关于数据库连接池大小 · brettwooldridge/HikariCP Wiki · GitHub
- -Brett Wooldridge编辑了此页面 on 8 Jan 2017 · 29个修订. 开发人员经常会错误地配置连接池. 在配置池时,需要理解一些原则,对于某些原则可能是违反直觉的. 10,000个同时前端用户. 想象一下,您有一个网站,尽管它可能不是Facebook规模,但仍然经常有10,000个用户同时发出数据库请求-每秒约有20,000个事务.
开发人员经常会错误地配置连接池。在配置池时,需要理解一些原则,对于某些原则可能是违反直觉的。
想象一下,您有一个网站,尽管它可能不是Facebook规模,但仍然经常有10,000个用户同时发出数据库请求-每秒约有20,000个事务。您的连接池应该有多大?您可能会惊讶,问题不是 多大,而是 多小!
观看Oracle真实世界性能小组的这段简短视频,以进行令人大开眼界的演示(约10分钟):

{Spoiler Alert},如果您没有观看视频。哦,加油!观看,然后回到这里。
您可以从视频中看到,在不进行任何其他更改的情况下,仅减小连接池大小就可以将应用程序的响应时间从约100ms减少到约2ms-改进了50倍以上。
我们似乎最近在计算的其他部分已经了解到,少即是多。为什么只有4个线程的 Nginx Web服务器可以大大 胜过具有100个进程的 Apache Web服务器?如果回想一下计算机科学101,这不是很明显吗?
即使是只有一个CPU内核的计算机也可以“同时”支持数十个或数百个线程。但是我们所有人[应该]都知道,这只是 时间片的神奇之处,而不仅仅是操作系统的一个把戏。实际上,那个单核一次只能执行 一个线程。然后OS切换上下文,该内核执行另一个线程的代码,依此类推。计算的基本定律是,给定单个CPU资源,按时间顺序执行A和B 总是比“同时” 执行A和B更快。一旦线程数超过CPU内核数,添加更多线程就会变慢,而不是更快。
几乎是真的...
它不像上面说的那么简单,但是很接近。还有其他一些因素在起作用。当我们查看数据库的主要瓶颈时,它们可以概括为三个基本类别: CPU, Disk, Network。我们可以在其中添加 内存,但是与 磁盘和 网络相比,带宽存在几个数量级的差异。
如果我们忽略“ 磁盘和 网络”,那将很简单。在具有8个计算核心的服务器上,将连接数设置为8将提供最佳性能,并且由于上下文切换的开销,超出此限制的任何内容都将开始变慢。但是我们不能忽略 磁盘和 网络。数据库通常将数据存储在 磁盘上传统上由旋转的金属板组成,金属板带有安装在步进电机驱动臂上的读/写头。读/写头一次只能位于一个位置(一次查询的读/写数据),并且必须“搜寻”到新的位置才能为另一次查询读/写数据。因此,存在寻道时间成本以及旋转成本,由此磁盘必须等待数据在读/写盘上“再次出现”。缓存在这里当然有帮助,但是原理仍然适用。
在这段时间内(“ I / O等待”),连接/查询/线程仅被“阻塞”以等待磁盘。正是在这段时间内,OS可以通过为另一个线程执行更多代码来更好地利用CPU资源。因此,由于线程在I / O上被阻塞,因此通过使连接/线程的数量大于物理计算内核的数量,我们实际上可以完成更多的工作。
还有多少?我们将会看到。还有多少个问题也取决于 磁盘子系统,因为较新的SSD驱动器没有“寻找时间”的成本或需要处理的旋转因素。不要被欺骗,“ SSD 更快,因此我可以拥有 更多线程”。那就是向后180度。更快,没有寻道,没有旋转延迟意味着 更少的阻塞,因此 更少的线程(更接近内核数)将比更多的线程有更好的性能。 只有在阻塞为执行创造机会时,更多的线程才能更好地执行。
网络类似于 磁盘。当发送/接收缓冲区填满并停顿时,通过以太网接口通过有线方式写数据也会引入阻塞。10千兆位接口的停滞速度将小于千兆以太网,而千兆以太网将停滞于100兆位以下。但是就资源阻塞而言,网络排名第三。有些人经常从计算中忽略它。
这是另一个打破文本墙的图表。
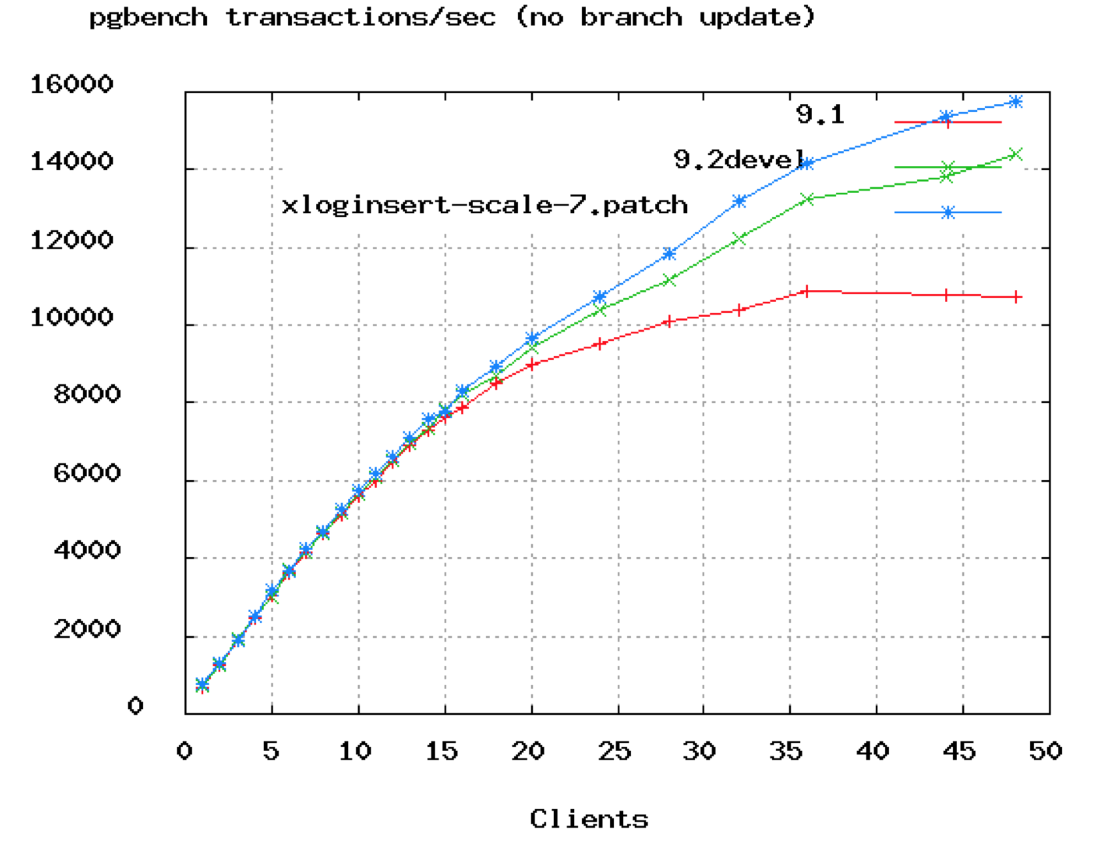
您可以在上述PostgreSQL基准测试中看到,TPS速率在大约50个连接处开始趋于平稳。在上面的Oracle视频中,他们显示连接从2048个下降到96个。我们可以说,即使96个也可能太高了,除非您使用的是16或32核处理器。
PostgreSQL项目提供了以下公式作为起点,但是我们认为该公式将在很大程度上适用于数据库。您应该测试您的应用程序,即模拟预期的负载,并 在此起点 附近尝试不同的池设置:
A formula which has held up pretty well across a lot of benchmarks for years is
that for optimal throughput the number of active connections should be somewhere
near ((core_count * 2) + effective_spindle_count). Core count should not include
HT threads, even if hyperthreading is enabled. Effective spindle count is zero if
the active data set is fully cached, and approaches the actual number of spindles
as the cache hit rate falls. ... There hasn't been any analysis so far regarding
how well the formula works with SSDs.
猜猜那是什么意思?您的带有一个硬盘的4核i7小型服务器应该正在运行以下连接池: 9 = ((4 * 2) + 1)。将其 10称为一个不错的整数。看起来低吗?试试看,我们打赌您可以轻松地处理3000个前端用户,在这种设置下以6000 TPS的速度运行简单查询。如果运行负载测试,则可能会发现,随着您将连接池推到更远的位置 10(在给定的硬件上),TPS速率开始下降,前端响应时间开始攀升。
如果您有10,000个前端用户,那么拥有10,000个连接池将使您精神错乱。1000仍然很恐怖。甚至有100个连接,过度杀伤力。您需要一个最多只有几十个连接的小型池,并且希望池中等待连接的其余应用程序线程被阻塞。如果对池进行了适当的调整,则将其设置为数据库能够同时处理的查询数量的极限,这几乎不超过如上所述的(CPU内核* 2)。
我们永远不会停止对我们遇到的内部Web应用程序的惊奇,几十个前端用户执行定期活动,并且连接池包含100个连接。不要过度配置数据库。
对于获得许多联系的单个演员,“池锁定”的前景有所提高。这在很大程度上是应用程序级的问题。是的,增加池的大小可以减轻这些情况下的锁定,但是我们敦促您在扩大池之前先检查一下在应用程序级别可以执行的操作。
为了避免死锁,计算池大小是一个相当简单的资源分配公式:
池大小= T n x(C m -1)+ 1
其中 T n是最大线程数,而 C m是单个线程 同时保持的最大 连接数。
例如,设想三个线程( T n = 3),每个线程都需要四个连接来执行某些任务( C m = 4)。确保永远不会发生死锁所需的池大小为:
池大小= 3 x(4-1)+ 1 = 10
另一个示例,您最多有八个线程( T n = 8),每个线程需要三个连接才能执行某些任务( C m = 3)。确保永远不会发生死锁所需的池大小为:
池大小= 8 x(3-1)+ 1 = 17
👉这不一定是 最佳的池大小,但 最低要求,以避免死锁。
some在某些环境中,使用JTA(Java事务管理器)可以通过将相同的Connection从返回 getConnection()到当前事务中已经拥有Connection的线程中来,大大减少所需的连接数。
池大小调整最终非常特定于部署。
例如,混合了长时间运行的事务和非常短的事务的系统通常是最难于使用任何连接池进行调整的系统。在那种情况下,创建两个池实例可以很好地工作(例如,一个用于长时间运行的作业,另一个用于“实时”查询)。
在主要运行长时间事务的系统中,通常对所需连接数存在“外部”限制-例如作业执行队列仅允许一定数量的作业一次运行。在这些情况下,作业队列大小应为“正确大小”以匹配池(而不是相反)。