CQRS基本概念 | event sourcing | CQRS | axon | EdisonXu的技术分享
- -在研究微服务的过程中,跨服务的操作处理,尤其是带有事务性需要统一commit或rollback的,是比较麻烦的. 本系列记录了我在研究这一过程中的心得体会. 本篇主要就以下几个问题进行介绍:. 什么是EventSourcing. EventSourcing和CQRS的关系. CQRS/ES怎么解决微服务的难题.
在研究微服务的过程中,跨服务的操作处理,尤其是带有事务性需要统一commit或rollback的,是比较麻烦的。本系列记录了我在研究这一过程中的心得体会。
本篇主要就以下几个问题进行介绍:
- 微服务中的一个大难题
- DDD中的几个基本概念
- 什么是EventSourcing?
- 什么是CQRS?
- EventSourcing和CQRS的关系?
- CQRS/ES怎么解决微服务的难题?
微服务架构已经热了有两年了,而且目测会越来越热,除非有更高级的架构出现。相关解释和说明,网上一搜一大堆,我这里就不重复了。一句话概括:
微服务将原来的N个模块,或者说服务,按照适当的边界,从单节点划分成一整个分布式系统中的若干节点上。
原来服务间的交互直接代码级调用,现在则需要通过以下几种方式调用:
前面两种就比较类似,都属于直接调用,好处明显,缺点是请求者必须知道被请求方的地址。现在一般会提供额外的机制,如服务注册、发现等,来提供动态地址,实现负载和动态路由。目前大多数微服务框架都走的这条路子,如当下十分火热的SpringCloud等。
事件驱动的方式,把请求者与被请求者的绑定关系解耦了,但是需要额外提供一个消息队列,请求者直接把消息发送到队列,被请求者监听队列,在获取到与自己有关系的事件时进行处理。主要缺点主要有二:
1) 调用链不再直观;
2) 高度依赖队列本身的性能和可靠性;
但无论是哪种方式,都使得传统架构下的事务无法再起到原先的作用了。
事务的作用主要有二:
在传统架构下,无论是DB还是框架所提供的事务操作,都是基于同线/进程的。在微服务所处的分布式框架下,业务操作变成跨进程、跨节点,只能自行实现,而由于节点通信状态的不确定性、节点间生命周期的不统一等,把实现分布式事务的难度提高了很多。
这就是微服务中的一个大难题。
在进一步深入前,必须要了解几个基本概念。这些基本概念在EventSourcing和CQRS中都会用到。
Aggregate聚合。这个词或许听起来有点陌生,用集合或者组合就好理解点。
A DDD aggregate is a cluster of domain objects that can be treated as a single unit.
—— Martin Fowler
以下图为例
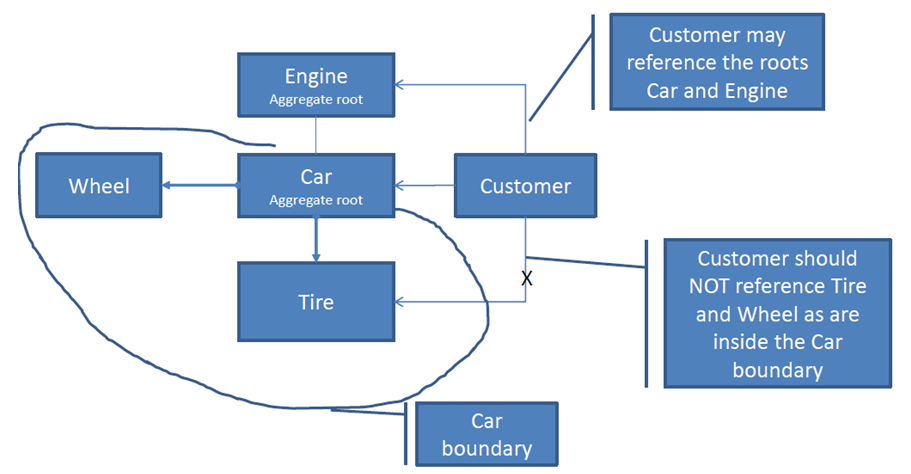
车、轮子、轮胎构成了一个聚合。其中车是聚合根( AggregateRoot)
Aggregate有两大特征:
具体来说, Aggregate存在于两种形式:
ROOT,外部只能通过 AggregateRoot对这组对象进行交互; 不保存对象的最新状态,而是保存对象产生的所有事件。
通过事件回溯(Event Sourcing, ES)得到对象最新的状态
以前我们是在每次对象参与完一个业务动作后把对象的最新状态持久化保存到数据库中,也就是说我们的数据库中的数据是反映了对象的当前最新的状态。而事件溯源则相反,不是保存对象的最新状态,而是保存这个对象所经历的每个事件,所有的由对象产生的事件会按照时间先后顺序有序的存放在数据库中。当我们需要这个对象的最新状态时,只要先创建一个空的对象,然后把和改对象相关的所有事件按照发生的先后顺序从先到后全部应用一遍即可。这个过程就是事件回溯。
因为一个事件就是表示一个事实,事实是不能被磨灭或修改的,所以ES中的事件本身是不可修改的(Immutable),不会有DELETE或UPDATE操作。
ES很明显先天就会有个问题——由于不停的记录Event,回溯获得对象最新状态所需花的时间会与事件的数量成正比,当数据量大了以后,获取最新状态的时间也相对的比较长。
而在很多的逻辑操作中,进行“写”前一般会需要“读”来做校验,所以ES架构的系统中一般会在 内存中维护一份对象的最新状态,在启动时进行”预热”,读取所有持久化的事件进行回溯。这样在读对象——也就是 Aggregate的最新状态时,就不会因为慢影响性能。
同时,也可以根据一些策略,把一部分的Event合集所产生的状态作为一个snapshot,下次直接从该snapshot开始回溯。
既然需要读,就不可避免的遇到并发问题。
EventSourcing要求对回溯的操作必须是原子性的,具体实现可参照Actor模型。
ActorModel的核心思想是与对象的交互不会直接调用,而是通过发消息。如下图:
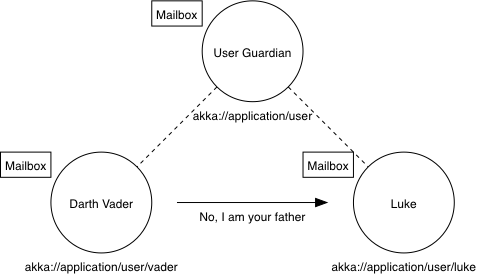
每一个Actor都有一个Mailbox,它收到的所有的消息都会先放入Mailbox中,然后Actor内部单线程处理Mailbox中的消息。从而保证对同一个Actor的任何消息的处理,都是线性的,无并发冲突。整个系统中,有很多的Actor,每个Actor都在处理自己Mailbox中的消息,Actor之间通过发消息来通信。
Akka框架就是实现Actor模型的并行开发框架。Actor作为DDD聚合根,最新状态是在内存中。Actor的状态修改是由事件驱动的,事件被持久化起来,然后通过Event Sourcing的技术,还原特定Actor的最新状态到内存。
另外,还有 Eventuate,两者的作者是同一人,如果对Akka和Eventuate的区别感兴趣的话,可以参照我翻译的一篇文章 (译)Akka Persistence和Eventuate的对比。
CQRS架构全称是 Command Query Responsibility Segregation,即命令查询职责分离,名词本身最早应该是 Greg Young提出来的,但是概念却很早就有了。
本质上,CQRS也是一种读写分离的机制,架构图如下:
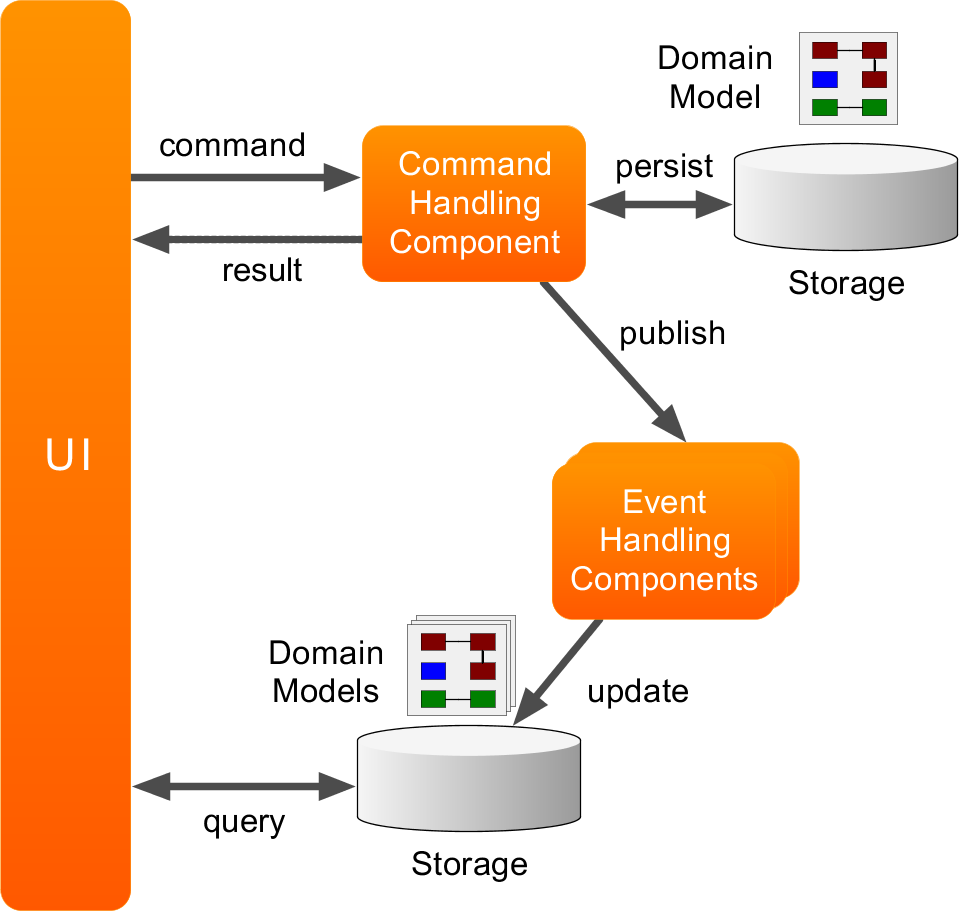
CQRS把整个系统划分成两块:
Command Side写的一边 Command,每一个 Command修改一个 Aggregate的状态。 Command Side的命令通常不需要返回数据。注意:这种“写”操作过程中,可能会涉及“读”,因为要做校验,这时可直接在这一边进行读操作,而不需要再到 Query Side去。Query Side读的一边 由于C端与Q端的分离,两端各有一个自己的 Repository,可根据不同的特性选取不同的产品,比如C端用RMDB,而Q端选用读取速度更快的NoSQL产品。
使用了CQRS架构,由于读写之间会有延迟,就意味着系统的一致性模型为最终一致性(Eventual Consistency),所以CQRS架构一般用于读比写大很多的场景。
注意:
CQRS并不像SOA、EDA(EventDrivenArchitecture)属于顶级架构,它有自己的局限性,并不适合于一切场景。有些天然适合于CRUD的系统,在评估CQRS所带来的好处与坏处后,认为利大于弊再选取CQRS。所以,通常CQRS只作为一个大系统中某部分功能实现时使用。
从前面的介绍,应该可以发现两者其实并没有直接的关系,但是EventSourcing天然适合CQRS架构的C端的实现。
CQRS/ES整合在一起的架构,优缺点如下:
Aggregate状态时,如果相关事件过多,需要提前“预热”我们先把实现微服务事务中的主要难点列出来,然后看用CQRS/ES是怎么一一解决的。
必须自己实现事务的统一commit和rollback;
这个是无论哪一种方式,都必须面对的问题。完全逃不掉。在DDD中有一个叫 Saga的概念,专门用于统理这种复杂交互业务的,CQRS/ES架构下,由于本身就是最终一致性,所以都实现了 Saga,可以使用该机制来做微服务下的transaction治理。
请求幂等
请求发送后,由于各种原因,未能收到正确响应,而被请求端已经正确执行了操作。如果这时重发请求,则会造成重复操作。
CQRS/ES架构下通过AggregateRootId、Version、CommandId三种标识来识别相同command,目前的开源框架都实现了幂等支持。
并发
单点上,CQRS/ES中按事件的先来后到严格执行,内存中 Aggregate的状态由单一线程原子操作进行改变。
多节点上,通过EventStore的broker机制,毫秒级将事件复制到其他节点,保证同步性,同时支持版本回退。(Eventuate)
结合的方式很简单,就是把合适的服务变成CQRS/ES架构,然后提供一个统一的分布式消息队列。
每个服务自己内部用的C或Q的Storage完全可以不同,但C端的Storage尽量使用同一个,例如MongoDB、Cansandra这种本身就是HA的,以保证可用性。同时也可以避免大数据分析导数据时需要从不同的库导。
目前,相对成熟的CQRS/ES可用框架有:
| 名称 | 地址 | 语言 | 文档 | 特点 |
|---|---|---|---|---|
| AxonFramework | http://www.axonframework.org | Java | 比较全,更新及时 | 目前作者正在开发与SpringCloud的相关集成 |
| Akka Persistence | http://akka.io/ | Scala(也有.Net版) | 文档全 | 相对成熟,性能较强 |
| Eventuate | http://eventuate.io | Scala | 文档较少 | 与Akka同源,在Akka基础上对分布式相关功能进行了增强,提供AWS上的SaaS |
| ENode | https://github.com/tangxuehua/enode | C# | 博客 | 来自微软的国人原创 |
| Confluent | https://www.confluent.io | Scala | 文档较少 | 不仅仅只是CQRS/ES,是整个一套基于kafka的高性能微服务产品,提供商业版 |