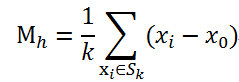
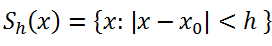

机器学习实践系列之5 - 目标跟踪 - 跟随技术的脚步-linolzhang的专栏 - CSDN博客
- -目标跟踪(Object Tracking),很多专业人士都不陌生,它是计算机视觉里面 用于视频分析的一个很大的分类,就像目标检测一样,是视频分析算法的底层支撑. 目标跟踪的算法有很多,像 Mean-Shift、光流法、粒子滤波、卡尔曼滤波等 传统方法,也有 TLD、CT、Struct、KCF 等掺杂了某些 “外力”,不那么纯粹的方法.
提到 目标跟踪(Object Tracking),很多专业人士都不陌生,它是计算机视觉里面 用于视频分析的一个很大的分类,就像目标检测一样,是视频分析算法的底层支撑。
目标跟踪的算法有很多,像 Mean-Shift、光流法、粒子滤波、卡尔曼滤波等 传统方法,也有 TLD、CT、Struct、KCF 等掺杂了某些 “外力”,不那么纯粹的方法。但不管怎样,Tracking这项工作有着很大的研究群体,也不乏有人为之奋斗终生!
• CamShift
CamShift是 连续自适应的Mean-Shift算法(Continuously Adaptive Mean-SHIFT),作为入门级的目标跟踪,包括两部分:
1. 对视频中的每一帧做 Mean-Shift;
2. 将上一帧的 Mean-Shift 结果 作为下一帧的输入,反复迭代;
算法步骤非常简单,问题可以演化为:Mean-Shift 是什么?其输入输出又是什么?
Mean-Shift就是大名鼎鼎的 均值漂移,这里面有两层含义:
1)均值
空间R中有N个样本点,任选一点x0,假定有k个点落在x的邻域范围(半径h)内,那么MeanShift向量可以定义为:
其中Sk是一个半径为h的高维球区域,满足公式:
说的再通俗一点,分两步:
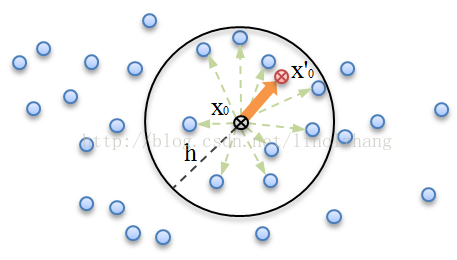
A) 任选空间内的一点x0,以该点为圆心做一个半径h的球(可能扩展到高维),统计球内的所有点,为x0的邻域点;
B) 圆心到邻域点连线作为向量,所有向量和求均值,即得到 Mean-Shift 向量。
通过均值计算,我们得到一个(x0, x'0)的向量,如图橘色箭头。
2)漂移
将圆心 x0移动到 Mean-Shift 向量的终点 x'0,就是 漂移(比平移好听)。以 x'0为新的中心,重复上面的过程,迭代计算,直到收敛。
Mean-Shift这种特征使得其在 目标跟踪、聚类、图像平滑等问题上都有应用。
核心思想是 利用概率密度的梯度爬升 来寻找局部最优。输入一个图像的区域范围,逐步迭代,对应区域朝 质心(重心)漂移。
概率密度函数 与 反向投影
事实上,我们需要将 待跟踪的目标 ROI进行提取 直方图,计算输入图像对应直方图的 反向投影,得到输入图像在已知目标颜色直方图的条件下的颜色概率密度分布图,包含了目标在当前帧中的相干信息。
对于目标区域内的像素,可得到该像素属于目标像素的概率,而对于非目标区域内的像素,该概率为0。
参考下面代码进行理解:
/* linolzhang 2013.11
CamShift跟踪
*/
#include "opencv/cv.h"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/video/tracking.hpp"
#include "opencv2/highgui/highgui.hpp"
#pragma comment(lib,"opencv_core2410.lib")
#pragma comment(lib,"opencv_imgproc2410.lib")
#pragma comment(lib,"opencv_video2410.lib")
#pragma comment(lib,"opencv_highgui2410.lib")
#define SAT_MIN 65 // 定义最小饱和度,低于该饱和度的色调不稳定
#define V_MIN 10
using namespace cv;
IplImage* getHSV(const IplImage *img,IplImage **img_h,IplImage **img_s,IplImage **img_v)
{
IplImage *img_hsv = cvCreateImage(cvGetSize(img), IPL_DEPTH_8U, 3);
cvCvtColor(img,img_hsv,CV_BGR2HSV);
cvSplit(img_hsv, *img_h, img_s==NULL?NULL:*img_s,img_v==NULL?NULL:*img_v, NULL);
// 定义掩码,只处理像素值为H:0~180,S:SAT_MIN~255的部分
IplImage *img_msk = cvCreateImage(cvGetSize(img), IPL_DEPTH_8U, 1);
cvInRangeS(img_hsv, cvScalar(0,SAT_MIN,V_MIN,0),cvScalar(180,255,255,0), img_msk);
cvReleaseImage(&img_hsv);
return img_msk;
}
int main(int argc, char** argv)
{
IplImage *src = cvLoadImage("1.jpg", -1); // 加载源图像 - 包含待跟踪目标
CvRect rcROI = cvRect(132,296,132,176); // 待跟踪目标位置
// 1.将目标转换到HSV空间,提取Hue分量
IplImage *src_h = cvCreateImage(cvGetSize(src), IPL_DEPTH_8U, 1);
IplImage *src_s = cvCreateImage(cvGetSize(src), IPL_DEPTH_8U, 1);
IplImage *hsv_mask = getHSV(src,&src_h,&src_s,NULL);
// 2.计算分量直方图 - 1维
int hist_size = 256; // 64 | 128 | 256
float range[] = {0,180};
float *ranges[] ={ range };
CvHistogram *hist = cvCreateHist(1, &hist_size, CV_HIST_ARRAY, ranges);
cvSetImageROI(src,rcROI); // 设置源图像ROI
cvCalcHist(&src_h, hist,0,hsv_mask);
cvReleaseImage(&hsv_mask);
cvResetImageROI(src); // 清空ROI
// 3.计算反向投影,得到概率密度图 img_prob
IplImage *dest = cvLoadImage("2.jpg", -1); // 从这幅图搜索
IplImage *dest_h = cvCreateImage(cvGetSize(dest), IPL_DEPTH_8U, 1);
IplImage *dest_s = cvCreateImage(cvGetSize(dest), IPL_DEPTH_8U, 1);
hsv_mask = getHSV(dest,&dest_h,&dest_s,NULL);
IplImage *img_prob = cvCreateImage(cvGetSize(dest),IPL_DEPTH_8U,1);
cvCalcBackProject(&dest_h,img_prob,hist);
cvAnd(img_prob, hsv_mask, img_prob, 0);
cvReleaseImage(&hsv_mask);
// 4.调用MeanShift函数计算
// int cvMeanShift(IplImage* imgprob,CvRect windowIn,CvTermCriteria criteria,CvConnectedComp* out);
// 参数说明:imgprob: 2D概率密度图 windowIn:初始窗口 criteria:迭代终止条件 out:输出结果
CvConnectedComp conn_comp;
cvMeanShift(img_prob,rcROI, cvTermCriteria(CV_TERMCRIT_ITER,10,0.1), &conn_comp);
//CvBox2D track_box;
//cvCamShift(img_prob,rcROI,cvTermCriteria(CV_TERMCRIT_ITER, 100, 0.01 ),&conn_comp, &track_box );
// 5.绘制结果
cvRectangle( src,cvPoint(rcROI.x,rcROI.y),cvPoint(rcROI.x+rcROI.width,rcROI.y+rcROI.height),cvScalar(0,255,0) );
cvShowImage("源图像",src);
cvShowImage("概率密度图",img_prob);
cvRectangle( dest,cvPoint(rcROI.x,rcROI.y),cvPoint(rcROI.x+rcROI.width,rcROI.y+rcROI.height),cvScalar(0,255,0) );
CvRect& rc = conn_comp.rect;
cvRectangle( dest,cvPoint(rc.x,rc.y),cvPoint(rc.x+rc.width, rc.y+rc.height),cvScalar(255,255,0) );
cvShowImage("Track结果",dest);
cvWaitKey(0);
// 释放资源
cvReleaseImage(&src);
cvReleaseImage(&dest);
cvReleaseImage(&img_prob);
return 0;
} CamShift算法在 Mean-Shift算法基础上进行了改进:
连续自适应:利用前一帧的目标尺寸调节搜索窗口大小,对有尺寸变化的目标可准确定位;
不过, CamShift算法在计算目标模板直方图分布时,没有使用核函数进行加权处理,也就是说目标区域内的每个像素点在目标模型中有着相同的权重,故算法的抗噪能力低于 Mean-Shift算法。
另外, CamShift 算法仍然采用目标的色彩信息来进行跟踪(Hue in HSV),很难处理目标与背景颜色(或其他对象)相近的情况,跟踪结果的鲁棒性仍然较差。
Cam Shift通常用于单目标跟踪,虽然也有人进行过多目标跟踪扩展,不过效果并不好。
• TLD
纯粹的跟踪已经out了,Tracking by Detecting 才是主流。
TLD(Tracking-Learning-Detection)是一种新的单目标长时间跟踪算法。该算法的贡献在于 将传统的 跟踪算法和 检测算法相结合解决 目标在跟踪过程中发生的形变、部分遮挡等问题。
原作者网站: http://personal.ee.surrey.ac.uk/Personal/Z.Kalal/
C++ 封装代码: https://github.com/arthurv/OpenTLD
Ubuntu下编译过程,进入OpenTLD-master目录:
1)$mkdir build
2)$cd build
3)$cmake ../src
4)make
可能会提示错误 PatchGenerator不是cv的一个成员,这是OpenCV版本过高导致的兼容问题(原版本是2.3),可以在TLD.h文件头文件添加:
#include <opencv2/legacy/legacy.hpp>
调试运行:
5)cd .. # 进入程序根目录
6)sudo bin/run_tld -p parameters.yml -s datasets/06_car/car.mpg
能够看到,TLD的跟踪效果还是很不错的。
TLD算法原理:
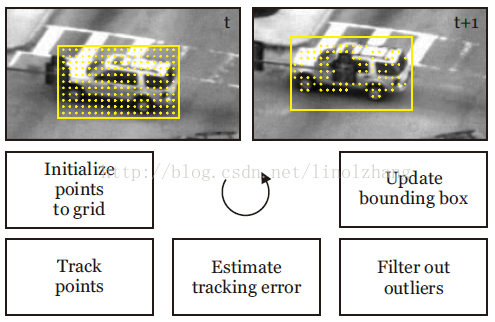
1)通过 跟踪器对目标进行跟踪,作者采用的是 光流法(Lucas-Kanade),这里作者引用了一个FB误差,可以描述为:
a)在 t 时刻,目标框随机初始化跟踪点,通过正向追踪得到 t+1时刻的目标位置;
b)反向追踪到 t 时刻,计算误差,选择其中误差最小的一半点作为最佳跟踪点;
类似 RanSac,找一些对结果贡献大的点。
示意如下图所示:
2)通过 检测器 对目标进行检测,作者使用了一个 级联分类器 作为Detector,其中用到了随机蕨(Random Ferns),这里不再多说;
3)通过 学习器在线学习目标特征,根据上面 跟踪器和检测器获得的正负样本进行在线训练,学习目标特征,并将训练特征更新到 检测器。
话说Online 真是个好思路,都在用,由于光线、遮挡、观测角度等原因,在运动过程中目标特征会有所变化。
算法不算复杂,这里面有个关键,就是作者提出的 P-N学习(P-N Learning)方法。
P-N学习针对 检测器对样本分类时产生的两种错误提供了两种“专家”进行纠正:
P专家(P-expert):检出漏检(false negative,正样本误分为负样本)的正样本;
N专家(N-expert):改正误检(false positive,负样本误分为正样本)的正样本。
说的通俗点就是,将检测结果和跟踪结果进行整合,哪个好用哪个, P-N学习是一个裁判员。
TLD 方法思想是非常值得借鉴的,当然这里面的 检测、跟踪、特征学习环节都可以基于你的需要进行修改和替换,毕竟TLD也已经不新了,你可以用深度学习的方法,也可以用效率更高的方法,Whatever。
• CT
压缩跟踪(Compressive Tracking) 是一种基于压缩感知的跟踪算法,来看作者(Kaihua Zhang,香港理工大学) 对该算法的简介:
首先利用符合压缩感知 RIP条件的随机感知矩对多尺度图像特征进行降维,然后在降维后的特征上采用简单的朴素贝叶斯分类器进行分类。
论文参考: Real-time compressive tracking. Kaihua Zhang, Lei Zhang, Ming-Hsuan Yang. ECCV 2012.(有代码可参考)
核心点:
1. 在 t时刻,进行图像采样(Patch),得到若干 正样本(目标)和 负样本(背景),通过金字塔变换得到多尺度特征;
2. 通过 稀疏测量矩阵M 对多尺度图像特征降维,然后利用降维后的特征 训练 分类器C(作者用了朴素贝叶斯);
3. 在 t+1时刻,在目标位置周围采样N个Candidate(邻域原则),同样通过 稀疏测量矩阵M 对其降维,提取特征;
4. 用 t 时刻用 分类器C进行分类,Score最大的窗口就是目标窗口。
• Struct
来自一篇2011年的ICCV:
Struck:Structured Output Tracking with Kernels
这里面用到了 高斯核函数,具体方法作者并没有详细研究,请自行脑补吧。
• KCF
KCF是一个非常经典的算法(kernelized correlation filters),速度快、效果好,来自论文:
High-speed tracking with kernelized correlation filters(ECCV 2012, TPAMI 2015)
Paper及源码下载参考作者主页: http://www.robots.ox.ac.uk/~joao/#
KCF算法的主要贡献:
1. 使用目标周围区域的循环矩阵采集正负样本,利用岭回归训练目标检测器;
算法利用 循环矩阵在傅里叶空间可对角化的性质将矩阵的运算转化为向量的Hadamad积,即元素的点乘,大大降低了运算量。
2. 将线性空间的岭回归通过核函数映射到非线性空间,在非线性空间通过求解一个对偶问题和某些常见的约束,同样的可以使用循环矩阵傅里叶空间对角化简化计算。
3. 给出了一种将多通道数据融入该算法的途径。
OpenCV3.1.0 在 contrib里提供了KCF的实现,需要用CMake重新编译,这里作者用的是VS2013(对应vc12)。
配置编译步骤:
1. 下载及项目配置
下载contrib库: https://github.com/opencv/opencv_contrib
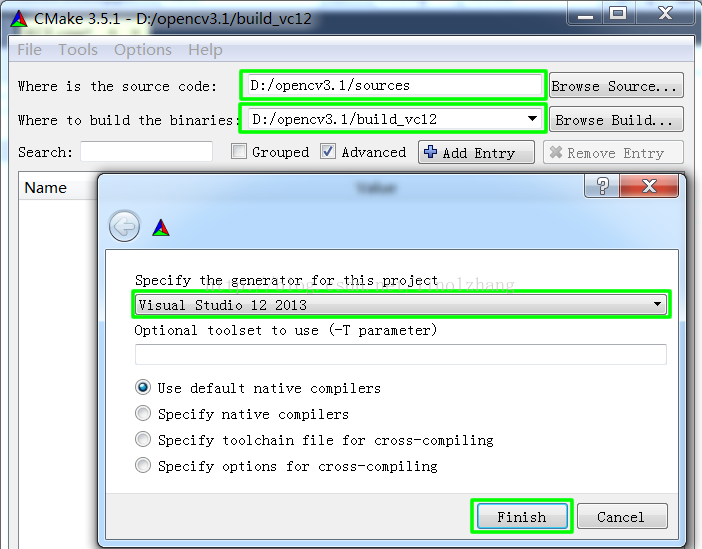
选择Source及binaries(生成位置),指定generator,Finish完成配置,如下图所示:
2. 添加编译选项
找到OPENCV_EXTRA_MODULES_PATH,加入opencv_contrib目录。
例如:作者的opencv_contrib 路径为D:/opencv3.1/opencv_contrib-master/modules
编译并生成,configure & generate
3. 配置VS2013
配置头文件 和 库文件,设置环境dll,调试运行程序
参考代码:
#include <opencv2/core/utility.hpp>
#include <opencv2/tracking.hpp>
#include <opencv2/videoio.hpp>
#include <opencv2/highgui.hpp>
#include <iostream>
using namespace std;
using namespace cv;
int main()
{
Rect2d roi;
Mat frame;
// create a tracker object
Ptr<Tracker> tracker = Tracker::create("KCF");
VideoCapture cap("1.avi");
cap >> frame;
// [selectroi]选择目标roi以GUI的形式
roi = selectROI("tracker", frame);
if (roi.width == 0 || roi.height == 0) // Invalid ROI
return 0;
// init
tracker->init(frame, roi);
// perform the tracking process
printf("Start the tracking process\n");
while(true)
{
cap >> frame;
if (frame.rows == 0 || frame.cols == 0)
break;
tracker->update(frame, roi);
rectangle(frame, roi, Scalar(255, 0, 0), 2, 1); // draw roi
imshow("tracker", frame); // show image
if(waitKey(1) == 27)
break;
}
return 0;
}