WebView JS 交互
- - ITeye博客WebView加jquery做页面会怎么样呢. // 创建WebView对象. // 把programList添加到js的全局对象window中,. // 这样就可以使用window.programList来获取数据. * 定义js回调java函数. // 绑定键盘的向上,向下按钮事件触发相应的js事件.
在过去的几年里,我逐渐将兴趣由桌面转移到web上。我对于能在任何设备上用浏览器访问的app的这种方式很是着迷。我有用过HTML,CSS,Flash和PHP的经验,所以我很熟悉这一领域–但是我只曾做过网站,而不是web app。我开始深入了解Rails,并立刻爱上了它,我所熟知的Flash的快速反应被替换成了页面加载。因此,我转向了Javascript。
就像学校新来的小孩,关于框架我分不清谁是谁。我寻找着,发觉 Backbone.js 几乎在每个地方都能见着,于是我便假定他是个标准。几个月后,我发现它不是为我准备的– Backbone.js 缺乏清晰的使用方向。每个我阅读过的教程都使用着不同的结构,这感觉太容易忽视常规有效的设计模式。
开始学习 Spine.js ,我花了一个晚上通读了用户手册以及试验它的示例app,我看到的一切看起来都挺好。那一晚,我是带着灿烂睡觉的,即使我真的很难入眠,因为我等不急想使用它了。什么让我如此兴奋呢?就是下面的这是个理由:
1、清晰的结构

Spine.js 遵循MVC模式,我写的所有应用都遵循着MVC架构,所以我很快就知道该怎么用Spine.js组织我的应用结构。这种似曾相识的感觉太棒了。这使得哪个类在干什么,哪个类是激活的清晰明了。
2、模型就是模型

Backbone.js也有模型,但是它很笨拙,因为有些集合–本质上是模型数组,它们能查询API并用结果给自己赋值。Spine.js模型跟Rails模型非常相似。一个模型能够被实例化用来呈现记录,但是它也拥有类级别的方法从API中取出结果。这些方法返回结果而不是产生一个数组,所以我们不需要考虑类在何处活跃。因为集合是实例,我看到过的许多示例中都把它们看作单例。结果,那些学习Backbone.js并跟随着那些示例的人也学会了写着不可测的代码。
3、Spine.app
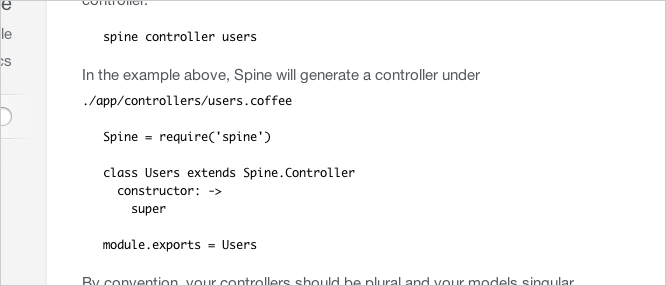
当使用Backbone.js时,我发现每次创建新类时我都会拷贝/粘贴代码,我开始想念在Rails时我习惯的生成器了。只需一条命令,我就能基于模版生成一个带有spec的新类,这为我节约了了几年开发的生命。“开发Backbone.js生成器”持续停留在我的todo列表,但是我从未着手于此。
Spine.app 生成文件,只需一行,我就创建了一个新类并带有spec,就像Rails一样。
4、动态记录

这个就想疯狂的黑魔法一样,但是它解决了一个我在Backbone.js遇到的问题。假设你应用的一个视图获得了一条记录。然后你在不同的视图获取并更新了同一条记录。在 Spine.js 中,两条记录都将同时更新。你不用担心保持他们同步。当我读到这一条时,我便为之感动了。
5、元素Hash

使用Backbone.js时,我总是发现我手动地分配变量用来在每个视图的渲染方法中嵌入元素,为每个元素重复相同的代码–有很多的样板文件。在Spine.js中,它拥有元素hash,key是选择器,值则是变量名,正如Backbone.js事件hash一样,你所有的元素都会被映射,这样清晰而简洁。
6、方法更新

在我使用Flash的日子,优化是生存的关键。如果我忘记移除某个事件监听器,我的app将会内存溢出,就像一个少于维护的应用。就因为这个,我在每个类中都包含了一个方法用来注销和移除所有的事件监听器。而Spine.js内建有这个功能。
7、控制器中的路由
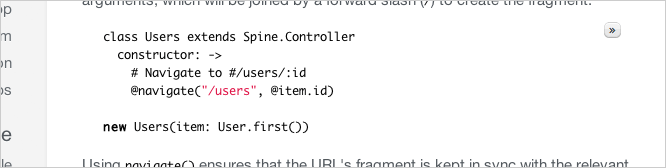
Spine.js中没有Router类,这个功能属于控制器类的一部分。在任何控制器中,我能导航至新的位置,并对新位置做出反应。其他的控制器也同样能对这个新位置作出反应。现在就没必要创建一个路由单例了。
8、模型适配器

默认情况下,Spine.js 把模型保存在内存中,但是有两个适配器可以被应用到任何的模型类上–Ajax和Local。只需简单的继承这些适配器,你的数据将可以在远端数据库存留或者是使用HTML5本地存储API。所有这些功能仅需一行代码。
9、从HTML元素中获取模型

这是我在Backbone.js遇到的另一个问题,我会实例化一个视图并绑定到一个模型,当我需要不通过访问视图实例来引用数据时,我就没那么幸运了。Spine.js提供了一个jQuery插件来访问元素的模型。仅需在元素上调用data方法你变获取了对应模型。
10、日志

Spine.js 生来就具备着一个轻量级的方便日志模块。你可以在任何控制器中调用log方法,它将会加上一系列前缀并输出到console。