第一次在 Kubernetes 上部署应用时我们忽略的5件事
根据我的经验,似乎大多数人认为将应用程序部署到
Kubernetes 上就完成工作了(无论使用
Helm 或手动)。通过在
GumGum 中使用 Kubernetes,我们遇到了一些“陷阱”,希望在此列出这些“陷阱”以帮助您在 Kubernetes 上部署应用程序之前了解基础。
第一步:配置 Pod 请求和限制
我们将从配置一个可以在其中运行 Pod 的干净环境开始。Kubernetes 在处理 Pod 调度和故障状态方面做得非常出色。但是,我们了解到,如果
Kubernetes 调度程序无法测量 Pod 需要多少资源才能成功运行,有时它会很难放置 Pod。这就是资源请求和限制的来源。关于设置应用程序请求和限制的最佳方法的争论很多。实际上,感觉起来更像是一门艺术,而不是一门科学。如下是
GumGum 内部对它们的看法:
Pod 请求:这是调度程序用来放置 pods 的主要参考值。来自
Kubernetes 文档:
过滤步骤会找到一组 Node 节点,它们可以用来调度 Pod 。例如,PodFitsResources 过滤器检查候选节点是否具有足够的可用资源来满足 Pod 的特定资源请求。
在内部,我们以这种方式使用应用程序请求;我们依据应用程序在正常工作负载下的实际需求估计来设置 Pod 请求。这样,调度程序能够根据实际放置节点。最初,我们希望将请求值设置为更高,以确保每个 pod 都有足够的资源,但是当我们这样做时,我们注意到调度时间大大增加,甚至有些 pod 完全无法调度。这点类似于我们没有指定资源请求时观察到的行为。在这种情况下,调度程序经常会“逐出” pod 而无法重新调度它们,这是由于控制器不知道应用程序需要多少资源,这也是调度算法的关键组成部分。
Pod 限制: 这是 pod 的直接限制;它表示集群允许容器使用的最大资源。
再次,来自官方文档...
如果您为该容器设置了4GiB的内存限制,则 kubelet(和容器运行时)将强制执行该限制。运行时可防止容器使用超出配置的资源限制。例如:当容器中的进程尝试消耗的内存大小超过允许的内存时,系统内核将终止尝试分配的进程,并出现内存不足(OOM)错误。
容器可以使用比其请求更多的资源,但永远不能超过其限制。正确设置这个值非常重要。理想情况下,您希望让 Pod 的资源需求在进程的生命周期中发生变化,而又不会干扰系统中的其他进程--这是限制的目标。不幸的是,我无法提供具体的设置值,但我们按照以下过程进行调整:
- 使用负载测试工具,我们模拟基本流量,并观察 pod 的资源使用情况(内存和 CPU)
- 我们将 pod 请求设置为任意低(同时将 pod 资源限制保持在请求值的5倍左右)并观察。当请求太少时,该进程将无法启动,并经常引发神秘的 Go 运行时错误。
我想指出的一点是,更高的资源限制导致更难的 pod 调度;因为它需要具有足够的可用资源的目标节点。试想一下您可能在资源限制很高(例如4GB内存)的情况下运行轻量级 web 服务器进程,这个进程您可能需要水平扩展,并且每个新容器都需要被调度到至少具有4GB可用内存的节点上。如果该节点不存在,则您的集群需要引入一个新节点来处理该 pod,这可能需要一些时间才能启动。务必在资源请求和限制之间取得最小的“界限”,以确保快速平稳地扩展。
第二步:配置 Liveness 和 Readiness 探针
Kubernetes 社区中经常讨论的另一个微妙话题。掌握 Liveness 和 Readiness 探针非常重要,因为它们提供了一种运行容错软件并最大程度地减少停机时间的机制。但是,如果配置不正确,它们可能会给您的应用程序带来严重的性能下降。以下是关于这两个探针的概要说明以及如何理解它们:
Liveness 探针:“指示容器是否正在运行。如果 Liveness 探针失败, kubelet 将杀死容器,并且容器将接受其重新启动策略。如果容器不提供 liveness 探针,则默认状态为成功。“—
Kubernetes Docs
Liveness 探针需要轻量,因为它们使用频繁,并且需要在应用运行时通知 Kubernetes。请注意,如果将其设置为每秒运行一次,那么每秒将增加一个额外的请求流量,因此请考虑处理该请求所需的那些额外资源。在 GumGum,我们的 Liveness 探针设置为在应用程序的主要组件运行时响应,但是数据(例如来自远程数据库或缓存)可能尚未完全可用时。我们通常是这样实现的,设置一个特定的“健康”状态,该状态仅返回200响应代码。这很好地表明您的进程已启动并且可以处理请求(但尚未处理流量)。
Readiness 探针:“指示容器是否准备好处理请求。如果 readiness 探针失败,则端点控制器将从与 Pod 匹配的所有服务的端点中删除 Pod 的 IP 地址。”
Readiness 探针的运行成本要高很多,因为它们要以表明整个应用程序正在运行并准备接收请求的方式进入后端。关于是否应该访问数据库,社区中存在很多争论。考虑到它确实造成的开销(这些检查运行频繁,但是可以调整),我们决定对于某些应用程序,只有从数据库返回记录后,我们才“提供流量”。通过使用经过深思熟虑的 readiness 探针,我们已经能够实现更高水平的可用性以及零停机时间部署。
如果您确定数据库的请求对应用程序的 readiness 探针有意义,请确保数据库查询尽可能简单。例如...
SELECT small_item FROM table LIMIT 1
如下是如何在 Kubernetes 中配置这两个值的示例:
livenessProbe:
httpGet:
path: /api/liveness
port: http
readinessProbe:
httpGet:
path: /api/readiness
port: http periodSeconds: 2
如下是一些其他配置选项:
-
initialDelaySeconds - 容器启动多少秒后探针开始运行 -
periodSeconds - 探针两次探测之间的等待间隔 -
timeoutSeconds - pod 被认为处于故障状态前的秒数。传统的超时时间。 -
failureThreshold - 重启信号发送到 pod 之前,pod 探针需要检测失败的次数。 -
successThreshold - pod 进入就绪状态之前探针必须检测成功多少次(在 pod 启动或恢复的故障事件后)
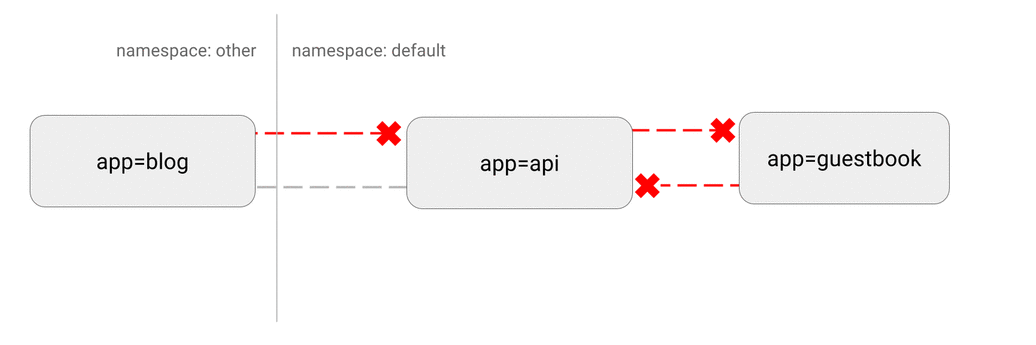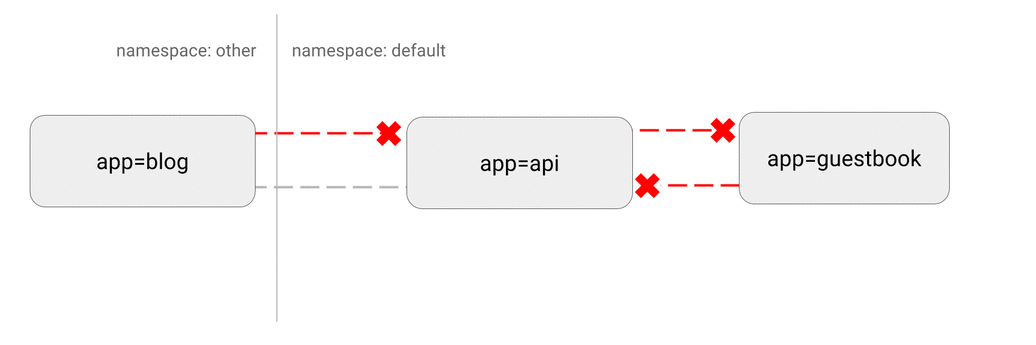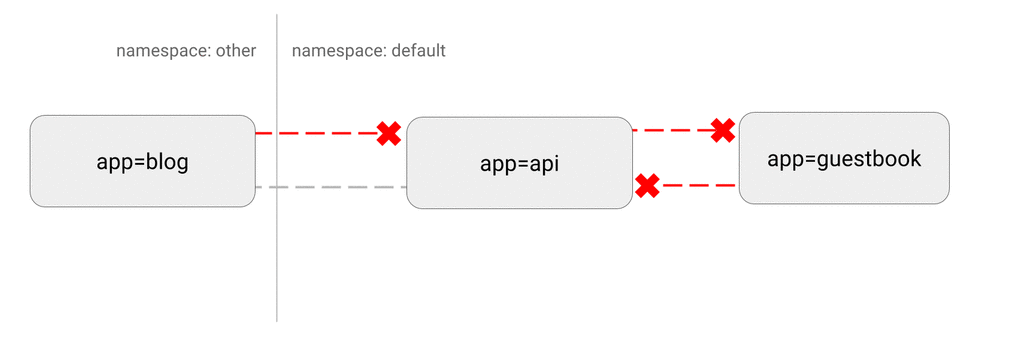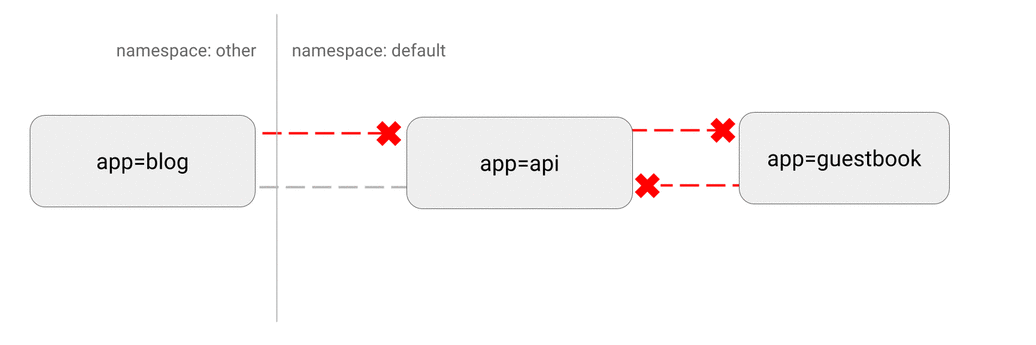
第三步:设置默认的 pod 网络策略
Kubernetes 使用一种“扁平”的网络拓扑,默认情况下,所有 pod 都可以直接相互通信。在某些情况下,这是不希望的,甚至是不必要的。潜在的安全隐患是,如果被利用,则单个易受攻击的应用程序可以为攻击者提供完全访问权限访问网络中的所有 pod。像在许多安全领域中一样,最小访问策略也适用于此,理想情况下,创建网络策略时会明确指定允许哪些容器到容器的连接。
例如,以下是一个简单的策略,该策略将拒绝特定命名空间的所有入口流量:
```
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
```
以下是此配置的可视化图像:
更多信息请看
这里。
第四步:通过 钩子 和 初始容器自定义行为
我们使用Kubernetes 系统的主要目标之一就是尝试为开发人员提供尽可能零停机的部署,这个目标很难实现,由于应用程序关闭并清理已利用资源的方式多种多样。我们遇到特别困难的一个应用是
Nginx。我们注意到,当我们启动这些 pod 的滚动部署时,活动连接在成功终止之前已被删除。经过广泛的在线研究,事实证明 Kubernetes 在终止 pod 之前并没有等待
Nginx 清理其连接。使用停止前钩子,我们能够注入此功能,并通过此更改实现了零停机时间。
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]
如下是 nginx-killer.sh :
!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
done
另一个非常有用的例子是使用初始化容器来处理应用程序的特定启动任务。某些受欢迎的 Kubernetes 项目,例如
Istio,也利用初始化容器将
Envoy 处理代码注入到 pod 中。如果您有繁重的数据库迁移进程需要在应用程序启动之前运行,则这特别有用。您也可以为此进程设置更高的资源限制,而对主应用程序不使用该限制。
另一个常见的模式是向初始化容器授予秘密访问权限,该容器将这些凭据暴露给主容器;防止来自主应用程序 pod 的未经授权的秘密访问。与往常一样,来自
文档:
初始化容器可以安全地运行实用程序或自定义代码,否则它们会使应用容器镜像的安全性降低。通过将不必要的工具分开,您可以限制应用容器镜像的攻击面。
第五步:内核调优
最后,将更先进的技术放到最后。Kubernetes 是一个非常灵活的平台,皆在让您以自己认为合适的方式运行工作负载。在 GumGum,我们有许多高性能应用程序,它们对资源的需求非常苛刻。在进行了广泛的负载测试之后,我们发现我们的一个应用程序正在使用默认的 Kubernetes 设置努力满足预期的流量负载。但是,Kubernetes 允许我们运行特权容器,该特权容器可以修改仅适用于特定运行 Pod 的内核参数。以下是我们用来修改 pod 允许的最大连接数的示例:
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "sysctl -w net.core.somaxconn=32768"]
这是一种不经常需要的更高级的技术。如果您的应用程序难以在高负载下保持运行,则可能需要尝试调整其中一些参数。与往常一样,可以在
官方文档中找到有关此过程和可以调整的值的更多信息。
总结
尽管 Kubernetes 似乎是一种现成的“开箱即用”解决方案,但是您需要采取一些关键步骤来确保应用程序的平稳运行。在将应用程序转换为在 Kubernetes 上运行的整个过程中,务必遵循负载测试“循环”;运行您的应用程序,对其进行负载测试,观察指标和扩展行为,基于该数据调整您的配置,然后重复。对您期望的流量保持实际,并使其超过该限制,以查看可能首先损坏的组件。使用这种迭代方法,您可能仅使用这些建议的一部分就能成功,或者可能需要更深入的调整。经常问自己以下问题:
- 我的应用程序的资源占用量是多少,它将如何变化?
- 该服务的实际扩展要求是什么?预计将处理多少平均流量和高峰流量?
- 我们期望该服务多久横向扩展一次?需要多长时间这些新的 pod 才能接受流量。
- 我们的 pod 会优雅地终止吗?它们是否需要?我们能否实现零停机时间部署?
- 如何使我的安全风险最小化,并限制所有受损 pod 的“爆炸半径”?我的服务是否具有不需要的权限或访问权限?
Kubernetes 提供了一个令人难以置信的平台,使您可以利用最佳实践在整个集群中部署数千个服务。正如人们所说,并非所有软件都是平等的。有时您的应用程序可能需要更多的工作,而且值得庆幸的是,Kubernetes 为我们提供了调整旋钮以实现我们期望的技术目标。通过结合使用资源请求和限制,liveness 和 readiness 检查,初始化容器,网络策略以及自定义内核调整,我相信您可以实现出色的基准性能以及弹性和快速可扩展性。
原文链接:
5 Things We Overlooked When Deploying Our First App on Kubernetes (翻译:xiebo)