[个推 CTO 谈数据智能] 之本质及技术体系要求
- - DiyCode - 致力于构建开发工程师高端交流分享社区社区毕业于浙江大学,现全面负责个推技术选型、研发创新、运维管理等工作,已带领团队开发出针对移动互联网、金融风控等行业的多项前沿数据智能解决方案. 曾任MSN中国首席架构师,拥有十余年资深技术开发与项目管理经验,在大数据处理系统、大规模并发平台、分布搜索系统、手机应用开发、无线通信领域和智慧金融系统等领域拥有丰富实践经验.
“最近看到一句话:“架构设计的关键思维是判断和取舍,程序设计的关键思维是逻辑和实现”,深以为然!
文 | 个推CTO Anson
引言
前文回顾:《数据智能时代来临:本质及技术体系要求》作为本系列的第一篇文章,概括性地阐述了对于数据智能的理解以及推出了对应的核心技术体系要求:
数据智能就是以数据作为生产资料,通过结合大规模数据处理、数据挖掘、机器学习、人机交互、可视化等多种技术,从大量的数据中提炼、发掘、获取知识,为人们在基于数据制定决策时提供有效的智能支持,减少或者消除不确定性。
从对数据智能的定义来看,数据智能的技术体系至少需要包含几个方面,见下图所示:
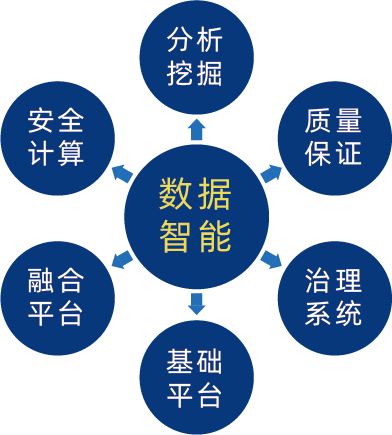
▲数据智能技术体系构成
其中数据资产治理、数据质量保证、数据智能下的安全计算体系会在后续的系列文章中重点阐述。
然而最近在实际工作中,发现大家对于如何处理多维数据进行分析以解决实际业务问题方面存在一些实实在在的困扰,特别是对于选择什么样的底层系统无所适从,毕竟有资源给大家进行试验的公司并不是太多。
故此我和团队一起研究,同时也借鉴了外部的一些资料,针对这个议题撰写了本系列的第二篇文章,主要围绕“多维度分析系统的选型方法”的主题,供大家参考,希望能缩短大家的决策时间。
正文内容
分析系统的考量要素
CAP 理论大家都已经比较熟悉, C.A.P 之间无法兼得,只能有所取舍。在分析系统中同样需要在三个要素间进行取舍和平衡,三要素分别是数据量、灵活性以及性能。
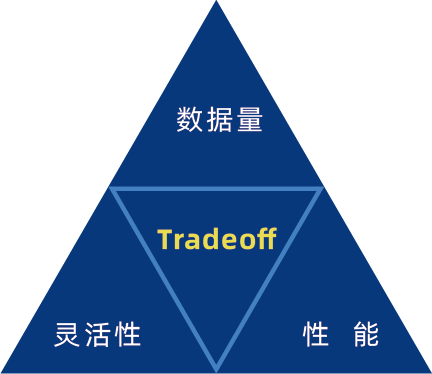
▲分析系统考量三要素
有的系统在数据量达到一定数量,譬如超过P级别后,在资源不变情况下,就无法满足处理要求了,哪怕是一个简单的分析需求。
灵活性主要指操作数据时的方式是否灵活,比如对于一般的分析师而言,使用SQL来操作是首选,没有太多的约束,如果使用特定领域的语言 (DSL) 相对就比较受限;另外一个意思是操作是否受预先条件的限制,譬如是否支持在多个维度下进行灵活的即席(Ad-Hoc)查询;最后一个就是性能要求,是否满足多并发操作、能否在秒级进行响应。
数据查询的过程分析
对数据进行聚合类型的查询时,一般按照以下三个步骤进行:

▲实时查询过程
首先,需要用索引检索出数据所对应的行号或者索引位置,要求能够从上亿条数据中快速过滤出几十万或几百万的数据。这方面是搜索引擎最擅长的领域,因为一般关系型数据库擅长用索引检索出比较精确的少量数据。
然后从主存储按行号或者位置进行具体数据的加载,要求能够快速加载这过滤出的几十上百万条数据到内存里。这方面是分析型数据库最擅长的领域,因为一般它们采用列式存储,有的还会采用mmap的方式来加快数据的处理。
最后进行分布式计算,能够把这些数据按照GROUP BY和SELECT的要求计算出最终的结果集。而这是大数据计算引擎最擅长的领域,如Spark、Hadoop等。
架构的比较和分析
结合以上两方面的要素,在架构方面目前主要是三类:
MPP (Massively Parallel Processing)
基于搜索引擎的架构
预计算系统架构
MPP架构
传统的RDBMS在ACID方面具有绝对的优势。在大数据时代中,如果你的数据大部分依然还是结构化的数据,并且数据并不是如此巨大的话,不一定非要采用类似Hadoop这样的平台,自然也可以采用分布式的架构来满足数据规模的增长,并且去解决数据分析的需求,同时还可以用我们熟悉的SQL来进行操作。
这个架构就是MPP(Massively Parallel Processing)–大规模并行处理。
当然实际上MPP只是一个架构,其底层未必一定是RDBMS, 而可以是架设在Hadoop底层设施并且加上分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine等组成),不使用MapReduce这样的批处理方式。
这个架构下的系统有:Greenplum、Impala、Drill、Shark等,其中Greenplum (一般简称GP) 使用PostgreSQL作为底层数据库引擎。
基于搜索引擎的架构
相对比MPP系统,搜索引擎在进行数据(文档)入库时将数据转换为倒排索引,使用Term Index、Term Dictionary、Posting 三级结构建立索引,同时采用一些压缩技术来进行空间的节省。
这些数据(文档)会通过一定的规则(譬如对文档ID进行哈希算法)分散到各个节点上。在进行数据检索的时候,采用Scatter-Gather计算模型,在各个节点上分别进行处理后,集中到发起搜索的节点进行最终聚合。
这个架构下的系统主要有:ElasticSearch、Solr,一般采用DSL进行操作。
预计算系统架构
类似Apache Kylin这样的系统就是预计算系统架构。其在数据入库时对数据进行预聚合,通过事先建立一定的模型,对数据进行预先的处理,形成“物化视图”或者数据Cube,这样对于数据的大部分处理实际是在查询阶段之前就完成了,查询阶段相当于进行二次加工。
这个架构下的系统主要有: Kylin,Druid。虽然Kylin和Druid都属于预计算系统架构,两者之间还是有不少差别。
Kylin是使用Cube的方式来进行预计算(支持SQL方式),一旦模型确定,要去修改的成本会比较大,基本上需要重新计算整个Cube,而且预计算不是随时进行,是按照一定策略进行,这个也限制了其作为实时数据查询的要求。
而Druid 更加适合做实时计算、即席查询(目前还不支持SQL),它采用Bitmap作为主要索引方式,因此可以很快地进行数据的筛选及处理,但是对于复杂的查询来说, 性能上比Kylin要差。
基于上面的分析,Kylin一般主推超大数据量下的离线的OLAP引擎,Druid是主推的大数据量下的实时OLAP引擎。
三种架构的对比
MPP架构的系统:
有很好的数据量和灵活性支持,但是对响应时间是没有必然保证的。当数据量和计算复杂度增加后,响应时间会变慢,从秒级到分钟级,甚至小时级都有可能。
搜索引擎架构的系统:
相对比MPP系统,牺牲了一些灵活性换取很好的性能,在搜索类查询上能做到亚秒级响应。但是对于扫描聚合为主的查询,随着处理数据量的增加,响应时间也会退化到分钟级。
预计算系统:
在入库时对数据进行预聚合,进一步牺牲灵活性换取性能,以实现对超大数据集的秒级响应。
结合上面的分析,以上三种分别是:
对于数据量的支持从小到大
灵活性从大到小
性能随数据量变大从低到高
因此,我们可以基于实际业务数据量的大小、对于灵活性和性能的要求综合来进行考虑。譬如采用GP可能就能满足大部分公司的需要,采用Kylin可以满足超大数据量的需求等。
结语
最近看到一句话:“架构设计的关键思维是判断和取舍,程序设计的关键思维是逻辑和实现”,深以为然!
未来,我们个推技术团队也将不断探索多维度分析系统的选型方法,与大家共同探讨,一如既往地为各位开发者提供更优质的服务。
更多内容请关注:个推技术学院
