通过Function Score Query优化Elasticsearch搜索结果
- - ScienJus's Blog在使用 Elasticsearch 进行全文搜索时,搜索结果默认会以文档的相关度进行排序,如果想要改变默认的排序规则,也可以通过 sort指定一个或多个排序字段. 但是使用 sort排序过于绝对,它会直接忽略掉文档本身的相关度(根本不会去计算). 在很多时候这样做的效果并不好,这时候就需要对多个字段进行综合评估,得出一个最终的排序.
在使用 Elasticsearch 进行全文搜索时,搜索结果默认会以文档的相关度进行排序,如果想要改变默认的排序规则,也可以通过 sort指定一个或多个排序字段。
但是使用 sort排序过于绝对,它会直接忽略掉文档本身的相关度(根本不会去计算)。在很多时候这样做的效果并不好,这时候就需要对多个字段进行综合评估,得出一个最终的排序。
在 Elasticsearch 中 function_score是用于处理文档分值的 DSL,它会在查询结束后对每一个匹配的文档进行一系列的重打分操作,最后以生成的最终分数进行排序。它提供了几种默认的计算分值的函数:
weight:设置权重field_value_factor:将某个字段的值进行计算得出分数。random_score:随机得到 0 到 1 分数 script_score:通过自定义脚本计算分值
它还有一个属性 boost_mode可以指定计算后的分数与原始的 _score如何合并,有以下选项:
multiply:将结果乘以 _score
sum:将结果加上 _scoremin:取结果与 _score的较小值max:取结果与 _score的较大值 replace:使结果替换掉 _score
接下来本文将详细介绍这些函数的用法,以及它们的使用场景。
weight 的用法最为简单,只需要设置一个数字作为权重,文档的分数就会乘以该权重。
他最大的用途应该就是和过滤器一起使用了,因为过滤器只会筛选出符合标准的文档,而不会去详细的计算每个文档的具体得分,所以只要满足条件的文档的分数都是 1,而 weight 可以将其更换为你想要的数值。
field\_value\_factor 的目的是通过文档中某个字段的值计算出一个分数,它有以下属性:
field:指定字段名
factor:对字段值进行预处理,乘以指定的数值(默认为 1)
modifier将字段值进行加工,有以下的几个选项:
none:不处理log:计算对数log1p:先将字段值 +1,再计算对数log2p:先将字段值 +2,再计算对数ln:计算自然对数ln1p:先将字段值 +1,再计算自然对数ln2p:先将字段值 +2,再计算自然对数square:计算平方sqrt:计算平方根reciprocal:计算倒数举一个简单的例子,假设有一个商品索引,搜索时希望在相关度排序的基础上,销量( sales)更高的商品能排在靠前的位置,那么这条查询 DSL 可以是这样的:
|
|
这条查询会将标题中带有雨伞的商品检索出来,然后对这些文档计算一个与库存相关的分数,并与之前相关度的分数相加,对应的公式为:
|
|
这个函数的使用相当简单,只需要调用一下就可以返回一个 0 到 1 的分数。
它有一个非常有用的特性是可以通过 seed属性设置一个随机种子,该函数保证在随机种子相同时返回值也相同,这点使得它可以轻松地实现对于用户的个性化推荐。
衰减函数(Decay Function)提供了一个更为复杂的公式,它描述了这样一种情况:对于一个字段,它有一个理想的值,而字段实际的值越偏离这个理想值(无论是增大还是减小),就越不符合期望。这个函数可以很好的应用于数值、日期和地理位置类型,由以下属性组成:
origin):该字段最理想的值,这个值可以得到满分(1.0)offset):与原点相差在偏移量之内的值也可以得到满分scale):当值超出了原点到偏移量这段范围,它所得的分数就开始进行衰减了,衰减规模决定了这个分数衰减速度的快慢衰减值( decay):该字段可以被接受的值(默认为 0.5),相当于一个分界点,具体的效果与衰减的模式有关
例如我们想要买一样东西:
它的理想价格是 50 元,这个值为原点
当价格超出了可接受的范围,就会让人觉得越来越不值。如果价格是 70 元,评价可能是不太想买,而如果价格是 200 元,评价则会是不可能会买,这就是由衰减规模和衰减值所组成的一条衰减曲线
或者如果我们想租一套房:
它的理想位置是公司附近
当距离超过 5km 时,我们对这套房的评价就越来越低了,直到超出了某个范围就再也不会考虑了
衰减函数还可以指定三种不同的模式:线性函数(linear)、以 e 为底的指数函数(Exp)和高斯函数(gauss),它们拥有不同的衰减曲线:
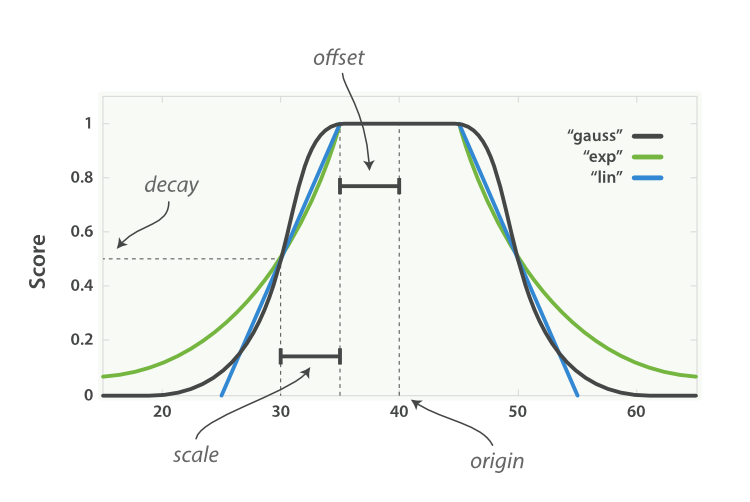
将上面提到的租房用 DSL 表示就是:
|
|
我们希望租房的位置在 40, 116坐标附近, 5km以内是满意的距离, 15km以内是可以接受的距离。
虽然强大的 field\_value\_factor 和衰减函数已经可以解决大部分问题了,但是也可以看出它们还有一定的局限性:
这两种方式应用的字段类型有限,field\_value\_factor 一般只用于数字类型,而衰减函数一般只用于数字、位置和时间类型
这时候就需要 script\_score 了,它支持我们自己编写一个脚本运行,在该脚本中我们可以拿到当前文档的所有字段信息,并且只需要将计算的分数作为返回值传回 Elasticsearch 即可。
注:使用脚本需要首先在配置文件中打开相关功能:
|
|
举一个之前做不到的例子,假如我们有一个位置索引,它有一个分类( category)属性,该属性是字符串枚举类型,例如商场、电影院或者餐厅等。现在由于我们有一个电影相关的活动,所以需要将电影院在搜索列表中的排位相对靠前。
之前的两种方式都无法给字符串打分,但是如果我们自己写脚本的话却很简单,使用 Groovy(Elasticsearch 的默认脚本语言)也就是一行的事:
|
|
接下来只要将这个脚本配置到查询语句中就可以了:
|
|
或是将脚本放在 elasticsearch/config/scripts下,然后在查询语句中引用它:
category-score.groovy:
|
|
|
|
在 script中还可以通过 params属性向脚本传值,所以为了解除耦合,上面的 DSL 还能接着改写为:
category-score.groovy:
|
|
|
|
这样就可以在不更改大部分查询语句和脚本的基础上动态修改推荐的位置类别了。
上面的例子都只是调用某一个函数并与查询得到的 _score进行合并处理,而在实际应用中肯定会出现在多个点上计算分值并合并,虽然脚本也许可以解决这个问题,但是应该没人愿意维护一个复杂的脚本吧。这时候通过多个函数将每个分值都计算出在合并才是更好的选择。
在 function\_score 中可以使用 functions属性指定多个函数。它是一个数组,所以原有函数不需要发生改动。同时还可以通过 score_mode指定各个函数分值之间的合并处理,值跟最开始提到的 boost_mode相同。下面举两个例子介绍一些多个函数混用的场景。
第一个例子是类似于大众点评的餐厅应用。该应用希望向用户推荐一些不错的餐馆,特征是:范围要在当前位置的 5km 以内,有停车位是最重要的,有 Wi-Fi 更好,餐厅的评分(1 分到 5 分)越高越好,并且对不同用户最好展示不同的结果以增加随机性。
那么它的查询语句应该是这样的:
|
|
注:其中所有以 $开头的都是变量。
这样一个饭馆的最高得分应该是 2 分(有停车位)+ 1 分(有 wifi)+ 6 分(评分 5 分 \* 1.2)+ 1 分(随机评分)。
另一个例子是类似于新浪微博的社交网站。现在要优化搜索功能,使其以文本相关度排序为主,但是越新的微博会排在相对靠前的位置,点赞(忽略相同计算方式的转发和评论)数较高的微博也会排在较前面。如果这篇微博购买了推广并且是创建不到 24 小时(同时满足),它的位置会非常靠前。
|
|
它的公式为:
|
|