TokuDB中的COLA-Tree
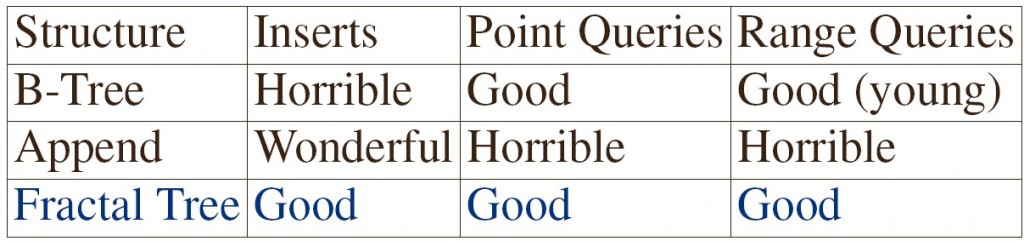
目前无论是商业的SQL Server,还是开源的MySQL,都基本上还在用比较老的 B+Tree(SQL Server用的是标准的B-Tree)的索引结构。从原理来说,B系列树在查询过程中应该是不会慢的,而主要问题就是出现在插入。B-Tree在插入的时候,如果是最后一个node,那么速度非常快,因为是顺序写。但如果数据插入比较无序的时候,比如先插入5然后10000然后3然后800这样跨度很大的数据的时候,就需要先“找到这个数据应该被插入的位置”,然后插入数据。这个查找到位置的过程,如果非常离散,那么就意味着每次查找的时候,他的子叶节点都不在内存中,这时候就必须使用磁盘寻道时间来进行查找了。更新基本与插入是相同的。如果是一个运行时间很长的B-Tree,那么几乎所有的请求,都是随机IO。以上就是B-Tree在磁盘结构中最大的问题了。
随机 IO几乎是令所有DBA谈虎色变的一个问题,当数据量小的时候,所有数据都能一下放到内存中那么就没有这个问题(其实这个时候也就没有必要用B-Tree的这种块结构了),但是一旦数据量大于内存的话这个问题就陡然出现了。其实从本质来说,k-v存储要解决的问题就是这么一个:尽可能快得写入,以及尽可能快的读取。
在分析解决方法之前,我们讨论几个极端。走一个极端的话,如果我每次写数据都顺序写,那么对Insert来说的话是最快的,但是每次Query就没法读了,因为我每次都需要Scan一遍整个表。那么如果我想获取最佳的读性能,那么方法就是像B-Tree那样全部排个序呗。但是因为B-Tree有那样的随机IO,这样我们有没有办法得到顺序写的写性能,有同时达到B-Tree的读性能呢?目前的方法主要有两种,一种是LMS-Tree(我将会在后面的博客中再做介绍,如果您实在等不及请见 July大牛的博文),另一种是COLA Tree。下面介绍的就是TokuDB中采用的COLA-Tree。
一、原理
我们假设有这样一种集合的结构,相邻行空间加倍。每一行要么全满要么全空,全满行的数据都是排好序的。

数据插入的时候,以上图的数据存储状态为例,如果再写一个值的时候,会写在第一行,比如写了3,这个时候第一行是空的,所以就放到第一行。再写一个值11的时候,因为第一行已经写满了,所以将3取出来,和11做排序,尝试写第二行。又因为第二行也满了,所以将第二行的5和10也取出,对3,11,5,10进行排序。写入第三行。最后的结果就是:

二、磁盘IO访问的性能
分析一下磁盘IO量。合并两行数据总数为X一共需要O(X/B)次IO(B是磁盘的一个block的大小),平摊到每个数据上只要O(1/B)次。如果数据总数为N,那么一个数据最多只可能merge logN次,所以做一次插入的cost只要O(logN / B)。对比使用B-Tree作为索引的话,由于B-tree高度为LogB(N),对于磁盘IO来说,访问磁盘的次数为logB(N) = logN/logB,对于数据的query来说访问磁盘的次数是一样的。
这是TokuDB做的分析,其实我觉得这个分析有点牵强,我觉得这有点欺负B-Tree只能单个数据单个数据的插入,对于大量数据的同时插入没有优势。如果CacheOblivious Tree也是单个的插入,那么单个插入访问IO的最坏情况是O(N/B)?
翻阅原论文,原论文中承认了单个插入访问IO的最坏情况是O(N/B),但这个论文里提出了方法将最坏的这个情况改善了,主要方法是对每个level复制一个同样大小的辅助数组(如下图的两行一组的结构),所有被插入的数据先放入原空间,如果原空间满了则放入这个新建空间(如果新建空间同时也满了则是算法设计失败)。Insert的时候由一个线程完成,对于要插入一个数据的情况,这时把要Insert的数据放入Level-0的空间中(如果原数组空间为空则放入原数组空间,若满则放入辅助数组,如果辅助数组满则是算法设计的失败);另外一个线程进行merge,merge的时候按下图的结构从左到右进行,把全满的一对level空间合并排序到下一个level存放(下一个level的原数组空间为空则放入原数组空间,若满则放入辅助数组,如果辅助数组满则是算法设计的失败)。每一次merge的结束有两个标志,其中之一是所有需要merge的level对全部merge完,其二就是merge过程一共移动了m个数据。那么m的取值是多少呢?应该满足两个原则,其一是需要保证每次merge不能使得相邻两个level同时出现全满的情况;其二就是m的取值应该尽可能的小(很显然插入的最坏情况下的时间复杂度是O(m)的)。这些牛逼的作者们推出了这么一个定理:对于k个level的数据库来说,每次merge的时候只要从低到高移动2k+2的数据项,就能保证相邻的两个level不会同时出现满员的情况(这个证明过程说实话我没有看的太懂,希望懂的各位能够指导我理解一下,谢谢各位!论文 在此的第9页的LEMMA-21)。这样对于一个数量为N的数据库来说,level层数为log(N),那么每次merge要移动的数据量为2log(N)+2,即IO次数只要(2log(N)+2)/B,即O(log(N)/B)。于是这个最坏情况的IO就神奇地从O(N/B)降到了O(log(N)/B)。

看看查询的性能。为了提高查找的性能,TokuDB在每个数据上加了一个forwardpointer,指向下一行中第一个比它大的数据的位置(这个叫做Fractional Cascading)。平均地看,上一级的每个数都把下一级搜索范围限制到了常数个,所以磁盘IO的次数最差应该为O(logN),好像这个没有问题。

TokuDB实际采用的方法对上面的Fractal Trees还做了改进,将插入的IO数量级从log(N)提高到了logB(N),但是由于TokuDB不是开源的,所以没法知道他们如何实现的。
三、性能分析
下面对TokuDB的性能总结一下,经过大家的测试,数据随机插入速度提高了20-80倍,如果是纯顺序插入则会慢3.5倍。
如果要存储blob,不要使用TokuDB,因为它限制记录不能太大;
如果你注重update的性能,不要使用TokuDB,它没有InnoDB快;
如果你想要缩小数据占用的存储空间,可以使用TokuDB,TokuDB也进行了文件压缩。
(转载此文请注明出处: http://blog.csdn.net/jiang1st2010/article/details/7901269)
引申阅读:
1. http://www.mysqlperformanceblog.com/2009/04/28/detailed-review-of-tokutek-storage-engine
2. http://tokutek.com/presentations/bender-Scalperf-9-09.pdf
3. http://openquery.com/blog/tokuteks-fractal-tree-indexes
4. 《Cache-ObliviousStreaming B-trees》
来源: http://blog.csdn.net/jwh_bupt/article/details/7901269
TokuDB与fractal tree index
2009 年以索引技术创业的 TokuTek 发布了 TokuDB for MySQL, 看性能参数是挺不错的.当时就对它产生了极大的兴趣. 但非常不幸偶没有理解它的索引原理 (Tokutek 也不说). 再加上它不是很成熟, 没有 ACID, 多核支持也不好, 所以暂时搁置了.
设有 n 个数据吧.基本意思是有 log2(n) 个索引块, 块的大小分别是 1, 2, 4… 直到 2^k, 其和大于 n (要不就存不下了 ). 每个块只有空和填满两种状态.插入时如果碰到块满的情况就把两个小块合并为更大的块.因为较小的块可以在内存中合并 (反正内存中怎么折腾都不会慢的), 对较大的块来说在旋转存储器上的归并速度也是很快的, 这就是 TokuDB 高速最直接的原因. 压缩是另一个加分的因素.
看来最大的问题就是, 两个块合成新块时, 如果两个块都很大就比较麻烦了.
删除的问题并不清楚. 不过考虑到它作为数据仓库的用途, 这一点可以暂时原谅. 删除也可以用对数据加 flag 的方法解决. 好像更新也不是简单的事情.看起来很像变种单机 BigTable, 只是不知道现在 Google 改造存储系统的情况如何.kumofs 的作者说 kumofs 是第二代分布式存储系统(彻底没有单点问题), 这个情况有感兴趣的自己去研究吧.
变长的数据是容易处理的. 搜索的复杂度降到 O(logB(N)), 存储的只要是块的位置(或编号)就可以了.事务(包括灾难恢复)和并行化可能是难度最大的部分.
说到对存储到硬盘上的数据进行整理, 就不得不提到 Reiser4 引入的 Dancing Tree.写入之前对 Block 做整理的操作, 这是一个比较有效的优化, 只是可惜了…
—
TokuDB 还有 covering index (试译: 覆盖索引) 的支持. 覆盖索引要求所有要查询的列都在索引之中.如果有 (a, b, c) 的覆盖索引, 则查询 select b, c where a = xx 这类是很快的.(覆盖索引和多维排序索引有什么区别? 如果后者不能完成这个任务, 那是 MySQL 的错, 这绝对不是首创)
但偶不明白二维索引的实现方式. 暂时继续抱怀疑态度.
复杂度分析对于研究算法来说是十分必要的.Point Query 的复杂度 O(logN/logB), 实际上就等于 O(logB(N)), 你是不是忘了换底公式了?关于插入的复杂度, 允许多个块写到一起(包括内存上的优化)是非常显然的优化. 但随机插入的场合如果不能减少 IO 的话可不行.Fractal Tree 索引的效率和内存的关系并不大, 但实现上看起来挺吃 CPU 的.仔细想来, Fractal Tree Index 大批量的插入均摊复杂度确实是 O(logN / B).
—
Tokutek 的收费政策是生产环境未压缩纯数据(不算索引) 50 GB 以下不收费,包括所有的副本(也就是说 Replication 的话就要算多次了), 当然也没有技术支持.
超过部分每 100 GB / 年收费 $1000 (换算一下是 $0.83 / GB * Month ).Tokutek 认为单台机器能承担 5 TB 的数据, 这个数字偶是要怀疑的. 而且偶不愿意承担单点的风险.显然可以谈个优惠价出来, 实际上偶愿意接受的价格不超过 $0.05 / GB * Month.这个收费比 GAE DataStore 和 Amazon SimpleDB 都贵太多了, 实在不合算. 有人还在想 Oracle 怎样怎样…
换一个角度说, 如果你用 NoSQL 存数据, 用它当索引(注意别涉及删除问题), 偶想肯定不会超过 50 GB 的 这个引擎存文本虽然没问题, 可是偶肯定不会这样推荐的.
—
TokuDB 的下载页面提供了 Fractal Tree Library 的下载, 只有 x86_64 的版本.(需要注册, 随便填填就过了, 需要验证 E-Mail, 没有审核)解压出来有一个大号的 .so 文件, include 目录下有 tokudb.h. 实现还算是比较完整. 提供了测试的程序, 但有说要是作为嵌入式数据库的话需要获得许可.
其他:
http://openquery.com/blog/tokuteks-fractal-tree-indexes
延伸阅读:
http://en.wikipedia.org/wiki/Fractal_tree_index
http://www.slideshare.net/mongodb/20121024-mongodbboston
作者:heiyeshuwu 发表于2014-7-30 18:06:30
原文链接