在这里主要分析一下HFile V2的各个组成部分的一些细节,重点分析了HFile V2的多级索引的机制,接下去有时间的话会分析源码中对HFile的读写扫描操作。HFile和流程:
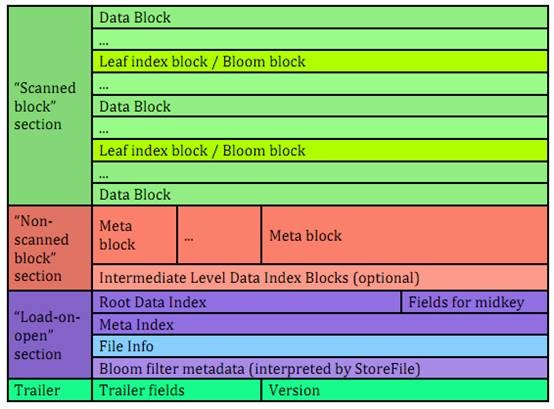
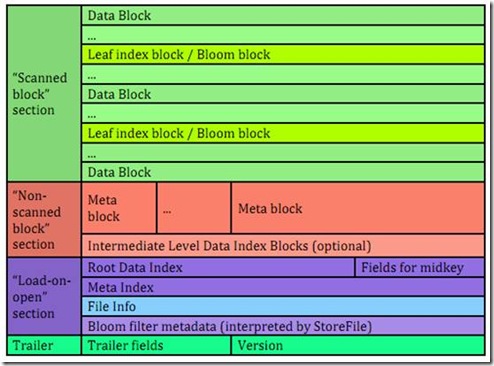
如下图,HFile的组成分成四部分,分别是Scanned Block(数据block)、Non-Scanned block(元数据block)、Load-on-open(在hbase运行时,HFile需要加载到内存中的索引、bloom filter和文件信息)以及trailer(文件尾)。
 在HFile 中根据一个key 搜索一个data 的过程
在HFile 中根据一个key 搜索一个data 的过程:
1、先内存中对HFile的root index进行二分查找。如果支持多级索引的话,则定位到的是leaf/intermediate index,如果是单级索引,则定位到的是data block
2、如果支持多级索引,则会从缓存/hdfs(分布式文件系统)中读取leaf/intermediate index chunk,在leaf/intermediate chunk根据key值进行二分查找(leaf/intermediate index chunk支持二分查找),找到对应的data block。
3、从缓存/hdfs中读取data block
4、在data block中遍历查找key。
接下去我们分析一个HFile的各个组成部分的详细细节,重点会分析一下HFile V2的多级索引。1 Hbase的KeyValue结构
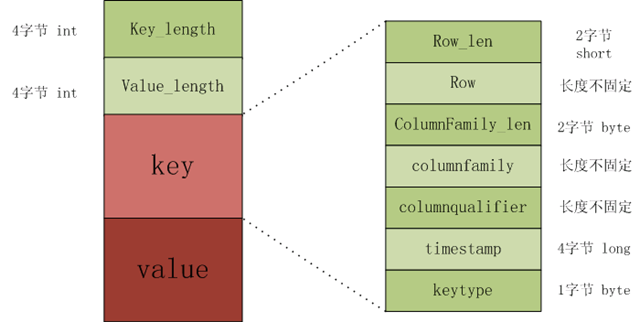
KeyValue结构是hbase存储的核心,每个数据都是以keyValue结构在hbase中进行存储。KeyValue结构是一个有固定格式的byte数组,其结构在内存和磁盘中的格式如下:
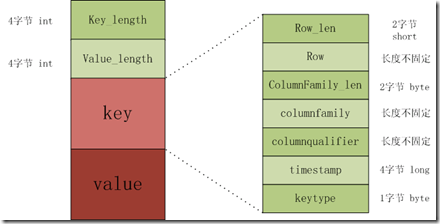
The KeyValue格式:
- Keylength
- valuelength
- key
- value
其中keylength和valuelength都是整型,表示长度。
而key和value都是byte数据,key是有固定的数据,而value是raw data。Key的格式如下。
The Key format:
- rowlength
- row (i.e., the rowkey)
- columnfamilylength
- columnfamily
- columnqualifier
- timestamp
- keytype
keytype有四种类型,分别是Put、Delete、 DeleteColumn和DeleteFamily。
特别说明:在key的所有组成成员中,columnquallfier的长度不固定,不需要用qualifier_len字段来标示其长度,因为可以通过key_len - ((key固定长度) + row_len + columnFamily_len)获得,其中Key固定长度为 sizeof(Row_len) + sizeof(columnFamily_len) + sizeof(timestamp) + sizeof(keytype)。KeyValue是字节流形式,所以不需要考虑字节对齐。2 File Trailer
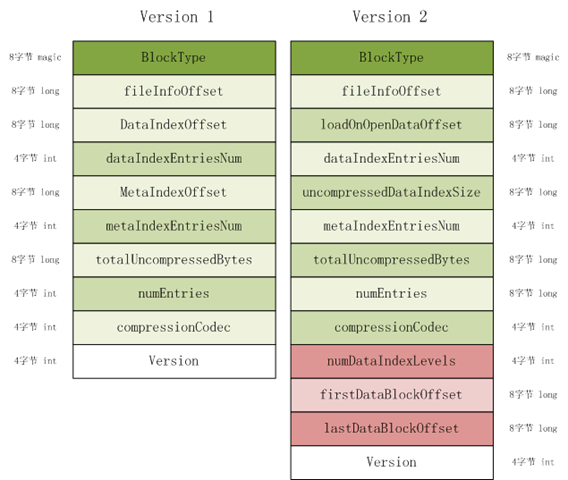
fixedFileTrailer记录了HFile的基本信息、各个部分的偏移值和寻址信息。fileTailer拥有固定的长度,下图是HFile V1和HFile V2的差别。在FileTrailer中存储着加载一个HFile的所有信息。FileTrailer在磁盘中的分布如下图所示:
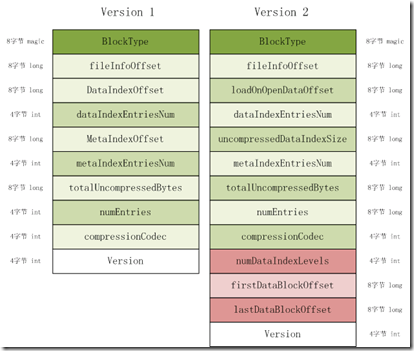
HFile V2见图右边。下面列举一下各个字段的含义和作用
BlockType:block类型。
FileInfoOffset:fileInfo的起始偏移地址。
LoadOnOpenDataOffset:需要被加载到内存中的Hfile部分的起始地址。
DataIndexEntriesNum:data index的root index chunk包含的index entry数目。
UncompressedDataIndexSize:所有的未经压缩的data index的大小 。
TmetaIndexEntriesNum:meta index entry的数目。
totalUncompressedBytes:key value对象未经压缩的总大小。
numEntries:key value对象的数目。
compressionCodec:编解码算法。
numDataIndexLeves:data block的index level。
firstDataBlockOffset:第一个data block的起始偏移地址。Scan操作的起始。
lastDataBlockOffset:最后一个data block的之后的第一个byte地址。记录scan的边界。
version:版本号。读取一个HFile的流程如下:
1、 首先读取文件尾的4字节Version信息(FileTrailer的version字段)。
2、 根据Version信息得到Trailer的长度(不同版本有不同的长度),然后根据trailer长度,加载FileTrailer。
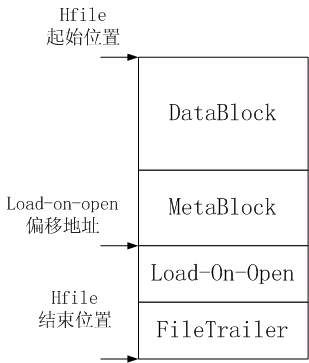
3、 加载load-on-open部分到内存中,起始的文件偏移地址是trailer中的loadOnOpenDataOffset,load-on-open部分长度等于(HFile文件长度 - HFileTrailer长度)
如下图所示:
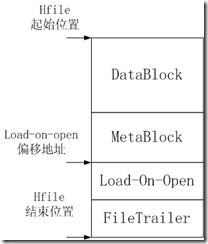
Load-on-open各个部分的加载顺序如下:
依次加载各部分的HFileBlock(load-on-open所有部分都是以HFileBlock格式存储):data index block、meta index block、FileInfo block、generate bloom filter index、和delete bloom filter。HFileBlock的格式会在下面介绍。3 Load on open
这部分数据在HBase的region server启动时,需要加载到内存中。包括FileInfo、Bloom filter block、data block index和meta block index。3.1 FileInfo
FileInfo中保存一些HFile的基本信息,并以PB格式写入到磁盘中。在0.96中是以PB格式进行保存。3.2 HFileBlock
在hfile中,所有的索引和数据都是以HFileBlock的格式存在在hdfs中,
HFile version2的Block格式如下两图所示,有两种类型,第一种类型是没有checksum;第二种是包含checksum。对于block,下图中的绿色和浅绿色的内存是block header;深红部分是block data;粉红部分是checksum。
第一种block的header长度= 8 + 2 * 4 + 8;
第二种block的header长度=8 + 2 * 4 + 8 + 1 + 4 * 2;
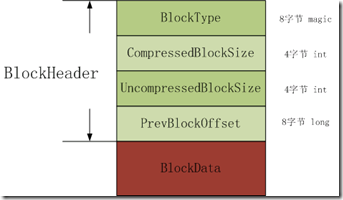
图3.1 不支持checksum的block
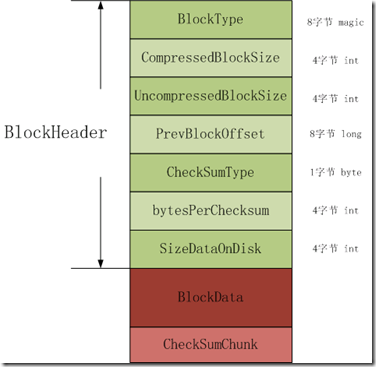
图 3.2 支持checksum的block
BlockType:8个字节的magic,表示不同的block 类型。
CompressedBlockSize:表示压缩的block 数据大小(也就是在HDFS中的HFileBlock数据长度),不包括header长度。
UncompressedBlockSize:表示未经压缩的block数据大小,不包括header长度。
PreBlockOffset:前一个block的在hfile中的偏移地址;用于访问前一个block而不用跳到前一个block中,实现类似于链表的功能。
CheckSumType:在支持block checksum中,表示checksum的类型。
bytePerCheckSum:在支持checksum的block中,记录了在checksumChunk中的字节数;records the number of bytes in a checksum chunk。
SizeDataOnDisk:在支持checksum的block中,记录了block在disk中的数据大小,不包括checksumChunk。DataBlock
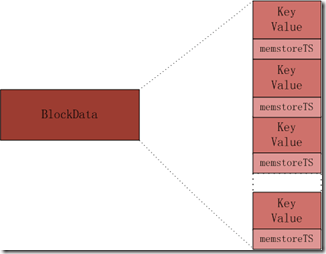
DataBlock是用于存储具体kv数据的block,相对于索引和meta(这里的meta是指bloom filter)DataBlock的格式比较简单。
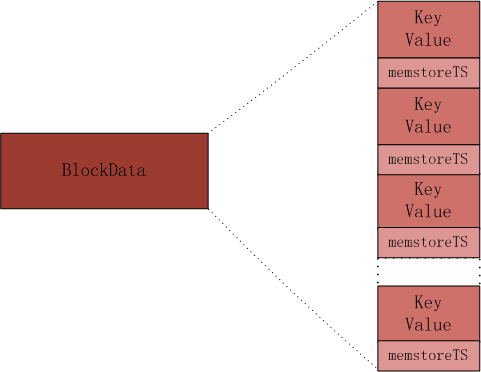
在DataBlock中,KeyValue的分布如下图,在KeyValue后面跟一个timestamp。
3.3 HFileIndex
HFile中的index level是不固定的,根据不同的数据类型和数据大小有不同的选择,主要有两类,一类是single-level(单级索引),另一类是multi-level(多级索引,索引block无法在内存中存放,所以采用多级索引)。
HFile中的index chunk有两大类,分别是root index chunk、nonRoot index chunk。而nonRoot index chunk又分为interMetadiate index chunk和leaf index chunk,但intermetadiate index chunk和leaf index chunk在内存中的分布是一样的。
对于meta block和bloom block,采用的索引是single-level形式,采用single-level时,只用root index chunk来保存指向block的索引信息(root_index-->xxx_block)。
而对于data,当HFile的data block数量较少时,采用的是single level(root_index-->data_block)。当data block数量较多时,采用的是multi-level,一般情况下是两级索引,使用root index chunk和leaf index chunk来保存索引信息(root_index-->leaf_index-->data_block);但当data block数量很多时,采用的是三级索引,使用root index chunk、intermetadiate index chunk和leaf index chunk来保存指向数据的索引(root_index-->intermediate_index-->leaf_index-->data_block)。
所有的index chunk都是以HFileBlock格式进行存放的,首先是一个HFileBlock Header,然后才是index chunk的内容。Root Index
Root index适用于两种情况:
1、作为data索引的根索引。
2、作为meta和bloom的索引。
在Hfile Version2中,Meta index和bloom index都是single-level,也都采用root索引的格式。Data index可以single-level和multi-level的这形式。Root index可以表示single-level index也可以表示multi-level的first level。但这两种表示方式在内存中的存储方式是由一定差别,见图3.3和3.4。
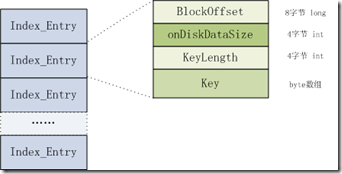
图3.3 single-level root index
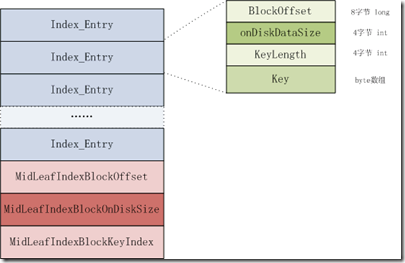
图3.4 multi-level root indexSingle-level
root索引是会被加载到内存中。在磁盘的格式见图3.4。
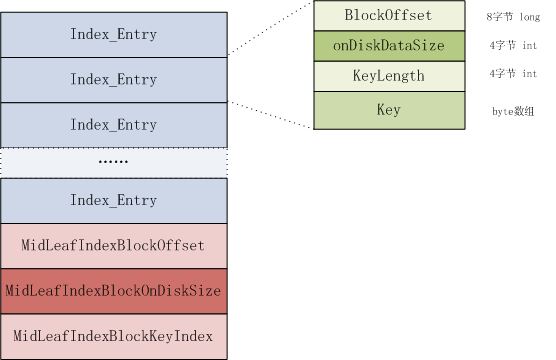
index entry的组成含义如下:
1、Offset (long):表示索引对应的block在Hfile文件中的偏移值。
2、On-disk size (int):表示索引对应的block在disk(Hfile文件)中的长度。
3、Key:Key是在内存中存储的byte array,分成两部分,其中一部分是key长度,另一部分是key数据。 Key值应该是index entry对应的data block的first row key。不论这个block是leaf index chunk还是data block或者是meta block。Mid-key and multi-level
对于multi-level root index,除了上面index entry数组之外还带有格外的数据mid-key的信息,这个mid-key是用于在对hfile进行split时,快速定位HFile的中间位置所使用。Multi-level root index在硬盘中的格式见图3.4。
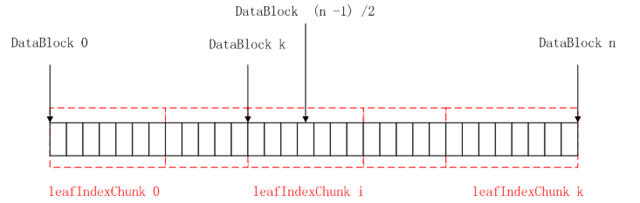
Mid-key的含义:如果HFile总共有n个data block,那么mid-key就是能定位到第(n - 1)/2个data block的信息。
Mid-key的信息组成如下:
1、Offset:所在的leaf index chunk的起始偏移量
2、On-disk size:所在的leaf index chunk的长度
3、Key:在leaf index chunk中的位置。
如下图所示:第(n – 1)/2个data block位于第i个LeafIndexChunk,如果LeafIndexChunk
的第一个data block的序号为k,那么offset、on-disk size以及key的值如下:
Offset为 LeafIndexChunk[i] 的offset
On-disk size为LeafIndexChunk[i] 的size
Key为(n – 1)/2 – k
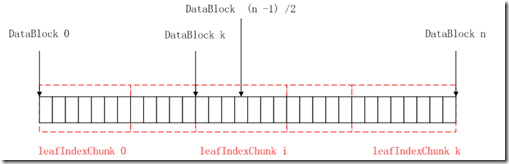
图 3.6 mid-key示意图NonRoot index
当HFile以multi-level来索引数据block时,会引入nonRoot index与root index一起构建整个索引。Nonroot索引包括Intermediate index和leaf index这两种类型,这两种索引在disk中的格式一致,都统一使用NonRoot格式进行存放,但用途和存放的位置不同。
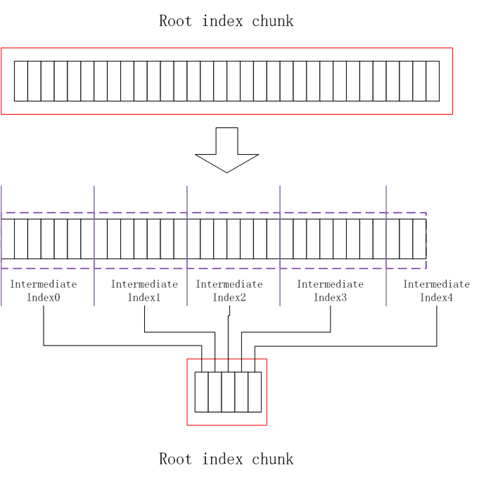
Intermediate index是在当HFile的数据block太多或内存存在限制时,使用两级数据索引时导致root index chunk超过其最大值,所以通过增加索引的级数,将intermediate index作为second level,以此来保证root index chunk的大小在一定限制内,减少加载到内存中时的内存消耗。
intermediate index chunk中的每个index Entry都指向一个leaf index chunk。Intermediate index chunk在加载时不会被加载到内存中。Intermediate index chunk在HFile中存储的位置是紧挨着root index chunk。在写入root index chunk时,会检查root index chunk的容量是否超过最大值,如果超过,那么将root index chunk划分成多个intermediate index chunk,然后重新生成一个root index entry,新root index entry中的每一个index entry都是指向intermediate index chunk。先将各个intermediate index chunk写入到disk中,然后再写入root index chunk,如下图所示。
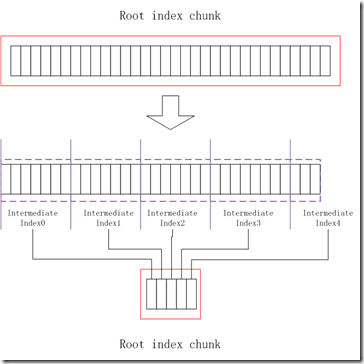
HFile使用multi-level index来索引data block时,Leaf index chunk是作为最末一级,leaf index chunk中的index entry是保存指向datablock的数据。Leaf index chunk也是以nonRoot格式来进行存储的,见图3.4,与intermediate index chunk一样,都样不会在加载hfile时被加载到内存中。
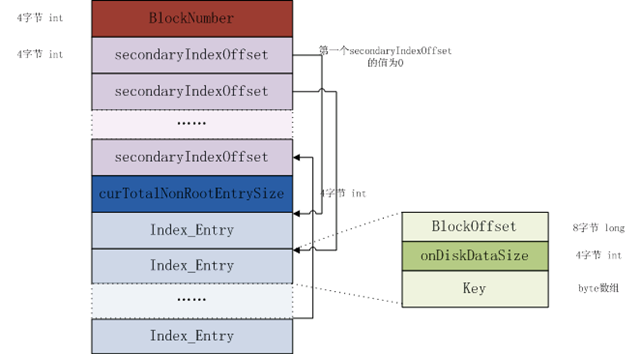
nonRoot索引增加了secondIndexOffset,作为二级索引,用于实现二分查找;而而nonRoot索引不会加载到内存中。增加nonRoot索引的目的就是解决在存储数据过大时导致索引的数量量也增加,无法加载到内存中,从而增加了seek和read时的开销。NonRoot index在磁盘中的格式如下图:
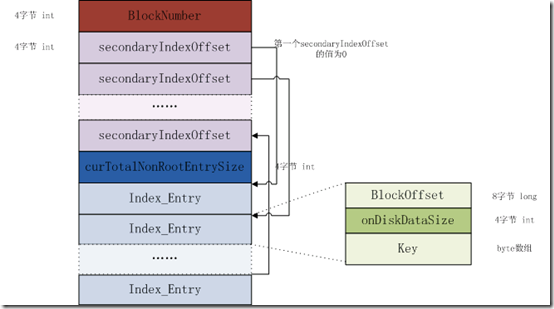
图 non Root index
1、BlockNumber:索引条目的数目。
2、secondaryIndexOffset:每一个secondaryIndexOffset都是表示index entry在leaf索引block中的相对偏移值(相对于第一个index entry),它是作为index entry的二级索引,用于实现快速搜索(二分法查找)。如下图所示,第一个secondaryIndexOffset的偏移值为0,往后都是index entry在disk中的长度相加。
3、curTotalNonRootEntrySize:leaf索引块中所有index entry在disk中总的大小。
4、Index Entries:每一个条目都包含三个部分
Offset:entry引用的block在文件中的偏移地址
On-disk size:block在硬盘中的大小
Key:block中的first row key. key不需要像在root索引中按照key length和keyvalue进行保存,因为有secondaryIndexOffset的存在,已经不需要通过key length来识别各个index entry的边界。NonRoot索引的二分查找实现
1、首先NonRoot索引中的Index_entry需要按照顺序排列,这个顺序是通过key值的大小来决定的。key值应该就是row的key值。
2、使用secondaryIndexOffset实现二分查找。 二分查找的原理
如果要查找一个InputKey所处的位置
首先将位置初始化,row为0,high为BlockNumber - 1
循环:
mid= (low + high) / 2
定位到中间位置的index Entry
将index Entry的key值与InputKey进行比较
如果 key > inputKey
Row = mid + 1
如果 key == inputKey
找到正确对象,返回
如果 key < inputKey
High = mid – 1 快速定位

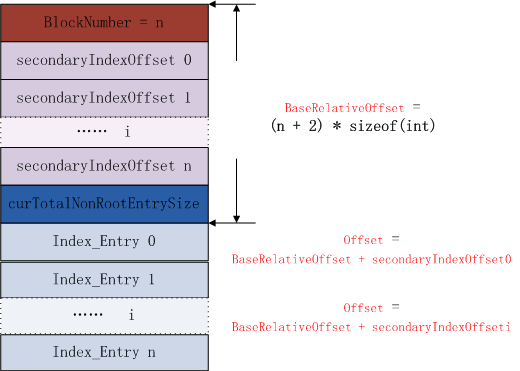
3.9 indexEntry偏移值计算
每一个secondaryIndexOffset是四个字节,secondaryIndexOffset的值是index Entry的相对偏移。见上图,对于一个序号为i的index entry,其在leaf索引chunk中的绝对偏移值为
“( BlockNumber + 2 ) * sizeof( int ) + secondaryIndexOffset[i]”

图 3.10 key值相对于index Entry的偏移
见上图,那么key的长度等于indexEntryOffset[i + 1] - (indexEntryOffset[i] + 4 * 8)Bloom filter
在HFile中,bloom filter的meta index也是作为load-on-open的一部分保存,bloom fiter有两种类型,一种是generate bloom filter,用于快速确定key是否存储在hbase中;另一种是delete bloom filter,用于快速确定key是否已经被删除。
Bloom filter meta index在硬盘中的格式如下:

Bloom meta index在磁盘中的格式如上图所示。
Version:表示版本;
totalByteSize:表示bloom filter的位组的bit数。
HashCount:表示一个key在位组中用几个bit位来进行定位。
HashType:表示hash函数的类型。
totalKeyCount:表示bloom filter当前已经包含的key的数目.
totalKeyMaxs:表示bloom filter当前最多包含的key的数目.
numChunks:表示bloom filter中包含的bloom filter block的数目.
comparatorName:表示比较器的名字.
接下去是每一个Bloom filter block的索引条目。[/i][/i][/i][/i]