
腾讯唯一时序数据库:CTSDB 解密
- -本文将对时序数据库的基本概念、应用场景及腾讯时序数据库CTSDB做简要介绍,希望对您有所帮助. 本文来自于公众号腾讯技术工程,由火龙果软件刘琛编辑推荐. 在引入时序数据库之前,先要了解“时序数据”的概念:按照时间顺序记录系统、设备状态变化的数据被称为时序数据(TimeSeries Data). 它普遍存在于IT基础设施、运维监控系统和物联网中.
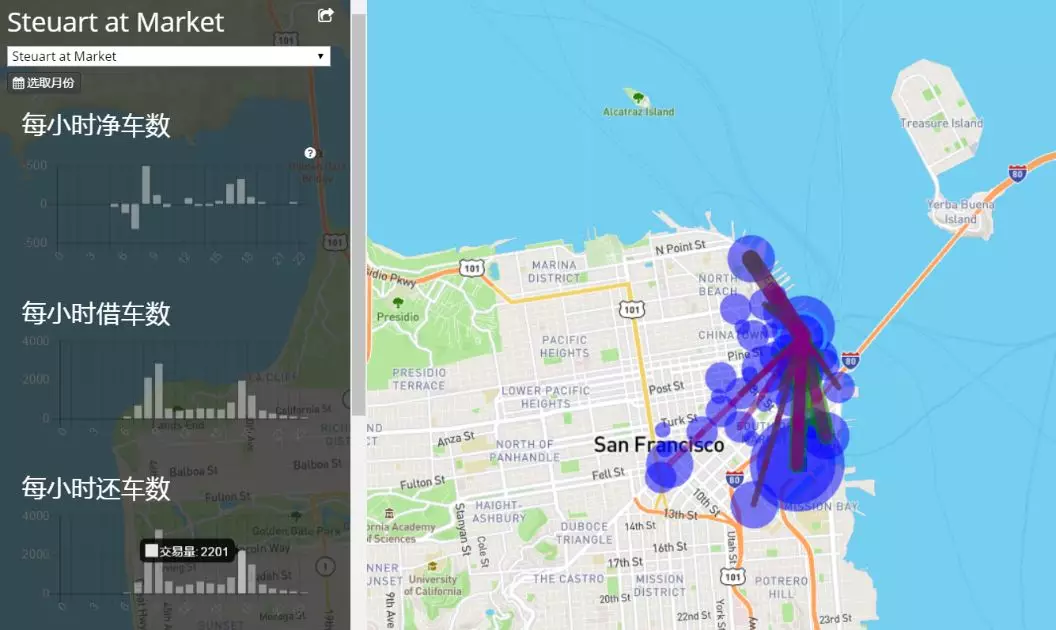
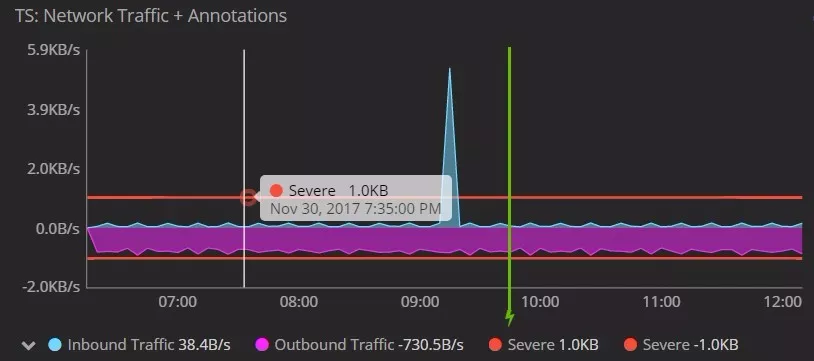
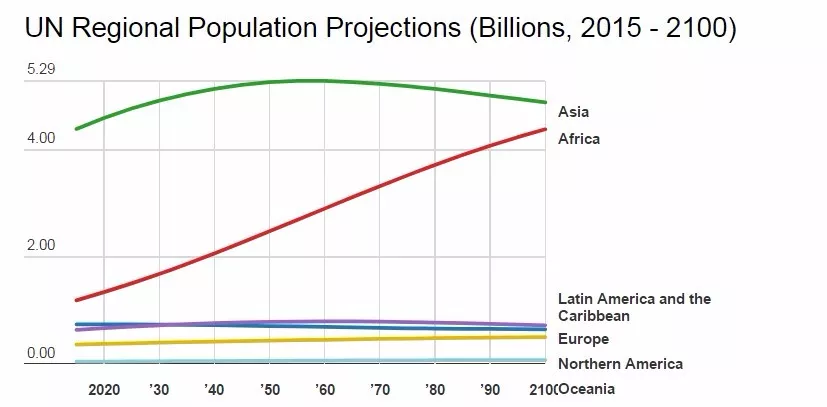
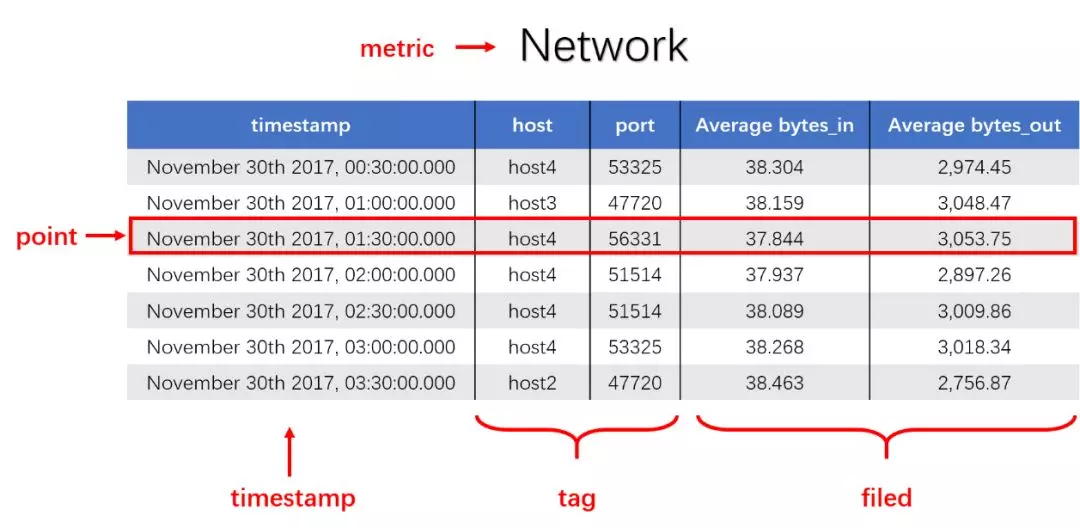
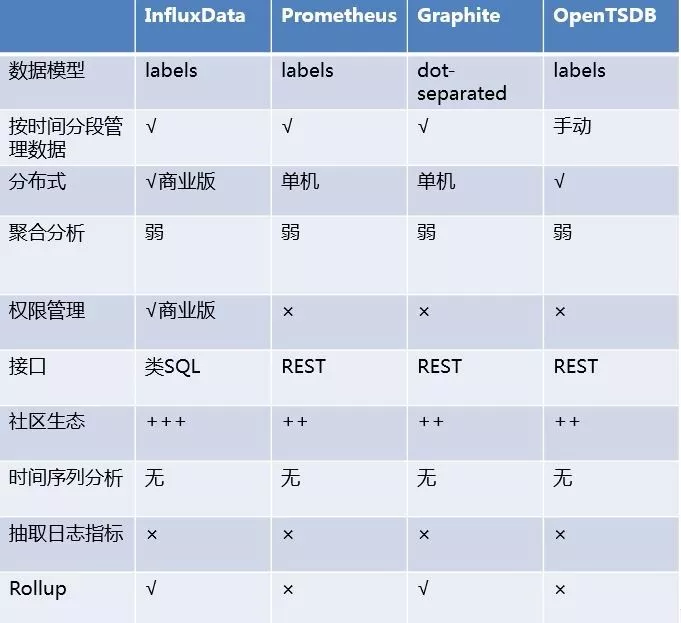
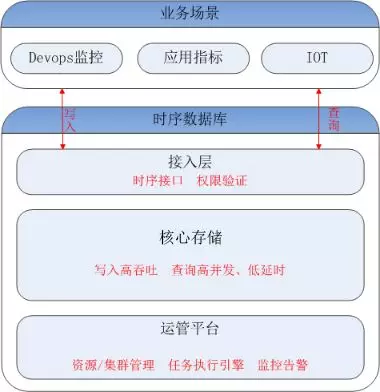
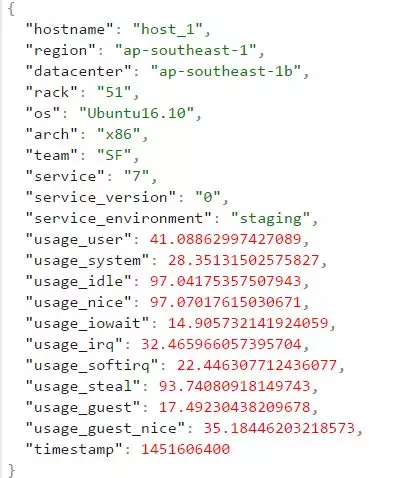
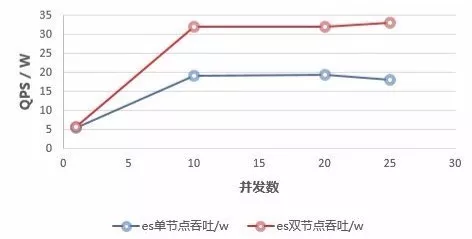
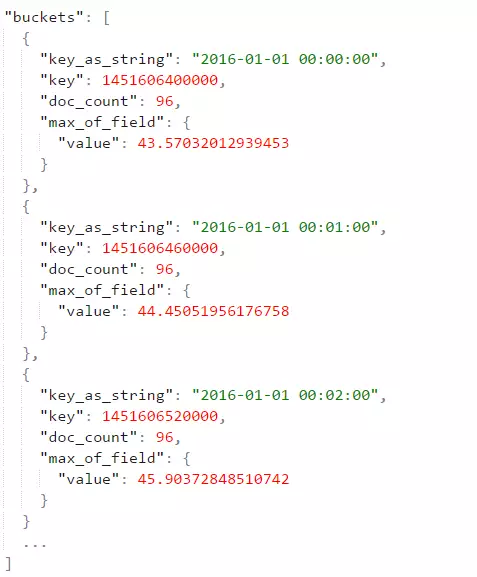
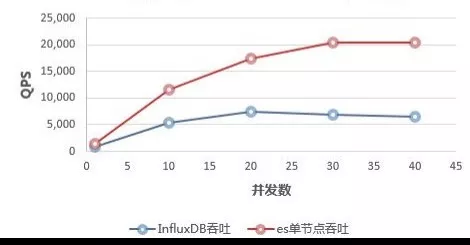
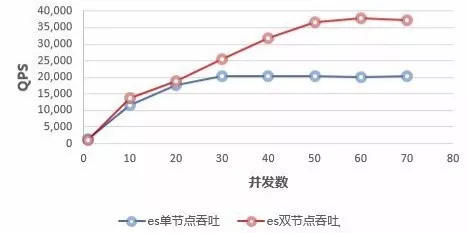
什么是时序数据库 1. 时序数据 1.1 什么是时序数据? 在引入时序数据库之前,先要了解“时序数据”的概念:按照时间顺序记录系统、设备状态变化的数据被称为时序数据(TimeSeries Data)。它普遍存在于IT基础设施、运维监控系统和物联网中。 时序数据从时间维度上将孤立的观测值连成一条线,从而揭示软硬件系统的状态变化。孤立的观测值不能叫时序数据,但如果把大量的观测值用时间线串起来,我们就可以研究和分析观测值的趋势及规律。其意义体现在两方面: (1)从时间轴往后看,时序数据可做成报表,观测数据变化规律、捕获异常。这里举两个例子: 下图为共享单车在旧金山某热门区域的每小时车辆的借还数量。通过分析该区域车辆数目的历史数据,单车公司可得知热点借车时间段是否需要车辆补给。 下图为某互联网服务的出入流量历史记录。从图中可以明显看到入流量(蓝色线)在某时间段有毛刺,服务提供商可基于此段时间排查服务有无异常。也可以进一步基于流量监控做告警,使运维人员能够及时处理线上问题。 (2)从时间轴向前看,时序数据可以建立数学模型、做统计分析,预测事物发展趋势。 举例,下图为联合国在2015年分析过往人口增长趋势后,发布的人口数字及预测报告。从图中可以看出未来非洲人口将持续增长,这是任何一个跨国企业都不该忽略的市场,也预示着当地政府面临重大挑战。 1.2 时序数据的数学模型 上面介绍了时序数据的基本概念,也说明了分析时序数据的意义。那么时序数据该怎样存储呢?数据的存储要考虑其数学模型和特点,时序数据当然也不例外。所以这里先介绍时序数据的数学模型和特点。 下图为一段时序数据,记录了一段时间内的某个集群里各机器上各端口的出入流量,每半小时记录一个观测值。这里以图中的数据为例,介绍下时序数据的数学模型(不同的时序数据库中,基本概念的称谓有可能不同,这里以腾讯CTSDB为准): metric: 度量的数据集,类似于关系型数据库中的 table; point: 一个数据点,类似于关系型数据库中的 row; timestamp: 时间戳,表征采集到数据的时间点; tag: 维度列,代表数据的归属、属性,表明是哪个设备/模块产生的,一般不随着时间变化,供查询使用; field: 指标列,代表数据的测量值,随时间平滑波动,不需要查询。 如上图所示,这组数据的metric为Network,每个point由以下部分组成: timestamp:时间戳 两个tag:host、port,代表每个point归属于哪台机器的哪个端口 两个field:bytes_in、bytes_out,代表piont的测量值,半小时内出入流量的平均值 同一个host、同一个port,每半小时产生一个point,随着时间的增长,field(bytes_in、bytes_out)不断变化。 如host:host4,port:51514,timestamp从02:00 到02:30的时间段内,bytes_in 从 37.937上涨到38.089,bytes_out从2897.26上涨到3009.86,说明这一段时间内该端口服务压力升高。 1.3 时序数据特点 数据模式: 时序数据随时间增长,相同维度重复取值,指标平滑变化:这点从上面的Network表的数据变化可以看出。 写入: 持续高并发写入,无更新操作:时序数据库面对的往往是百万甚至千万数量级终端设备的实时数据写入(如摩拜单车2017年全国车辆数为千万级),但数据大多表征设备状态,写入后不会更新。 查询: 按不同维度对指标进行统计分析,且存在明显的冷热数据,一般只会频繁查询近期数据。 2. 时序数据库 有了时序数据后,该存储在哪里呢?首先我们看下传统的解决方案在存储时序数据时会遇到什么问题。 2.1 传统解决方案 时序数据往往是由百万级甚至千万级终端设备产生的,写入并发量比较高,属于海量数据场景。传统的时序数据解决方案主要有两种:关系型数据库(MySQL)、Hadoop生态。 ・ MySQL:在海量的时序数据场景下存在如下问题 存储成本大:对于时序数据压缩不佳,需占用大量机器资源; 维护成本高:单机系统,需要在上层人工的分库分表,维护成本高; 写入吞吐低:单机写入吞吐低,很难满足时序数据千万级的写入压力; 查询性能差:适用于交易处理,海量数据的聚合分析性能差。 ・ Hadoop生态(Hadoop、Spark等) 数据延迟高:离线批处理系统,数据从产生到可分析,耗时数小时、甚至天级; 查询性能差:不能很好的利用索引,依赖MapReduce任务,查询耗时一般在分钟级。 2.2 时序数据库 时序数据库是管理时序数据的专业化数据库,并针对时序数据的特点对写入、存储、查询等流程进行了优化,这些优化与时序数据的特点息息相关: 1) 存储成本: 利用时间递增、维度重复、指标平滑变化的特性,合理选择编码压缩算法,提高数据压缩比; 通过预降精度,对历史数据做聚合,节省存储空间。 2) 高并发写入: 批量写入数据,降低网络开销; 数据先写入内存,再周期性的dump为不可变的文件存储。 3) 低查询延时,高查询并发: 优化常见的查询模式,通过索引等技术降低查询延时; 通过缓存、routing等技术提高查询并发。 2.3 开源时序数据库对比 目前行业内比较流行的开源时序数据库产品有 InfluxDB、OpenTSDB、Prometheus、Graphite等,其产品特性对比如下图所示: 从上表可以看出,开源的时序数据库存在如下问题: 没有free、易用的分布式版本(OpenTSDB支持分布式部署,但依赖系统过多,维护成本高); 聚合能力普遍较弱,而时序数据大多需要来做统计分析; 没有free的权限管理; 没有针对时间序列的多维度对比分析工具。 CTSDB 腾讯CTSDB(Cloud Time Series Database)是一种分布式、高性能、多分片、自均衡的时序数据库,针对时序数据的高并发写入、存在明显的冷热数据、IoT用户场景等做了大量优化,同时也支持各行业的日志解析和存储,其架构如下图所示。 1. CTSDB主要特点 1) 高性能:(具体性能数据将在后文给出) 支持批量写入、高并发查询; 通过集群扩展,随时线性提升系统性能; 支持sharding、routing,加速查询。 2) 高可靠: 支持多副本; 机架感知,自动错开机架分配主从副本。 3) 易使用: 丰富的数据类型,REST接口,数据写入查询均使用json格式; 原生分布式,弹性可伸缩,数据自动均衡; 4) 低成本: 支持列存储,高压缩比(0.1左右),降低存储成本; 支持数据预降精度:降低存储成本的同时,提高查询性能。 副本数可按需调整。 5) 强大的聚合能力: max,min,avg,percentile,sum,count,group by等常用聚合; 复杂的脚本聚合(例如可对多字段间的计算结果做聚合); 时间区间聚合、GEO聚合、嵌套聚合。 6) 亮点能力: 数据监控告警:对存入数据进行数据量、字段统计、基线对比等监控,通过微信、短信、邮件告警; 权限系统:支持用户名密码、机器白名单的权限系统; 数据时效性:支持数据过期删除; 数据导出。 2. 竞品性能对比测试 这里选用业界较为流行的InfluxDB来与CTSDB做性能对比测试。 2.1 测试场景 CTSDB与InfluxDB对比测试:CTSDB与InfluxDB均单节点部署,单节点占用24个cpu核心,128g内存,万兆网卡,,磁盘SSD RAID0。 CTSDB单节点集群与双节点集群对比测试:用以验证CTSDB的线性扩展能力。 2.2 写入性能测试 数据样例: 导入的数据由InfluxDB的官方测试工具产生,https://github.com/influxdata/influxdb-comparisons。 数据为若干host的时序数据,每个point包含10个tag(均为string类型),10个filed(均为float类型),timestamp为时间戳(一个host每10秒一个点)。 样例如下所示: 测试结果: (1) CTSDB单节点集群与InfluxDB单机版写入性能对比 结论:CTSDB单节点写入性能最高在19w,InfluxDB在15w。 (2) CTSDB单节点集群与CTSDB双节点集群写入性能对比 结论:CTSDB单节点集群写入最高可达20w,双节点集群写入性能34w。 2.3 查询性能测试 查询样例: 这里以CTSDB的查询语句为例: 查询语句解读: 取出1个host的全量数据,然后任取一个小时做过滤后,按分钟粒度分桶(groupby,最终结果有60个桶),最后输出所有的桶,并计算桶内所有数据的usage_user字段最大值 。 注意这里的查询使用了CTSDB的routing功能,用以加速查询。 查询结果样例: 测试结果: (1) CTSDB单节点集群与InfluxDB单机版查询性能对比 结论:CTSDB查询性能整体比InfluxDB好很多,当并发数较高时(40),CTSDB查询性能比InfluxDB高出近4倍,在2w左右。在并发线程数达到50时,InfluxDB出现链接错误,拒绝查询请求;此时,CTSDB可正常查询。 (2) CTSDB单节点集群与双节点集群查询性能对比 结论:在并发数较高的情况下,双节点集群查询性能较单节点集群有了大幅度提升,呈现了查询性能线性扩展的趋势。 |