比较PageRank算法和HITS算法的优缺点
- - 互联网旁观者1998年,Sergey Brin和Lawrence
Page[1]提出了PageRank算法. 该算法基于“从许多优质的网页链接过来的网页,必定还是优质网页”的回归关系,来判定网页的重要性. 该算法认为从网页A导向网页B的链接可以看作是页面A对页面B的支持投票,根据这个投票数来判断页面的重要性. 当然,不仅仅只看投票数,还要对投票的页面进行重要性分析,越是重要的页面所投票的评价也就越高.
top_hits指标聚合器跟踪要聚合的最相关文档。 该聚合器旨在用作子聚合器,以便可以按存储分区汇总最匹配的文档。
top_hits聚合器可以有效地用于通过存储桶聚合器按某些字段对结果集进行分组。 一个或多个存储桶聚合器确定将结果集切成哪些属性。
选项:
我们还是来用一个例子来展示如何使用这个:
我们选用Kibana里带的官方的Sample web logs来作为我们的索引:
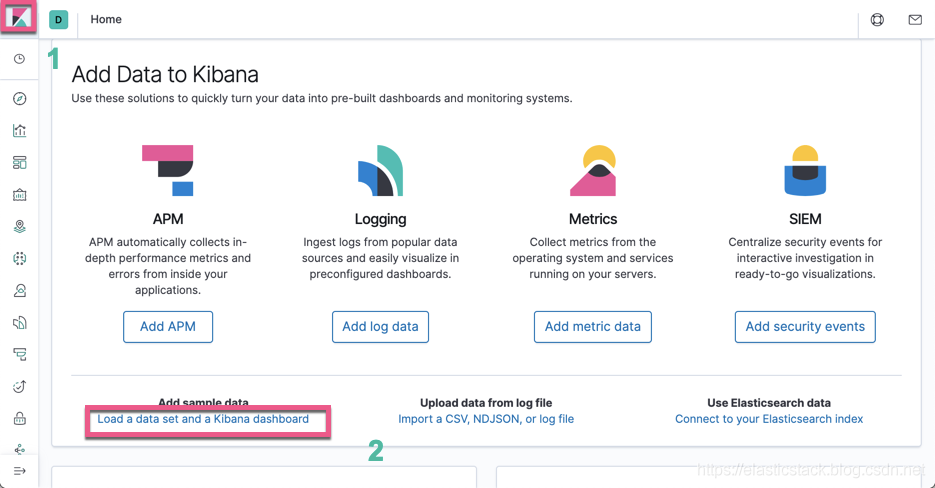
然后加载我们的索引:
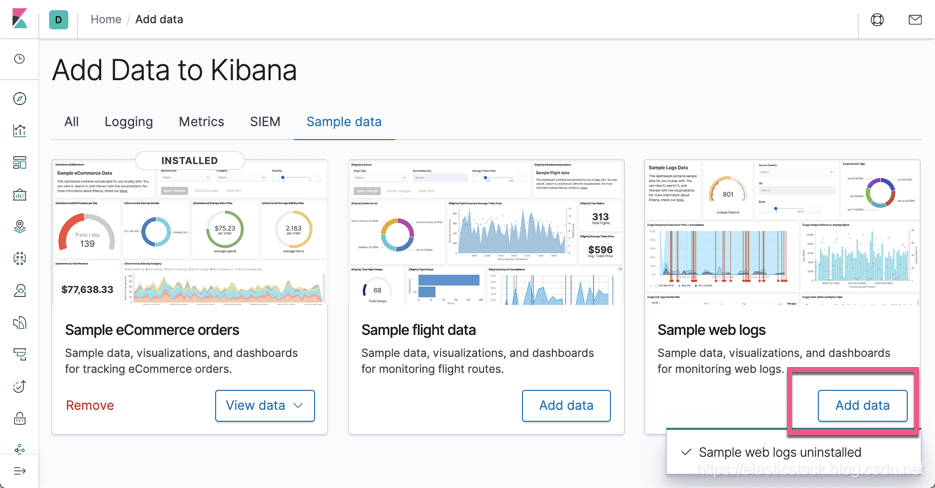
这样我们的数据就加载完成了。
首先,我们先做一个简单的基于hosts的aggregation:
GET kibana_sample_data_logs/_search
{
"size": 0,
"aggs": {
"hosts": {
"terms": {
"field": "host.keyword",
"size": 2
}
}
}
} 上面的搜索的结果是我们想得到2个桶的数据(这里为了说明问题的方便,设定为2)。而这两个桶是基于hosts的值。搜索的结果是:
"aggregations" : {
"hosts" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 2807,
"buckets" : [
{
"key" : "artifacts.elastic.co",
"doc_count" : 6488
},
{
"key" : "www.elastic.co",
"doc_count" : 4779
}
]
}
} 现在的要求是:我们想针对这里的每个桶得到按照我们需要排序的前面的几个结果,比如下面的搜索:
GET kibana_sample_data_logs/_search
{
"size": 0,
"aggs": {
"hosts": {
"terms": {
"field": "host.keyword",
"size": 2
},
"aggs": {
"most_bytes": {
"top_hits": {
"sort": [
{
"bytes": {
"order": "desc"
}
}
],
"_source": {
"includes": [
"bytes",
"hosts",
"ip",
"clientip"
]
},
"size": 2
}
}
}
}
}
} 上面实际上市一个pipleline的聚合。它在针对上面的桶来做了一个top_hits的聚合。针对每个桶,我们需要安装bytes的大小,降序排列,并且每个桶只需要两个数据:
"aggregations" : {
"hosts" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 2807,
"buckets" : [
{
"key" : "artifacts.elastic.co",
"doc_count" : 6488,
"most_bytes" : {
"hits" : {
"total" : {
"value" : 6488,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "kibana_sample_data_logs",
"_type" : "_doc",
"_id" : "dnNIHm8BjrINWI3xXlRc",
"_score" : null,
"_source" : {
"bytes" : 19929,
"ip" : "127.155.255.9",
"clientip" : "127.155.255.9"
},
"sort" : [
19929
]
},
{
"_index" : "kibana_sample_data_logs",
"_type" : "_doc",
"_id" : "OXNIHm8BjrINWI3xX1td",
"_score" : null,
"_source" : {
"bytes" : 19904,
"ip" : "100.177.58.231",
"clientip" : "100.177.58.231"
},
"sort" : [
19904
]
}
]
}
}
},
{
"key" : "www.elastic.co",
"doc_count" : 4779,
"most_bytes" : {
"hits" : {
"total" : {
"value" : 4779,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "kibana_sample_data_logs",
"_type" : "_doc",
"_id" : "4nNIHm8BjrINWI3xYWQl",
"_score" : null,
"_source" : {
"bytes" : 19986,
"ip" : "233.204.30.48",
"clientip" : "233.204.30.48"
},
"sort" : [
19986
]
},
{
"_index" : "kibana_sample_data_logs",
"_type" : "_doc",
"_id" : "wnNIHm8BjrINWI3xW0Rj",
"_score" : null,
"_source" : {
"bytes" : 19956,
"ip" : "129.237.102.30",
"clientip" : "129.237.102.30"
},
"sort" : [
19956
]
}
]
}
}
}
]
}
} 从上面的返回结果可以看出来两个hosts artifacts.elastic.co及www.elastic.co各返回两个结果,并且它们是按照bytes的大小进行降序排列的。
细心的读者可能会发现这个和我之前介绍的field collapsing有些类似。只是field collapsing里针对每个桶有一个结果,并且是按照我们的要求进行排序的最高结果的那个。当然我们也可以含有多几个返回结果在inner_hits之中。