


忘掉 Snowflake,感受一下性能高出 587 倍的全局唯一 ID 生成算法
- - SegmentFault 最新的文章今天我们来拆解 Snowflake 算法,同时领略百度、美团、腾讯等大厂在全局唯一 ID 服务方面做的设计,接着根据具体需求设计一款全新的全局唯一 ID 生成算法. 这还不够,我们会讨论到全局唯一 ID 服务的分布式 CAP 选择与性能瓶颈. 已经熟悉 Snowflake 的朋友可以先去看大厂的设计和权衡.
今天我们来拆解 Snowflake 算法,同时领略百度、美团、腾讯等大厂在全局唯一 ID 服务方面做的设计,接着根据具体需求设计一款全新的全局唯一 ID 生成算法。这还不够,我们会讨论到全局唯一 ID 服务的分布式 CAP 选择与性能瓶颈。
已经熟悉 Snowflake 的朋友可以先去看大厂的设计和权衡。
百度 UIDGenertor: https://github.com/baidu/uid-...
美团 Leaf: https://tech.meituan.com/2017...
腾讯 Seqsvr: https://www.infoq.cn/article/...
全局唯一 ID 是分布式系统和订单类业务系统中重要的基础设施。这里引用美团的描述:
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一 ID 做标识。
这时候你可能会问: 我还是不懂,为什么一定要全局唯一 ID?
我再列举一个场景,在 MySQL 分库分表的条件下,MySQL 无法做到依次、顺序、交替地生成 ID,这时候要保证数据的顺序,全局唯一 ID 就是一个很好的选择。
在爬虫场景中,这条数据在进入数据库之前会进行数据清洗、校验、矫正、分析等多个流程,这期间有一定概率发生重试或设为异常等操作,也就是说在进入数据库之前它就需要有一个 ID 来标识它。
美团技术团队列出的 4 点属性我觉得很准确,它们是:
看上去第 3 点和第 4 点似乎还存在些许冲突,这个后面再说。除了以上列举的 ID 属性外,基于这个生成算法构建的服务还需要买足高 QPS、高可用性和低延迟的几个要求。
大家在念书的时候肯定都学过 UUID 和 GUID,它们生成的值看上去像这样:
6F9619FF-8B86-D011-B42D-00C04FC964FF
由于不是纯数字组成,这就无法满足趋势递增和单调递增这两个属性,同时在写入时也会降低写入性能。上面提到了 数据库自增 ID 无法满足入库前使用和分布式场景下的需求,遂排除。
有人提出了借助 Redis 来实现,例如订单号=日期+当日自增长号,自增长通过 INCR 实现。但这样操作的话又无法满足编号不可猜测需求。
这时候有人提出了 MongoDB 的 ObjectID,不要忘了它生成的 ID 是这样的: 5b6b3171599d6215a8007se0,和 UUID 一样无法满足递增属性,且和 MySQL 一样要入库后才能生成。
难道就没有能打的了吗?
Twitter 于 2010 年开源了内部团队在用的一款全局唯一 ID 生成算法 Snowflake,翻译过来叫做雪花算法。Snowflake 不借助数据库,可直接由编程语言生成,它通过巧妙的位设计使得 ID 能够满足递增属性,且生成的 ID 并不是依次连续的,能够满足上面提到的全局唯一 ID 的 4 个属性。它连续生成的 3 个 ID 看起来像这样:
563583455628754944
563583466173235200
563583552944996352
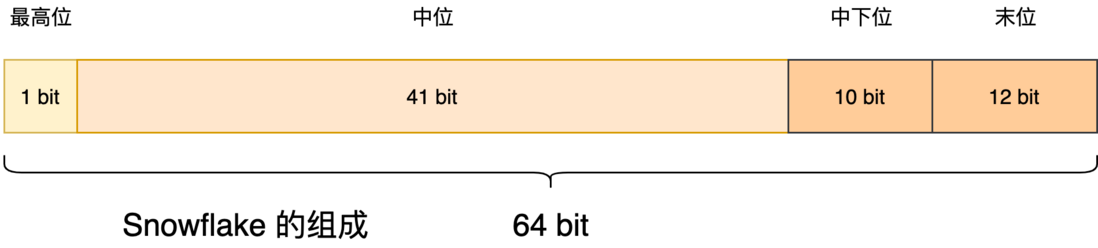
Snowflake 以 64 bit 来存储组成 ID 的4 个部分:
1、最高位占1 bit,值固定为 0,以保证生成的 ID 为正数;
2、中位占 41 bit,值为毫秒级时间戳;
3、中下位占 10 bit,值为工作机器的 ID,值的上限为 1024;
4、末位占 12 bit,值为当前毫秒内生成的不同 ID,值的上限为 4096;
Snowflake 的代码实现网上有很多款,基本上各大语言都能找到实现参考。我之前在做实验的时候在网上找到一份 Golang 的代码实现:
代码可在我的 Gist 查看和下载。
snowflake 不依赖数据库,也不依赖内存存储,随时可生成 ID,这也是它如此受欢迎的原因。但因为它在设计时通过时间戳来避免对内存和数据库的依赖,所以它依赖于服务器的时间。上面我们提到了 Snowflake 的 4 段结构,实际上影响 ID 大小的是较高位的值,由于最高位固定为 0,遂 影响 ID 大小的是中位的值,也就是时间戳。
试想,服务器的时间发生了错乱或者回拨,这就直接影响到生成的 ID,有很大 概率生成重复的 ID 且 一定会打破递增属性。这是一个致命缺点,你想想, 支付订单和购买订单的编号重复,这是多么严重的问题!
另外,由于它的 中下位和 末位 bit 数限制,它 每毫秒生成 ID 的上限严重受到限制。由于 中位是 41 bit 的毫秒级时间戳,所以从当前起始到 41 bit 耗尽,也 只能坚持 70 年。
再有,程序获取操作系统时间会耗费较多时间,相比于随机数和常数来说,性能相差太远,这是 制约它生成性能的最大因素。
长话短说,我们来看看 百度、美团、腾讯(微信)是如何做的。
百度团队开源了 UIDGenerator 算法.
它通过借用未来时间和双 Buffer 来解决时间回拨与生成性能等问题,同时结合 MySQL 进行 ID 分配。这是一种基于 Snowflake 的优化操作,是一个好的选择,你认为这是不是优选呢?
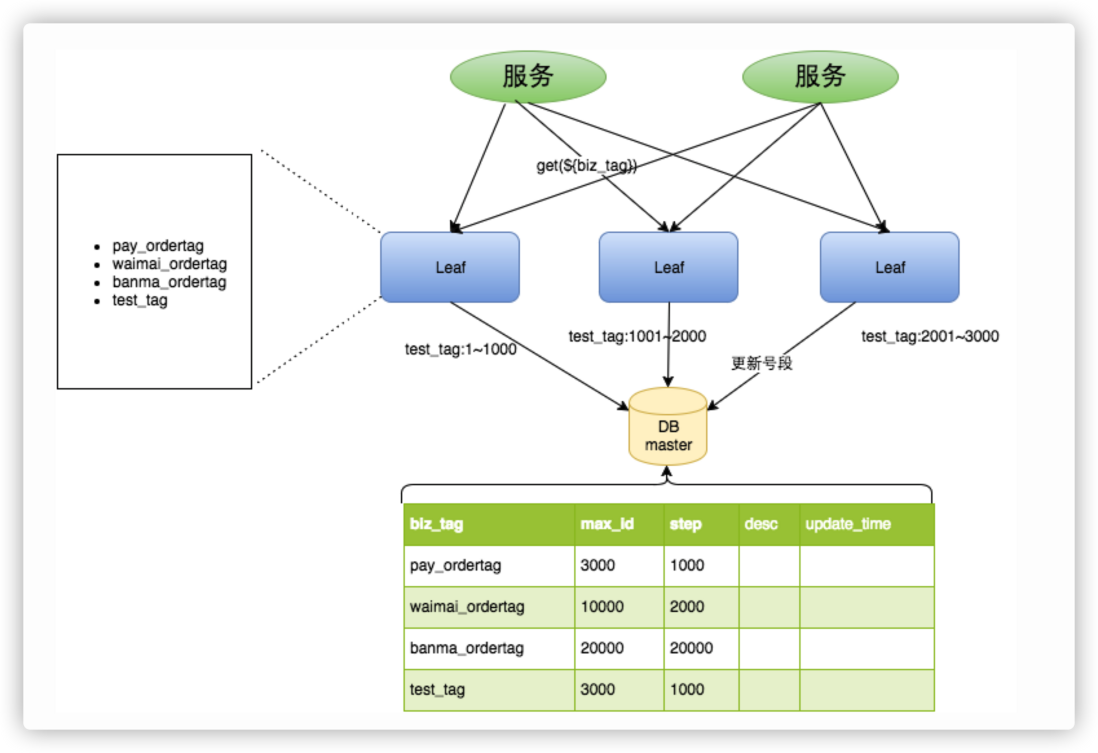
美团团队根据业务场景提出了基于号段思想的 Leaf-Segment 方案和基于 Snowflake 的 Leaf-Snowflake 方案.
出现两种方案的原因是 Leaf-Segment 并没有满足安全属性要求,容易被猜测,无法用在对外开放的场景(如订单)。Leaf-Snowflake 通过文件系统缓存降低了对 ZooKeeper 的依赖,同时通过对时间的比对和警报来应对 Snowflake 的时间回拨问题。这两种都是一个好的选择,你认为这是不是优选呢?
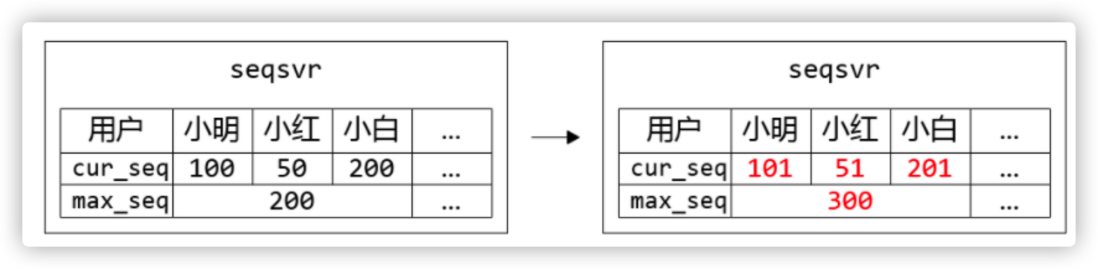
微信团队业务特殊,它有一个用 ID 来标记消息的顺序的场景,用来确保我们收到的消息就是有序的。在这里不是全局唯一 ID,而是单个用户全局唯一 ID,只需要保证这个用户发送的消息的 ID 是递增即可。
这个项目叫做 Seqsvr,它并没有依赖时间,而是通过自增数和号段来解决生成问题的。这是一个好的选择,你认为这是不是优选呢?
在了解 Snowflake 的优缺点、阅读了百度 UIDGenertor、美团 Leaf 和腾讯微信 Seqsvr 的设计后,我希望设计出一款能够满足全局唯一 ID 4 个属性且 性能更高、使用期限更长、不受单位时间限制、不依赖时间的全局唯一 ID 生成算法。
这看起来很简单,但吸收所学知识、设计、实践和性能优化占用了我 4 个周末的时间。在我看来,这个算法的设计过程就像是液态的水转换为气状的雾一样,遂我给这个算法取名为 薄雾(Mist)算法。接下来我们来看看薄雾算法是如何设计和实现的。
位数是影响 ID 数值上限的主要因素,Snowflake 中下位和末位的 bit 数限制了单位时间内生成 ID 的上限,要解决这个两个问题,就必须重新设计 ID 的组成。
抛开中位,我们先看看中下位和末位的设计。中下位的 10 bit 的值其实是机器编号,末位 12 bit 的值其实是单位时间(同一毫秒)内生成的 ID 序列号,表达的是这毫秒生成的第 5 个或第 150 个 数值,同时二者的组合使得 ID 的值变幻莫测,满足了安全属性。实际上并不需要记录机器编号,也可以不用管它到底是单位时间内生成的第几个数值,安全属性我们可以通过多组随机数组合的方式实现,随着 数字的递增和随机数的变幻,通过 ID 猜顺序的难度是很高的。
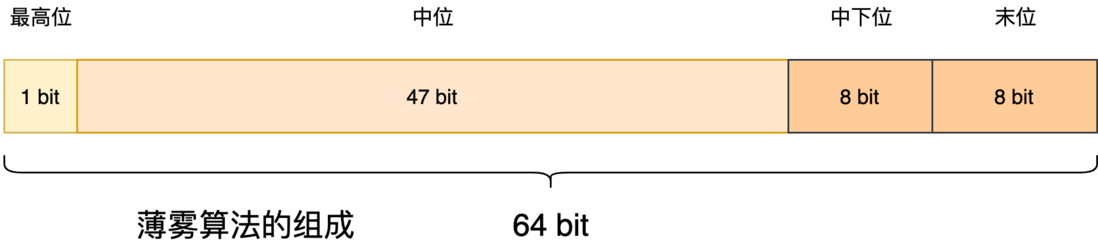
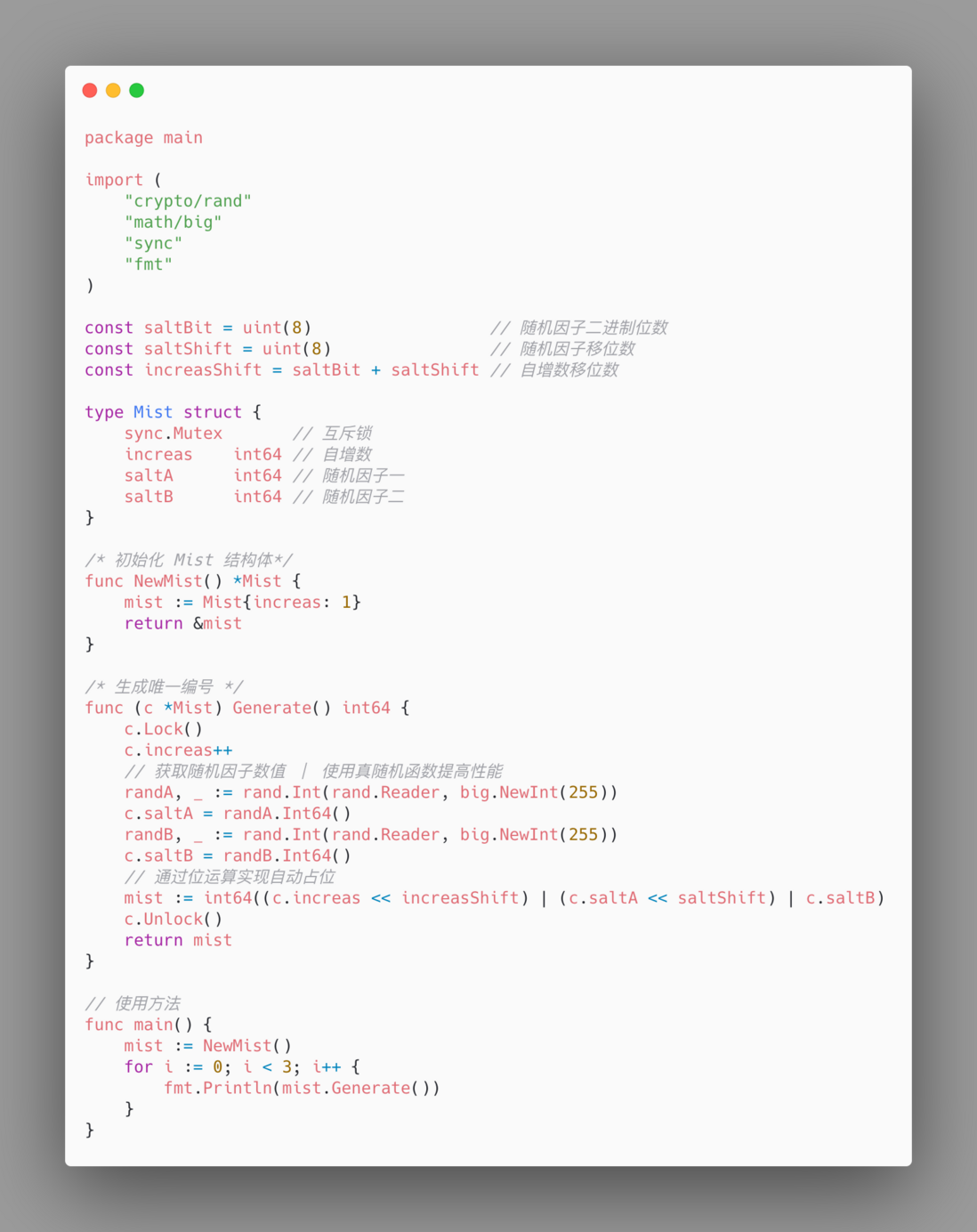
最高位固定是 0,不需要对它进行改动。我们来看看至关重要的中位,Snowflake 的中位是毫秒级时间戳,既然不打算依赖时间,那么肯定也不会用时间戳,用什么呢?我选择自增数 1,2,3,4,5,...。中位决定了生成 ID 的上限和使用期限,如果沿用 41 bit,那么上限跟用时间戳的上限相差无几,经过计算后我选择采用与 Snowflake 的不同的分段:
缩减中下位和末位的 bit 数,增加中位的 bit 数,这样就可以拥有更高的上限和使用年限,那上限和年限现在是多久呢?中位数值的上限计算公式为 int64(1<<47 - 1),计算结果为 140737488355327 。 百万亿级的数值,假设每天消耗 10 亿 ID,薄雾算法能用 385+ 年, 几辈子都用不完。
中下位和末位都是 8 bit,数值上限是 255,即开闭区间是 [0, 255]。这两段如果用随机数进行填充,对应的组合方式有 256 * 256 种,且每次都会变化,猜测难度相当高。由于不像 Snowflake 那样需要计算末位的序列号,遂薄雾算法的代码并不长,具体代码可在我的 GitHub 仓库找到:
聊聊性能问题,获取时间戳是比较耗费性能的,不获取时间戳速度当然快了,那 500+ 倍是如何得来的呢?以 Golang 为例(我用 Golang 做过实验),Golang 随机数有三种生成方式:
基于固定数值种子的随机数每次生成的值都是一样的,是伪随机,不可用在此处。将时间戳作为种子以生成随机数是目前 Golang 开发者的主流做法,实测性能约为 8800 ns/op。
大数真随机知道的人比较少,实测性能 335ns/op,由此可见性能相差近 30 倍。大数真随机也有一定的损耗,如果想要将性能提升到顶点,只需要将中下位和末位的随机数换成常数即可,常数实测性能 15ns/op,是时间戳种子随机数的 587 倍。
要注意的是,将常数放到中下位和末位的性能是很高,但是猜测难度也相应下降。
薄雾算法为了避开时间依赖,不得不依赖存储,中位自增的数值只能在内存中存活,遂需要依赖存储将自增数值存储起来,避免因为宕机或程序异常造成重复 ID 的事故。
看起来是这样,但它真的是依赖存储吗?
你想想,这么重要的服务必定要求高可用,无论你用 Twitter 还是百度或者美团、腾讯微信的解决方案,在 架构上一定都是高可用的,高可用一定需要存储。在这样的背景下,薄雾算法的依赖其实并不是额外的依赖,而是可以与架构完全 融合到一起的设计。
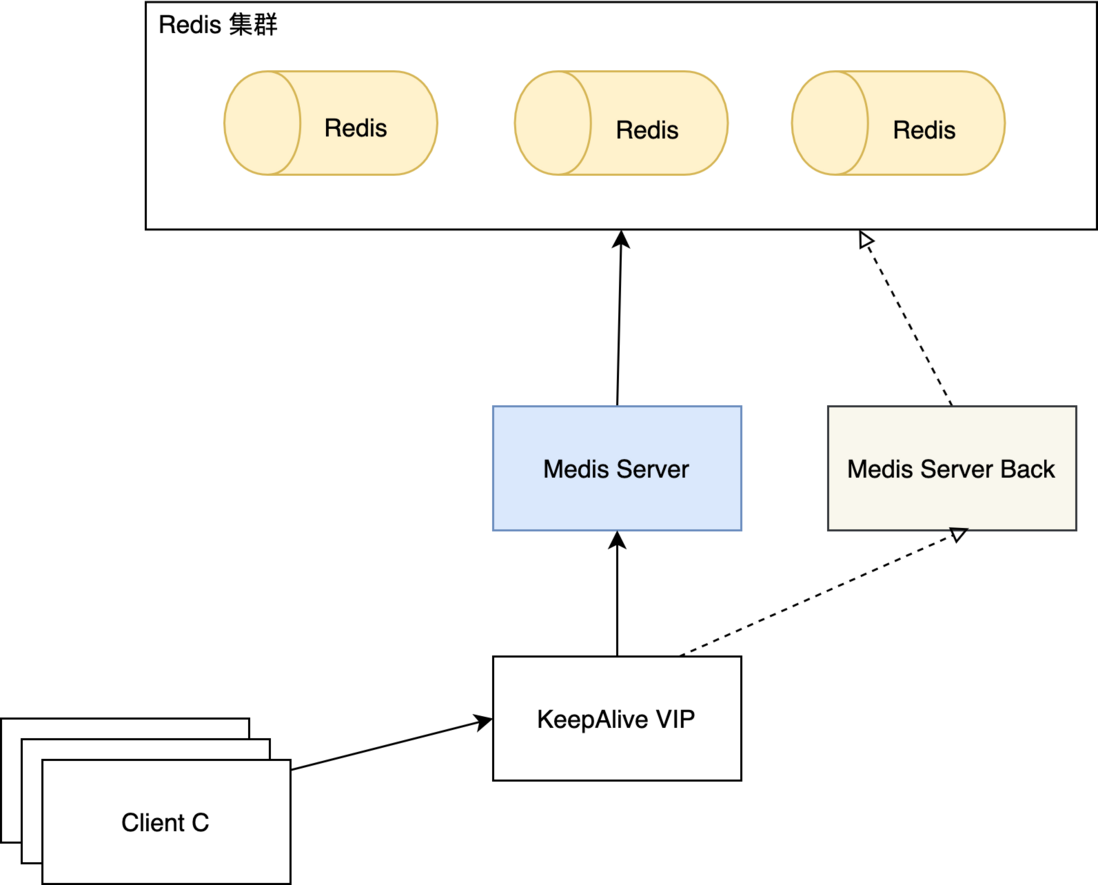
既然提出了薄雾算法,怎么能不提供真实可用的工程实践呢?在编写完薄雾算法之后,我就开始了工程实践的工作,将薄雾算法与 KV 存储结合到一起,提供全局唯一 ID 生成服务。这里我选择了较为熟悉的 Redis,Mist 与 Redis 的结合,我为这个项目取的名字为 Medis。
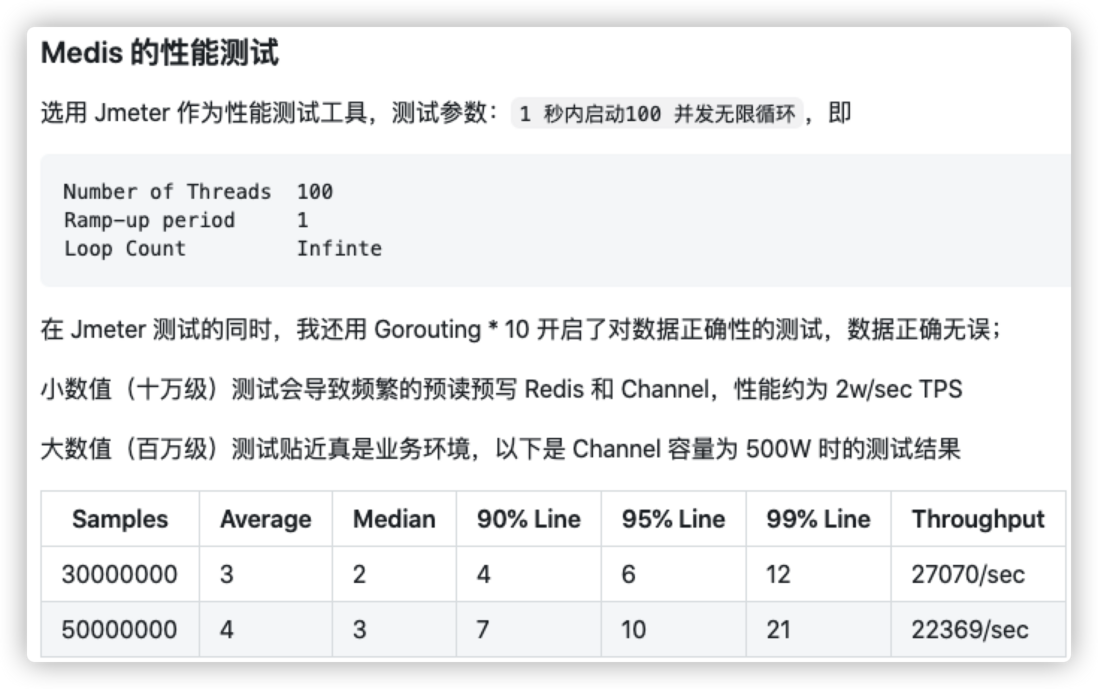
性能高并不是编造出来的,我们看看它 Jemeter 压测参数和结果:
以上是 Medis README 中给出的性能测试截图,在大基数条件下的性能约为 2.5w/sec。这么高的性能除了薄雾算法本身高性能之外,Medis 的设计也作出了很大贡献:
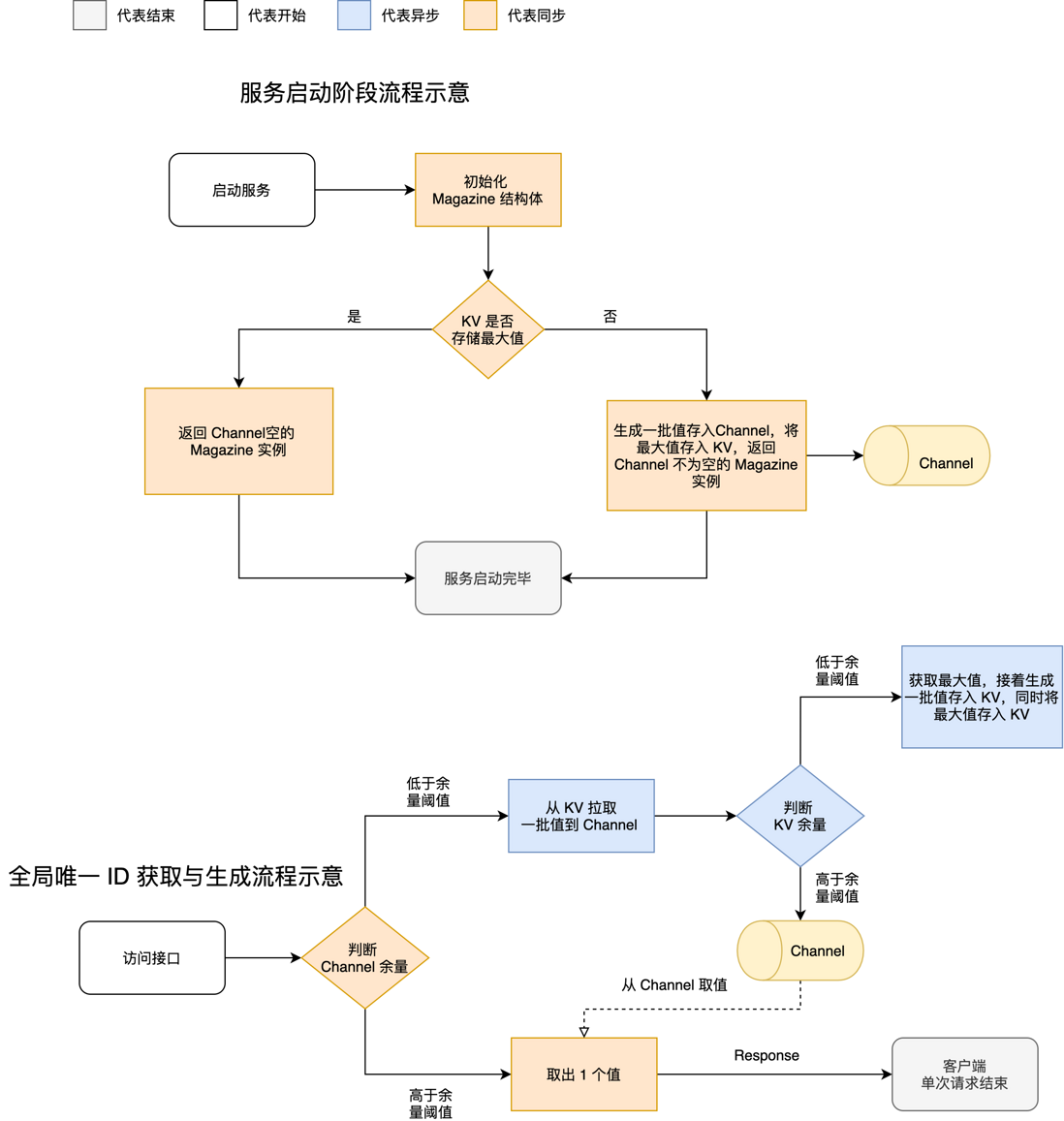
Medis 服务启动流程和接口访问流程图下所示:
感兴趣的朋友可以下载体验一下,启动 Medis 根目录的 server.go 后,访问 http://localhost:1558/sequence 便能拿到全局唯一 ID。
分布式 CAP (一致性、可用性、分区容错性)已成定局,这类服务通常追求的是可用性架构(AP)。由于设计中采用了预存预取,且要保持整体顺序递增,遂单机提供访问是优选,即分布式架构下的性能上限就是提供服务的那台主机的单机性能。
你想要实现分布式多机提供服务?
这样的需求要改动 Medis 的逻辑,同时也需要改动各应用之间的组合关系。如果要实现分布式多机同时提供服务,那么就要 废弃 Redis 和 Channel 预存预取机制,接着放弃 Channel 而 改用即时生成,这样便可以同时使用多个 Server,但性能的瓶颈就 转移到了 KV 存储(这里是 Redis), 性能等同于单机 Redis 的性能。你可以采用 ETCD 或者 Zookeeper 来实现多 KV,但这不是 又回到了 CAP 原点了吗?
至于怎么选择,可根据实际业务场景和需求与架构进行讨论,选择一个适合的方案进行部署即可。
领略了 Mist 和 Medis 的风采后,相信你一定会有其他巧妙的想法,欢迎在评论区留言,我们一起交流进步!
夜幕团队成立于 2019 年,团队包括崔庆才(静觅)、周子淇(Loco)、陈祥安(CXA)、唐轶飞(大鱼|BruceDone)、冯威(妄为)、蔡晋(悦来客栈的老板)、戴煌金(咸鱼)、张冶青(MarvinZ)、韦世东(Asyncins|奎因)和文安哲(sml2h3)。
涉猎的编程语言包括但不限于 Python、Rust、C++、Go,领域涵盖爬虫、深度学习、服务研发、逆向工程、软件安全等。团队非正亦非邪,只做认为对的事情,请大家小心。