微软迷踪
- 晋安渔夫 - cnBeta.COM上周一,即微软CEO史蒂夫・鲍尔默来华访问前一天,微软(Microsoft)市值15年来首次被IBM超越. 这是继去年被苹果公司挤下IT市值王座之后,微软排名再度滑落. 但这并未影响鲍尔默来华展示微软对于移动互联网的野心,他在演讲中透露,Windows Phone未来几个月内将进入中国.
计算机视觉用于物体图像识别和图像分类对很多人来说可能已经不是新鲜事,但 精细化物体分类就相对更加神秘,它从成千上万种动植物中分辨出具体种类,满足用户在实际生活中的识别需要,这也正是“微软识花”这款应用背后的秘密所在。近日,微软亚洲研究院多媒体搜索与挖掘组的研究员们通过大量的实验观察及讨论提出了一种 基于递归注意力模型的卷积神经网络,能够让精细化物体分类成为现实。
————这里是正式回答的分割线————
在日常生活中,我们可以很容易地识别出常见物体的类别(比如:计算机、手机、水杯等),但如果进一步去判断更为精细化的物体分类名称,比如去公园游览所见的各种花卉、树木,在湖中划船时遇到的各种鸟类,恐怕是专家也很难做到无所不晓。不过,也可见精细化物体分类所存在的巨大需求和潜在市场。
虽然精细化物体分类拥有广阔的应用前景,但同时也面临着艰巨的挑战。如下图所示,每一行的三种动物都属于不同种类,但其视觉差异却非常微小。要分辨他们,对于普通人来说绝非易事。

通过观察我们不难发现,对于精细化物体分类问题,其实形态、轮廓特征显得不那么重要,而细节纹理特征则起到了主导作用。 目前,精细化分类的方法主要有以下两类:
然而,这两种方法都有其各自的局限性。最近,微软亚洲研究院多媒体搜索与挖掘组的研究员们通过大量的实验观察以及与相关领域专家的讨论,创造性地提出了 “将判别力区域的定位和精细化特征的学习联合进行优化”的构想,从而让两者在学习的过程中相互强化,也由此诞生了“Recurrent Attention Convolutional Neural Network”(RA-CNN,基于递归注意力模型的卷积神经网络)网络结构。这种网络可以更精准地找到图像中有判别力的子区域,然后采用高分辨率、精细化特征描述这些区域,进而大大提高精细化物体分类的精度。该项工作已经被CVPR 2017(计算机视觉与模式识别)大会接收,并应邀做了报告分享,点击此处可查看论文 《RA-CNN:基于递归注意力模型的卷积神经网络》 。
其实,这样的情况在精细化物体分类问题中非常普遍。看似相似的两张图片,当我们把有判别力的区域放大后却发现大相径庭。而“RA-CNN”网络则有效地利用了这一特点,通过将不同尺度图像的重要区域特征融合,以确保重要信息充分发挥作用:有用的信息不丢失,同时噪声得到抑制。
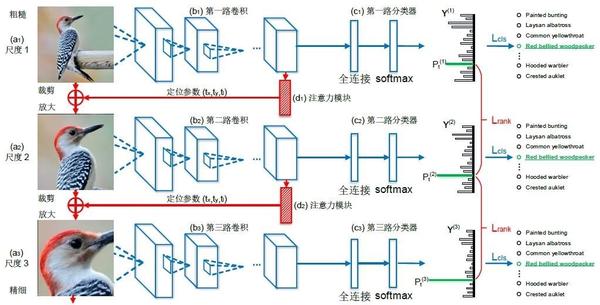
只需输入一张图片,“RA-CNN”便可自动找到不同尺度下的有判别力区域:上图中蓝色部分是分类子网络,它们将多个尺度的图片用相应的卷积层提取出特征后送入softmax 分类器,再以类别标签作为监督对卷积层和分类器参数进行优化,当最终分类时,将各个尺度的特征拼接起来,用全连接层将信息充分融合后进行分类。
上图中的红色部分则是定位子网络,其输入是一张图片的卷积层特征,而输出的是这张图片有判别力区域的中心坐标值和边长。定位子网络以层间的排序损失函数作为监督,优化下一尺度的图片子区域在正确类别上的预测概率大于本尺度的预测概率,这样可以促使网络自动找到最有判别力的区域。有了重要区域的坐标,再对原图进行裁剪和放大操作便可得到下一尺度的输入图片,而为了使网络可以进行端到端的训练,研究员们设计了一种对裁剪操作进行近似的可导函数来实现。以下是“RA-CNN”在三个公开数据集上找到的有判别力区域的例子及对应的分类精度:

看到这里或许你对“RA-CNN”精细化物体分类问题的解决原理及其效果有了一定的了解,想要亲自感受精细化物体分类技术的独特魅力的小伙伴们可以下载微软亚洲研究院推出的智能识别应用—— 微软识花一键体验哦~
————这里是回答结束的分割线————
以上回答摘选自微软研究院AI头条, 基于递归注意力模型的卷积神经网络:让精细化物体分类成为现实 。
感谢大家的阅读。
本账号为微软亚洲研究院的官方知乎账号。本账号立足于计算机领域,特别是人工智能相关的前沿研究,旨在为人工智能的相关研究提供范例,从专业的角度促进公众对人工智能的理解,并为研究人员提供讨论和参与的开放平台,从而共建计算机领域的未来。
微软亚洲研究院的每一位专家都是我们的智囊团,你在这个账号可以阅读到来自计算机科学领域各个不同方向的专家们的见解。请大家不要吝惜手里的“邀请”,让我们在分享中共同进步。
也欢迎大家关注我们的微博和微信 (ID:MSRAsia) 账号,了解更多我们的研究。