对于一个互联网创业公司来说,其生存所依赖的业务系统每天都会产生大量的日志,比如系统日志、业务流水日志、程序异常日志、访问日志、审计日志等等。通过收集业务日志数据,供离线和在线的分析系统使用,以支持线上业务或运营分析等使用。
日志除了供分析系统使用以外,更多的时候开发同学会依赖日志排查问题。当我们需要使用到日志排查问题时,它们往往是我们手上唯一可以用来查明当时的发生状况和问题的根本原因的有用信息,并且在开发过程中,我们也会使用日志查看程序运行时的状态。
日志系统三部分
关于日志,分为三部分:
-
打日志 打日志可以分为客户端日志和服务端日志,这两种日志都会包含日志的基本功能,排查问题、查看运行时状态和供分析系统使用;
-
收集日志 当日志打在客户端,或打在分布式的服务器时,就需要将这些分散在各地的日志收集回来;
-
分析日志 当从日志中心下载到日志后,根据实际的需求我们需要分析日志,可能是给分析系统、告警系统或者业务系统使用,又或者是直接给到开发同学确认排查问题等等。
打日志
日志分级
按 RFC5424 的标准,日志级别分为八个级别,分别是:
- 0 Emergency 紧急:系统已不可用
- 1 Alert 警报:必须立即采取措施
- 2 Critical 关键:临界条件
- 3 Error 错误:错误条件
- 4 Warning 警告:警告状况,系统能继续运行
- 5 Notice 注意:正常但重要的条件
- 6 Informational 信息:参考消息,关键路径的打点日志
- 7 Debug 调试:调试级消息,所有有用的信息
以上为新的标准,但在实际工作中经常会用到一种简化版本
-
Error:系统发生了严重的错误, 必须马上进行处理, 否则系统将无法继续运行. 比如, 保持的连接断开,服务不可用,存储写不进去了等.
-
Warning:系统能继续运行, 但是必须要关注了,可能是系统存在潜在问题,此处需要在日志备注说明中列出可能有哪些问题,也可能是一些明显的异常,此时需要人工介入检查,不过实际工作中,此类日志一般是在出了问题后才会去看.
-
Info:重要的业务逻辑处理完成. 比如一个登录逻辑,哪个用户登录了就可以写到 Info 日志中。
-
Debug:调试类信息,量会非常大,主要给开发人员看,在各种日志库中,除了Debug 还会有一个 Trace 级别,实践中我们打 Debug 日志就好,不用再细分更详细的级别了。
并且,在不同的环境部署的日志级别也不同。
- 正式环境:个人习惯用 Info,Info 级的日志能让我看到关键的信息,在排查问题时会比较有用;也会有人或开源的组件会开启 Warning,甚至 Error;
- 测试环境:可以开到 Debug 级,也可以默认开 Info 级,当需要排查某些特殊问题的时候再开到 Debug 级;
- 开发环境:任何对实际开发工作有帮忙的信息都可以打到日志中,一般是 Debug 级。
在实际工作中个人建议用简化版的四个等级即可,就算打日志的 SDK 提供了 8 种级别,也可以只用你需要的简化版本。
日志包含的字段
日志包括的必要字段:
- Version 版本
- TIMESTAMP 时间戳,当无法获取时间戳时使用NULL
- APP NAME 用来标识设备或某个应用
- MSG TYPE 消息的类型 具有相同的 MSG TYPE 应该反映相同语义的事件
- MSG CONTENT 消息内容 日志具体的内容
重要字段:
- RESULT 结果 表示当前的结果
- CONSUMED TIME 花费时间,表示在当前阶段花费的时间
- SOURCE 来源 比如来源的ip,调用方等
- LOCATION/PATH 调用的位置或路径 表示调用的地方,常用来排查问题和查看执行流程,可能会精确到某个文件的某一行
打日志的原则
-
染色体系 给每一次请求加上一个全局的logid(id全局唯一,最好是能根据id定位到业务或用户,比如业务编号+用户编号+时间戳+随机数),每次记日志的时候,logid打出来,所有底层的框架在调用的时候,需要在公共属性部分将这个logid传过去,打印的所有日志都要带上这个logid。这样所有的业务,所有的服务,不管有多少系统,有多少机器,在处理同一请求时,都可以根据logid找到所有的日志,如果把所有的日志都收集到日志中心,就可以按时间序将所有的请求过程打印出来。染色体系是一个系统工程,需要底层框架的支持。
-
结构化的数据 包含用户IP,时间,所在业务,所在机器,所在服务,所在类或函数,甚至到哪一行代码; 将什么时候,什么业务,在什么地方发生了什么事情,描述清楚这些,使得日志可追溯。结构化的数据最要是有日志类库保证其结构的完整性。
-
日志是给人看的 需要更友好的语言表述,不要写一些没有语义的日志,比如 保存数据错误 之类的,这里最好是说明谁在哪里保存什么样的数据错误。
收集日志
当日志以规范的格式打印出来后,我们需要收集这些日志以供后面的流程使用,如前面说的分析系统,或给到开发同学定位排查问题等等。
日志最终都是文本,当业务不大,单机的文本日志就能满足需求,甚至一些监控类的业务也可以在单机文本日志的基础上实现;然而,文本日志本身有两种方式:
-
一种是直接日志类库写到本地的单机文本日志,这种方式的优点的是简单,易实现;缺点是日志打得比较散,需要有额外的手段来归拢日志,如最简单的,用 rsync 实现多机日志同步脚本部署,这种简单情况一般出现于仅需要将文本日志归集的简单实现,另外更复杂一些收集方案可以考虑 ELK 等开源方案;对于一个已有业务来说,这种把日志落到本地硬盘的方式对业务侵入最小最自然。以 ELK 收集日志为例,其结构示例所下所示:
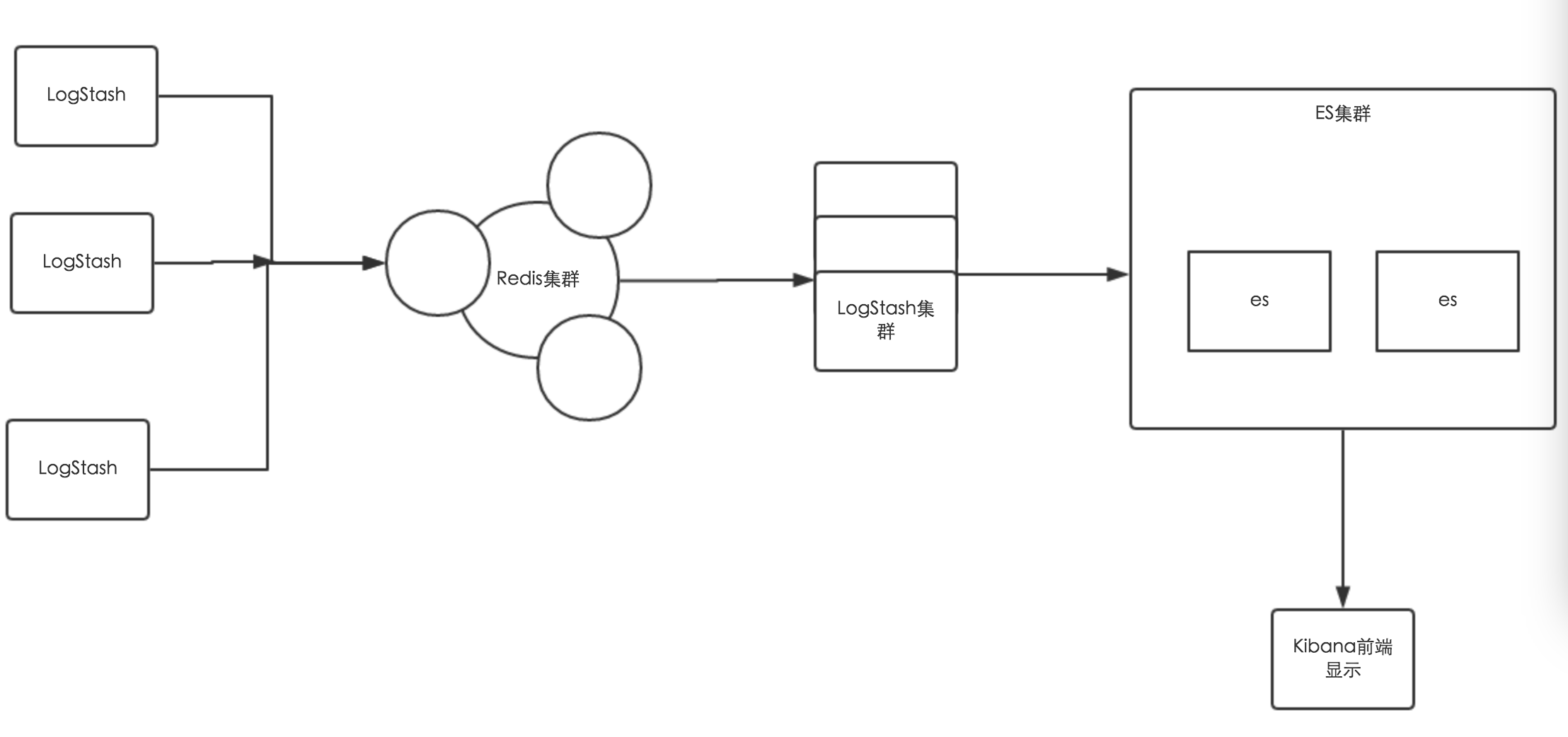
(1) LogStash Agent:在各台机器上部署的Agent,用来上传日志到队列
(2) Redis: 接收日志的队列,削峰填谷,
(3) Logstash集群:做日志解析,统一成 json 格式输出给 Elasticsearch ,json 格式的好处是直接
(4) Elasticsearch:实时日志分析服务的核心技术,实时的数据存储服务,通过 index 组织数据,兼具强大的搜索和统计功能。
(5) Kibana:基于 Elasticsearch 的数据可视化组件,前端操作非常方便,用鼠标几次点击即可完成搜索,聚合,生成报表等功能,这种可视化能力是大家选择 ELK Stack 的很重要的原因。
-
另一种是提供一个专门的日志服务,日志服务包括写入者,中继者,收集者,存储者。
(1)写入者: 日志服务提供专门定制的 SDK,业务直接调用 SDK 即可,SDK 负责日志的写入,直接与 Agent 通信,通过 Agent 将日志传输到 Collector 节点;
(2)中继者: Agent 是中断者,实现日志在客户端的转发和本地存储,其可以在类似于 supervisor 等进程管理程序的监控下运行,通过第三方程序监控进程状态,异常退出时自动拉起,对于特别重要的日志可以考虑先落到硬盘再转储;
(3)收集者:Collector 是收集者,其需要集中部署在某个集群,负责接收 Agent 发送的日志,并且将日志根据定义好的规则写到相应的 Store ;
(4)存储者:Store 是存储者,Collector 和 Store 可以部署在相同的地方,也可以分开,一般我们将历史日志按天存储到 hadoop 中,供后续离线分析使用,与此同时,如果业务有需要,可以将日志也分发一份到 Storm 系统提供实时日志分析;
以上的日志服务是属于比较完备的版本,如果业务不是那么复杂,可以根据自己的实际情况选择使用全部或部分功能;甚至更简单一些,日志服务本身可以仅仅是一个 UDP 的 socket 服务,将收集到的日志直接存储到本地,最多加个归档压缩。
日志的后续使用
当我们按照要求收集到足够的日志后,我们对这些日志可以做很多事情,如监控,实时搜索,问题定位等等,以 ELK 架构为例,见下图:
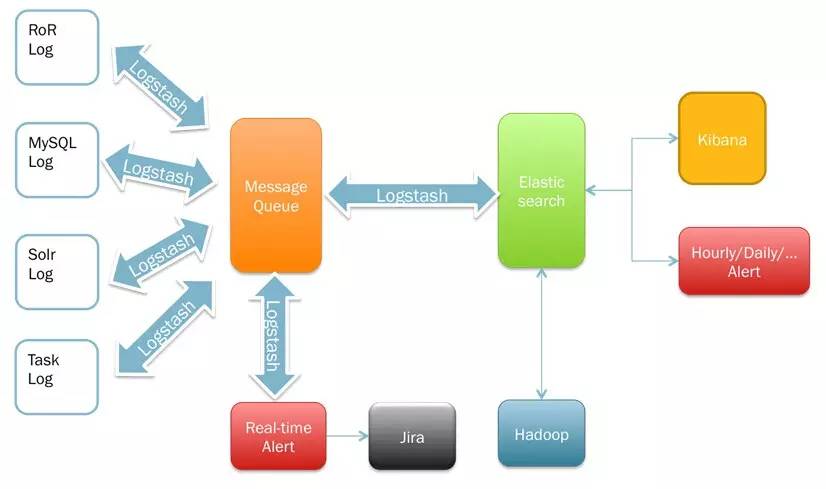
在日志经过 MQ 时,我们可以将日志转到到两个地方,一个是实时监控服务,针对日志中有问题的内容做实时的告警,并将规则匹配后的内容存到Jira中,用于问题记录、派发和追踪。 Jira的作用只是问题的跟进,相对简单一些,监控这块我们更推荐使用 Zabbix 类系统的日志监控来实现,制定日志监控规则,对日志做上报分析处理和告警监控,这样会更实时,更灵活。
另一个是将日志转到 ES, ELK Spark可以做实时的搜索和报表,报表呈现方为 Kibana,另外 ES 结合其自己的 Hadoop Plugin,通过 Hadoop2 做 Map Reduce 的计算反向投递给业务系统。
Kafka 中的日志保留最近几天的,并给 Storm 等实时分析系统提供数据源。
对于落到 ELK 的数据,如果有做染色,可以在 Kibana 的搜索界面中根据染色标志搜索出定位问题所需要的信息。
在创业的过程中,一个好的、在当下合适的日志系统选型能处理前期业务中的关于日志的大部分问题,也能满足后期的扩展需求。在这个阶段,除非之前有日志服务相关的系统可以重用,否则建议直接使用写本地文件,使用 ELK 收集日志的架构。其中关于写日志,找一个标准库自己封装一下对外接口,按照约定写即可;关于染色系统,前期如果资源不够,可以考虑不用上,待后期有资源投入后开发公共组件或框架。
参考资料: http://diyitui.com/content-1432833903.30823746.html
除了眼前的苟且,还有架构与远方。
介绍创业路上的技术选型和架构、大型网站架构、高性能高可用可扩展架构实现,技术管理等相关话题,紧跟业界主流步伐。
