使用kibana可视化报表实时监控你的应用程序,从日志中找出问题,解决问题 - 一线码农 - 博客园
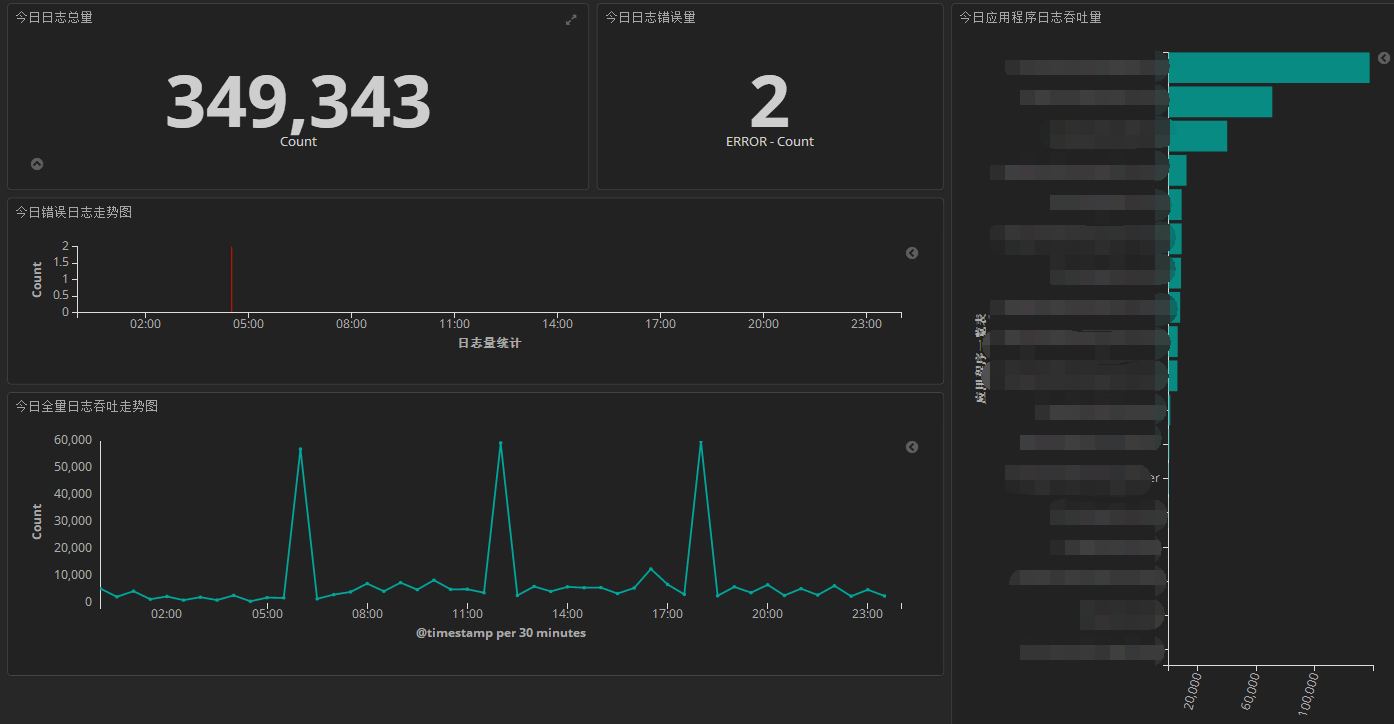
- - 先结果导向,来看我在kibana dashborad中制作的几张监控图. dashboard1:监控几个维度的日志,这么点日志量是因为把无用的清理掉了,而且只接入了部分应用. <1> 每日日志总数. <2> 每日日志错误数,从log4net中level=ERROR抠出来的.
先结果导向,来看我在kibana dashborad中制作的几张监控图。
一:先睹为快
dashboard1:监控几个维度的日志,这么点日志量是因为把无用的清理掉了,而且只接入了部分应用。
<1> 每日日志总数。
<2> 每日日志错误数,从log4net中level=ERROR抠出来的。
<3> 每个应用贡献的日志量(按照应用程序分组)
<4> 今日错误日志时间分布折线图。
<5> 今日全量日志时间分布折线图。
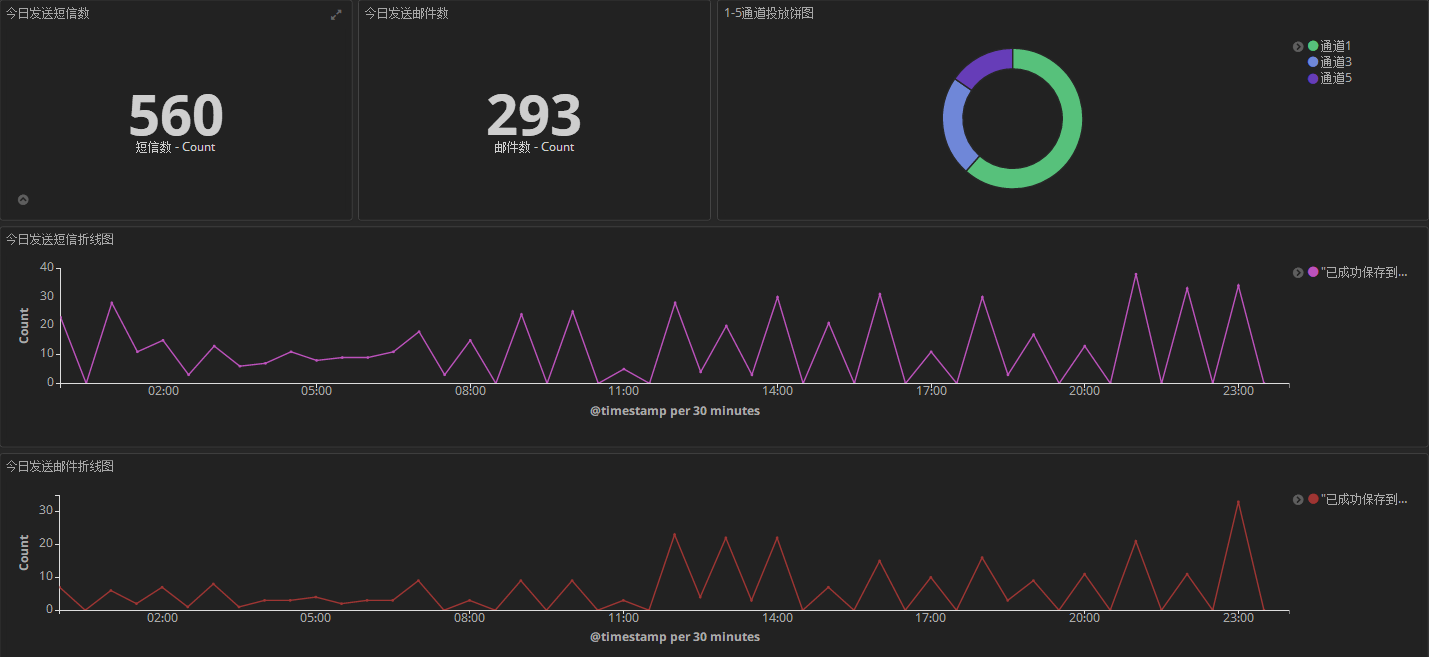
dashboard2:这个主要用来监控某日智能精准触发的短信数和邮件数以及通道占比情况。
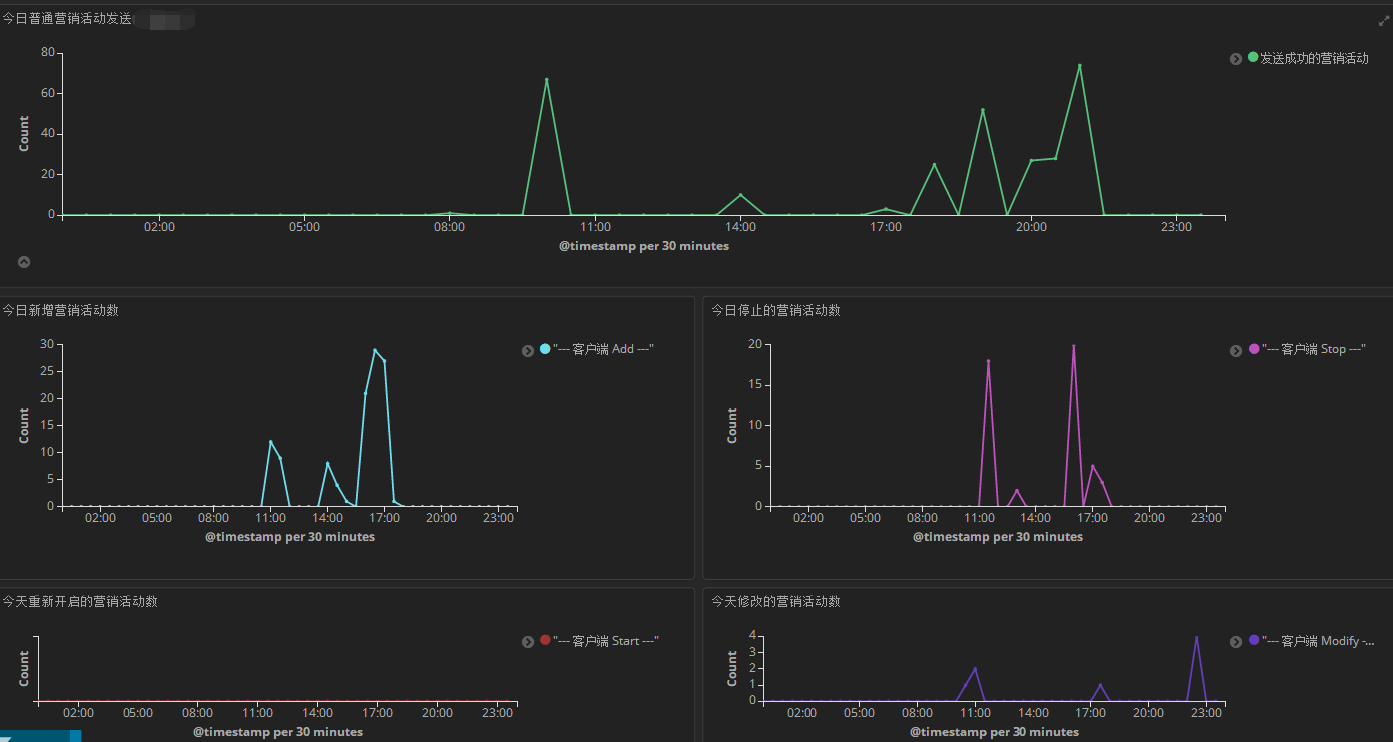
dashboard3: 某日发送的营销活动概况,一目了然。
二:采集注意事项
接下来我们聊聊这个流程中注意的问题。
1. 使用fileBeat 清洗掉垃圾日志
采集端使用的是filebeat,一个应用程序配置一个prospectors探测器。
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
# Each - is a prospector. Most options can be set at the prospector level, so
# you can use different prospectors for various configurations.
# Below are the prospector specific configurations.
################## 1. IntelligentMarketing.Service3 ##################
-
enabled: true
paths:
D:\Services\channel3\log\*.log
exclude_lines: ['^----------','重新排队,暂停 100。$']
fields:
appname: IntelligentMarketing.Service3
ipnet: 10.153.204.199
ippub: 121.41.176.41
encoding: gbk
multiline.pattern: ^(\s|[A-Z][a-z]|-)
multiline.match: after
################## 2. IntelligentMarketing.Service4 ##################
-
enabled: true
paths:
D:\Services\channel4\log\*.log
exclude_lines: ['^----------','重新排队,暂停 100。$']
fields:
appname: IntelligentMarketing.Service4
ipnet: 10.153.204.199
ippub: 121.41.176.41
encoding: gbk
multiline.pattern: ^(\s|[A-Z][a-z]|-)
multiline.match: after
《1》 exclude_lines
这个用来过滤掉我指定的垃圾日志,比如说以 ----------- 开头的 和 “重新排队,暂停100。”结尾的日志,反正正则怎么用,这里就怎么配吧,有一点注意,
尽量不要配置 contain模式的正则,比如: '.*暂未获取到任何mongodb记录*.' 这样会导致filebeat cpu爆高。
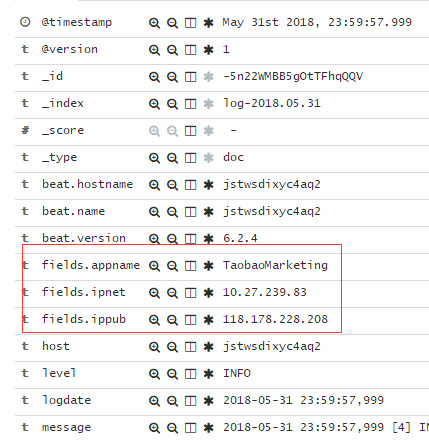
《2》 fields
这个用于配置应用程序专属的一些信息,比如我配置了appname,内网ip,外网ip,方便做后期的日志检索,检索出来就是下面这样子。
《3》 multiline
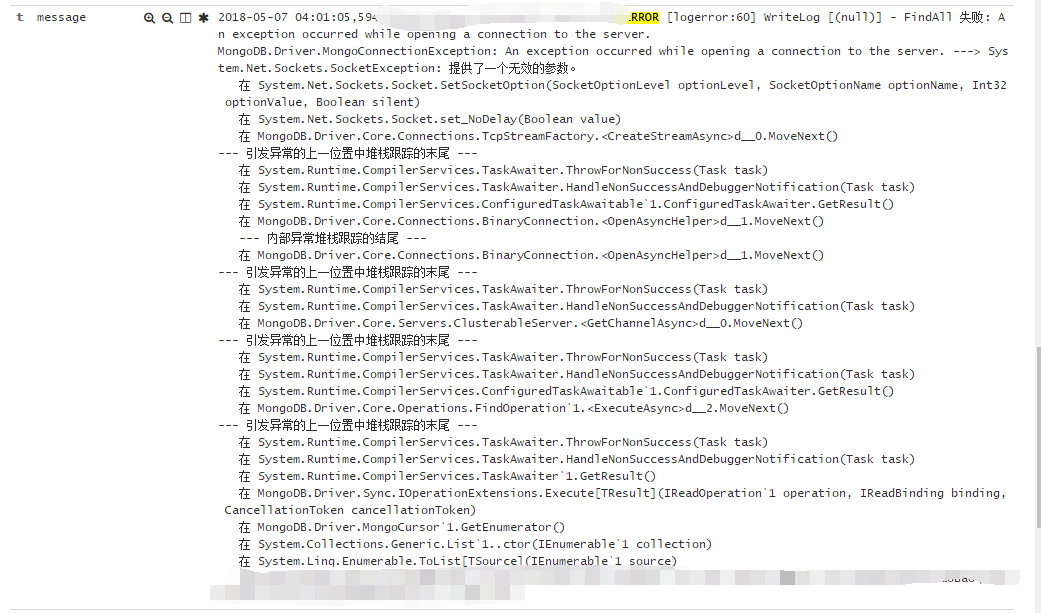
有时候应用程序会抛异常,就存在着如何合并多行信息的问题,我这里做的配置就是如果当前行是以‘空格’,‘字母‘ 和 ‘-’开头的,那么就直接合并到上
一行,比如下面这个Mongodb的FindALL异常堆栈。
2. logstash解析日志
主要还是使用 grok 正则,比如下面这条日志,我需要提取出‘date’,‘threadID’,和 “ERROR” 这三个重要信息。
2017-11-13 00:00:36,904 [65] ERROR [xxx.Monitor.Worker:83] Tick [(null)] - 这是一些测试数据。。
那么就可以使用如下的grok模式。
match => { "message" => "%{TIMESTAMP_ISO8601:logdate} \[%{NUMBER:threadId}\] %{LOGLEVEL:level}"}
上面这段话的意思就是:提取出的时间给logdate,65给threadId,ERROR给level,然后整个内容整体给默认的message字段,下面是完整的logstash.yml。
input {
beats {
port => 5044
}
}
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:logdate} \[%{NUMBER:threadId}\] %{LOGLEVEL:level}"}
}
if ([message] =~ "^----------") {
drop {}
}
date {
match => ["logdate", "yyyy-MM-dd HH:mm:ss,SSS"]
# target => "@timestamp"
timezone => "Asia/Shanghai"
}
ruby {
code => "event.timestamp.time.localtime"
}
}
output {
stdout {
codec => rubydebug { }
}
elasticsearch {
hosts => "10.132.166.225"
index => "log-%{+YYYY.MM.dd}"
}
}
三: kibana制作
1. 今日全量日志吞吐走势图
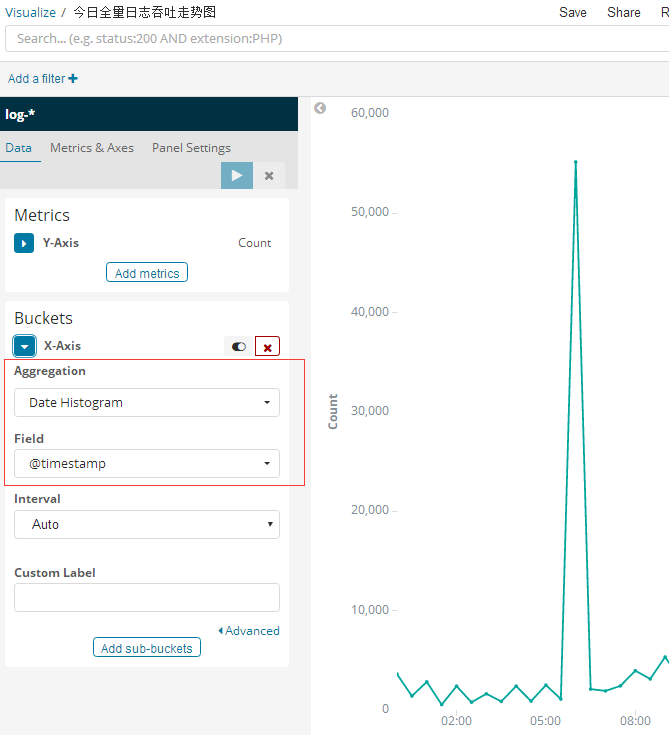
这个比较简单。因为本质上是一个聚合计算,aggreration按照 Date Histogram聚合即可。
2. 今日错误日志走势图
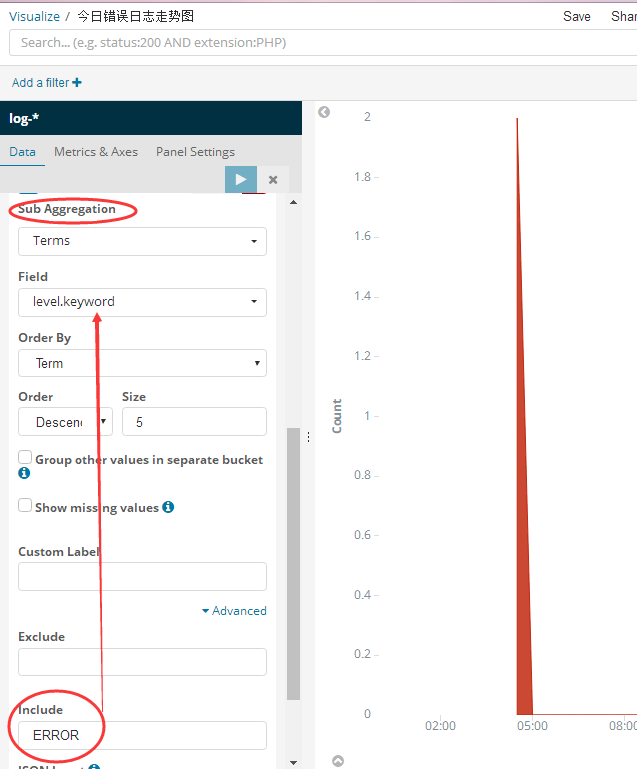
这个相当于在上面那个按时间聚合分组之后,然后在每一个bucket中再做一个 having level=‘ERROR’的筛选即可。
3. 今日普通营销活动发送
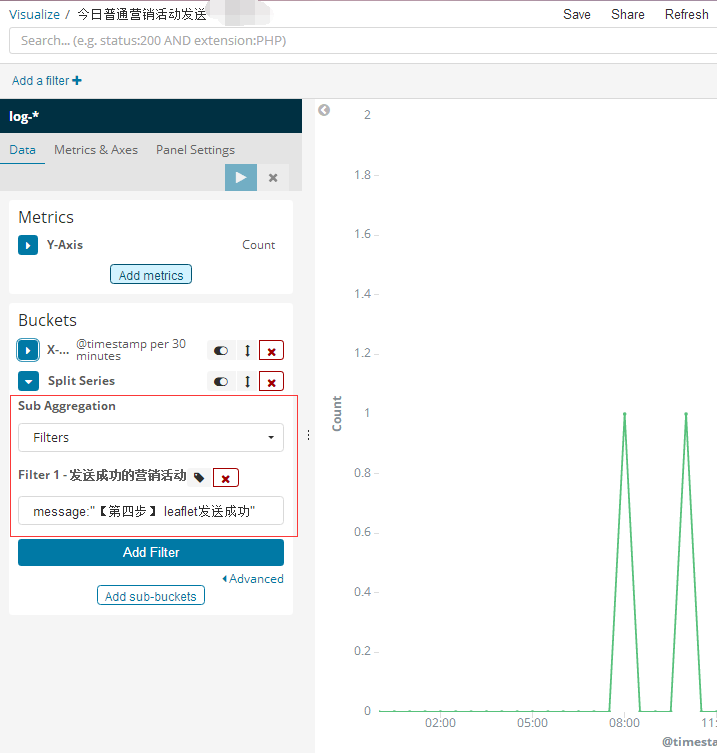
这个就是在bucket桶中做了一个 having message like '%【第四步】 leaflet发送成功%' ,为什么这么写是因为只要发送成功,我都会追加这么一条日志,
所以大概就是这么个样子,性能上大家应该也知道,对吧。
4. 今日应用程序日志吞吐量
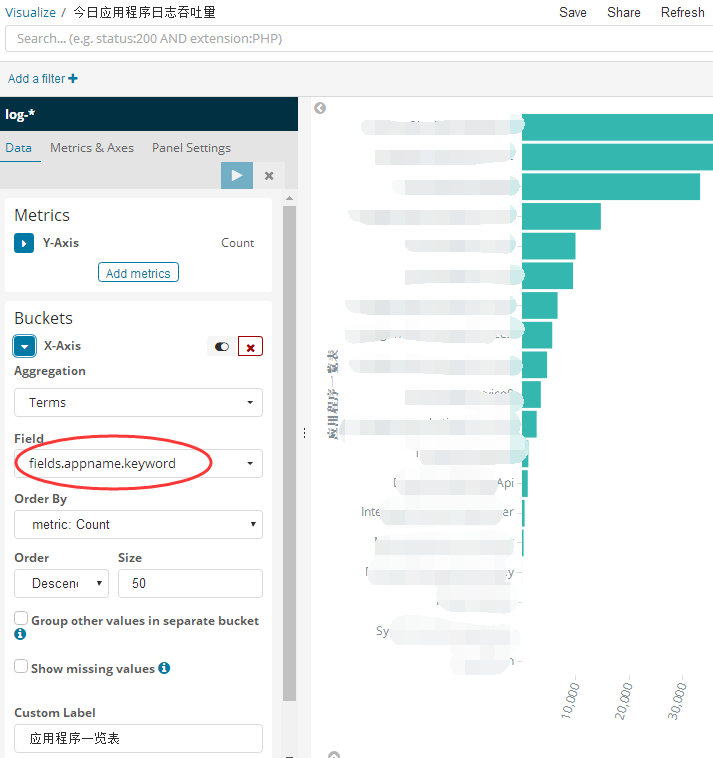
这个不想上面那三张图按照时间聚合,而是按照appname 聚合就可以了,还记得我在filebeat的fileld中添加的appname字段吗?
四:使用nginx给kibana做权限验证
为了避开x-pack 的复杂性,大家可以使用nginx给kibana做权限验证。
1. 安装 yum install -y httpd-tools。
2. 设置用户名和密码:admin abcdefg
htpasswd -bc /data/myapp/nginx/conf/htpasswd.users damin abcdefg
3. 修改nginx的配置。
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
auth_basic "Restricted Access";
auth_basic_user_file /data/myapp/nginx/conf/htpasswd.users; #登录验证
location / {
proxy_pass http://10.122.166.225:5601; #转发到kibana
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
allow 222.68.71.185; #允许的IP
allow 118.133.47.76; #允许的IP
deny all;
}
4. 重启nginx
[root@localhost conf]# /data/myapp/nginx/sbin/nginx -s reload
然后绑定域名到你的ip之后,登陆就会有用户名密码验证了。
好了,本篇就说这么多,希望对你有帮助。