使用filebeat收集kubernetes中的应用日志 - 宋净超的博客|Cloud Native|云原生布道师
- -本文已同步更新到Github仓库. kubernetes-handbook中. 使用Logstash收集Kubernetes的应用日志,发现logstash十分消耗内存(大约500M),经人提醒改用filebeat(大约消耗10几M内存),因此重写一篇使用filebeat收集kubernetes中的应用日志.
本文已同步更新到Github仓库 kubernetes-handbook中。
昨天写了篇文章 使用Logstash收集Kubernetes的应用日志,发现logstash十分消耗内存(大约500M),经人提醒改用filebeat(大约消耗10几M内存),因此重写一篇使用filebeat收集kubernetes中的应用日志。
在进行日志收集的过程中,我们首先想到的是使用Logstash,因为它是ELK stack中的重要成员,但是在测试过程中发现,Logstash是基于JDK的,在没有产生日志的情况单纯启动Logstash就大概要消耗 500M内存,在每个Pod中都启动一个日志收集组件的情况下,使用logstash有点浪费系统资源,经人推荐我们选择使用 Filebeat替代,经测试单独启动Filebeat容器大约会消耗 12M内存,比起logstash相当轻量级。
Kubernetes官方提供了EFK的日志收集解决方案,但是这种方案并不适合所有的业务场景,它本身就有一些局限性,例如:
基于以上几个原因,我们决定使用自己的ELK集群。
Kubernetes集群中的日志收集解决方案
| 编号 | 方案 | 优点 | 缺点 |
|---|---|---|---|
| 1 | 每个app的镜像中都集成日志收集组件 | 部署方便,kubernetes的yaml文件无须特别配置,可以为每个app自定义日志收集配置 | 强耦合,不方便应用和日志收集组件升级和维护且会导致镜像过大 |
| 2 | 单独创建一个日志收集组件跟app的容器一起运行在同一个pod中 | 低耦合,扩展性强,方便维护和升级 | 需要对kubernetes的yaml文件进行单独配置,略显繁琐 |
| 3 | 将所有的Pod的日志都挂载到宿主机上,每台主机上单独起一个日志收集Pod | 完全解耦,性能最高,管理起来最方便 | 需要统一日志收集规则,目录和输出方式 |
综合以上优缺点,我们选择使用方案二。
该方案在扩展性、个性化、部署和后期维护方面都能做到均衡,因此选择该方案。
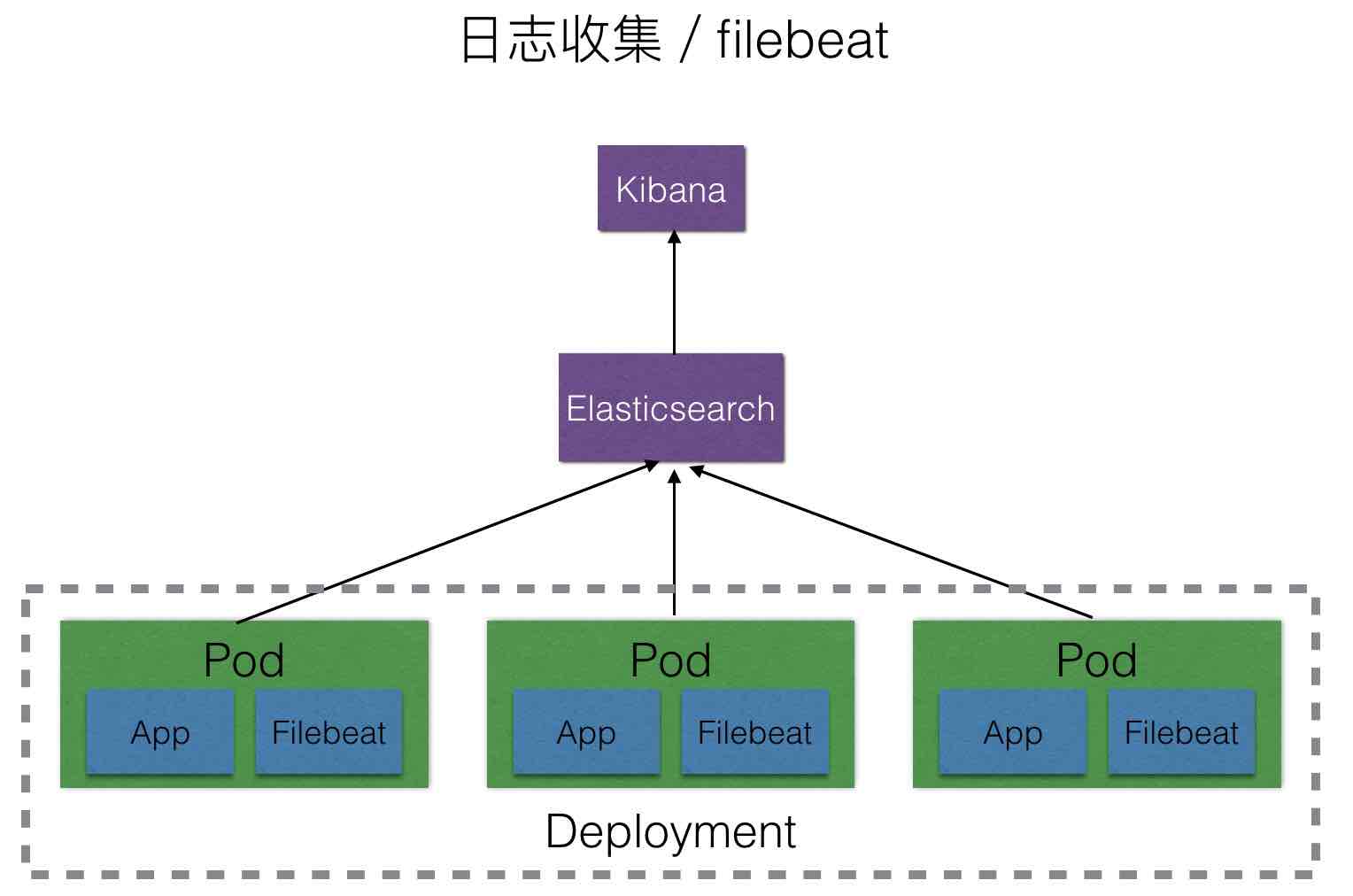
我们创建了自己的logstash镜像。创建过程和使用方式见 https://github.com/rootsongjc/docker-images
镜像地址: index.tenxcloud.com/jimmy/filebeat:5.4.0
我们部署一个应用对logstash的日志收集功能进行测试。
创建应用yaml文件 fielbeat-test.yaml。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: filebeat-test
namespace: default
spec:
replicas: 3
template:
metadata:
labels:
k8s-app: filebeat-test
spec:
containers:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/filebeat:5.4.0
name: filebeat
volumeMounts:
- name: app-logs
mountPath: /log
- name: filebeat-config
mountPath: /etc/filebeat/
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/analytics-docker-test:Build_8
name : app
ports:
- containerPort: 80
volumeMounts:
- name: app-logs
mountPath: /usr/local/TalkingData/logs
volumes:
- name: app-logs
emptyDir: {}
- name: filebeat-config
configMap:
name: filebeat-config
---
apiVersion: v1
kind: Service
metadata:
name: filebeat-test
labels:
app: filebeat-test
spec:
ports:
- port: 80
protocol: TCP
name: http
selector:
run: filebeat-test
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
data:
filebeat.yml: |
filebeat.prospectors:
- input_type: log
paths:
- "/log/*"
- "/log/usermange/common/*"
output.elasticsearch:
hosts: ["172.23.5.255:9200"]
username: "elastic"
password: "changeme"
index: "filebeat-docker-test" 注意事项
/usr/local/TalkingData/logs目录挂载到logstash的 /log目录下。manifests/test/filebeat-test.yaml找到。创建应用
部署Deployment
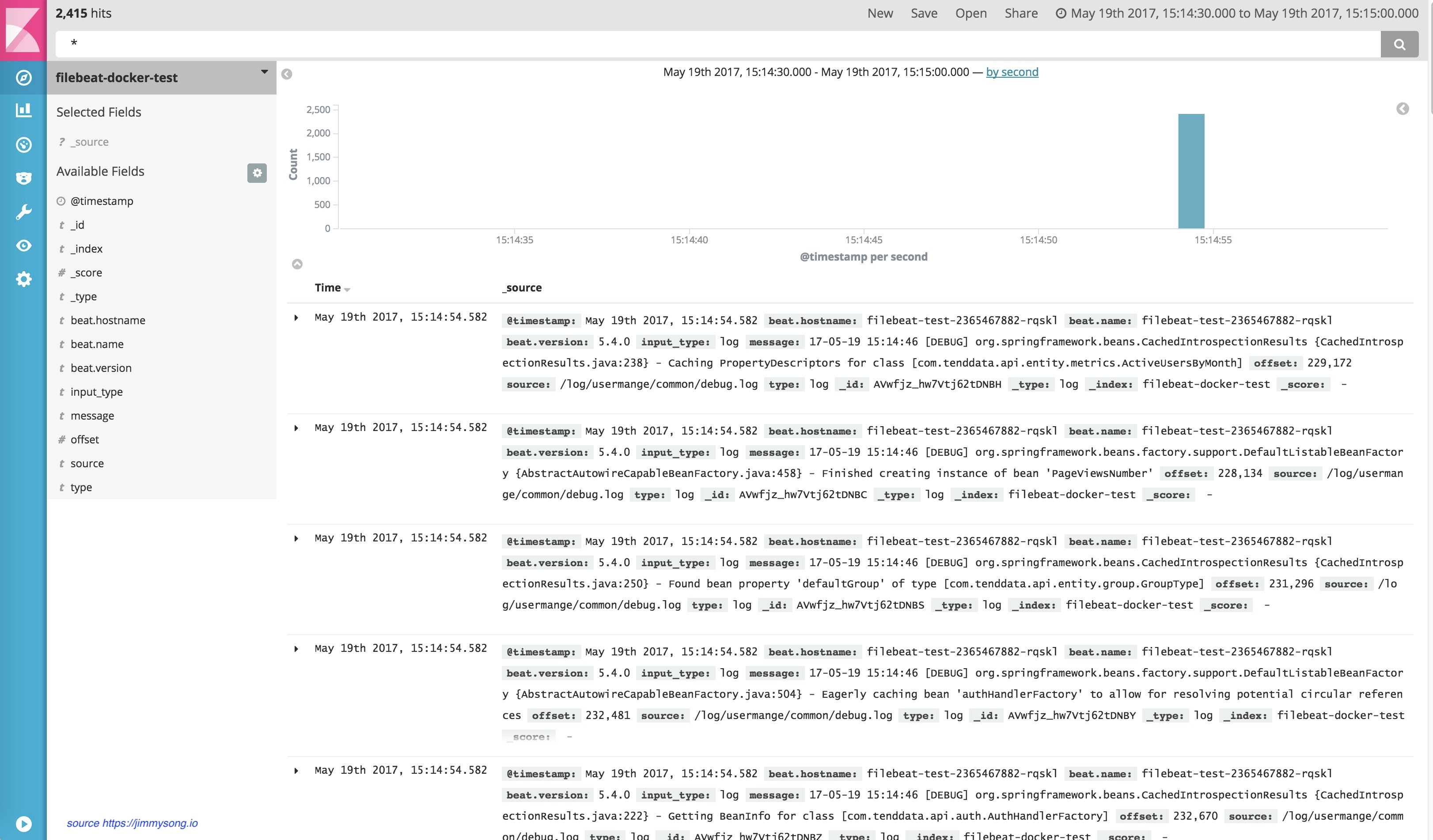
kubectl create -f filebeat-test.yaml 查看 http://172.23.5.255:9200/_cat/indices将可以看到列表有这样的indices:
green open filebeat-docker-test 7xPEwEbUQRirk8oDX36gAA 5 1 2151 0 1.6mb 841.8kb 访问Kibana的web页面,查看 filebeat-docker-test的索引,可以看到filebeat收集到了app日志。
「真诚赞赏,手留余香」