Trail:分布式追踪
- - 猫尾博客在又拍云,即使是 应用层服务也依赖到其他服务,而那些服务又依赖到了更多服务. 当一个接口超时时,定位接口的性能瓶颈是困难的. 解决定位服务性能瓶颈和错误原因的问题,是实现 Trail:分布式追踪服务 的初衷. 系统接收到外部的请求后,会在分布式系统内形成复杂的调用关系,. Trail 采集服务(进程)间的调用,记录处理调用数据,并提供分析平台.
在又拍云,即使是 应用层服务也依赖到其他服务,而那些服务又依赖到了更多服务。当一个接口超时时,定位接口的性能瓶颈是困难的。
解决定位服务性能瓶颈和错误原因的问题,是实现 Trail:分布式追踪服务 的初衷。
系统接收到外部的请求后,会在分布式系统内形成复杂的调用关系,
Credit: Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
Trail 采集服务(进程)间的调用,记录处理调用数据,并提供分析平台。
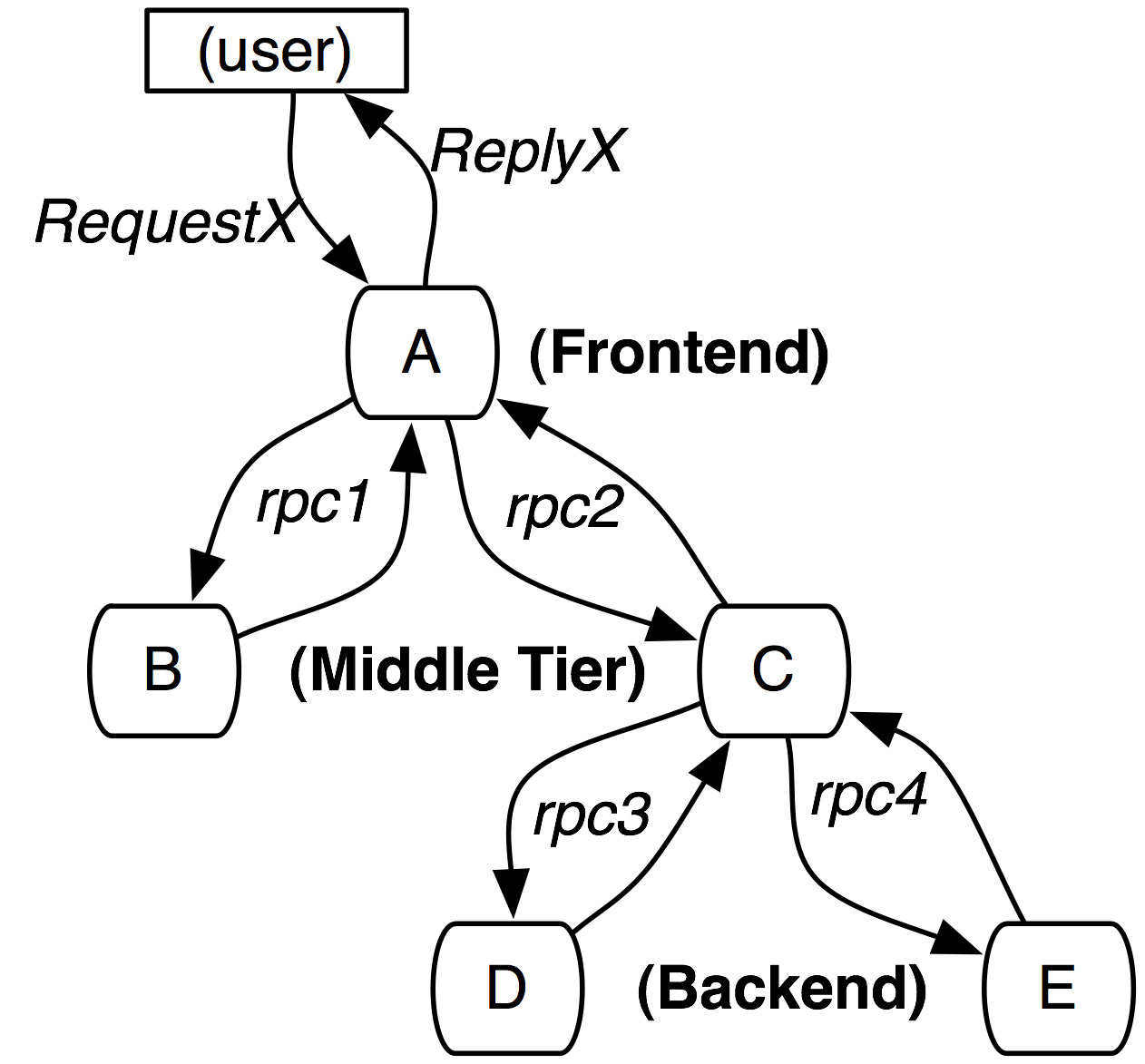
分布式系统的调用形成树状结构,我们称一次调用形成的调用链为 trace,每个 trace 有唯一 ID traceId,构成 trace 的最小元素是 span, trace 下的所有 span 有相同的 traceId。
每个 span 有自己唯一的 ID spanId,通过在 span 中存储父 span ID parentId 来建立 span 之间的关系。
Credit: Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
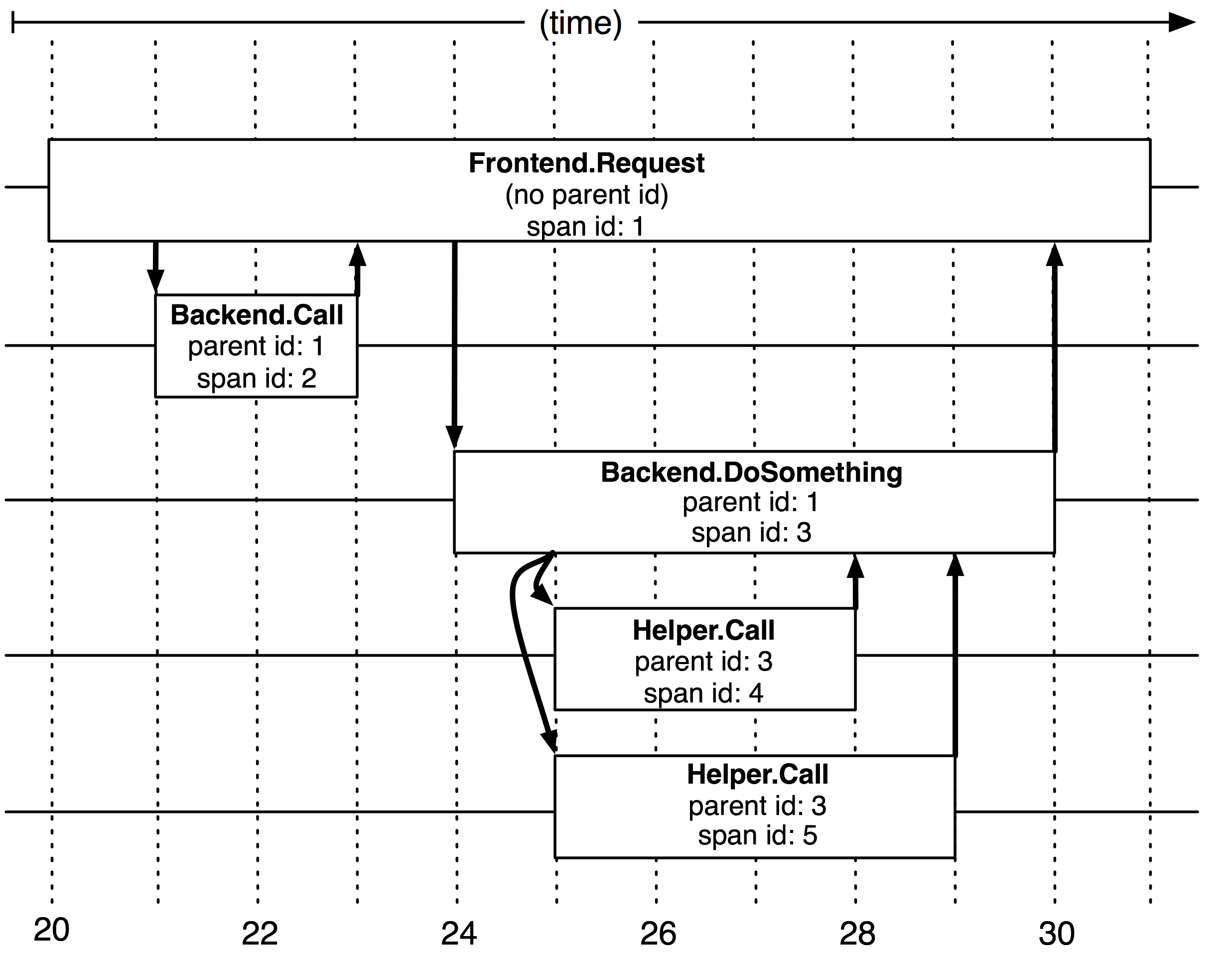
Trail 记录 span 来记录服务之间的调用,并生成完整的 trace。它通过在基础通信和调用库中增加采集代码来实现采集功能。
以 HTTP 协议举例,在前端 HTTP 服务器进程接收到用户请求后,会 创建一个新的 span,这是 trace 中的第一个 span,该 span 初始化过程中除了生成 spanId 外还会 生成 traceId。
当前端服务进程 向后端服务进程发送 HTTP 请求时, 请求头中被加入了额外信息,包括 traceId spanId。后端进程接收到请求,也会创建 span,但在创建过程中会直接使用接收到的 traceId,并设置 parentId。
span 采集的关键是
Trail 目前没有实现完善的存储机制,当 span 采集后,将通过 TCP 请求发送至 Logstash,并被转存至 Elasticsearch。
分析程序通过接口读取 Elasticsearch 数据,根据需求组装数据。
如,为了展示一次调用完整的调用链,将查询特定 traceId 下的所有 span,并通过 parentId 构建调用链。
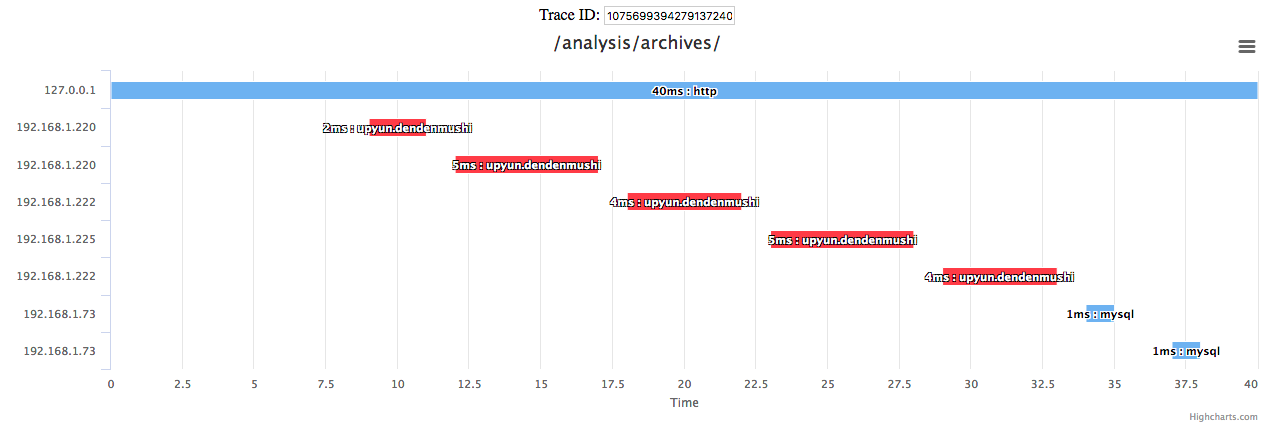
在组织服务关系过程中,需要节点 node 和关系 link 两个原子数据。节点通过对多条 span 聚合标签获得,关系通过聚合父子 span 的标签(有方向性)获得。在展示服务状态过程时,数据量较小,节点和关系数据可以在浏览器端实时计算。在展示服务关系时,数据量较大,可以通过定时任务在特定时间计算。
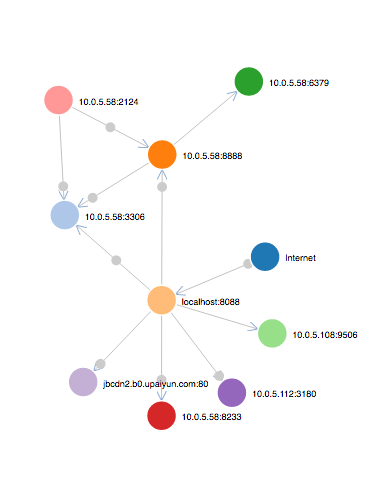
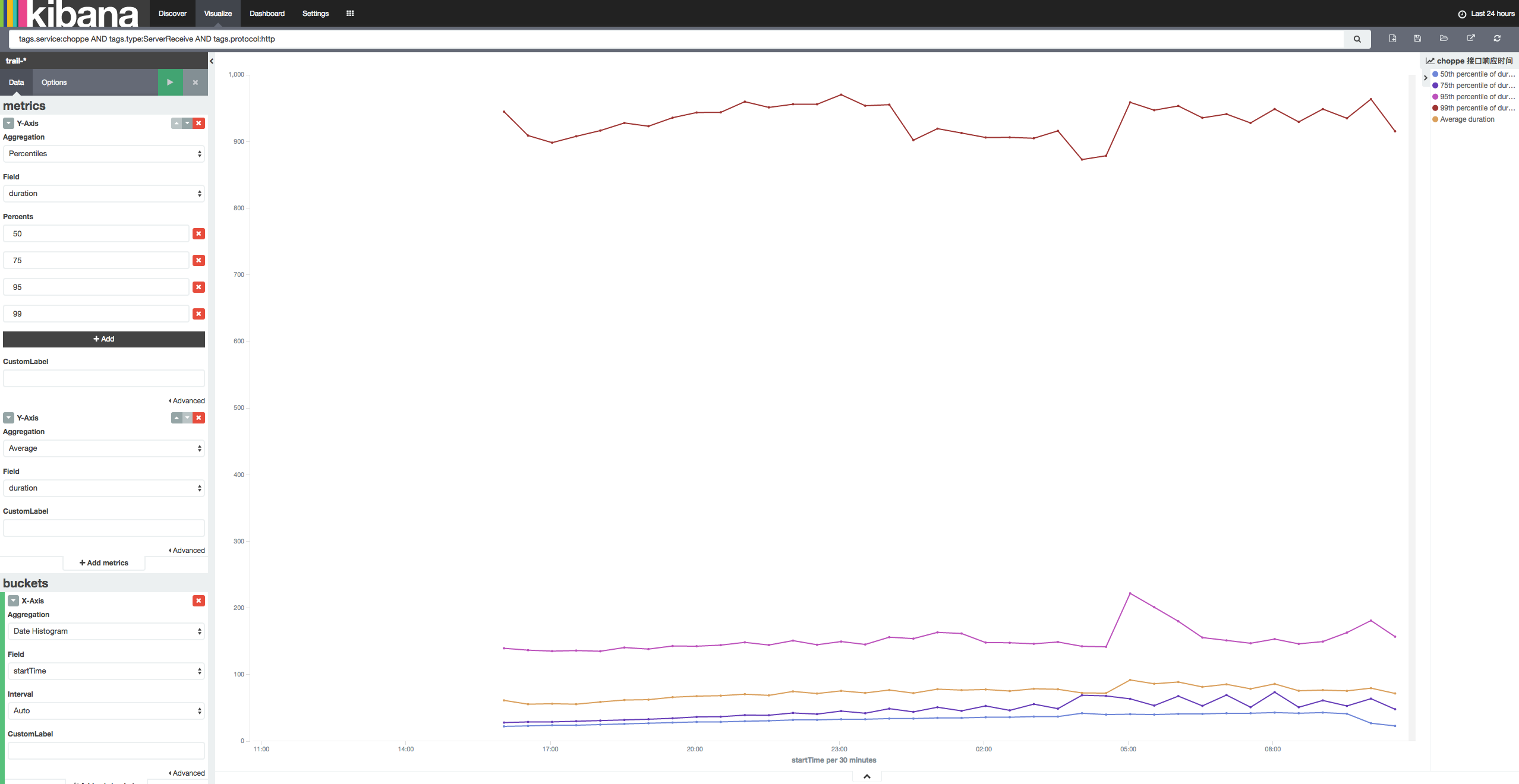
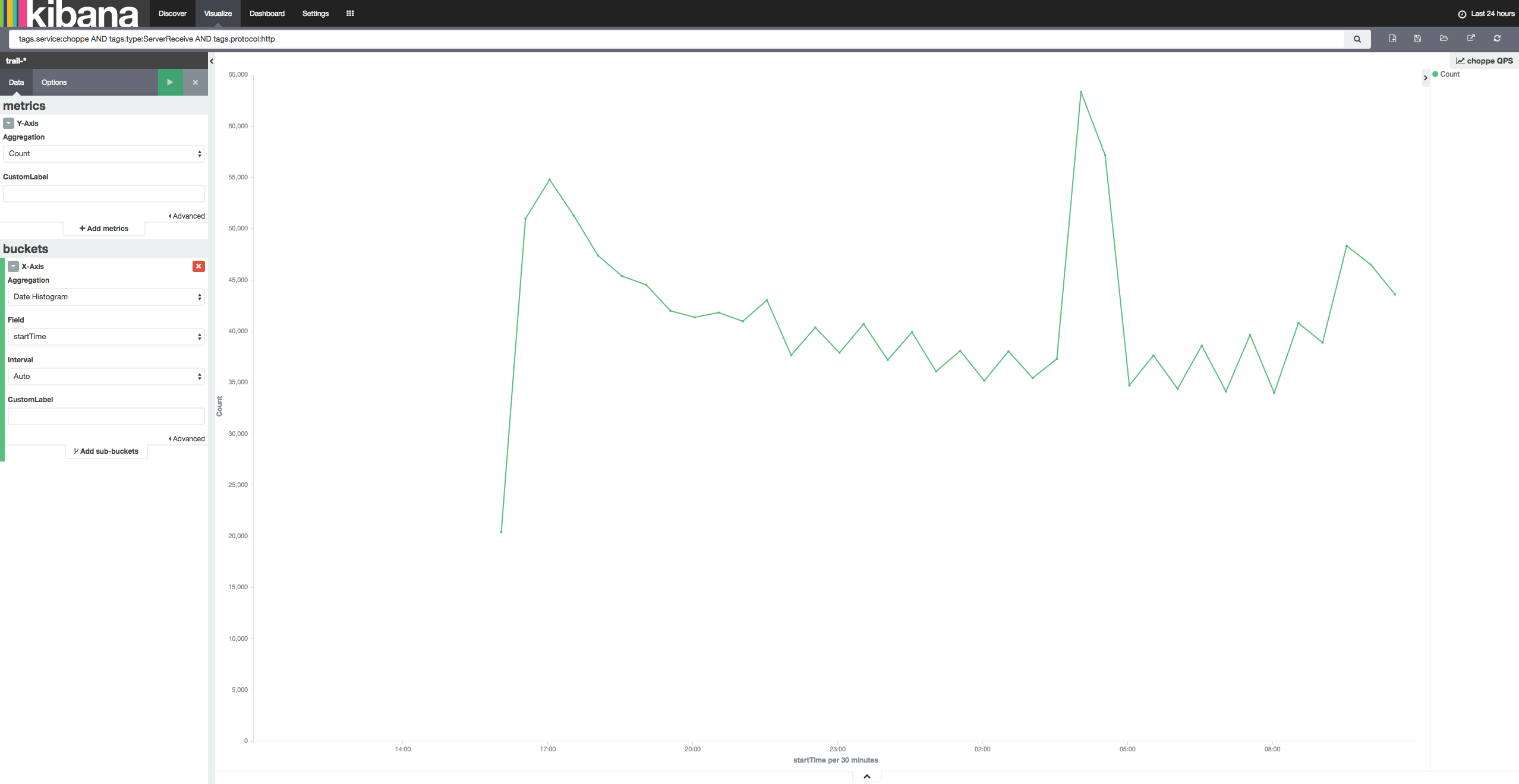
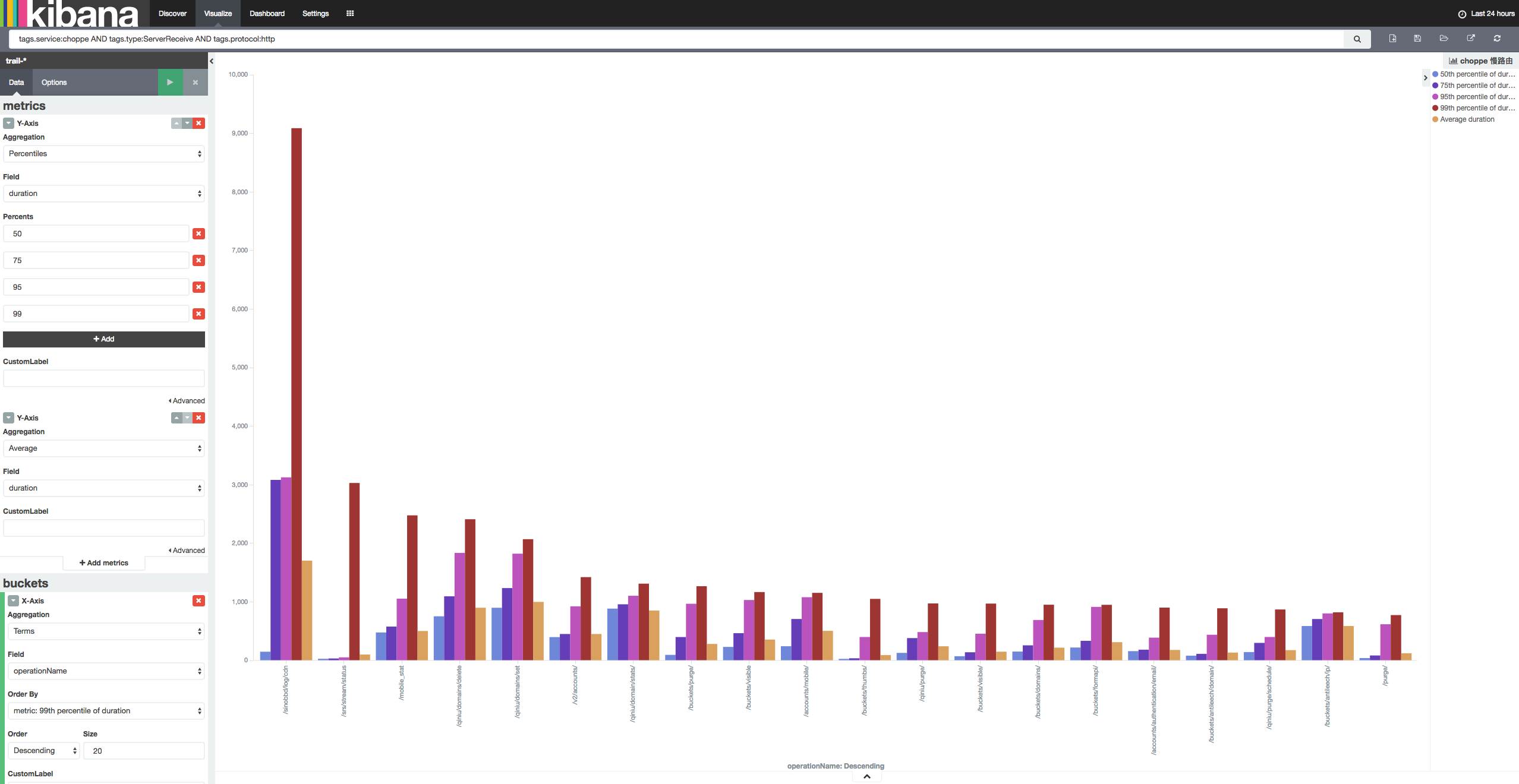
服务性能数据可以通过 Kibana 和 Elasticsearch 直接生成图表,
可用性
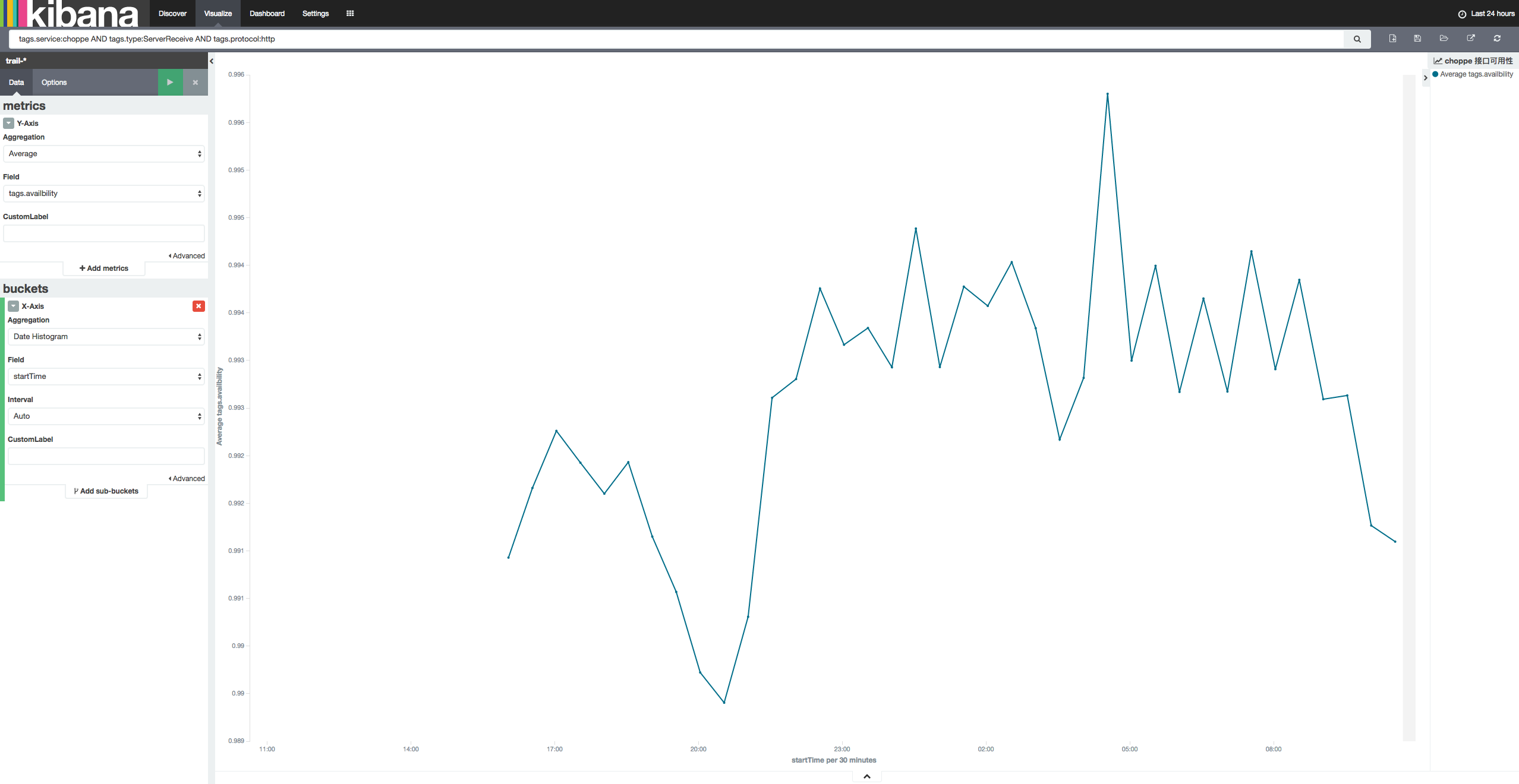
响应时间
QPS
慢路由
接口请求量
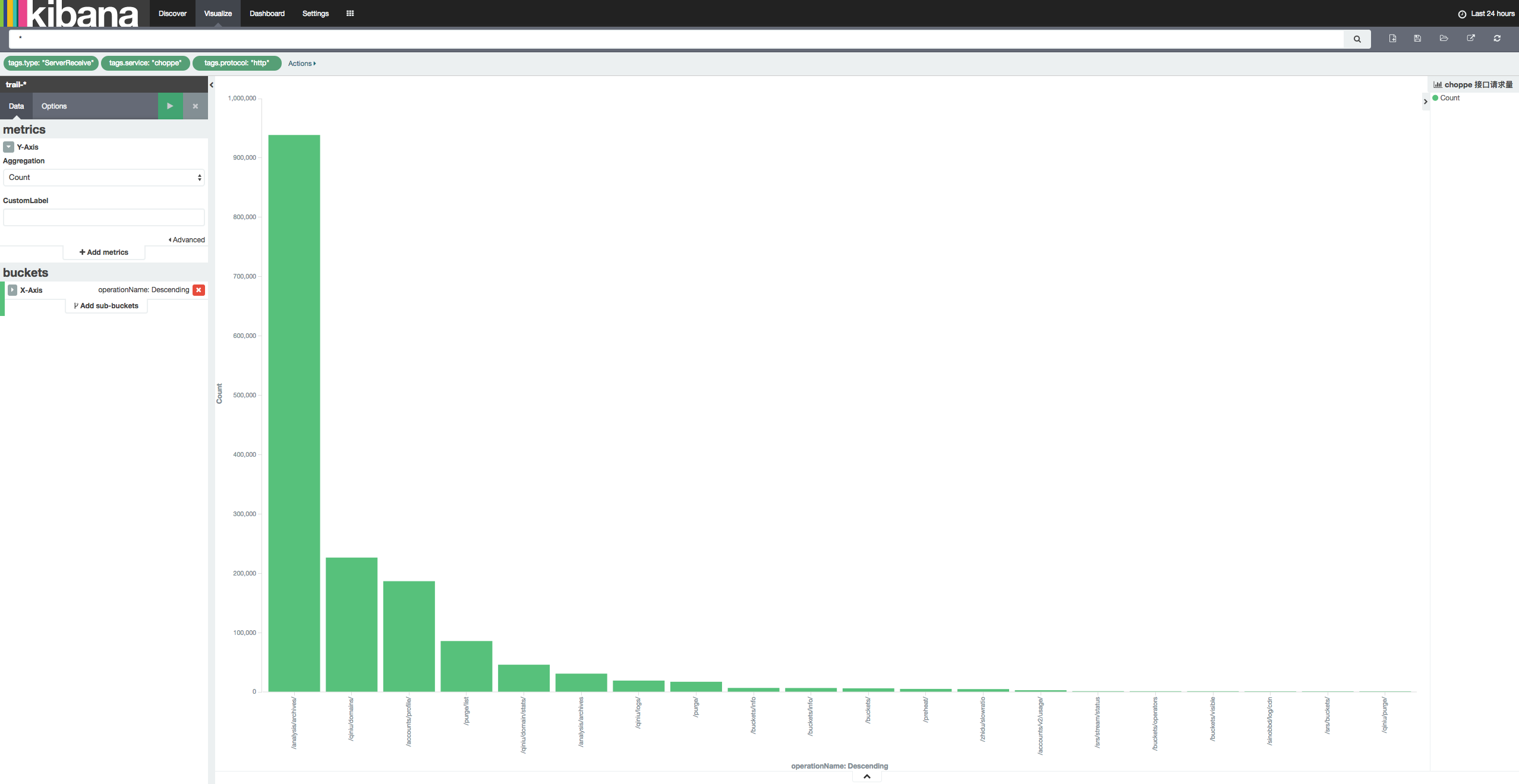
目前 Trail 的采集功能已经完善,然而在存储,处理和分析功能上还有很多遗留问题。
在绘制调用链的过程中,发现子 span 的开始时间可能小于父 span 时间,这个问题是由不同机器之间存在时间差引起的。因为整个 span 的时间非常短(通常只有十几毫秒),机器间细微的时间不同步也会导致这种现象。该问题仍未解决,仅在绘制调用链的过程中补偿时间差。
Trail 目前仅支持同步调用,对异步调用(如任务队列)其实也可以从相似的方式处理,
对 Node.js 应用代码来说,所有请求都在一个线程中,因而难以区分 当前执行代码在哪个 trace 上(Request-Local)。
continuation-local-storage 部分解决了这个问题,它通过 绑定回调函数的上下文来区分请求。然而这增加了埋点代码的复杂度,在为基础库实现采集代码时,需要 非常小心的实现和完备的测试用例,才能保证不出问题。
span 的完整数据结构
type Span {
operationName: String
startTime: Number
duration: Number
tags: [Object]
logs: [Array]
traceId: Long
spanId: Long
parentId: String
sampled: Boolean
baggage: Object
}
span 示例
{
"type": "trail",
"operationName": "upyun.account.get",
"startTime": 1475035067586,
"duration": 3,
"tags": {
"type": "ServerReceive",
"service": "surume",
"address": "10.0.5.58",
"host": "10.0.5.58",
"port": "8888",
"protocol": "upyun.dendenmushi",
"status": 0
},
"traceId": "5638971931279564310",
"spanId": "1171987629847622065",
"parentId": "17243618903848623758",
"sampled": true,
"baggage": {}
}
span 生命周期
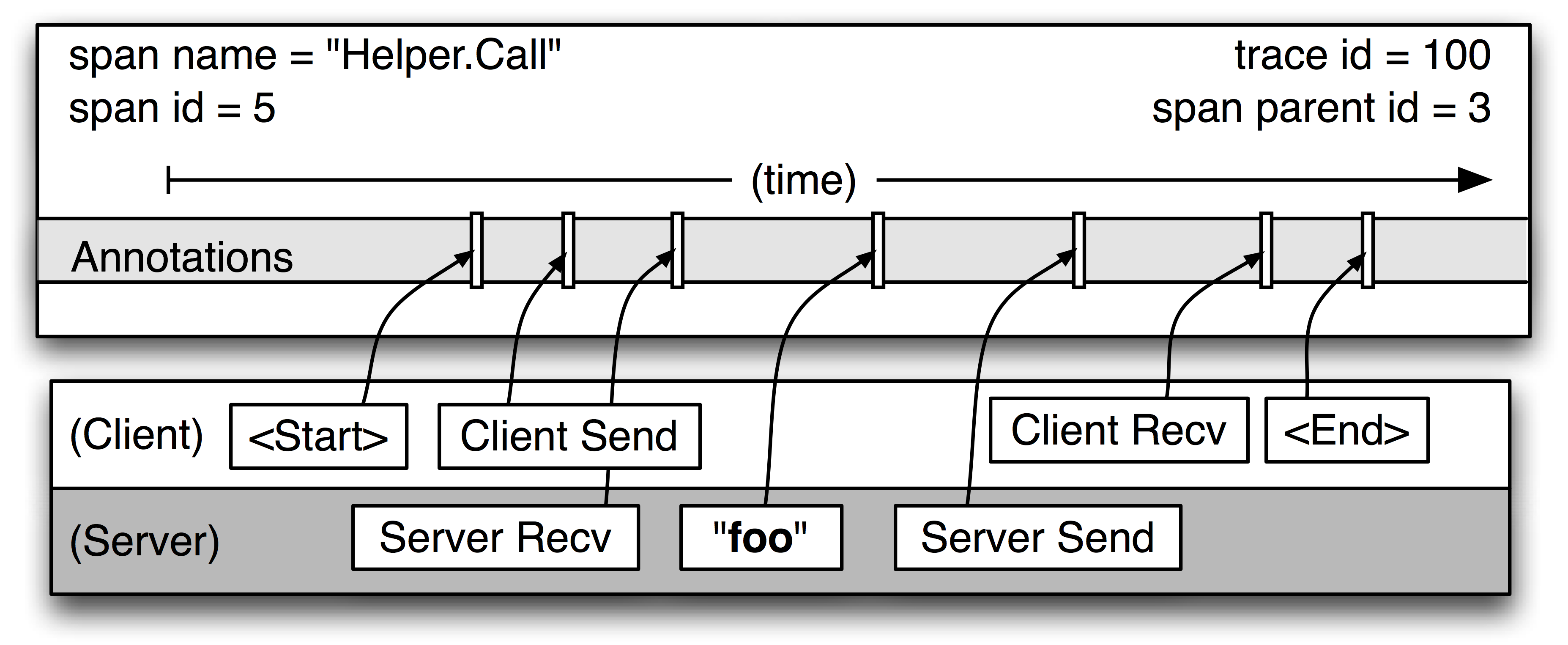
Credit: Dapper, a Large-Scale Distributed Systems Tracing Infrastructure