
{kind=link}
大数据下的用户画像
- - 人月神话的BLOG简单点来说用户画像,即是 根据用户的静态基本属性和动态行为数据来构建一个可标签化的用户模型. 静态属性:个人基本信息(地域,年龄,性别,婚姻),家庭信息,工作信息等. 动态行为:购买行为,点击行为,浏览,评论,营销活动参与行为,退换货行为,支付行为等. 为何要进行用户画像,核心还是后续的针对性营销,当我们组织一次针对性营销的时候,首先要确定的就是营销的用户群体,那么就要从用户标签中精确定位这个群体.
最近1~2年电商行业飞速发展,各种创业公司犹如雨后春笋大量涌现,商家通过各种活动形式的补贴来获取用户、培养用户的消费习惯。
但任何一件事情都具有两面性,高额的补贴、优惠同时了也催生了“羊毛党”。
“羊毛党”的行为距离欺诈只有一步之遥,他们的存在严重破环了活动的目的,侵占了活动的资源,使得正常的用户享受不到活动的直接好处。
今天主要分享下腾讯自己是如何通过大数据、用户画像、建模来防止被刷、恶意撞库的。
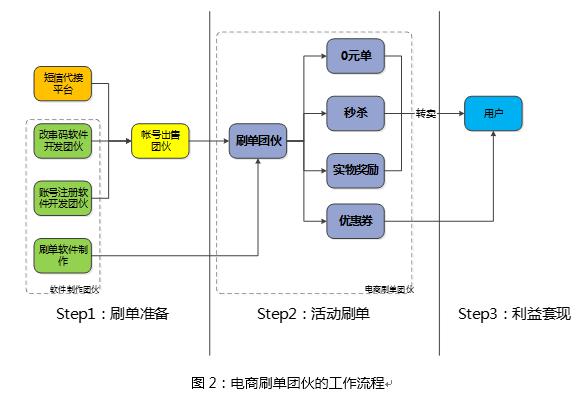
“羊毛党”一般先利用自动机注册大量的目标网站的账号,当目标网站搞促销、优惠等活动的时候,利用这些账号参与活动刷取较多的优惠,最后通过淘宝等电商平台转卖获益。
他们内部有着明确的分工,形成了几大团伙,全国在20万人左右:
这些黑产团队,有三个特点:

对抗刷单,一般来讲主要从三个环节入手:

风险学习引擎:效率问题。由于主要的工作都是线下进行,所以线上系统不存在学习的效率问题。线上采用的都是C++实现的DBScan等针对大数据的快速聚类算法,基本不用考虑性能问题。
风险学习引擎:采用了黑/白双分类器风险判定机制。之所以采用黑/白双分类器的原因就在于减少对正常用户的误伤。
例如,某个IP是恶意的IP,那么该IP上可能会有一些正常的用户,比如大网关IP。
再比如,黑产通过ADSL拨号上网,那么就会造成恶意与正常用户共用一个IP的情况。
黑分类器:根据特征、机器学习算法、规则/经验模型,来判断本次请求异常的概率。
白分类器:判断属于正常请求的概率。

我们以黑分类器为例来剖析下分类器的整个逻辑框架。
总的来讲我们采用了矩阵式的逻辑框架,最开始的黑分类器我们也是一把抓,随意的建立一个个针对黑产的检测规则、模型。
结果发现不是这个逻辑漏过了,而是那个逻辑误伤量大,要对那一类的账号加强安全打击力度,改动起来也非常麻烦。
因此我们就设计了这个一个矩阵式的框架来解决上述问题。

矩阵的横向采用了Adaboost方法,该方法是一种迭代算法,其核心思想是针对同一个训练集训练不同的弱分类器,然后把这些分类器集合起来,构成一个最终的分类器。
而我们这里每一个弱分类器都只能解决一种帐号类型的安全风险判断,集中起来才能解决所有账户的风险检测。
那么在工程实践上带来三个好处:
矩阵纵向采用了Bagging方法,该方法是一种用来提高学习算法准确度的方法,该方法在同一个训练集合上构造预测函数系列,然后以一定的方法将他们组合成一个预测函数,从而来提高预测结果的准确性。
上面讲的部分东西,理解起来会比较艰涩,这里大家先理解框架,后续再理解实现细节。
大数据一直在安全对抗领域发挥着重要的作用,从我们的对抗经验来看,大数据不仅仅是数据规模很大,而且还包括两个方面:
所以想要做风控和大数据的团队,一定要注意在自己的产品上多埋点,拿到足够多的数据,先沉淀下来。
我们的团队研发了一个叫魔方的大数据处理和分析的平台,底层我们集成了MySQL、MongoDB,Spark、Hadoop等技术,在用户层面我们只需要写一些简单的SQL语句、完成一些配置就可以实现例行分析。
这里我们收集了社交、电商、支付、游戏等场景的数据,针对这些数据我们建立一些模型,发现哪些是恶意的数据,并且将数据沉淀下来。
沉淀下来的对安全有意义的数据,一方面就存储在魔方平台上,供线下审计做模型使用;另一方面会做成实时的服务,提供给线上的系统查询使用。
画像,本质上就是给账号、设备等打标签。
用户画像 = 打标签
我们这里主要从安全的角度出发来打标签,比如IP画像,我们会标注IP是不是代理IP,这些对我们做策略是有帮助的。
以QQ的画像为例,比如,一个QQ只登录IM、不登录其他腾讯的业务、不聊天、频繁的加好友、被好友删除、QQ空间要么没开通、要么开通了QQ空间但是评论多但回复少,这种号码我们一般会标注QQ养号(色情、营销),类似的我们也会给QQ打上其他标签。
标签的类别和明细,需要做风控的人自己去设定,比如:地理位置,按省份标记。性别,安男女标记。其他细致规则以此规律自己去设定。
我们看看腾讯的IP画像,沉淀的逻辑如下图:

一般的业务都有针对IP的频率、次数限制的策略,那么黑产为了对抗,必然会大量采用代理IP来绕过限制。
既然代理IP的识别如此重要,那我们就以代理IP为例来谈下腾讯识别代理IP的过程。
识别一个IP是不是代理IP,技术不外乎就是如下四种:
以上代理IP检测的方法几乎都是公开的,但是盲目去扫描全网的IP,被拦截不说,效率也是一个很大的问题。
因此,我们的除了利用网络爬虫爬取代理IP外,还利用如下办法来加快代理IP的收集:通过业务建模,收集恶意IP(黑产使用代理IP的可能性比较大)然后再通过协议扫描的方式来判断这些IP是不是代理IP。每天腾讯都能发现千万级别的恶意IP,其中大部分还是代理IP。


实时系统使用C/C++开发实现,所有的数据通过共享内存的方式进行存储,相比其他的系统,安全系统更有他自己特殊的情况,因此这里我们可以使用“有损”的思路来实现,大大降低了开发成本和难度。
数据一致性,多台机器,使用共享内存,如何保障数据一致性?
其实,安全策略不需要做到强数据一致性。
从安全本身的角度看,风险本身就是一个概率值,不确定,所以有一点数据不一致,不影响全局。
但是安全系统也有自己的特点,安全系统一般突发流量比较大,我们这里就需要设置各种应急开关,而且需要微信号、短信等方式方便快速切换,避免将影响扩散到后端系统。


适应的场景包括:
Q&A
Q:风险学习引擎是自研的,还是使用的开源库?
风险学习引擎包括两个部分,线上和线下两部分:
线上:自己利用c/c++来实现。
线下:涉及利用python开源库来做的,主要是一些通用算法的训练和调优。
Q:请问魔方平台中用到的MongDB是不是经过改造?因为MongDB一直不被看好,出现问题也比较多。
我们做了部分改造,主要是DB的引擎方面。
Q:请问黑分类器和白分类器有什么区别?
白分类器主要用来识别正常用户,黑分类器识别虚假用户。
Q:风险概率的权重指标是如何考虑的?
先通过正负样本进行训练,并且做参数显著性检查;然后,人工会抽查一些参数的权重,看看跟经验是否相符。
Q:安全跟风控职责如何区分呢?
相比安全,风控的外延更丰富,更注重宏观全局;针对一个公司来讲,风控是包括安全、法务、公关、媒体、客服等在内一整套应急处理预案。
Q:如果识别错了,误伤了正常用户会造成什么后果么?比如影响单次操作还是会一直失败。
如果识别错了正常用户不会被误伤,但是会导致体验多加了一个环节,如弹出验证码、或者人工客服核对等。
想和群内专家继续交流有关高可用架构的问题,请关注公众号后,回复arch,申请进群。
来源:《科学农夫》
作者:颜国平,腾讯云-天御系统研发负责人。一直负责腾讯自有验证码、业务安全、防刷、账号安全等研发工作。内部支持的产品(游戏、电商、腾讯投资的O2O企业)非常广泛。在业务安全领域项目经验丰富,并且具备深度学习、大数据架构搭建等实战经验。