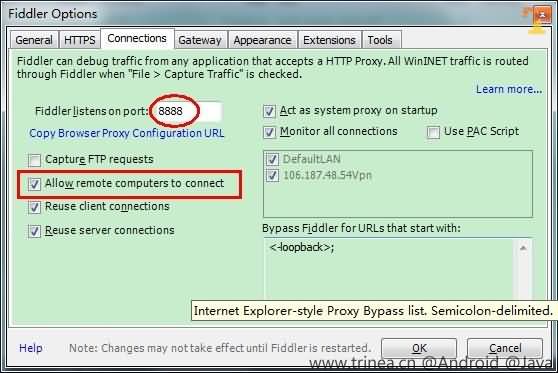
(2) 配置Fiddler允许远程连接
如上图的菜单中点击connections,选中allow remote computers to connect,默认监听端口为8888,若被占用也可以设置,配置好后需要重启Fiddler,如下图:
(3) 配置手机端
Pc端命令行ipconfig查看Fiddler所在机器ip,本机ip为10.0.4.37,如下图
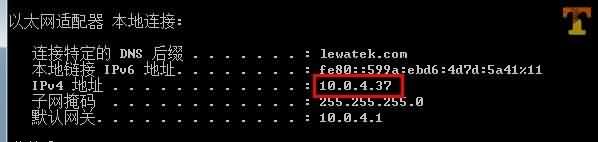
打开手机连接到同一局域网的wifi,并修改该wifi网络详情(长按wifi选择->修改网络)->显示高级选项,选择手动代理设置,主机名填写Fiddler所在机器ip,端口填写Fiddler端口,默认8888,如下图:
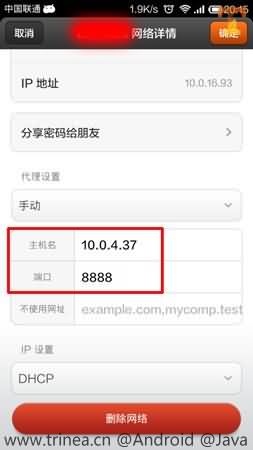
这时,手机上的网络访问在Fiddler就可以查看了,如下图微博和微信的网络请求:
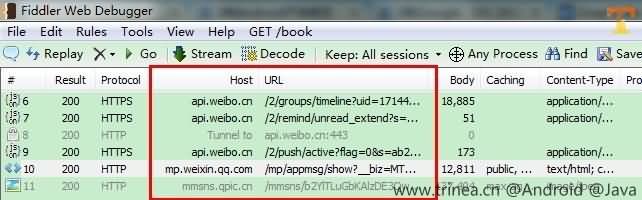
可以双击上图某一行网络请求,右侧会显示具体请求内容(Request Header)和返回内容(Response Header and Content),如下图:
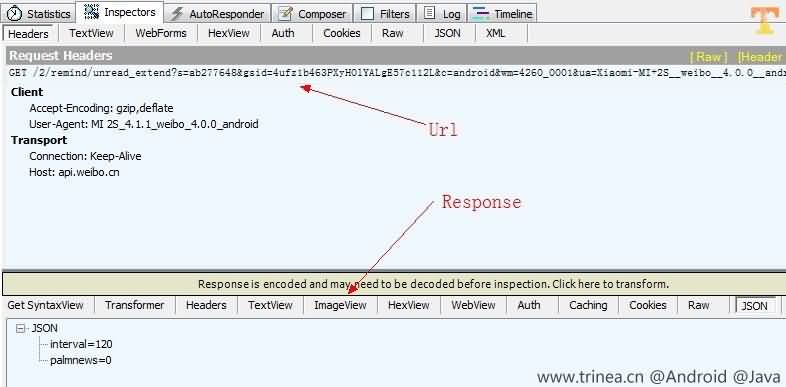
可以发现Fiddler可以以各种格式查看网络请求返回的数据,包括Header, TextView(文字), ImageView(图片), HexView(十六进制),WebView(网页形式), Auth(Proxy-Authenticate Header), Caching(Header cache), Cookies, Raw(原数据格式), JSON(json格式), XML(xml格式)很是方便。
停止网络监控的话去掉wifi的代理设置即可,否则Fiddler退出后手机就上不网了哦。
如果需要恢复手机无密码状态,Android端之后可以通过系统设置-安全-受信任的凭据-用户,点击证书进行删除或清除凭据删除所有用户证书,再设置密码为无。
如果只需要监控一个软件,可结合系统流量监控,关闭其他应用网络访问的权限。
精益用户体验的原则 | 曉生
原则1:夸职能团队
这是什么?跨职能团队是由具有多种学科背景的成员组建而成来创建产品一种团队结构。具有软件工程,产品管理,交互设计,视觉设计,内容策略,市场营销,和质量保证(QA)学术背景的人才都应该被吸收在精益用户体验团队之内。精益用户体验要求多学科之间实现高水平的的合作。他们的参与必须持之以恒,不能半途而废,从项目开始的第一天直到项目的最后一天。
为什么这样做?多样化的团队模式颠覆了传统的所谓的瀑布式的环环相连的设计方式。不同学术背景的成员在设计初期都可以针对每个想法提出自己的看法。团队中鼓励跨部门交流,以此带动团队效率的提升。
原则2:小型,专用,聚集
这是什么?简化团队规模,保持你的团队核心成员数量不超过10人。所有成员都要聚在一起,共同投入到一个项目里。
为什么这样做?小团队的利益归结为三个词:交流,聚焦,和友情。规模较小的团队更容易对项目阶段,内容变更和新的认知保持流畅状态。将团队投入到一个项目中,保持团队中的每个人都一直将其放在同一个优先级之上。团队成员都聚在同一个地方可以让同事之间的良好关系迅速建立起来。
原则3:项目进展=成果,不是输出
这是什么?功能和服务都是输出物。商业目标要实现的是产品或服务所带来的成果。精益用户体验依据明确定义的商业成果来评估项目进展。
为什么这样做?当我们试图预测哪些功能将会带来特定成果的时候,通常都可看做是一种投机行为。虽然特定功能在上线发布前很容易管理,但我们同样对其有效性一无所知,直到它真正投放到市场中。通过管理成果的方式(以及二者的所带来的进展),我们便可以掌握我们创建的功能的效果。如果某个功能运行的不好,我们可以做出客观的决策:维持原状,改变策略,或替换其它功能。
原则4:问题焦点的团队
这是什么?问题焦点的团队是一个旨在解决商业问题而不是关注与某一项功能实现的团队。这是对关注成果收益团队的一种逻辑上的延伸。
为什么这样做?让团队独立解决商业问题显示了对整个团队的信任。允许团队成员提出自己的解决方案,能够驱动成员在解决团队所面临的问题时的那种内心深处的荣誉感和主人翁意识。
原则5:减少浪费
这是什么?精益制造的一个核心原则就是将移除那些与实现最终目标无关的要素。在实践精益用户体验时,最终目标是优化改进的成果;因此,任何与改进成果无关的要素都可以认为是一种变相的浪费,理应从团队的实践过程中剔除出去。
为什么这样做?团队资源是有限的。队提出的浪费资源的要素越多,团队运作地越快。团队想要的是一个高效的运作团队,能够在工作中直面挑战。去除浪费,能够让团队的精力聚焦在问题的关键点上。
原则6:小批量
这是什么?另一个来源于精益制造的基本原理是小批量的使用。精益制造通过践行这个理念来保持低库存和高质量的平衡。将这个理念移植到精益用户体验上,这也就意味着创建一个设计原型是推动团队工作进程的必要做法,用以避免大的未测试的“库存”和未实现的设计思想。
为什么这样做?大批量的设计带来的是低下的团队工作效率。因为需要迫使团队
等待大批量的设计交付。这阻碍了团队去验证想法理念的有效性,让一些团队成员不可避免空闲下来无所事事,也导致一些设计想法被搁置下来最终没有使用上。这种方法是一种对资源的浪费,没有大限度地提高团队整体的认知潜能。
原则7:持续的发现
这是什么?持续的发现是指在设计和开发阶段中用户持续参与的过程。这种参与过程是通过定期活动,采用定量和定性的方法来实现的。我们的目标是了解用户如何使用你的产品,为什么他们要这样做。按时间表定期做研究,研究涉及整个团队的参与。
为什么这样做?定期与用户谈话给团队提供了更多验证新产品想法的机会。通过将整个团队成员都融入到研究周期中,团队能够建立起用户和其面临问题的同理心。最后,团队成员聚在一起参与探讨,可以减少今后对口头交流和文档汇报需要。
原则8:GOOB 新的以用户为中心方法
这是什么?这听起来像一个婴儿的第一声言语,但GOOB实际上对斯坦福大学教授、企业家和作者史蒂夫·布兰克提出的所谓的“走出大楼”的缩写。这是因为人们意识到,在会议室里讨论用户需求是什么最终也得到想要的解决方案。相反,问题的答案就在市场当中,在你办公室大楼外面。在倡导用户研究多年之后,用户体验研究人员最终得到了来自商业领域的史蒂夫·布兰克的支持。布兰克的建议是:让你的潜在用户对你的想法提供比过去更快的反馈。在设计初期便用残酷的事实来测试你的想法。最好早些发现在设计方向上的错误,以免你花费时间和资源去创建一个最终无人问津的产品。
为什么这样做?最终,成功或失败的产品也不是由团队,而是由用户决定的。“现在购买”按钮是由你设计的,但是否点击取决于用户。如果你越早得到用户的反馈,你就能越快知道的想法是否行得通。
原则9:共识
这是什么?共识是团队在长期的合作过程中建立起来的一种共同理解,包括对问题领域、产品和用户的丰富理解。
为什么这样做?共同理解在精益用户体验中是必须的。如果团队成员对正在做什么和为什么这么做达成共识,那么团队便不需要依赖二手的研究报告和详细的文档来继续接下来的工作。
原则10:反面教材——明星,大师,和高手
这是什么?精益用户体验倡导一种基于团队协作的心态,而明星,大师,高手以及其他精英专家会采取不合作的态度,破坏团队凝聚力。
为什么这样做?明星既不会与你共享他们的想法,也不会分享聚光灯下的荣耀。当团队中某个人自我意识强烈,并决心站出来成为明星时,团队凝聚力霎时间土崩瓦解了。当合作被打破,团队失去了之前创立的推动项目高效运作的团队共识的大环境,不可避免地会再次陷入不断地重复设计的过程之中。
原则11:外化工作
这是什么?外化的意思是将你头脑和计算机中的想法和方案都展示给公众。用泡沫塑料板,白板,绘图墙,打印的纸条和便笺让他们的团队成员,同事,和用户看到团队的工作进展。
为什么这样做?外化工作将每个团队成员头脑中的想法展示在了墙上,让每个人都看到团队现在处于哪个阶段。这就建立了一种团队内持续流动的信息流,从共享中汲取系想法,启发新思路。它可以让所有的队员——即使是平时少言寡语的人——都参与到信息共享活动中来。便笺条或白板草图与团队中最突出的成员在团队中的地位同等重要。
原则12:做事优于分析
这是什么?精益用户体验提倡做事优于分析。将想法尽快创建出第一个版本比在会议室里花半天时间讨论它的优点是什么更有意义。
为什么这样做?遇到难题,在会议室里是找不到答案的。相反,问题的答案存在于用户那里。为了找到这些问题的答案,你需要把想法具体化——你需要做出一些能够让人们给予反馈的东西。针对想法的争论是在浪费时间和精力。做出一些东西,走出大楼去验证它,而不是在房间里分析各种可能的情况。
原则13:学习优于增长
这是什么?在同一时间里找到产品的合适定位并扩展业务范围是很难的一件事。他们是一个矛盾体。精益用户体验主张的是学习认知第一,业务扩展第二。
为什么这样做?随意扩展一个未经证实的想法是一件危险的事情。它可能会达到目的,也可能不会。如果它最终被证实不能达到目的,而你已经将它扩大到整个用户群当中了,那么就意味着整个团队是浪费了之前宝贵的时间和资源。在扩展之前一定要确保想法是正确的,以减轻广泛的功能部署的固有风险。
原则14:失败的权利
这是什么?为了找到商业问题的最佳解决方案,精益用户体验团队需要通过实验来验证想法,而且大多数的想法会证明是错误的。团队如果想要获得成功,就必须遇到失败时能够安全化解。拥有失败的权利意味着团队需要有一个安全的实验环境。这种环境既指于技术环境——他们可以以一种安全的方式推动想法落实,也指文化环境——他们不会因为想法被验证是失败的而受到惩罚。
为什么这样做?失败的权利产生了所谓的实验文化,即实验孕育了创新,反过来,创新产生了新的解决方案。当团队不再为工作结果的失败而担惊受怕的时候,他们更倾向于冒险尝试,那些好的想法最终都源自于高风险的尝试之中。俗话说失败是成功之母,在这里同样适用。
在视频“为什么你需要失败”中,CD Baby 的创始人德里克·塞维斯讲述了陶瓷课上的一件趣事。上课第一天老师就宣布,学生将分被成两组。
一组学生每学期只需要做一个陶罐,他们的成绩将取决于那个陶罐的制作质量。另一组学生则是通过他们在学期制作的陶罐的重量打分。如果他们做了50磅的陶罐或更多,他们会得到一个A,40镑将获得B,30镑为C以此类推。成绩与他们实际做的是什么一点关系都没有。老师说他甚至不会看他们做的陶罐,他只会在学期最后一天将他浴室的体重秤拿来的给学生做得东西称重。
在学期结束时,一个有趣的事情发生了。课程的外部观察人员指出,最高质量的陶罐已经由“重量决定”的小组完成了。他们花了整个学期的工作尽可能迅速地制作陶罐,有时成功有时失败。但是他们从每一次实验中都学到了新的东西。通过这个学习过程,他们更好地达到了最终目标:制造高品质的陶罐。
相比之下,只做一个陶罐的那组学生,由于没有经历失败,也就无法从中快速学习成长,也就没有“重量决定”组的学生做得好。他们花了一学期时间在思考如何去制作一个能够达到A等级的陶罐的方法,但没有执行这一宏伟的想法的具体实践活动。
原则15:莫谈交付
这是什么?精益用户体验设计过程就是从创建输出文档到实现最终成果团队的转变。随着跨职能协作的增加,团队与利益相关者之间的谈话也不再是关于具体要做什么东西,而是更多关注要实现什么目标,成果如何。
为什么这样做?最终好的产品而不是文档来解决用户面临的问题。团队应该把关注重点放在认识对用户起到主要作用和影响的功能上。用什么产品原型去发掘并不重要,最重要的是产品的质量如何,而质量的好坏是通过市场对其的反馈来确定的。
android voip你选哪一个 SipDroid,IMSDroid,CSipsimple,Linphone,webrtc?-Android开发进阶&经验分享-eoe Android开发者社区_Android开发论坛 - Powered by Discuz!
最新要做一个移动端视频通话软件,大致看了下现有的开源软件
一) sipdroid
1)架构
sip协议栈使用JAVA实现,音频Codec使用skype的silk(Silk编解码是Skype向第三方开发人员和硬件制造商提供免版税认证(RF)的Silk宽带音频编码器)实现。NAT传输支持stun server.
2)优缺点:
NAT方面只支持STUN,无ICE框架,如需要完全实现P2P视频通话需要实现符合ICE标准的客户端,音频方面没看到AEC等技术,视频方面还不是太完善,目前只看到调用的是系统自带的MediaRecorder,并没有自己的第三方音视频编解码库。
3)实际测试:
基于sipdroid架构的话,我们要做的工作会比较多,(ICE支持,添加回音消除,NetEQ等gips音频技术,添加视频硬件编解码codec.),所以就不做测试了。
二) imsdroid
1)架构:
基于doubango(Doubango 是一个基于3GPP IMS/RCS 并能用于嵌入式和桌面系统的开源框架。该框架使用ANSCI-C编写,具有很好的可移植性。并且已经被设计成非常轻便且能有效的工作在低内存和低处理能力的嵌入式系统上。苹果系统上的idoubs功能就是基于此框架编写) .音视频编码格式大部分都支持(H264(video),VP8(video),iLBC(audio),PCMA,PCMU,G722,G729)。NAT支持ICE(stun+turn)
2)效果实测
测试环境:公司局域网内两台机器互通,服务器走外网sip2sip
音频质量可以,但是AEC打开了还是有点回音(应该可以修复)。视频马赛克比较严重,延迟1秒左右。
3)优缺点
imsdroid目前来说还是算比较全面的,包括音视频编解码,传输(RTSP,ICE),音频处理技术等都有涉猎。doubango使用了webrtc的AEC技术,但是其调用webrtc部分没有开源,是用的编译出来的webrtc的库。如果要改善音频的话不太方便,Demo的音频效果可以,视频效果还是不太理想。
三)csipsimple
1)sip协议栈用的是pjsip,音视频编解码用到的第三方库有ffmpeg(video),silk(audio),webrtc.默认使用了webrtc的回声算法。支持ICE协议。
2)优缺点:
csipsimple架构比较清晰,sip协议由C实现,java通过JNI调用,SIP协议这一块会比较高效。其VOIP各个功能也都具备,包括NAT传输,音视频编解码。并且该项目跟进新技术比较快,官方活跃程度也比较高。如果做二次开发可以推荐这个。
3)实测效果
测试环境:公司局域网内两台机器互通,服务器走外网sip2sip
音频质量可以,无明显回音,视频需要下插件,马赛克比imsdroid更严重。
四)Linphone
这个是老牌的sip,支持平台广泛 windows, mac,ios,android,linux,技术会比较成熟。但是据玩过的同事说linphone在Android上的bug有点多,由于其代码实在庞大,所以我暂时放弃考虑Linphone.不过如果谁有跨平台的需要,可以考虑Linphone或者imsdroid和下面的webrtc.。。。好像现在开源软件都跨平台了。。。
五) webrtc
imsdroid,csipsimple,linphone都想法设法调用webrtc的音频技术,本人也测试过Android端的webrtc内网视频通话,效果比较满意。但是要把webrtc做成一个移动端的IM软件的话还有一些路要走,不过webrtc基本技术都已经有了,包括p2p传输,音视频codec,音频处理技术。不过其因为目前仅支持VP8的视频编码格式(QQ也是)想做高清视频通话的要注意了。VP8在移动端的硬件编解码支持的平台没几个(RK可以支持VP8硬件编解码)。不过webrtc代码里看到可以使用外部codec,这个还是有希望调到H264的。
总结:sipdroid比较轻量级,着重基于java开发(音频codec除外),由于其音视频编码以及P2P传输这一块略显不足,不太好做定制化开发和优化。imsdroid,遗憾就是直接调用webrtc的库,而最近webrtc更新的比较频繁,开发比较活跃。如果要自己在imsdroid上更新webrtc担心兼容性问题,希望imsdroid可以直接把需要的webrtc相关源码包进去。csipsimple的话,都是围绕pjsip的,webrtc等都是以pjsip插件形式扩充的,类似gstreamer. webrtc如果有技术实力的开发公司个人还是觉得可以选择这个来做,一个是google的原因,一个是其视频通话相关关键技术都比较成熟的原因。个人觉得如果能做出来,效果会不错的。
以上仅是个人观点,每个项目需求不一样,选择可能也不一样。欢迎大家跟贴讨论交流或者QQ交流
QQ34280027
android 视频通话 项目 源码 - android大牛MrJing 活动中心 - 博客频道 - CSDN.NET
几个开源的视频会议、SIP服务器:
Telepresence:https://code.google.com/p/telepresence/
Yate:http://yate.null.ro/pmwiki/
Doubango:http://www.cnblogs.com/DreamSea-for-Jimmy/archive/2011/07/28/2119877.html
一、开源voip有哪些
SIPDroid、linphone、imsdroid
SIPDroid:纯java语言开发
Linphone:基于多个平台,但android下的bug较多,很难正常的通话。
Imsdroid:底层基于doubango的开源代码,更新比较及时.
Linphone和Imsdroid的底层均是c语言,支持的平台比较广泛.
二、源码如何获取
Linphone:http://www.linphone.org/需安装git工具.
不知道是否因为git工具的问题,经常没下午便断开,需获取多次,才能获取到完整的代码.
Imsdroid:这个首先必须安装svn.需先下载doubango的源码,然后再下载Imsdroid的源码. Imsdroid的源码位置: http://code.google.com/p/imsdroid/source/checkout, doubango的源码位置:http://code.google.com/p/doubango/source/checkout.
三、编译重需注意;
Linphone:编译过程还需要下载其他的内容,可以直接复制网址到ie中进行下载.
如果你是在windows下使用cygwin,最好链接的时候会出现一个致命的错误,那就是argument list too long,这种情况下,最好直接放到linux下去编译,该问题便可以解决.升级cygwin的版本也很难解决该问题.
Linphone的java工程要求sdk为2.3版本,对我们这种在公司网络不好的人来说,这是最悲催的事了.
Imsdroid:分为两部分:doubango和imsdroid的编译.
Doubango:windows下编译会有一大堆的错误,还是果断放弃windows,转到linux下编译好了.但建议最好编2.0版本,2.0的编译方法需要到wiki中查找, 参考http://code.google.com/p/imsdroid/wiki/Building_IMSDroid_v2_x这个网页.最好生成一个动态库tinyWRAP.so.
Imsdroid的编译:最后要生成apk文件,必须首先编译android-ngn-stack工程,该工程编译成功后,会生成jar文件,供imsdroid工程使用.
Oracle 数据库隔离级别,特性,问题和解决方法 - 1-2-3 - 博客园
Oracle的序列化(serializable)隔离级别
序列化,顾名思义,是让并发的事务感觉上是一个挨一个地串行执行的。之所以说是“感觉上”,是因为当2个事务并发时,Oracle并不会阻塞其中一个事务去等待另一个事务执行完毕再执行,而是仍然让2个事务同时并行,那么如何能“感觉”是串行的呢?请看下图的实验。

用户B的事务因为指定了serializable隔离级别,所以虽然在查询费用明细表之前,用户A提交了对费用明细表的更改,但是因为用户A提交的更改是在用户B的事务开始之后才提交的,所以这个更改对用户B的事务不可见。也就是说,用户B的事务开始之后,其它事务提交的更改都不会再影响事务内的查询结果,这样感觉上用户A的事务好像是在用户B的事务结束之后才执行的似的。这本来是非常好的一个特性,极大地提高了并行性,但是也会造成问题。
问题1:Oracle的这种“假串行”会让严格依赖于时间的程序产生混乱。
请看下图这个例子,对费用结算的例子稍稍做了一点改动。

程序员的本意是统计2012-3-4这天从零点至运行程序之时的费用总额。如果他以为 Oracle 的 serializable 会像 C# 的 lock 一样阻塞其它事务的话,就会对结果非常吃惊:在2012-3-4 0:00 ~ 2012-3-4 10:02 实际有3条费用明细,总额为20+30+100=150,而不是用户B的事务统计得出的50。
问题2:ORA-08177 Can't serialize access for this transaction (无法序列化访问)错误。
如果你使用了 serialize 隔离级别,没准你的客户会经常抱怨这个随机出现的错误。兄弟,你并不孤独!
导致这个错误的原因有2个:
(1) 两个事务同时更新了同一条数据。你可以这样重现这个错误:事务B开始(使用serialize 隔离级别) => 事务A开始,更新 表1.RowA 但不提交 => 事务B更新表1.RowA,因为行锁定而被阻塞 => 事务A提交 => 事务B报 ORA-08177 错误。
(2) 事务所更新的表的 initrans 参数太小。Oracle 官方文档的说法是,如果使用了 serialize 隔离级别,表的 initrans 参数最小要设置成3(默认是1)。
alter table 费用明细表 initrans 3;
原文:“Oracle Database stores control information in each data block to manage access by concurrent transactions. Therefore, if you set the transaction isolation level to SERIALIZABLE, then you must use the ALTER TABLE command to set INITRANS to at least 3. This parameter causes Oracle Database to allocate sufficient storage in each block to record the history of recent transactions that accessed the block. Higher values should be used for tables that will undergo many transactions updating the same blocks.”
注意,人家说的是“最小是3”。我用自己笔记本里的 32 位 Oracle10g 测试的结果是设置成 3 也会频繁地报 ORA-08177 错误。后来改成5 和 10,都不行。改成50,终于不报错了。但是都说了这个错误是随机的,有时候3也没问题的——反过来说,设置成50也未必保险。坑爹啊!真坑爹!!这就像菜谱里面写的“放入适量的油……”,他喵的到底多少算是“适量”啊?!!!
有兴趣的读者可以使用下图的语句实际测试一下。

我的建议是,还是尽量不要用 serialize 隔离级别吧,用户是不会理解什么叫“无法序列化访问”的,他只会觉得你的“XX功能会随机地不好用”倒是真的。稍后我们再简单讨论一下不用 serialize 隔离级别如何避免幻读。现在先来看一下 Oracle 官方文档建议的适合使用 serialize 隔离级别的3种情况。
(1) With large databases and short transactions that update only a fewrows(大数据库、只更新几条数据的短事务)
(2) Where the chance that two concurrent transactions will modify thesame rows is relatively low(2个并发事务更新同一条数据的几率不大)
(3) Where relatively long-running transactions are primarily read only(相对运行时间较长的事务主要用来读取数据)
使用默认的 read committed 隔离级别,如何避免幻读产生的问题
使用默认的 read committed 隔离级别,如何编写程序才能避免幻读产生的问题呢?首先,无论是“不可重现的读取(nonrepeatable read)”还是“幻读(phantom read)”,都是因为程序反复读取数据产生的。所以首先需要做的是,在一个事务里确保只读取数据一次。最好用C#而不是存储过程实现业务逻辑,这样很容易做到只读取一次,然后把结果存放到IList或IDictionary里。比较难办的是需要更新数据的情况。回顾一下前面所举的幻读的例子。

事务B使用相同的条件进行了2次查询/筛选,一次是为了向费用结算表插入汇总数据,一次为了确定对费用明细表的更新范围。在这两次筛选之间,事务A提交了一条新的费用明细数据,导致两次筛选的结果不一致。要避免这个问题,还是要贯彻“只读取一次”的原则,或者更广义地说,是“只确定一次筛选范围”。大致有2种方法。
<法一> 可以先把符合条件的费用明细读取出来保存到一个列表里,然后无论统计还是更新,都局限于这个列表里的数据。下面的C#代码与上图的功能相同,但是没有幻读的问题。

// 用户B的事务开始
IList<费用明细> chargeList = 费用明细Repository.获取未结算列表();
费用结算 balance = new 费用结算
{
总金额 = chargeList.Sum(t => t.金额),
结算编号 = "J122"
};
费用结算Repository.Save(balance);
// 这时候用户A提交了一条新的费用明细,不过没关系
foreach(费用明细 charge in chargeList)
{
charge.是否已结算 = 1;
charge.结算编号 = "J122";
费用明细Repository.Update(charge);
}
这个方法的缺点是要对 chargeList 里的每个实体 Update 一次,如果数据量较大可能会有性能问题。这时候可以用<法二>。
注 本文为了表述的方便使用了中文和英文混杂的代码,实际编程的时候不要这样做。
<法二> 使用事务B独有的方法标识出操作数据的范围。

注 虽然上图是用SQL语句来演示的,使用C#(实体+ORM)同样可以用这种方法。
严格依赖时间的程序

严格来说这并不是幻读造成的问题——事务A还没提交呢。这种设计十分危险,无论使用 read committed 还是 serializable 隔离级别都不足以避免并发造成的不一致,应该尽量避免这样的设计。依赖时间很危险,因为系统时间是随时可能被系统管理员更改的,更别提有些国家和地区会实行夏时制,想想看,事务B提交了之后,系统时间被回拨了1小时!
然而世事往往不尽如人意,你可能不幸遇到了这样一个遗留系统,或者用户有很多其它的业务或与你交互的系统严格依赖于时间而逼得你不得不这么做的时候,该怎么办呢?
<法一> 在业务逻辑层面,可以把用户B和用户A的两个方法使用C#提供的线程同步技术串行化——理论上行的通,但是操作费用明细实体的方法那么多,很容易有所遗漏。
<法二> 在Repository层面,为费用明细实体设置一个令牌,并且可以设置是否进入令牌模式。在令牌模式下,费用明细Repository里面的所有持久化操作都必须拿到令牌才能操作,拿不到令牌直接抛异常。平时的业务操作都在非令牌模式下工作。在用户B想要进行结算操作时,事务开始之后,马上设置成令牌模式,然后获取令牌,这样就能确保此时只有用户B才能操作费用明细表了。此法虽然并发性很差,但是既简单又保险。而且很多时候像结算这样的操作一个月(或一天)只进行一次,并发性差一些也可以忍受。值得注意的是下面这种情况。

虽然发生的概率不高,但是让令牌法彻底失效了。综合考虑系统时间被管理员改变的可能性,仅仅在结算事务里独占令牌也是不够的,还必须在费用明细Repository.Save()方法里验证费用明细.创建时间必须大于最近一次的结算时间。
条形码编码原理解析 | AIR20
条形码在我们的日常生活中非常常见。我们平时购买的各种商品,还有书籍上都印有条形码。条形码可以方便商家管理商品的库存,控制售价。物流中运用条形码可以实现快速扫包,将快递发往正确的目的地,免去了人工分拣的麻烦。今天我们就来看看条形码是如何编码的。
首先,条形码的种类很多,不同种类所应用的范围也各不相同。例如买的饮料上印的条形码,和汽车上还有火车票上的条形码显然不是同一种。本文将主要介绍EAN-13条形码。EAN-13(European Article Number)原本是欧洲标准,后来被采纳为国际标准,被广泛世界各国应用在商品编码和书籍编码(ISBN)中。
下图是一个常见的条形码,我们以它为例,来讲讲条形码是如何编码的。
 味全麦香味酸牛奶的条形码
味全麦香味酸牛奶的条形码
首先,我们注意到下面的一串 13 位数字,这是我们要编码的内容。前三位 693 代表是中国大陆生产(690 - 699 都是保留给中国大陆的),紧接着有四位的制造商代码和五位的产品代码,最后一位是校验码,用来检验条码是否有输入错误,详细说明请参考身份证和条形码中的校验码。大家很容易猜到,条形码的存储的信息是通过粗细不同的黑白条纹的不同排列组合来实现的,事实也的确如此,如果用 1 来表示单位宽度的黑色条纹,0 来表示单位宽度的白色条纹,那么条形码可以认为是一个二进制序列,这个二进制序列的长度是 93 位。仔细观察不难发现,在条形码的最左侧、中间和最右侧都有两根稍长的细竖线,分别可以用 101, 01010, 101 来表示。13 位的数字,第一位在最左侧,然后这些竖线将剩余的 12 位分成了两部分 6 位的数码。
在左边的前六位和右边的后六位中,每一位数字都可以由一个长度为 7 的二进制序列表示,每一个数码有三种不同的编码方式A、B、C,如下表所示:
| 数码 | A方式 | B方式 | C方式 |
|---|---|---|---|
| 0 | 0001101 | 0100111 | 1110010 |
| 1 | 0011001 | 0110011 | 1100110 |
| 2 | 0010011 | 0011011 | 1101100 |
| 3 | 0111101 | 0100001 | 1000010 |
| 4 | 0100011 | 0011101 | 1011100 |
| 5 | 0110001 | 0111001 | 1001110 |
| 6 | 0101111 | 0000101 | 1010000 |
| 7 | 0111011 | 0010001 | 1000100 |
| 8 | 0110111 | 0001001 | 1001000 |
| 9 | 0001011 | 0010111 | 1110100 |
若干个连续的 1 表示一个较宽的黑色条纹,而若干个连续的 0 则表示一个较宽的白色条纹。从上表我们不难看出:
- 每一个数码都是由黑白相间的 4 个条纹构成的并且总长度为 7(满足这样条件的序列有 40 个但只有 30 个用在编码中);
- 同一个数码的编码方式C和A是互补的,即交换 0 和 1;
- 同一个数码的编码方式B是C的反序排列。
我们可以先来把最右侧的 6 位进行编码,直接参照编码方式C进行转换即可。021471 对应 42 位的二进制序列:
1110010 1101100 1100110 1011100 1000100 1100110
这样就完成了右半部分的编码,大家可以把编码跟上图对照进行检验。
同时左半部分的 7 位根据前置码(第一位数码)的不同交替使用编码方式A和B进行编码,前置码不参与编码,如下表所示:
| 首位 | 第 2 位 | 第 3 位 | 第 4 位 | 第 5 位 | 第 6 位 | 第 7 位 |
|---|---|---|---|---|---|---|
| 0 | A | A | A | A | A | A |
| 1 | A | A | B | A | B | B |
| 2 | A | A | B | B | A | B |
| 3 | A | A | B | B | B | A |
| 4 | A | B | A | A | B | B |
| 5 | A | B | B | A | A | B |
| 6 | A | B | B | B | A | A |
| 7 | A | B | A | B | A | B |
| 8 | A | B | A | B | B | A |
| 9 | A | B | B | A | B | A |
味全酸牛奶的条码的第一位是 6,因此接下来 6 位的编码依次采用ABBBAA,参照第一个表,932571 的编码应当为:
0001011 0100001 0011011 0111001 0111011 0011001
将他们放到左半部分,至此,我们的编码就完成了,大家可以对照图片检验一下。有了编码方法,相应的解码也就很容易了,大家可以试一试。
另外现在二维码也很流行,大家可以参照 ISO/IEC 18004 学习二维码的编码原理。
Jackson 框架,轻易转换JSON - hoojo - 博客园
Jackson是性能排在前列的json序列化工具,推荐使用。Jackson可以轻松的将Java对象转换成json对象和xml文档,同样也可以将json、xml转换成Java对象。
前面有介绍过json-lib这个框架,在线博文:http://www.cnblogs.com/hoojo/archive/2011/04/21/2023805.html
相比json-lib框架,Jackson所依赖的jar包较少,简单易用并且性能也要相对高些。而且Jackson社区相对比较活跃,更新速度也比较快。
一、准备工作
1、 下载依赖库jar包
Jackson的jar all下载地址:http://jackson.codehaus.org/1.7.6/jackson-all-1.7.6.jar
然后在工程中导入这个jar包即可开始工作
官方示例:http://wiki.fasterxml.com/JacksonInFiveMinutes
因为下面的程序是用junit测试用例运行的,所以还得添加junit的jar包。版本是junit-4.2.8
如果你需要转换xml,那么还需要stax2-api.jar
public class JacksonTest {
private JsonGenerator jsonGenerator = null;
private ObjectMapper objectMapper = null;
private AccountBean bean = null;
@Before
public void init() {
bean = new AccountBean();
bean.setAddress("china-Guangzhou");
bean.setEmail("[email protected]");
bean.setId(1);
bean.setName("hoojo");
objectMapper = new ObjectMapper();
try {
jsonGenerator = objectMapper.getJsonFactory().createJsonGenerator(System.out, JsonEncoding.UTF8);
} catch (IOException e) {
e.printStackTrace();
}
}
@After
public void destory() {
try {
if (jsonGenerator != null) {
jsonGenerator.flush();
}
if (!jsonGenerator.isClosed()) {
jsonGenerator.close();
}
jsonGenerator = null;
objectMapper = null;
bean = null;
System.gc();
} catch (IOException e) {
e.printStackTrace();
}
}
}