理解Java虚拟机体系结构
- - ImportNew众所周知,Java支持平台无关性、安全性和网络移动性. 而Java平台由Java虚拟机和Java核心类所构成,它为纯Java程序提供了统一的编程接口,而不管下层操作系统是什么. 正是得益于Java虚拟机,它号称的“一次编译,到处运行”才能有所保障. 1.1 Java程序执行流程. Java程序的执行依赖于编译环境和运行环境.

本地方法栈和虚拟机栈有的虚拟机是不分的;


句柄优势:reference本身不需要修改,只会改变句柄中的实例数据指针
直接指针访问优势:最大好处速度快。节省了一次指针定位的开销;
HotSpot采用此方式
3个区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)
header:(官方称 Mark Word)运行时数据,入哈希码(HashCode)、GC分代年龄 锁状态标识
Instance Data:类型指针,既对象只想他的类元数据的指针;
Padding:因为对象的大小必须是8字节的整数倍。如果数据没有对齐。需要Padding来补全
1)引用计数法(不能用):每当一个地方引用它时,计数器+1,引用失效时,计数器-1,任何时刻计数器为0的对象就是不可能在被使用
java没有用 最主要的原因很难解决对象之间互相循环引用的问题;
public class ReferenceCountingGC {
public Object instance=null;
public static void main(String[] args) {
ReferenceCountingGC objA= new ReferenceCountingGC();
ReferenceCountingGC objB= new ReferenceCountingGC();
objA.instance=objB;
objB.instance=objA;
objA=null;
objB=null;
}
}
2)可达性分析算法:

* Java 语言中,可作为GC Roots的对象包括下面几种;
* 虚拟机栈中(栈帧中的本地变量表)的引用对象
* 方法区中类静态属性引用对象
* 方法区中类常量引用对象
* 本地方法栈JNI引用的对象
总结:finalize()方法不执行或者只能执行一次
不可达对象,也并非"非死不可" 这时候是在缓刑阶段。要真正宣告死亡,至少要经理两次标记过程。
如果对象进行可达性分析后发现没有GC Roots相关联的引用链,会被第一次标记并且进行一次筛选,筛选条件是此对象是否有必要执行finalize()方法。
对象没有覆盖finalize方法(逃脱命运的最后机会),或者 finalize()方法被虚拟机掉用过(只能执行一次),虚拟机将这两种情况都视为"没有必要执行"
如果被判定有必要执行,那么对象会放置叫一个F-Queue的队列之中,并且稍后虚拟机自动建立Finalize线程去执行它既finalize方法
但并不承诺会等待他运行结束,怕死循环或者运行缓慢。finalize方法是逃脱命运的最后机会,如果没有逃脱就真的被回收了;
标记:标记所有需要回收的对象
清除:统一回收所有被标记的对象
不足1:效率问题,标记和清除效率都不高;
不足2:空间问题,产生大量的不连续的内存碎片

内存容量划分两个大小相等的两块,每次使用其中的一块。这块用完了复制存活的对象到另一块,在把这块清理掉
不足:代价太高 把内存缩小为原来的一半;
现代的商用虚拟街都采用这种算法来回收新生代;因为新生代都是 朝生暮死 所以不需要1:1来划分
而将内存分为一块较大的Eden 和两个较小的Survivor 默认大小比;8:1, 每次新生代中可用的内存空间是整个新生代容量的90=(Eden+Survivor),
"浪费" 10 因为没办法保证回收只有不多于10的存活,Survivor空间不够需要老年代进行 担保;

标记和以前一样,后续步骤不是直接回收,而是存活对象向一端移动,然后清理边界以外的内存;

根据对象存活周期将内存划分不同的几块。一般堆分为 新生代 和老年代。这样根据年代的特点采用最适当的收集算法
新生代:少量存活 选择复制算法
老年代:存活率高,没有额外空间担保,必须使用 标记清理 或者标记整理;
GC会产生停顿(Sun也叫它 "Stop The World"),OoMap 存放着GC Roots,不是每条指令都生成一个。
不是任何时都能停下来进行 GC ,只有在 "特定的位置" 才可以GC 这个位置也叫安全点(Safepoint)
安全点的选定基本上是以程序"是否具有让程序长时间执行的特征"为标准选定的
关于安全点另一个需要考虑的就是如何在GC发生的时让所有线程都"跑"到最近的安全点上在停下来;有两种方案
抢先式中断(Preemptive Suspension)(现在几乎都这种方案):不需要线程的执行代码主动配合,GC发生时候先把线程全部中断,如果有线程不在安全点,就回复线程让它跑到安全点。
主动式中断(Voluntary Suspension):当GC需要中断线程的时候,不对线程造作,仅仅简单地设置一个标志位,各个线程执行的时候主动去轮询这个标志位,发现中断标志位真就挂起,轮询标志的地方安全点重合。
而对于不执行的线程,任何时间都是安全的也称为安全区;


G1收集器因为没有商用的就不写了;
Serial:单线程收集器,在进行垃圾收集时,必须要暂停其他所有的工作线程,直到它收集结束。
需要STW(Stop The World),停顿时间长。
简单高效,对于单个CPU环境而言,Serial收集器由于没有线程交互开销,可以获取最高的单线程收集效率。
ParNew:是Serial的多线程版本,除了使用多线程进行垃圾收集外,其他行为与Serial完全一样
Tips:1.Server模式下虚拟机的首选新生收集器,与CMS进行搭配使用。
Parallel Scavenge:目标是达到一个可控制的吞吐量,吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间),高吞吐量可以高效率地利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务,并且虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种调节方式称为GC自适应调节策略。
Serial Old:老年代的单线程收集器,使用标记 - 整理算法,
Parallel Old:老年代的多线程收集器,使用标记 - 整理算法,吞吐量优先,适合于Parallel Scavenge搭配使用
无法处理浮动垃圾,因为在并发清理阶段用户线程还在运行,自然就会产生新的垃圾,而在此次收集中无法收集他们,只能留到下次收集,这部分垃圾为浮动垃圾,同时,由于用户线程并发执行,所以需要预留一部分老年代空间提供并发收集时程序运行使用。
由于采用的标记 - 清除算法,会产生大量的内存碎片,不利于大对象的分配,可能会提前触发一次Full GC。虚拟机提供了-XX:+UseCMSCompactAtFullCollection参数来进行碎片的合并整理过程,这样会使得停顿时间变长,虚拟机还提供了一个参数配置,-XX:+CMSFullGCsBeforeCompaction,用于设置执行多少次不压缩的Full GC后,接着来一次带压缩的GC。
[GC (System.gc()) [PSYoungGen: 6270K->584K(9216K)] 11390K->5712K(19456K), 0.0011969 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]

* GC类型
* Minor GC:指发生在新生代的垃圾收集动作,非常频繁,速度较快。
* Major GC:指发生在老年代的GC,出现Major GC,经常会伴随一次Minor GC,同时Minor GC也会引起Major GC,一般在GC日志中统称为GC,不频繁。
* Full GC:指发生在老年代和新生代的GC,速度很慢,需要Stop The World。
大对象直接进入老年代:大对象就是大量连续内存空间的Java对象,典型的就是很长的字符串及数组。并且内存超过虚拟机设置大对象的值;
长期存活的对象进入老年代:jvm给每个对象定义一个对象年龄计数器。如果eden出生并经过第一次Minor GC后仍然存活并且能被Survivor容纳的话,将被移动到Survivor空间并将对象年龄设为1.对象在Survivor区每"熬过"一次Minor GC则年龄+1,当年龄达到一定程度(默认15岁),下一次将会被晋升老年代。
动态对象年龄判定:为了更好的适应内存状况。如果在Survivor空间中相同年龄的所有对象大小的综合大于Survivor的一半,那么大于等于这个年龄的将被一起带入老年代
Tips:研究代码对象到底怎么回收请看Page:93(深入理解JVM虚拟机第二版)

代码的运行参数设置为: -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8

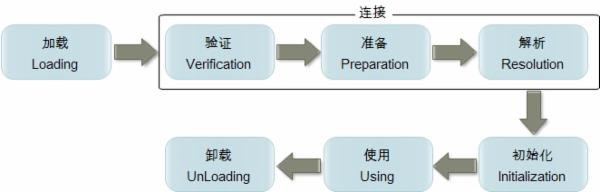
编译器手机的顺序是由语句在源文件中出现的顺序决定的,静态语句块中只能访问到定义在静态语句之前的变量,定义它之后的变量,可以赋值,但不能访问
public class Test{
static{
i=0;
system.out.print(i);//非法向前引用
}
static int i=1;
}
<clinit>(类构造器方法):如果类或者接口没有静态语句块,也没有对变量的赋值,那么编译器可以不为这个类生成<clinit>方法并且他被加锁了
Tips:如果在此方法中耗时很长,就可能造成多个进程阻塞;
Java虚拟器角度仅仅有两种不同的类加载器:
一种启动类加载器(Bootstrap ClassLoader):C++语言实现是虚拟器自身的一部分;
另一种是所有其他的类加载器(java语言,JVM之外 继承ClassLoader)
更详细:
! 
Bootstrap ClassLoader:负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类
Extension ClassLoader:负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包
App ClassLoader:负责记载classpath中指定的jar包及目录中class
Custom ClassLoader:属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader
加载过程中会先检查类是否被已加载,检查顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检查,只要某个classloader已加载就视为已加载此类,保证此类只所有ClassLoader加载一次。而加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。
###为什么这么设计?
类加载器:任何一个类都需要加载它的类加载器和这个类一同确立其在java虚拟机唯一性。每个类加载器都有类名称空间。
两个类是否相同,是由同一个类加载器为前提下才有意义.相同是指equals、instanceof isAssignalbeFrom isIntance等;
例如类java.lang.Object,他存放在rt.jar中,无论哪个类加载器加载这个类,最终都是委派给魔性最顶端的启动类加载器进行加载。因此Object类在程序的各种类加载器环境中都是 同一个类。
相反如果没有使用,各个类加载自行加载的话。那么系统将出现多个不同的Object类,那么java类型体系中最基本的行为也无法保证;
以下是ClassLoader的源码,实现很简单
rotected synchronized Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
// First, check if the class has already been loaded
Class c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
//从父加载器加载
c = parent.loadClass(name, false);
} else {
//从bootstrap loader加载
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
1.2以后,应当把自己的类逻辑写到findClass()(protected)方法中;
热部署:OSGI(类加载器精髓);
NB技巧:子类可以公开父类中的protected的方法;
public void findClass_(){
super.findClass();//protected
}
Map map=new HashMap();
Map(静态类型,外观类型接口类型(我习惯叫)):其变化仅在使用时发生,变量本身的静态类型不会改变,并且最终的静态类型是在编译期可知的。
HashMap(实际类型):其变化的结果在运行期才可确定,编译器不编译程序时并不知道一个对象的实际类型是什么。
public class OverLoad {
public static void sayHello(char arg) {
System.out.println("hello char");
}
public static void sayHello(int arg) {
System.out.println("hello int");
}
public static void sayHello(long arg) {
System.out.println("hello long");
}
public static void sayHello(Character arg) {
System.out.println("hello Character");
}
public static void sayHello(Serializable arg) {
System.out.println("hello Serializable");
}
public static void sayHello(Object arg) {
System.out.println("hello object");
}
public static void sayHello(char ...arg) {
System.out.println("hello arg...");
}
public static void main(String[] args) {
sayHello('a');
}
}
从头注解方法,结果会按顺序输出。
1、基本类型是重载按char->int->long->float->double->Character->Serializable(因为Character实现了他)顺序匹配的。
2、可变参数的重载优先级是最低的。
Tips:如果出现了两个参数分别为Serializable和Comparable(Character实现这两个),编译器无法确定自动转型那种类型。提示类型模糊拒绝编译;
方法执行会找到对应的实际类型。
NB之处 不仅仅能实现别人的接口,也能实现自己的接口这样相当于 对象本身了,但是可以却可以在方法执行之前或之后搞事情了
public class DynamicProxyTest {
interface IHello{
void sayHello();
}
static class Hello implements IHello{
@Override
public void sayHello(){
System.out.println("hello world");
}
}
static class DynamicProxy implements InvocationHandler{
Object originalObj;
Object bind(Object originalObj){
this.originalObj = originalObj;
return Proxy.newProxyInstance(originalObj.getClass().getClassLoader(), originalObj.getClass(),
getInterfaces(),this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
System.out.println("welcome");
return method.invoke(originalObj, args);
}
}
public static void main(String[] args) {
/* 设置此系统属性,让JVM生成的Proxy类写入文件.保存路径为:com/sun/proxy(如果不存在请生工创建) */
System.getProperties().put("sun.misc.ProxyGenerator.saveGeneratedFiles", "true");
IHello hello = (IHello)new DynamicProxy().bind(new Hello());
hello.sayHello();
}
}
System.getProperties().put("sun.misc.ProxyGenerator.saveGeneratedFiles", "true")->设置此系统属性,让JVM生成的Proxy类写入文件.保存路径为:com/sun/proxy(如果不存在请生工创建)
java逆向工具:为了解决把1.5中编写的代码放到1.4 1.3的环境部署使用的问题。比较出色的Retrotranslator
编译后的字节码文件中替换为原生类型,并且在相应的位置插入强制转换;
所以泛型遇到重载,不会执行编译;例如参数List<Integer>和List<String>编译后的文件是一样的所以你懂的;
public class Sugar {
//看bin目录下的编译文件;
public static void main(String[] args) {
//泛型 自动装箱,自动拆箱,便利循环,变长参数;
List<Integer> list= Arrays.asList(1,2,3,4);
int sum=0;
for (int integer : list) {
sum+=integer;
}
System.out.println(sum);
}
}
编译后文件
public class Sugar {
public Sugar() {
}
public static void main(String[] args) {
List list = Arrays.asList(new Integer[]{Integer.valueOf(1), Integer.valueOf(2), Integer.valueOf(3), Integer.valueOf(4)});
int sum = 0;
int integer;
for(Iterator var3 = list.iterator(); var3.hasNext(); sum += integer) {
integer = ((Integer)var3.next()).intValue();
}
System.out.println(sum);
}
}
当定义为volatile之后具备两种特性:
第一保证此变量对 所有线程的可见性。当一个线程修改了这个值,新值对于其他线程来说立即可知;
第二:禁止指令重排序优化;
这个目录的< volatile教材>文件夹有对应的范例;
volatile和普通变量性能几乎没有区别,比synchronized关键字快;
主要两种:协同式调度和抢占式调度
协同(不用):执行时间由线程本身来控制。吧自己工作执行完后主动通知系统切换到另一个线程;
坏处:如果线程出现堵塞那么所有都堵塞了
抢占:系统分配时间,切换不由线程本身来决定
Thread.yield()可以让出执行时间.获取时间则没有办法;
额外知识 ++不是原子性,AtomicInteger CAS(原子性)来避免阻塞同步;