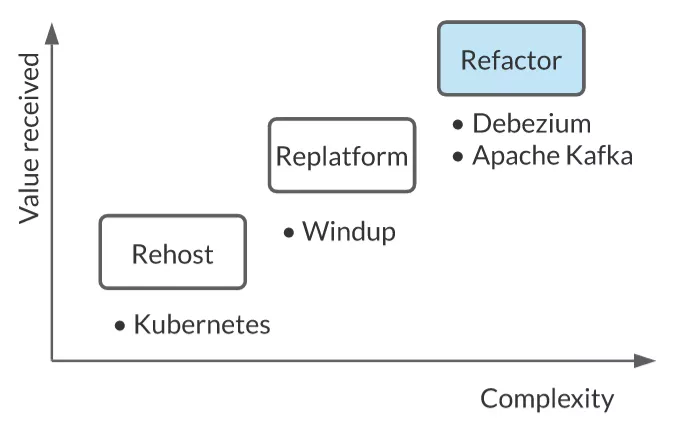
使用 Kafka、Debezium 和 Kubernetes 实现应用现代化的模式
- - InfoQ - 促进软件开发领域知识与创新的传播本文最初发表于 RedHat 的开发者站点,经原作者 Bilgin Ibryam 许可,由 InfoQ 中文站翻译分享. “我们建造计算机的方式与建造城市的方式是一样的,那就是随着时间的推移,依然毫无计划,并且要建造在废墟之上. Ellen Ullman 在 1998 年写下了这样一句话,但它今天依然适用于我们构建现代应用程序的方式,那就是,随着时间的推移,我们要在遗留的软件上构建应用,而且仅仅有短期的计划.