MySQL数据库复制概论
- - Float_Luuu的博客每当我们讨论一项(新的)领域技术的时候,最好的方式通常是首先抛出一些问题,这些问题大致分为三类:诶. 这项技术又是什么玩意(What)?这项技术为什么会存在. 我们已经有那么多解决方案(Method)了,我们问什么要用它(Why). 如果这项技术那么好且我们正好有场景可以用到这项技术,且能使我们的系统得到很乐观的优化,那么我们怎么用呢(How).
每当我们讨论一项(新的)领域技术的时候,最好的方式通常是首先抛出一些问题,这些问题大致分为三类:诶?这项技术又是什么玩意(What)?这项技术为什么会存在?我们已经有那么多解决方案(Method)了,我们问什么要用它(Why)?如果这项技术那么好且我们正好有场景可以用到这项技术,且能使我们的系统得到很乐观的优化,那么我们怎么用呢(How)?大概已经有同学觉得这些问题很熟悉了,是的,这就是黄金全法则提出的三个问题,对于每种新鲜事物我们首先基于这三个问题去了解,更有利于弄清楚事情的本质,端正态度去了解,而不是因为新,因为大家都说好,才要去了解……。说了那么多前奏,我们可以开始了,今天我们就带着黄金圈法则提出的三个问题去看看MySQL数据库复制这项领域技术,然后再结合实际应用扩展一些问题,本文也仅仅是结合自己了解的皮毛以抛砖引玉的态度和大家一起分享。
WHAT?
MySQL复制使得一台Mysql数据库服务器的数据被拷贝到其他一台或者多台数据库服务器,前者通常被叫做Master,后者通常被叫做Slave。
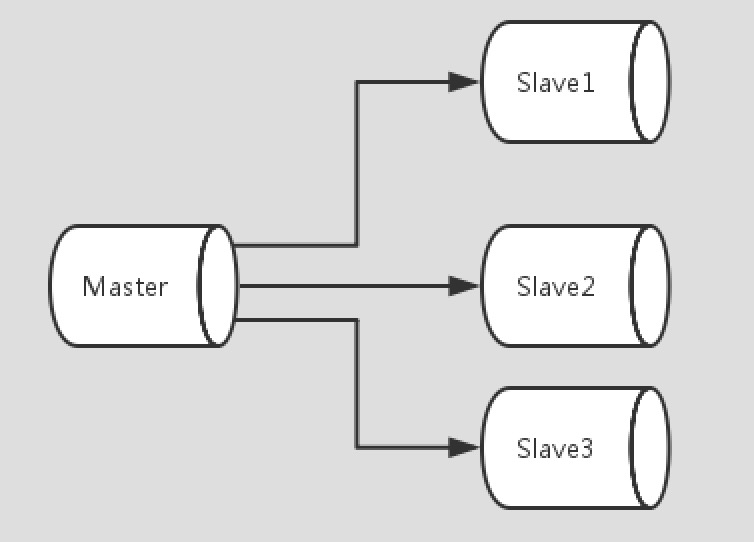
MySQL复制示意图
复制的结果是集群(Cluster)中的所有数据库服务器得到的数据理论上都是一样的,都是同一份数据,只是有多个copy。MySQL默认内建的复制策略是异步的,基于不同的配置,Slave不一定要一直和Master保持连接不断的复制或等待复制,我们指定复制所有的数据库,一部分数据库,甚至是某个数据库的某部分的表。
MySQL复制支持多种不同的复制策略,包括同步、半同步、异步和延迟策略等。
同步策略:Master要等待所有Slave应答之后才会提交(MySql对DB操作的提交通常是先对操作事件进行二进制日志文件写入然后再进行提交)。
半同步策略:Master等待至少一个Slave应答就可以提交。
异步策略:Master不需要等待Slave应答就可以提交。
延迟策略:Slave要至少落后Master指定的时间。
MySQL复制同时支持多种不同的复制模式:
基于语句的复制,Statement Based Replication(SBR)。
基于行的复制Row Based Replication(RBR)。
混合复制(Mixed)。
WHY?
这个问题其实也就是MySQL复制有什么好处,我们可以将复制的好处归结于下面几类:
性能方面:MySQL复制是一种Scale-out方案,也即“水平扩展”,将原来的单点负载扩散到多台Slave机器中去,从而提高总体的服务性能。在这种方式下,所有的写操作,当然包括UPDATE操作,都要发生在Master服务器上。读操作发生在一台或者多台Slave机器上。这种模型可以在一定程度上提高总体的服务性能,Master服务器专注于写和更新操作,Slave服务器专注于读操作,我们同时可以通过增加Slave服务器的数量来提高读服务的性能。
防腐化:由于数据被复制到了Slave,Slave可以暂停复制进程,进行数据备份,因此可以防止数据腐化。
故障恢复:同时多台Slave如果有一台Slave挂掉之后我们还可以从其他Slave读取,如果配置了主从切换的话,当Master挂掉之后我们还可以选择一台Slave作为Master继续提供写服务,这大大增加了应用的可靠性。
数据分析:实时数据可以存储在Master,而数据分析可以从Slave读取,这样不会影响Master的性能。
HOW?
这里我们只介绍一下MySQL的复制是如何工作的,至于配置,网上也有很多相关的介绍,读者具体应用的时候可以再去查阅。我们拿最常用的基于二进制文件的复制来看看。
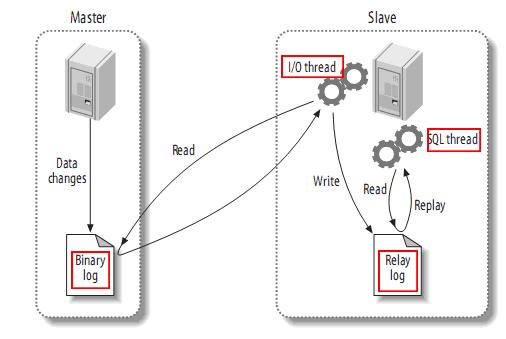
MySQL复制工作示意图
MySQL的复制过程大概如下:
首先,主库在每次准备提交事务完成数据更新操作之前都会将数据更改操作记录到二进制日志中,这些日志是以二进制的方式记录数据更改的事件。值得一提的是二进制日志中记录的顺序实际上是事务的提交顺序,而非SQL执行语句的顺序。在记录二进制日志之后,主库会告诉存储引擎事务可以提交了。
然后,备库会启动一个IO线程,之所以叫做IO线程是因为这个线程专门做IO相关的工作,包括和主库建立连接,然后在主库上启动一个特殊的二进制转储线程,这个转储线程会不断的读取二进制日志中的事件,发送给备库的IO线程,备库的IO线程会将事件记录到中继日志中。
备库会有一个叫做SQL的线程被开启,这个线程做的事情是读取中继日志中的DB操作事件在备库执行,从而实现数据更新。
总的来说,在发生复制的主库服务器和备库服务器中,一共有三个线程在工作。
上面我们已经大概了解的什么是复制?为什么要复制?如何复制?这三个问题了,接下来我们基于上面的介绍,提出一些实际应用可能会发生的问题来思考如何解决。博主自问自答的方式-。-
问答环节
问题一:通过复制模型虽然读能力可以通过扩展slave机器来达到提高,而写能力却不能,如果写达到瓶颈我们应该怎么做呢?
答:我们首先会得出结论,这种复制模型对于写少读多型应用是非常有优势的,其次,当遇到这种问题的时候我们可以对数据库进行分库操作,所谓分库,就是将业务相关性比较大的表放在同一个数据库中,例如之前数据库有A,B,C,D四张表,A表和B表关系比较大,而C表和D表关系比较大,这样我们把C表和D表分离出去成为一个单独的数据库,通过这种方式,我们可以将原有的单点写变成双点写或多点些,从而降低原有主库的写负载。
问题二:因为复制是有延迟的,肯定会发生主库写了,但是从库还没有读到的情况,遇到这种问题怎么办?
答:MySQL支持不同的复制策略,基于不同的复制策略达到的效果也是不一样的,如果是异步复制,MySQL不能保证从库立马能够读到主库实时写入的数据,这个时候我们要权衡选择不同复制策略的利弊来进行取舍。所谓利弊,就是我们是否对从库的读有那么高的实时性要求,如果真的有,我们可以考虑使用同步复制策略,但是这种策略相比于异步复制策略会大大降低主库的响应时间和性能。我们是否可以在应用的设计层面去避开这个问题?
问题三:复制的不同模式有什么优缺点?我们如何选择?
答:基于语句的复制实际上是把主库上执行的SQL在从库上重新执行一遍,这么做的好处是实现起来简单,当前也有缺点,比如我们SQL里面使用了NOW(),当同一条SQL在从库中执行的时候显然和在主库中执行的结果是不一样的,注入此类问题可以类推。其次问题就是这种复制必须是串行的,为了保证串行执行,就需要更多的锁。
基于行的复制的时候二进制日志中记录的实际上是数据本身,这样从库可以得到正确的数据,这种方式缺点很明显,数据必须要存储在二进制日志文件中,这无疑增加的二进制日志文件的大小,同时增加的IO线程的负载和网络带宽消耗。而相比于基于语句的复制还有一个优点就是基于行的复制无需重放查询,省去了很多性能消耗。
无论哪种复制模式都不是完美的,日志如何选择,这个问题可以在理解他们的优缺点之后进行权衡。
问题四:复制的工作过程只有三个线程来完成,对于Master来说,写是并发的,也就出现了一个IO线程要把所有并发的数据变更事件记录,这个IO线程会不会累死?当一个Master对应多个Slave的时候,其实在Master中会唤起多个IO线程,这无疑会增加Master的资源开销,如果出现事件堆积,也就是事件太多,来不及及时发送出去怎么办?另外就是Slave那边的IO线程和SQL线程也会有对应主库并发数据变更事件,而Slave方单个线程处理的问题,这个时候Slave线程会不会累死?
答:上面的问题确实会发生,上面第一个问题和第二个问题其实是写负载的问题,当事件堆积太多,从库时延就会变大,Slave单SQL线程问题据说有参数可以开启并行操作,这个大家可以确认一下。
问题五:针对复制工作过程可能会出现的问题,主库写完二进制日志文件同时都会保存二进制日志的偏移量,但是当断电的时候,二进制日志文件没有刷新到磁盘,主库重新启动之后,从库尝试读该偏移量的二进制日志,会出现读不到的情况,这个问题应该怎么解决?
答:首先如果开启了sync_binlog选项,对于innodb同时设置innodb_flush_log_at_trx_commot=1,则可以保证二进制日志文件会被写入磁盘,但MyISAM引擎可能会导致数据损坏。如果没有开启这个选项,则可以通过制定从库的二进制偏移量为下一个二进制日志文件的开头,但是不能解决事件丢失问题。
问题六:从库在非计划的关闭或重启时,回去读master.info文件去找上次停止复制的位置,这同样会有一个问题,如果master.info不正确,就会导致复制数据不一致的情况,遇到这个问题怎么办?
答:这个问题可以通过两种方式解决,一是控制master.info在从库非计划关闭或重启的时候让master.info能够同步到磁盘,这样下次启动的时候就不会读取错误的信息,这有助于减少错误的发生概率。另外想要找到正确的复制位置是困难的,我们也可以选择忽略错误。
……
其实问题也是蛮多的,这里就不再继续提问了,包括如果主库二进制日志文件损坏怎么办?从库中继日志文件损坏怎么办?因为每个环节都不是百分之一百可靠的,因此我们必须对可能遇到的问题提出假设,思考解决方案。本文通过黄金圈法则提出的三个问题来认识MySQL复制,通过自问自答的形式来对主体的一些可能存在的应用问题进行讨论,对于复制方面还存在很多的实际应用问题,这里只是抛砖引玉,还请数据库大牛们多多指教。
参考文献:
《高性能MySQL》
官方《refman》