CQRS——命令与查询职责分离【翻译】
- - 企业架构 - ITeye博客翻译自大牛Martin Fowler的CQRS. 原文地址:http://martinfowler.com/bliki/CQRS.html. CQRS代表着命令查询责任分离. 我第一次听到这个模式是从Greg Young那里. 这个模式的核心就是你在更新数据时所使用的模型可以与读取和查询时所用的数据模型不一样.
翻译自大牛Martin Fowler的CQRS。原文地址:http://martinfowler.com/bliki/CQRS.html
==================================================================
CQRS代表着命令查询责任分离。我第一次听到这个模式是从Greg Young那里。这个模式的核心就是你在更新数据时所使用的模型可以与读取和查询时所用的数据模型不一样。这个最为简单的概念实际上却引出了在信息系统设计上具有深远意义的一些结论。
实际上用户与信息系统进行交互的主旋律方式,还是将信息系统当做一个能做增删改查的数据库。我的意思是指当我们新增记录、修改记录、读取记录和删除记录的时候,我们对它实际上已经建立了心智模型。在最简单的场景里,我们对数据的操作实际上就是写入和读出两种。
然而随着我们的需求变得越来越复杂,系统实现也一点一点的脱离最初的模型。也许我们希望能够有其他的方式来查阅数据库中的数据,比如将多条数据扁平化为一条,或者将来源于不同系统的数据组成虚拟的记录来展现。在存储端我们也许会发现校验规则或许只允许固定的几种数据组合被持久化,甚至要求用不同于上层提供的数据模型的方式来持久化数据。
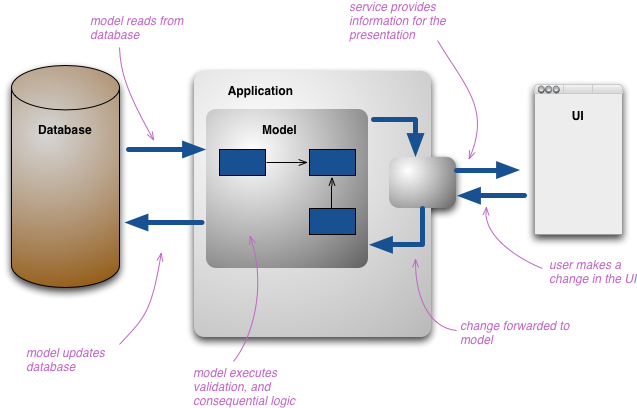
当这些情况发生的时候我们开始思考信息的多种表现方式。当用户对用户进行互动操作的时候,他们会使用各种不同的数据展现样式,其中每一种实际上都是一种具有代表性的模式。开发人员通常会在开发时建立他们自己的模型来操纵系统模型中所用的核心部分。如果你在使用一个领域模型,那么它通常是对一个领域在概念上具有代表性的模型。你也可以将持久化的数据模型设计的尽可能与概念模型一致。
这种多层次的代表性模式架构可能会很复杂,但在实际应用中程序员通常会将其简化为一个的概念上的代表模型,而这个代表模型聚合了所有的展现方式。
CQRS带来的变化就是将原本统一的概念模型拆分成更新和查询时所使用的不同模型,就是CommandQuerySeparation这个单词中的命令(Command)和查询(Query)。这么做的原理是对于很多问题,尤其是那种十分复杂的领域,执行命令和进行查询时使用相同的模型会导致更加复杂的情况,而且此时的模型可能对哪种情况都无法完全满足。
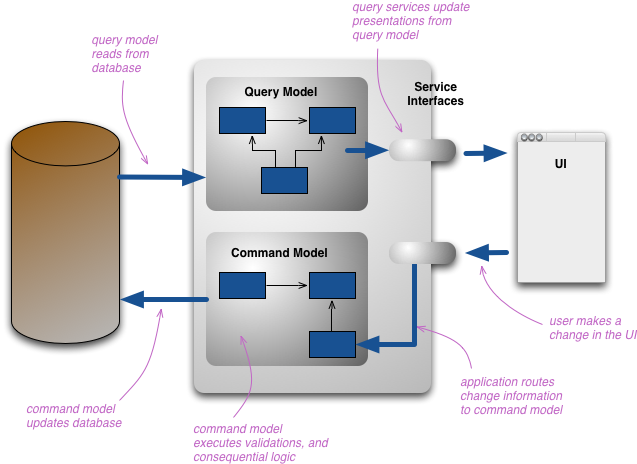
通过拆分模型我们通常会隐含的暗示着这是不同的模型对象,可能运行在不同的逻辑流程中,甚至可能是在不同的硬件资源上。一个web上的例子是,用户看到的页面是通过查询模型渲染出来的。如果用户提交了一个变更,这个变更路由到了正确的命令模型上并且执行了,那么作为结果查询模型会通过通信的方式获知这个变更并更新渲染出的数据。
当然我们也为可能的变化做了提前准备。内存中的多种模型可能会基于同一个数据库,此时数据库作为不同模型间的数据沟通方式。与此同时不同的模型间也可以依赖不同的数据库,比如通过采用报告型数据库来高效的搭建起查询端的数据库。在这种情况下就需要其他的数据沟通方式来完成模型或数据库间的数据同步问题。
查询和命令两种场景下的模型不一定是两个完全不同的模型,他们也许只是有着不同的接口用以满足所在的场景。这更类似于数据库中的视图概念。但是当提到CQRS的时候,有一个清晰的信号就是这些模型是完全不同的。
CQRS天然的能够与其他一些架构模式相配合。
当我们抛弃原有的基于增删改查方式的代表模式时,可以轻易的迁移到基于任务的UI界面上。
以命令模式作为蓝本设计会自然而然的使用到命令和事件,而这些又引出了事件溯源。
同时拥有多个独立的模型增加了保持数据一致性的难度,同时也增加了使用最终一致性策略的可能性。
在许多领域里,更新数据时可能会涉及到大量的规则校验,所以采用饥饿式更新的策略可以简化查询端的复杂度。
增删改查的方式适用于比较复杂的领域,但同时领域驱动模式也适用。
和其他的模式一样,CQRS也有适用的场景。许多的系统本身更加适合用传统的增删改查模式,那么就应该用那个模式。CQRS对于所有人来说在思维上都是一个大的跳跃,所以除非你真的清楚CQRS能带给你的好处否则不要轻易尝试。
尤其CQRS应该只在一个系统的特定部分中(DDD中所说的有边界的上下文)使用而非整个系统。以此推而广之,一个系统中的每个具有边界的上下文领域都应该根据其自身特点决定建模方式。
到目前为止,我看到的CQRS带来的益处有两个方面。首先是对复杂性的掌控——一个复杂的领域可能更加适合CQRS。我必须要澄清的是,实际上仍然有很多情况下查询和命令共享数据模型会更简单,这个必须具体问题具体分析。
另一个好处是对高性能的支撑能力。CQRS能够让你将读和写分开,使得单独对读或写进行扩展变的很容易。如果你的系统在读和写两方面有非常大的不同,那么CQRS会很适合。即便不能如此,你也可以针对两个方面各自选择最优的优化方案。一个例子就是对读和写采用不同的数据库读取方案。
如果你的系统不适合使用CQRS,但同时也面临复杂度或者性能的问题,别忘了你可以使用从属数据库(ReportingDatabase)。CQRS中所有的查询都使用不同的数据模型。通过从属数据库你可以继续用主库支撑绝大部分的请求,将对应的更吃力的请求转移到从属数据库上。
目前为止我们还没有足够的CQRS实践经验,无法对其好处和缺点完全了解。所以尽管CQRS是一个我很喜欢的模式,但我不会将它放到第一优先级上。