用虚拟机搭建Kubernetes集群_The_shy等风来的博客-CSDN博客_虚拟机搭建k8s集群
- -一、Docker到底做了什么:. 一个轻量级的,在宿主机(比如你的云服务器centos或ubuntu虚机)基础上建立的一个隔离的主机环境,我们把这个隔离的虚拟主机环境叫容器. 跟传统的虚拟机相比,docker最大的区别就是它复用了外部物理宿主机内核,所以很轻量. docker主要解决了开发与部署时的环境冲突问题以及部署项目的成本问题:.
docker就是个容器服务。一个轻量级的,在宿主机(比如你的云服务器centos或ubuntu虚机)基础上建立的一个隔离的主机环境,我们把这个隔离的虚拟主机环境叫容器。跟传统的虚拟机相比,docker最大的区别就是它复用了外部物理宿主机内核,所以很轻量。docker主要解决了开发与部署时的环境冲突问题以及部署项目的成本问题:
1、保证部署和开发环境一样: docker环境
2、任何语言写的程序+程序的依赖环境都被封装打包为: docker镜像
3、所有程序都通过统一的docker命令将镜像运行成: docker容器
一切镜像都是基于Dockerfile来构建的,除了使用官方或别人的镜像,你也可以自己编写Dockerfile构建镜像,Dockerfile是个特殊的文本文件,就叫Dockerfile名称不能随便取。
1、单机使用,无法有效集群。
2、随着容器数量上升,管理成本攀升。
3、没有有效的容灾/自愈机制,容器死了你只能手动重启或新建。
4、没有预设编排模板,无法实现快速、大规模容器调度。
5、没有统一的配置管理中心工具。
6、没有容器生命周期的管理工具。
7、没有图形化运维管理工具。
综上所诉, 当容器量上升之后,我们需要一套容器编排工具。基于docker容器引擎的开源容器编排工具目前市场上主要有:
(1)docker compose,docker swarm
(2)Mesosphere + Marathon
(3) Kubernetes
由来:谷歌的Brog系统,后经Go语言重写并捐献给CNCF基金会,彻底开源。
含义:词根源于希腊语:舵手/飞行员。
作用:开源的容器编排工具( 生态极其丰富)。

如果装有集装箱的船没有帆,是没有灵魂和方向的。
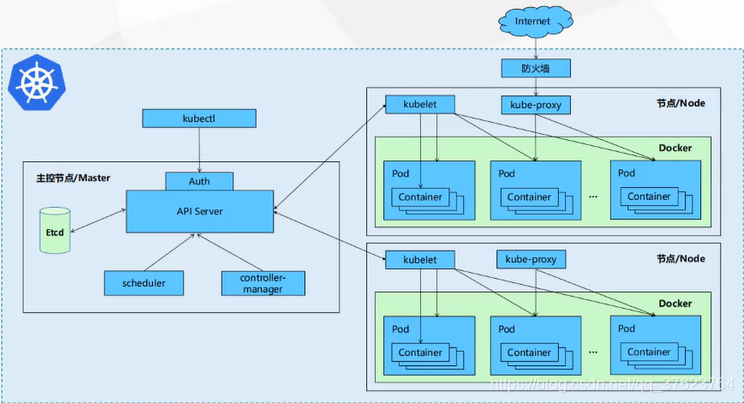
1、看上图,一共有三台节点,一台master两台node。k8s集群中所谓的节点其实就是服务器,k8s中的节点分为两类。一类是主节点master,它只负责做管理调度,不跑业务,主节点上的主要组件有三个,一是 apiserver,它是k8s的大脑,k8s集群所有运转都要经过apiserver;第二个 scheduler,用来从后端的n多个工作节点node中按照特定算法选出一个或多个最合适的节点进行弹性伸缩pod,为什么是pod不是docker容器?因为K8S中最小的资源调度单元就是pod,pod其实就是一个包含多个docker容器的容器组而已;第三个 controller manager,用来控制刚刚选出来的后端节点启动或销毁pod,维持pod数量始终在我们规定的预期中。
2、还有一类是k8s的工作节点或运算节点worker,就是上面说的node。node中主要组件也有三个,一个是 docker,node是专门用来跑pod的,所以必须要有docker服务;第二个是 kubelet,kubelet接受master上的controller manager的指令,收到指令后告诉这个node上的docker服务,docker收到指令就会去启动或销毁哪些docker容器;最后一个是 kube-proxy服务发现,现在node上的这些pod跑起来了,但K8S集群终究是个私有网络或是内网,现在还不能被外部访问,我们要先把k8s的内部网络打通,k8s已经提供了解决方案,本例我们用flannel的cni网络插件,让每个node上都跑一个flannel的pod,救能把k8s内网互相打通。外部访问每个node的唯一的物理网卡指定ip,随后物理网卡端口映射到内网node上pod的端口,达到访问pod目的,后面会专门讲K8S的服务发现。
3、另外K8S还有个核心组件: etcd,看上图它是跑在master上,其实生产环境etcd集群是单独跑在其他节点上的。etcd可以看成K8S数据库,所有的master和node的节点信息,服务,K8S账户密码都在这里存着。
K8S就是一组服务器的集群,只不过是每个master和node上面都安装了上诉各自的三个组件,让我们能在master上统一调度这些node节点来跑pod。
首先 etcd存储了k8s(master)的认证账户和密码,还有注册进k8s集群的所有工作节点node的ip和主机信息。假如现在我想启动一个nginx容器组pod来提供服务:首先你用K8S客户端命令kubectl进行认证或者说登录k8s, apiserver会对你的账号和密码去etcd对比,通过的话apiserver马上让 scheduler去帮你找一个合适的node,scheduler就会根据特定算法去后端找一个特别合适的node,找到之后马上返回给apiserver,apiserver接着会去找 controller manager,让它去这个node上通知 kubelet让它运行一个nginx的pod,kubelet收到指令马上在本机找 docker服务,docker收到指令就会在本机启动一个nginx的pod。然后 kube-proxy给这个pod分配一个ip,让外界通过service或是ingress来访问这个nginx的pod(服务发现)。
不使用k8s之前:现在一个网站需要抗1w的并发,假设网站做的nginx反向代理引流。但是现在假设一个nginx只能抗2k的流量,所以我们需要跑五台nginx容器,前面说过K8S最小执行单元是pod,现在假设每个pod中只运行一个nginx的docker容器。这五个pod全跑在一个服务器肯定是性能没有保障。现在我们拿三个节点来跑,前两个节点跑两个pod,第三个跑只跑一个pod。现在抗1w并发肯定是没问题了。但是一段时间后第一个节点宕机了,那么它的docker进程也就没了,所以里面运行的这两个pod也肯定没了,你只能去检查这个节点为什么崩了,检查好了还要重启pod。 使用k8s:第一个节点崩了之后,k8s的controller-manager就发现,诶,之前用户给我规定好要维持五个pod为什么现在只有三个pod,它就会告诉apiserver,apiserver又去找scheduler让它选出一个或多个节点来跑还差的两个pod,scheduler自动帮你选出一个最合适的节点比如第三个节点,再通过apiser转发到controllermanager,controller-manager再到第三个node的kubelet,让kubelet通知到本地docker,最后docker再跑两个pod,现在就成了集群中第三个node跑三个pod,加上第二个node的两个,保证你始终是有五个pod,这就叫 k8s的容灾机制,允许你集群中的某个节点宕机。现在又来了,假设突然并发升到了1.5w,那怎么办?k8s会再在剩下的两个节点中继续选一个或多个再创建三个nginx容器(假设一个nginx抗2k)。
1、 自我修复。某个节点宕机之后,k8s会自动在其他节点跑这个宕机节点上所有死去的docker容器。注意修复是指维持docker数量。不是说你节点死机了k8s帮你修复这个节点(服务器)。
2、 服务发现,负载均衡。k8s自带负载均衡,第一个请求分到第一个nginx容器,第二个分到第二个容器,以此轮询。
3、 自动部署和回滚。部署服务只需命令,k8s会自动装依赖。回滚顾名思义就是新版部署到k8s之后出问题了,你可以轻松地回滚到上一个稳定的版本。
4、集中化配置管理和密钥管理。
5、存储编排。
6、任务批处理运行。
7、 自动弹性伸缩。
1、Minikube,仅供学习使用,无意义,它是个单节点的微信K8S。
2、 二进制安装部署(生产上首选,学习首选,因为自己配置的好排错)。
3、 kubeadmin,K8S的一种部署工具,相对简单,熟手推荐。
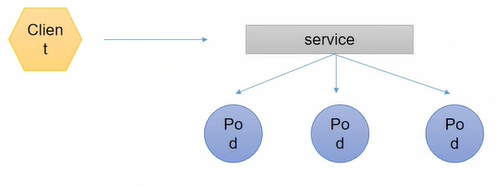
也就是前面说的kube-proxy组件,实现让外部访问node上跑的pod一共有两种方式,一是 service,二是 ingress。以service为例:K8S中service是pod的对外访问的统一接口,为什么要加这一层service或ingress呢,因为pod的生命周期可长可短,当pod被销毁重启后,K8S会自动随机分配ip,这时ip一定会变,如果外部客户端再次访问之前的pod时,如果这个pod被重启过是访问不到的,显然很不友好,而service或ingress就是为了解决这个问题。即外部只访问service或ingress,不需要管pod的ip是多少变没变。因为这个service或ingress的ip是定死的,就算pod的ip变了,service或ingress会在内部自动修改对应起来,可以把service或ingress跟pod的关系理解为映射。并且service或ingress收到请求后是RR算法(轮询)。那service或ingress怎么知道这个请求对应要去轮询哪些pod呢?所以K8S中又引入了 label标签,每个pod都有自己的label标签。pod和label是多对多,比如现在一个node上跑了八个pod,有三个pod我打label标签为v1,有两个pod我打标签为v2,最后三个pod我打标签为v2和v3。然后我在node上定义了两个service服务,service1只管v1和v2,外部访问service1会映射到v1和v2标签,service2映射到v3;当客户端访问service1的ip+port时,service1就会自动调度到标签包含v1和v2的pod上去,因为这里所有pod都带有v1或v2,那它就会对这八个pod来轮询给客户端访问,当客户端访问service2的ip+port时,service2就只会调度到最后两个pod上去轮询。注意到一点,现在service只能是ip+port,如果我想要相同ip+port不同的访问路径来映射到不同pod就没办法,这时,ingress就用场了,ingress跟service唯一区别就是,ingress能细到访问路径,相同ip+port不同路径能对应到不同的label标签。service和ingress都是pod的对外访问接口,当外部访问pod时,如果是访问service服务就用:127.0.0.1:8000,如果是访问ingress服务就用:127.0.0.1:8000/a/b/c。
K8S有三层网络:Node网络,POD网络,Service网络。
注意真实的物理网络就只有一个,就是Node节点网络,也就意味着我们在构建服务器的时候只需要一张网卡(下文我们只有一个网卡配置文件)。Service网络和POD网络都是虚拟网络,即内部网络。你想要访问POD就需要在service网络中去访问,service就会通过iptables或lvs的转换以及label标签达到访问pod的目的。
最后一个 namespace命名空间,比如一个场景,你是pod提供商,你在同一个工作节点启了10个pod,每个pod都有label对吧,并且这些个pod肯定是能通过localhost互相访问,假如现在腾讯买了你5个pod,网易买了你5个pod,但他们是两家不同公司,肯定是不希望相互之间访问。而这个namespace就可以实现业务隔离,为不同公司提供隔离的pod运行环境。另外还有一个场景,你也是跑了10个pod仅个人使用,你有五个pod用于线上环境,5个pod用于测试环境,如果测试环境能访问线上环境肯定也是不合理,所以第二个功能就能隔离线上、测试、开发环境。一句话namespace能隔离同一个工作节点上的pod。
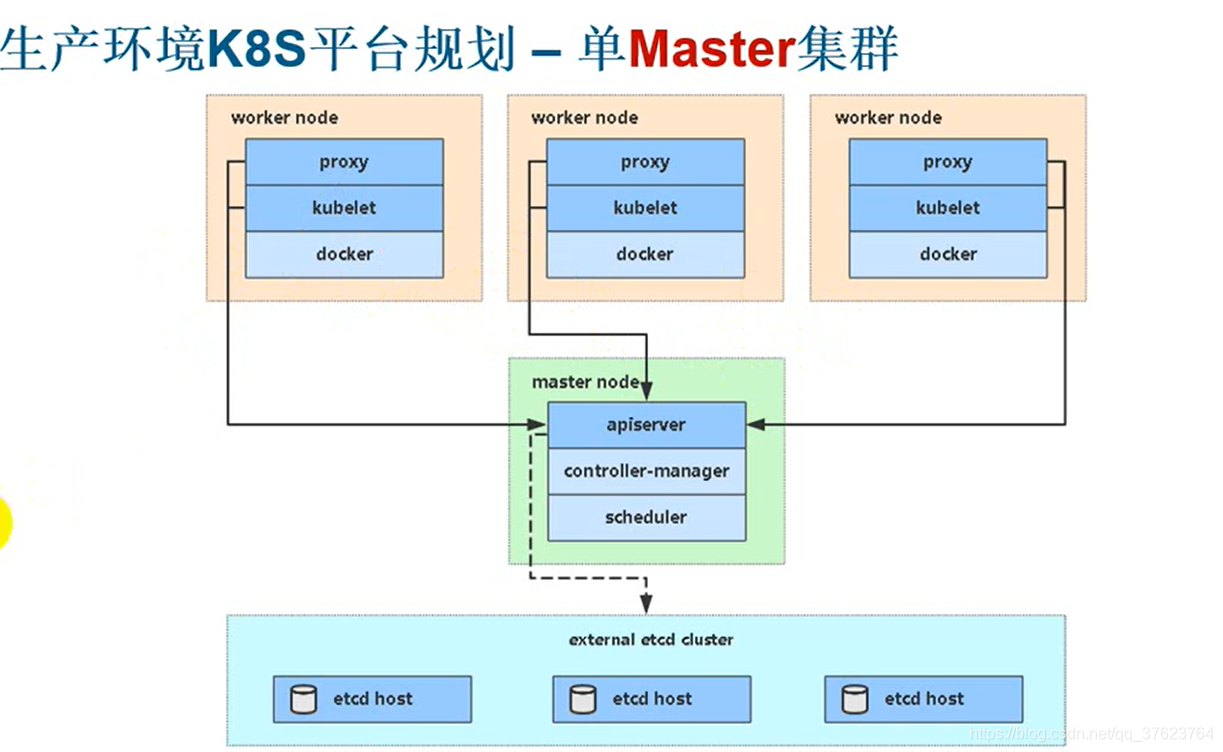
1、 测试环境K8S平台规划(单master):一台master接三台node再加三个etcd服务
2、 生产环境K8S平台规划(多master):三台master接两台LB(下图load balancer)负载均衡到三台node加三个etcd服务
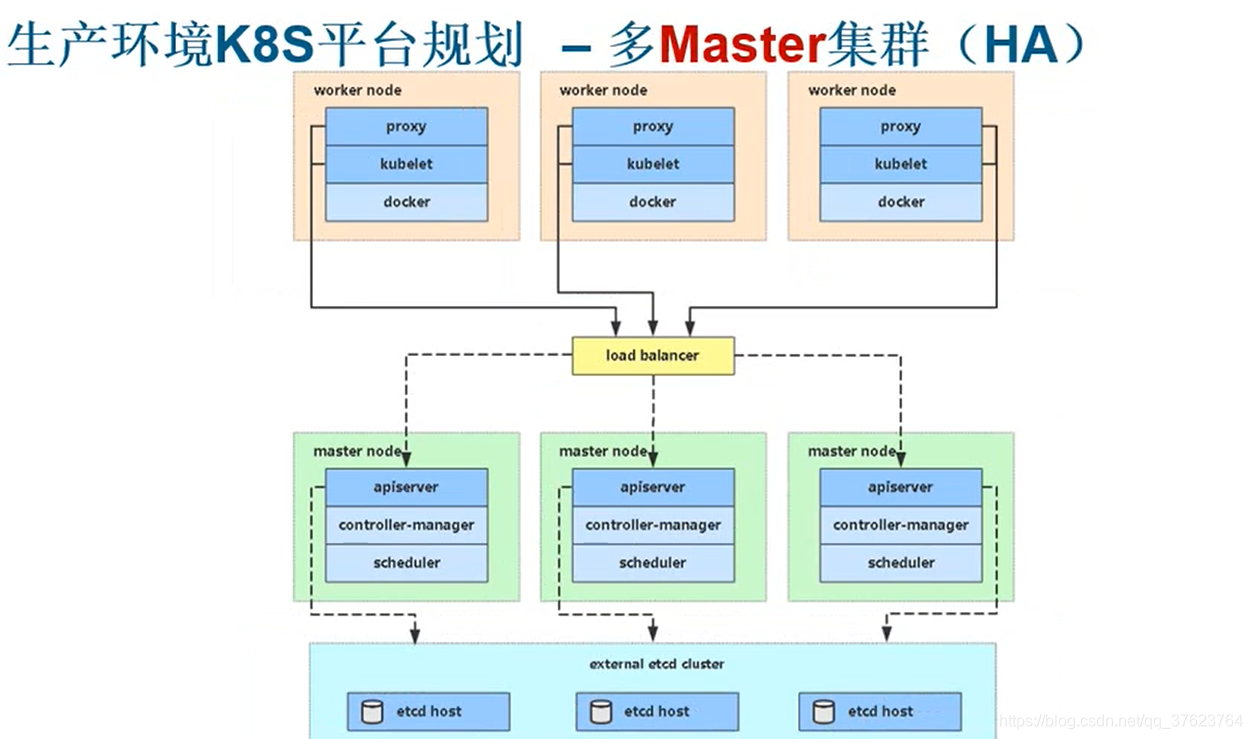
生产环境建议使用3个master节点,防止master宕机,node节点越多越好,前面说了node宕机不用怕,K8S会自动把宕机节点上的所有pod迁移到其他node上,这个迁移操作是master来自动调度安排的,所以master是不允许宕机的,这就是我们生产环境必需做master高可用的原因,就像你电脑的cpu,你的cpu挂了你电脑就废了。本例中我们用LB(load balancer)实现负载均衡,即node和master是通过LB来通讯的,让LB来接受node请求再调度到某个master来处理,而LB同样是为了防止单点故障所以是两个,最后etcd,etcd在生产环境中也 必须大于三台节点以上的奇数个防止单点故障,etcd会自动做主从,奇数个是因为选主节点是投票机制。
生产环境中每个master要保证16G内存,每个node要保证64G内存且越大越好,因为node是用来跑pod的。 本次条件限制我们的所有虚机都调为1G内存。我的笔记本是8G内存,我是这样安排的,两台master,两台node,两台LB,然后 etcd服务我就不单独开虚机,直接跑在master1和两台node上,我需要安装6个虚机。三台虚机都是2核1G,就算6台机内存占满了,也还留了2G内存给我的外部windows机。这六台虚机的内存设置太低了,只能用于实验跑几个pod,稍微多跑一点就要卡,或者直接导致集群崩溃。
从下一步开始,到第二十六步结束。我先只部署一个master加两个node,然后部署三个etcd服务在这三台节点上。第二十七步再开始实现master高可用,即再加一台master和两台LB。
1、下面链接有我这次离线部署K8S集群所需的全部压缩包。链接: https://pan.baidu.com/s/11AsmR_Zr0rqlioRjBGATnQ提取码: 1dh7 。
2、前面说了我先用单master加两个node一共三台节点来启一个k8s集群,安装虚拟机的时候要 一、选择桥接网络。二、内存1G,如果你的物理机内存大可以每台机2G。三、2个内核。四、50G硬盘。安装三台虚机是比较耗时的,所以我只安装一台虚机,取名叫k8s-master1,剩下的两台node用安装好的k8s-master1克隆出,改一下名称就行了。我们是桥接网络,所以虚机的ip要设置成跟我的windows物理机网段一致,我的物理机是192.168.0网段。centos镜像版本是centos7.7,点击阿里云centos镜像站点 http://mirrors.aliyun.com/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-2003.iso下载这个镜像来安装,安装系统就不用说了,挂载好了镜像之后,点开机跟着操作就行了。安装完master1的centos操作系统后,进去改网卡配置文件 vi /etc/sysconfig/network-scripts/ifcfg-ens33,文件如下:
TYPE=Ethernet # 网卡类型:为以太网
PROXY_METHOD=none # 代理方式:关闭状态
BROWSER_ONLY=no # 只是浏览器:否
BOOTPROTO=static #设置网卡获得ip地址的方式,我们直接静态ip定死
DEFROUTE=yes # 默认路由
IPV4_FAILURE_FATAL=no # 是否开启IPV4致命错误检测:否
IPV6INIT=yes # 现在还没用到IPV6不用管
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33 # 网卡物理设备名称,看你自己的网卡文件后缀
UUID=e06fa942-1b0e-426d-b262-ca2cd3375fa2 # 通用唯一识别码我们不一样
DEVICE=ens33 # 网卡设备名称, 必须和 NAME 值一样
ONBOOT=yes # 系统启动时是否应用此网卡,前面服务发现提到k8s真实的物理网络就只有一个,所以只需这一张物理网卡。
IPADDR=192.168.0.63 # 网卡对应的ip地址
GATEWAY=192.168.0.1 # 网关,最后一位是1,前三个是你的网段
PREFIX=24 # 子网 24就是255.255.255.0
DNS1=8.8.8.8 # 域名解析dns服务器
3、上面我master节点的网卡配置文件,我把master1的ip设为192.168.0.63,其余两台node机,克隆开机后只需进去换下上图的IPADDR保存退出,重启网络即可。顺便克隆出master2和LB1和LB2待用。然后 systemctl restart network重启网络,ifconfig命令在centos7不可用,用 ip ad查看本机master1的ip,发现就变成了设置的192.168.0.63。再去ping外部机和百度,现在你就可以在xshell上操作了,要方便很多,我在vmware上连个复制都没有。
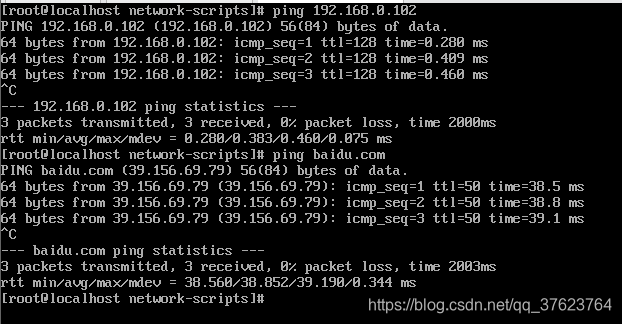
5、刚刚克隆出来的master2、LB1、LB2先放着。这里我们必需完成三台虚拟机(master1,node1和node2)的创建还要修改好ip(修改网卡后一定要重启网络),并且都能ping通外部主机和外网达到上图效果。另外再介绍一下我的虚机配置:
master1:虚机名为k8s-master1 IP为192.168.0.63。
node1:虚机名为k8s-node1 IP为192.168.0.65。
node2:虚机名为k8s-node2 IP为192.168.0.66。
master2:虚机名为k8s-master2 IP为192.168.0.64。
LB1:虚机名为LB-backup1 IP为192.168.0.67。
LB2:虚机名为LB-backup2 IP为192.168.0.68。
k8s版本:1.16, 安装方式:二进制离线安装。 虚机使用的操作系统:centos7.7。
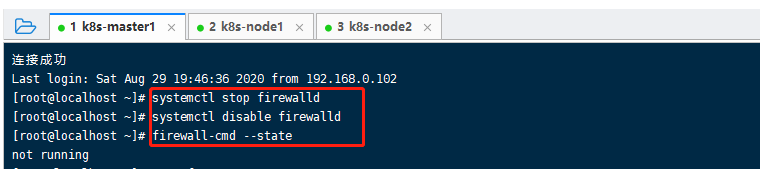
1、关闭三台机的防火墙以及防火墙开机自启动: systemctl stop firewalld以及 systemctl disable firewalld,最后在三台机上用 firewall-cmd --state检查一下三台机是不是not running。
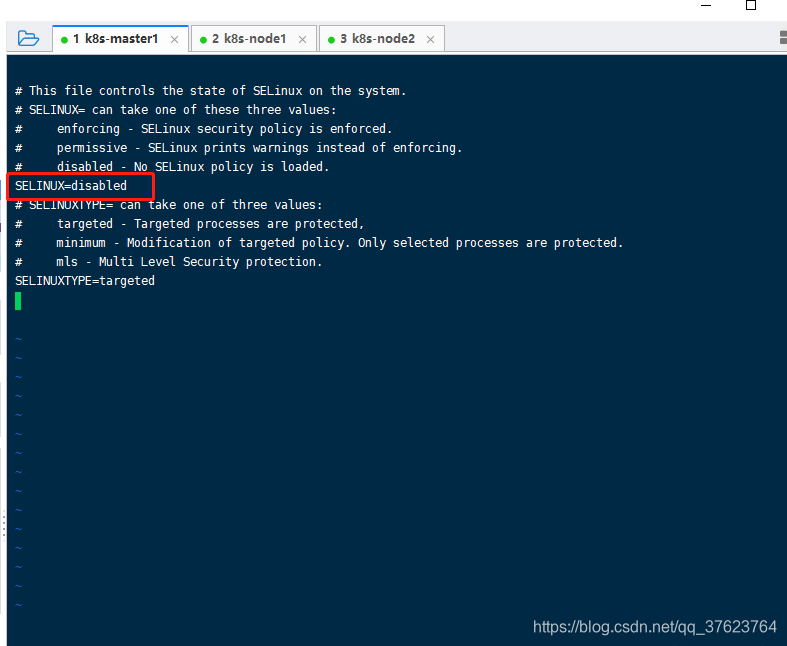
2、关闭selinux。
三个节点都执行 setenforce 0然后再 vi /etc/selinux/config修改画圈的这行,保存退出。
3、配置各个节点的主机名hostname,不要跟前面的虚拟机名混淆,虚拟机名只是描述没什么卵用。这一步需要在每台机上分别修改自己不同的名称,比如master1上执行 hostnamectl set-hostname k8s-master1,修改好之后你xshell关闭,重连一下三台虚机就会看到像这样的[root@k8s-master1]。
4、配置名称解析。
名字取好了,下一步在每台节点上修改hosts文件,让他们各自认识彼此的主机名, vi /etc/hosts,每个节点加上这四行,保存退出。
192.168.0.63k8s-master1192.168.0.64k8s-master2192.168.0.65k8s-node1192.168.0.66k8s-node2192.168.0.67LB_backup1# 这个是load banlance1的主机名先加上,不影响的192.168.0.68LB-backup2# 这是load banlance2的主机名先加上 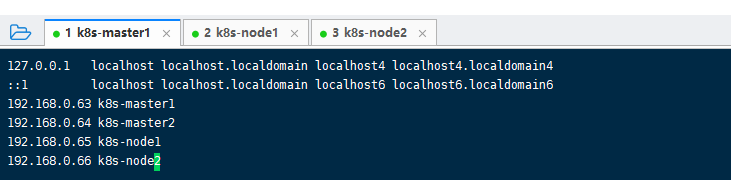
达到下面的效果,不用ip用主机名就可以互相ping通:
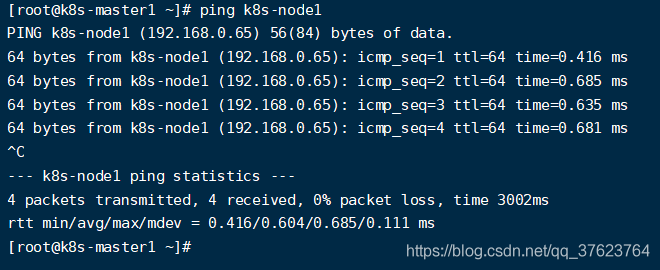
5、配置时间同步。
第一步配置master:选择一个节点作为时间服务器的服务端,剩下的作为客户端,一般选master节点,配置k8s-master1: yum install chrony -y,然后再 vi /etc/chrony.conf修改下图三个位置:
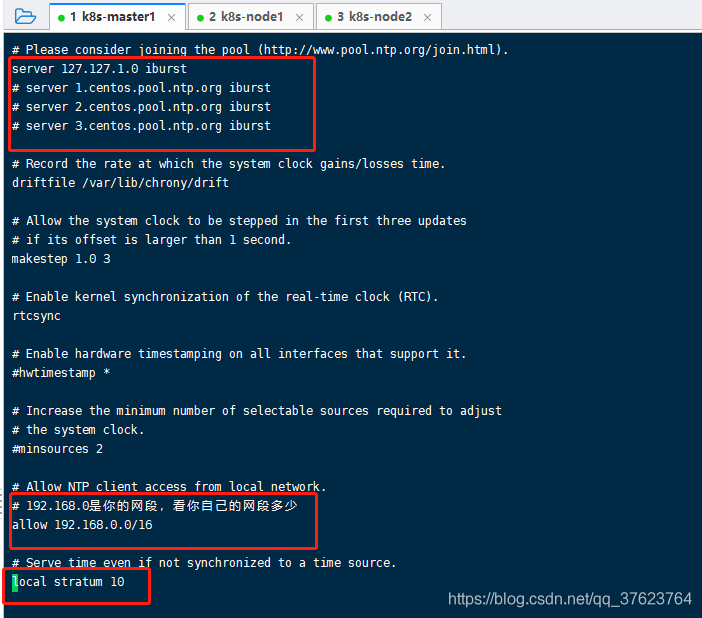
systemctl restart chronyd重启master机上的时间服务, systemctl enable chronyd设置开机启动,最后检验时间服务器是否正常启动: ss -unl | grep 123

第二步配置node:现在配好了master,再去配两个工作节点node,两台node上也是分别先安装 yum install chrony -y,然后 vi /etc/chrony.conf,但这两个工作节点只需要改一个地方,如下图改成主服务器master的ip即可。

两台node分别 systemctl restart chronyd重启时间服务,再 systemctl enable chronyd设置开机启动,最后分别用命令 chronyc sources来检验是否和master同步。如果是个*而不是?说明两个node已经和master同步,如果是?说明chrony.conf配置文件有问题。最后你在三台机执行 date校验时间是否一致。

6、关闭交换分区。
三个节点上分别执行 swapoff -a然后再 vi /etc/fstab,把最后一行注释掉,
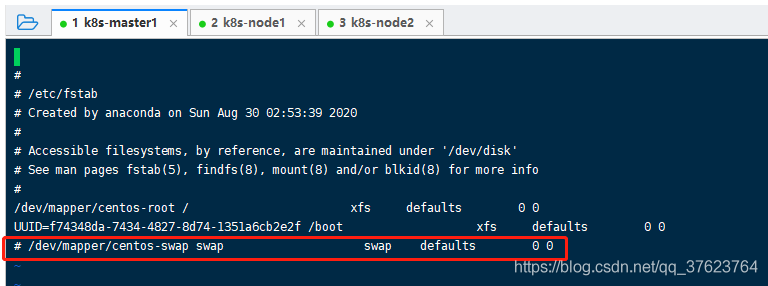
再分别执行 free -m检查交换分区是否成功关闭,整个命令我们经常用来查看剩余内存空间,比如下图我们还剩余650M:

因为 etcd和master通讯以及 node和master通讯都必须是https,所以部署之前首先要给etcd,master,node颁发ssl自签证书,我们先部署etcd服务,再部署master的三个组件和node的三个组件。关于加密:
对称加密:数据发送方和接收方用相同的密钥,隐患就是发送方会把密钥连同数据一起发过去,一旦被抓包,数据就被破了。
非对称加密:用公钥-私钥实现加解密,公钥保存在发送方用来加密数据,私钥保存在接收方用来解密,并且这一对密钥是一一对应的,一般都是有提供商。即加解密用的不是一个密钥,用这个公钥加密的数据只能由它唯一对应的私钥解密。
单向加密:只能加密,不能解密,比如MD5。
如果你想你的网站是https协议,关于ssl加密证书你要了解三点:
1、 ssl证书来源:可以网络第三方机构购买,证书加密级别越高,越贵,一般两三千,通常是公网上。另外你还可以自签一个证书,但必须是你用https在内网使用不是在公网上,通常用在公司内部,
2、 签证机构:(CA)
自建CA,可以用openssl和cfssl,本例中我们使用cfssl,也是k8s官方推荐的,比openssl更简单。让我们的k8s节点间通过cfssl来实现https访问。
3、 给xxx服务颁发证书。
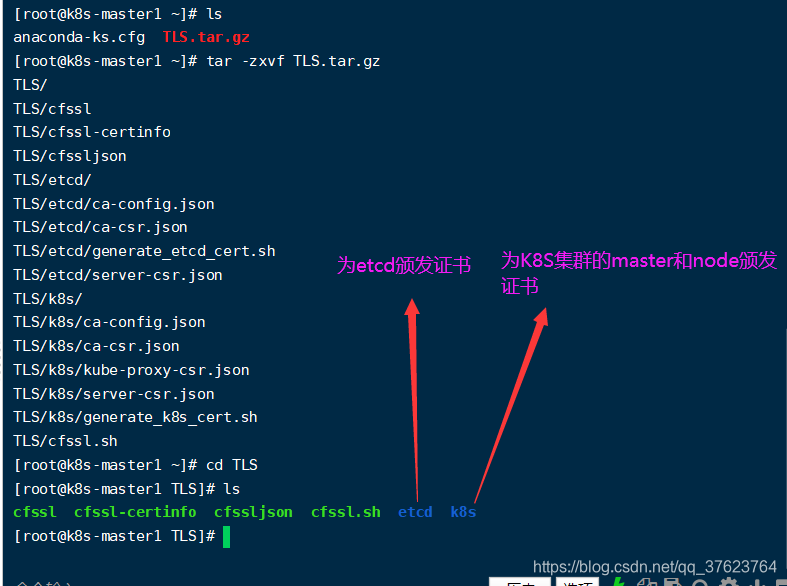
前面说了由于硬件配置问题,三个etcd服务我是跑在master和两个node上。我先在 master1的/root上传了网盘里的 TLS.tar.gz,这些包在上面我提供了网盘链接。先 tar -zxvf TLS.tar.gz解压,进入TLS,里边生成四个文件两个目录,一个是为etcd颁发证书,一个是为k8s的master和node颁发证书:
1、前面说过三个etcd服务是跑在master和两台node上,所以要在master和两台node上为etcd颁发,现在先在master。首先执行脚本cfssl.sh,执行之前先看一下这个脚本:
2、我们 ./cfssl.sh执行这个脚本,然后你可以去看一下/usr/local/bin,确实就有了这三个文件。然后我们cd刚刚解压生成的etcd目录, vi server-csr.json
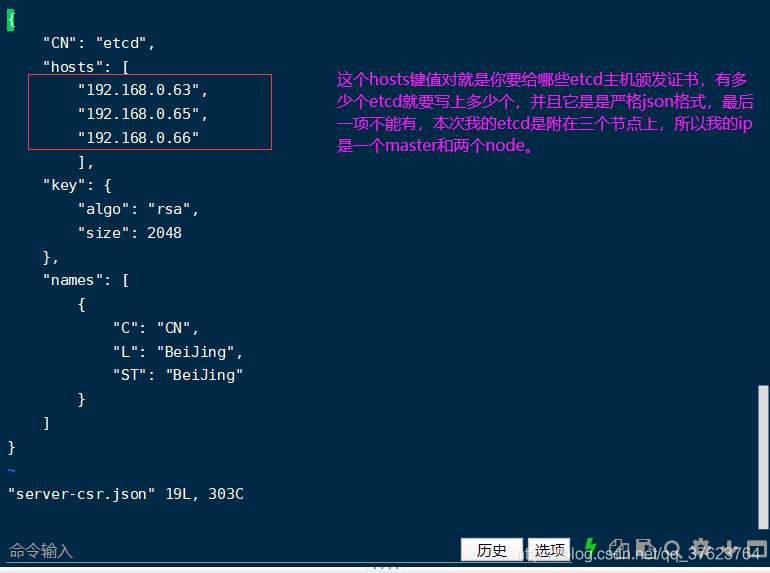
3、写明etcd所在节点ip之后,下一步向证书颁发机构申请证书,由于我们是自建CA(颁发机构),只需执行刚刚解压生成的 etcd目录里的 generate_etcd_cert.sh脚本,就能拿到证书文件了。
4、此时会生成四个颁发的证书文件,公钥加密私钥解密,任何人想向目前我们这个CA申请证书就必须携带这个生成的公钥 ca.pem,而另外两个server文件CA颁发好的证书,针对的就是我们前面设置的三个etcd的节点ip虚机。
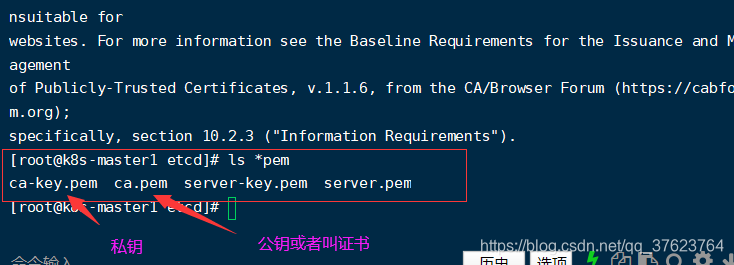
1、首先上传 etcd.tar.gz到/root目录下解压,会生成一个文件,一个目录 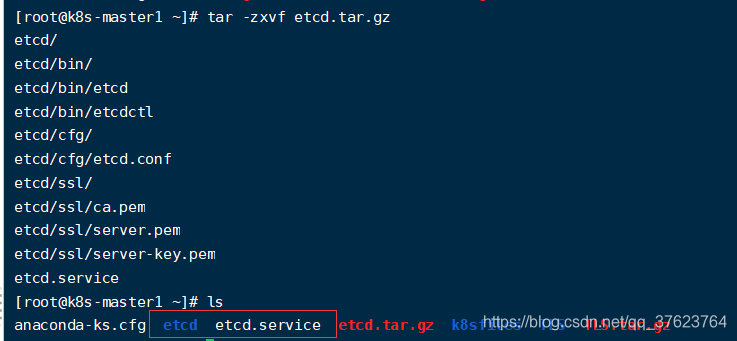
2、因为etcd.service文件指定了这两个位置,你要按照指定的位置移动一下这个文件和目录。执行
mv etcd.service/usr/lib/systemd/system
mv etcd/opt 3、紧接着就去修改这个 etcd.conf配置文件: vi /opt/etcd/cfg/etcd.conf
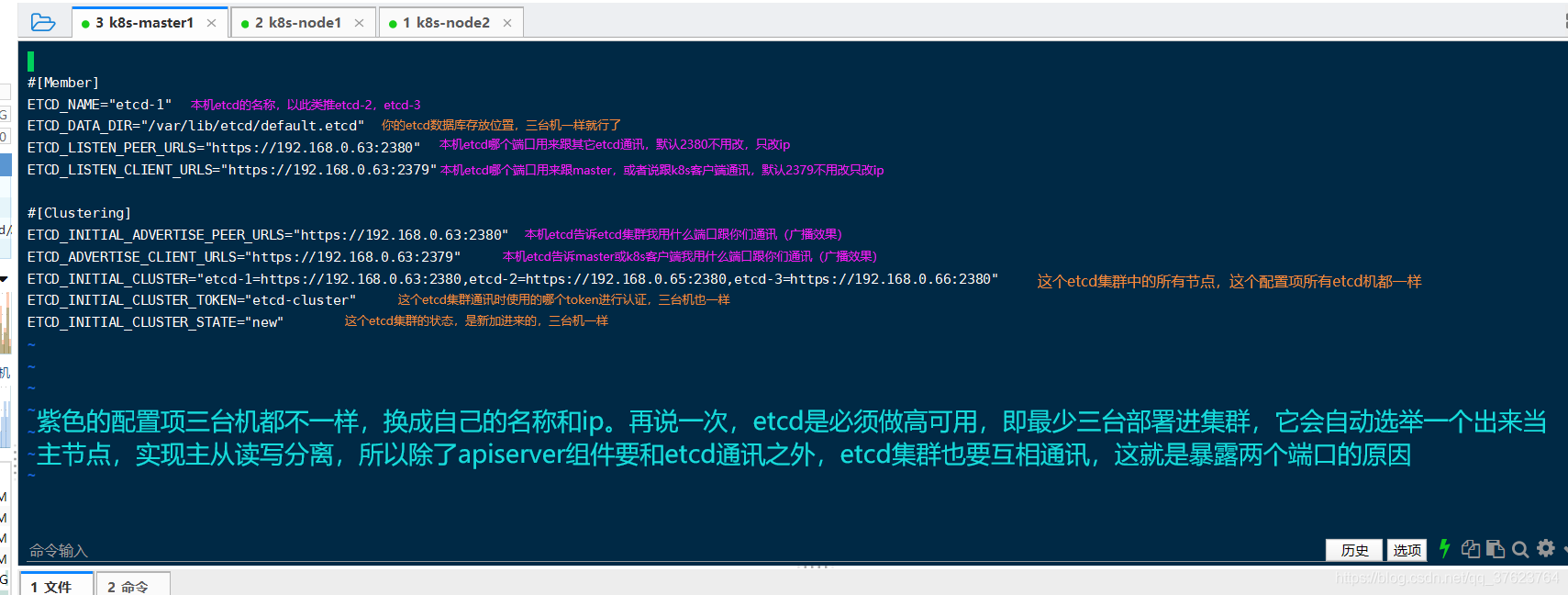
4、现在已经把etcd的配置文件改好了接下来去把上一步生成的etcd的其中三个证书文件放到etcd目录的ssl下。 \cp ca.pem server.pem server-key.pem /opt/etcd/ssl
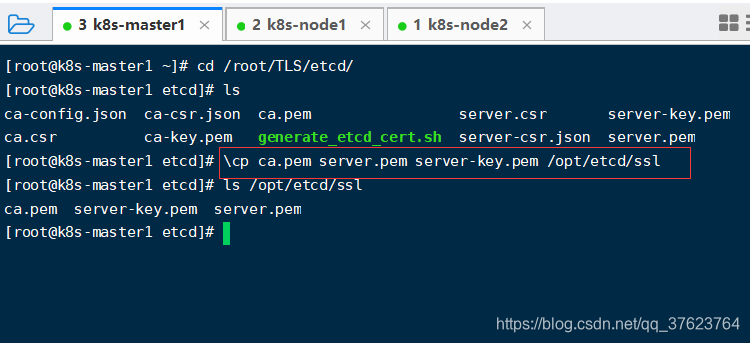
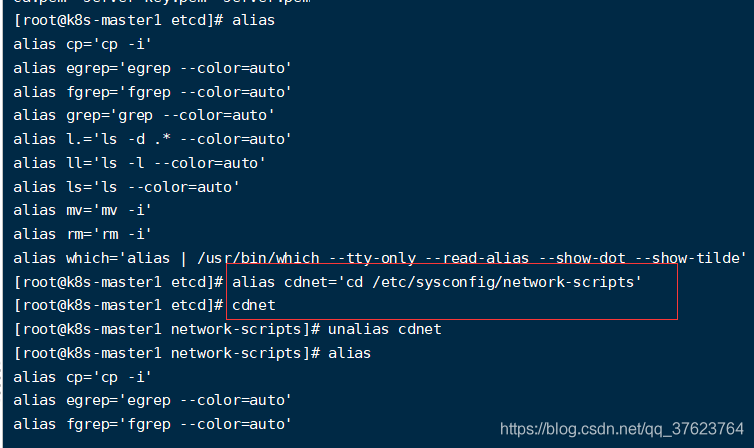
其中\cp加反斜杠的意思就是不使用linux命令别名,好处就是有覆盖时不提醒,因为cp实际是有别名的cp=“ap -i”,-i表示交互式有提示,linux命令别名有时会帮我们提升工作效率:用alias可以看到所有linux命令别名,你可以用unalias删除,也可以加反斜杠临时不使用,就用原生的,下图详解
5、 为两台node上的etcd颁发证书,生产环境是不会把etcd服务附加在master或node机上跑,我是因为宿主机硬件配置有限,所以才这样做。现在我们就已经给这个单master节点上跑的etcd颁发好证书了。其它两个node上给etcd颁发证书也是重复操作,没必要。所以我们直接在master节点上把以上生成好的etcd证书和管理程序拷到两个node上,然后在每个node改一下配置文件ip即可。不建议去重复操作,一是麻烦,二是80%出错导致etcd启动报错,直接在master用下面这四行命令:
scp/usr/lib/systemd/system/etcd.service root@k8s-node1:/usr/lib/systemd/system
scp/usr/lib/systemd/system/etcd.service root@k8s-node2:/usr/lib/systemd/system
scp-r/opt/etcd root@k8s-node1:/opt
scp-r/opt/etcd root@k8s-node2:/opt 6、然后在两个node机上分别修改etcd.conf配置文件, vi /opt/etcd/cfg/etcd.conf。修改里面的主机名和ip即可(上面有详细说明怎么改),配置改好之后我们就分别在三台机上执行一下两条命令。
systemctl start etcd (启etcd服务)
systemctl enable etcd(允许开机启动) 7、最后任意在一台机执行命令检查etcd集群是否启动成功,自己看情况改成你的节点ip:
/opt/etcd/bin/etcdctl--ca-file=/opt/etcd/ssl/ca.pem--cert-file=/opt/etcd/ssl/server.pem--key-file=/opt/etcd/ssl/server-key.pem--endpoints="https://192.168.0.63:2379,https://192.168.0.65.https://192.168.0.66"cluster-health 出现以下提示表示etcd已经在三台机上部署成功

1、前面两步已经给master和两台node上的etcd服务颁发了证书,并且已经跑起来了这个etcd集群。下面就要给master和node颁发证书了。先给master颁发,上传 tar -zxvf k8s-master.tar.gz到/root目录下解压,会生成三个文件一个目录,压缩包看前面网盘链接。
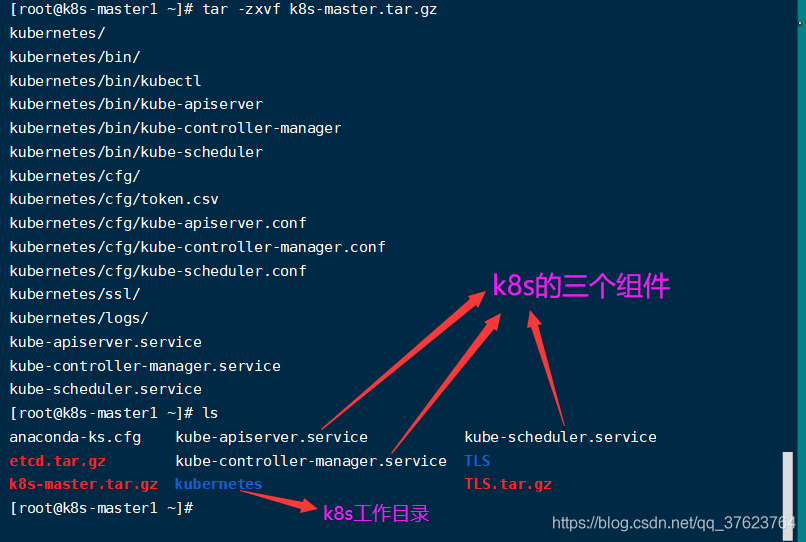
2、像之前给etcd颁发证书一样,先移动这3个文件和一个目录到k8s默认设定好去找的位置:
mv kube-apiserver.service kube-controller-manager.service kube-scheduler.service/usr/lib/systemd/system
mv kubernetes//opt 3、再进入之前解压证书生成的 TLS/k8s目录:
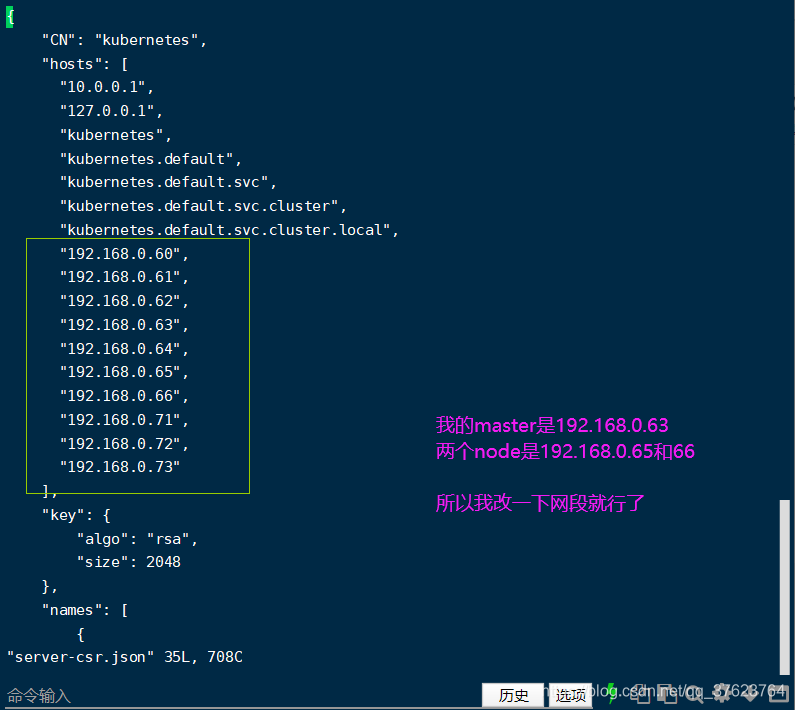
4、跟etcd一样,你也要改一下你为哪些node和master节点生成证书,里面ip可能有点多,因为我们只有三台机,不用删,全部改就行了不影响,保证你的三台机ip在里面即可: vi server-csr.json
4、现在再像之前一样执行里边的 generate_k8s_cert.sh脚本,就会生成k8s的自签证书,一共6个pem证书文件。然后把一下4个证书文件复制到ssl下:
cp ca-key.pem ca.pem server.pem server-key.pem/opt/kubernetes/ssl/ 部署master也就是部署master的三个组件。上一步为master颁发好证书之后,现在我们就去修改master上的三个组件的配置文件:
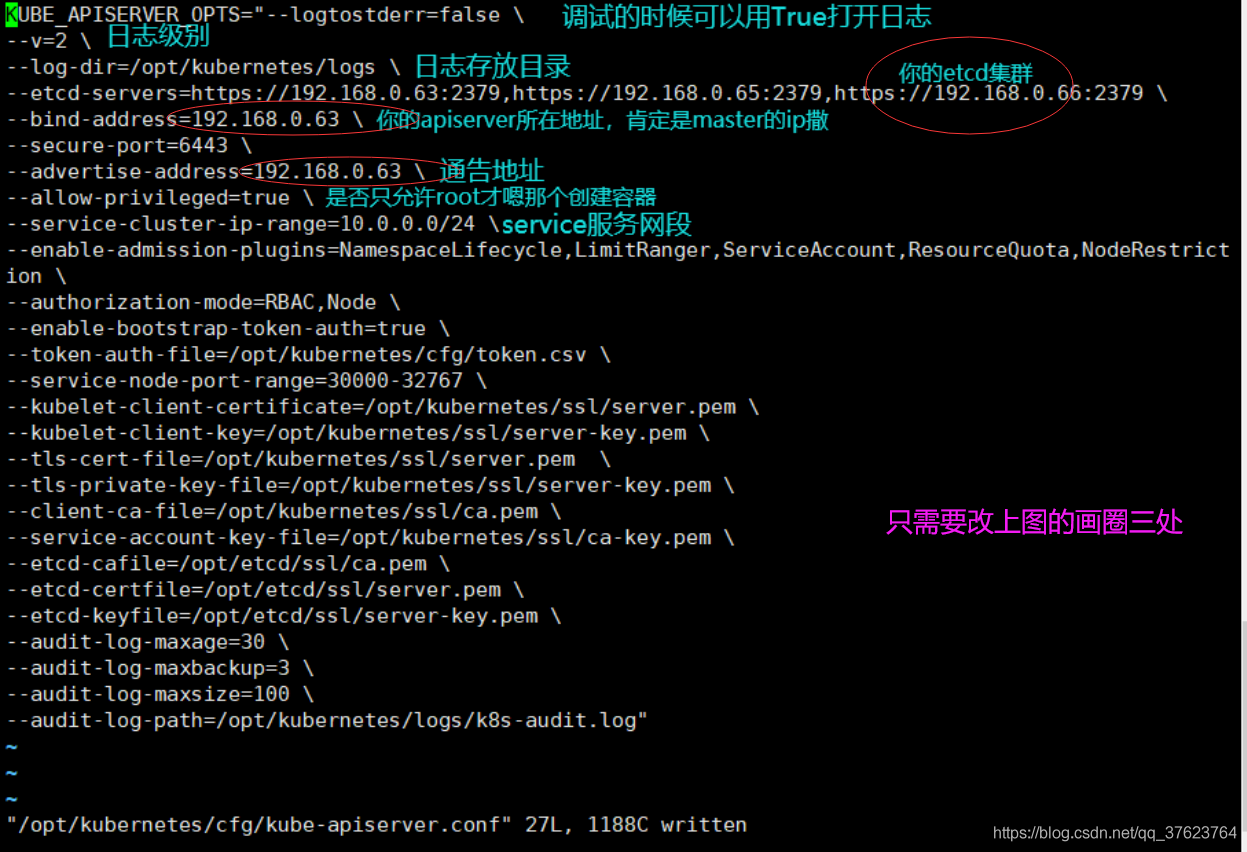
1、修改apiserver的配置文件(先只改三处): vi /opt/kubernetes/cfg/kube-apiserver.conf,我的etcd集群分别对应了我master和两台node的ip:
2、修改scheduler的配置文件(目前不需要改动): vi /opt/kubernetes/cfg/kube-scheduler.conf
3、修改controller-manager的配置文件(目前不需要改动): vi /opt/kubernetes/cfg/kube-controller-manager.conf
4、开启master上的三个组件服务(在master上执行):
systemctl start kube-apiserver
systemctl enable kube-apiserver
systemctl start kube-scheduler
systemctl enable kube-scheduler
systemctl start kube-controller-manager
systemctl enable kube-controller-manager 5、验证是否启动成功: ps aux | grep kube

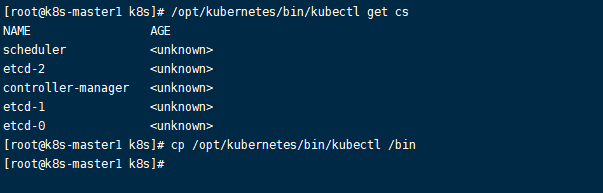
master上的所有日志文件都在/opt/kubernetes/logs下,可以去tail -f看一下三个组件的日志文件(.INFO结尾的),看下是否有异常。也可以执行 /opt/kubernetes/bin/kubectl get cs,如果出现下图信息,也表示你的配置是成功的,顺便把kubectl命令移动到系统bin目录下方便以后在master上操作node。
1】刚才在看apiserver的配置文件的时候,里边有两行,解释如下
--enable-bootstrap-token-auth=true \指定基于bootstrap可以做认证
--token-auth-file=/opt/kubernetes/cfg/token.csv \只给token.csv文件里面指定的用户进行颁发。
2】执行命令:
kubectl create clusterrolebinding kubelet-bootstrap--clusterrole=system:node-bootstrapper--user=kubelet-bootstrap 配置好了之后就可以自动地为访问kubelet的服务颁发证书。到目前为止master节点就完全部署好了。

我只介绍node1的部署流程,node2自己重复第22和23步,部署node其实也是部署node的三个组件: docker, kubelet, kube-proxy。我们切换到第一台node1,把网盘中的 k8s-node.tar.gz传到node1的/root下。
1、 安装docker(采用离线安装):先解压文件 tar -zxvf k8s-node.tar.gz
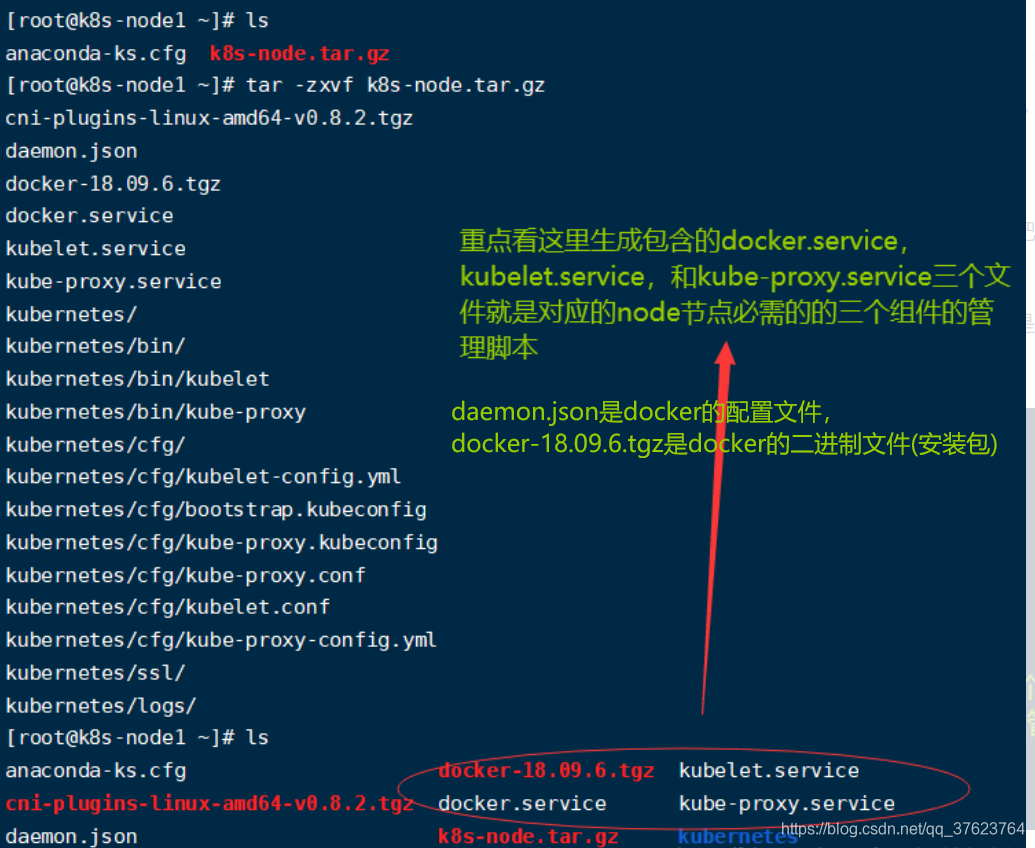
2、node上执行以下命令:
mv docker.service/usr/lib/systemd/system
mkdir/etc/docker
cp daemon.json/etc/docker/tar-zxvf docker-18.09.6.tgz# 解压dockermv docker/*/bin# 把解压的docker移动过去就代表docker安装好了(离线安装) 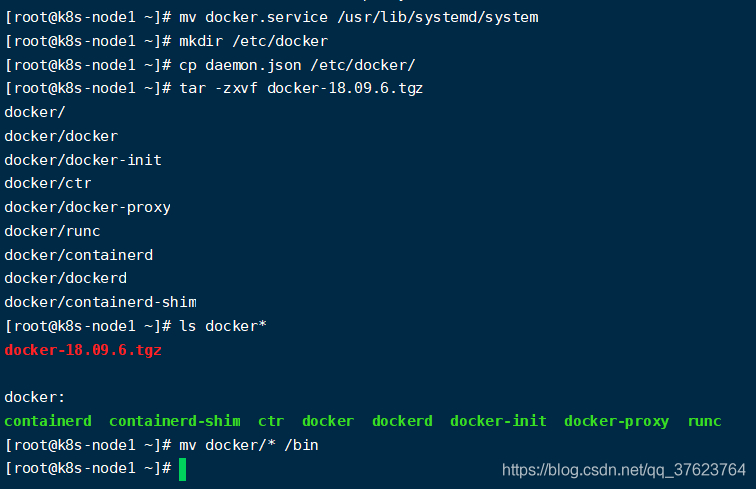
3、到目前为止docker组件就安装好了,现在启动docker服务并设置开启自启动
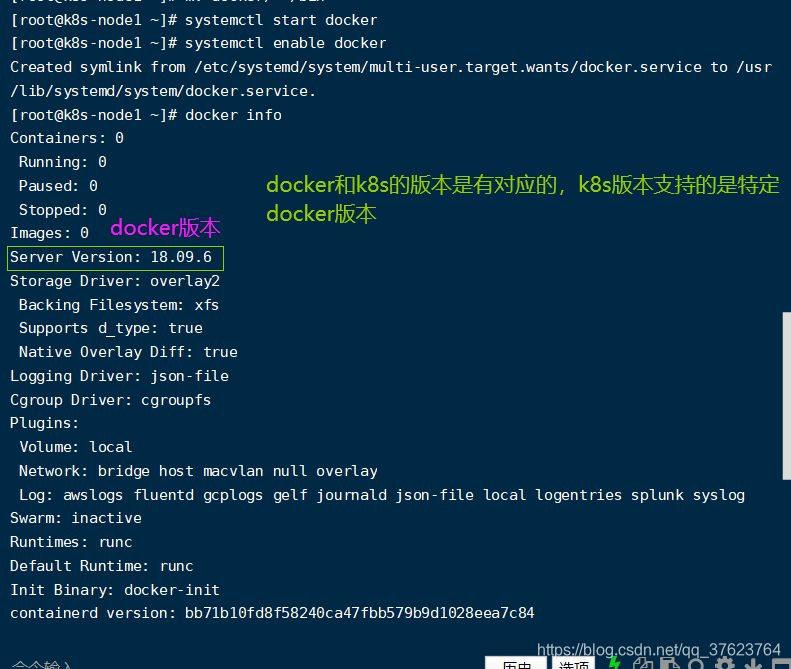
systemctl start docker
systemctl enable docker 再 docker info查看真启动情况:
4、现在node节点的第一个组件docker已经安装并启动了,接着把刚刚解压生成的node节点上剩余的两个组件管理脚本移动到system下,最后把刚刚解压生成的kubernetes目录放到 /opt下:
mv kubelet.service kube-proxy.service/usr/lib/systemd/system
mv kubernetes//opt 5、 给node颁发ssl证书:我们之前生成了两个证书目录etcd和k8s,一个是给etcd颁发,一个是给master和node颁发,前面已经给master颁发了,但现在node机上还没有,所以我们需要 在master机上!!把证书scp到node上,现在是在处理node1,后面记得在node2重复这些操作:
cd/root/TLS/k8s
scp ca.pem kube-proxy-key.pem kube-proxy.pem root@k8s-node1:/opt/kubernetes/ssl/ 6、来到这台node机上,修改kubelet和kube-proxy组件配置文件:
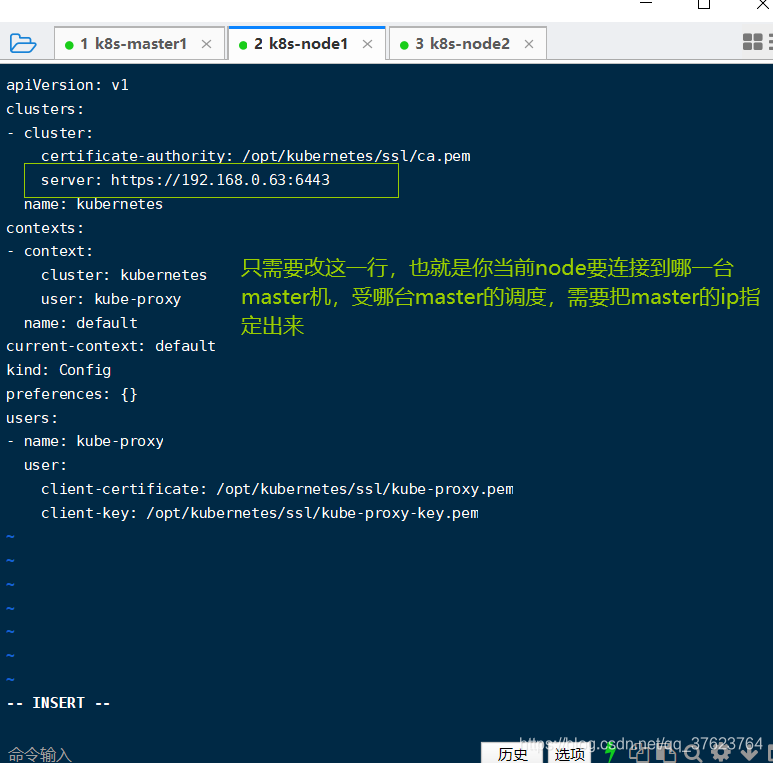
vi /opt/kubernetes/cfg/kube-proxy.kubeconfig
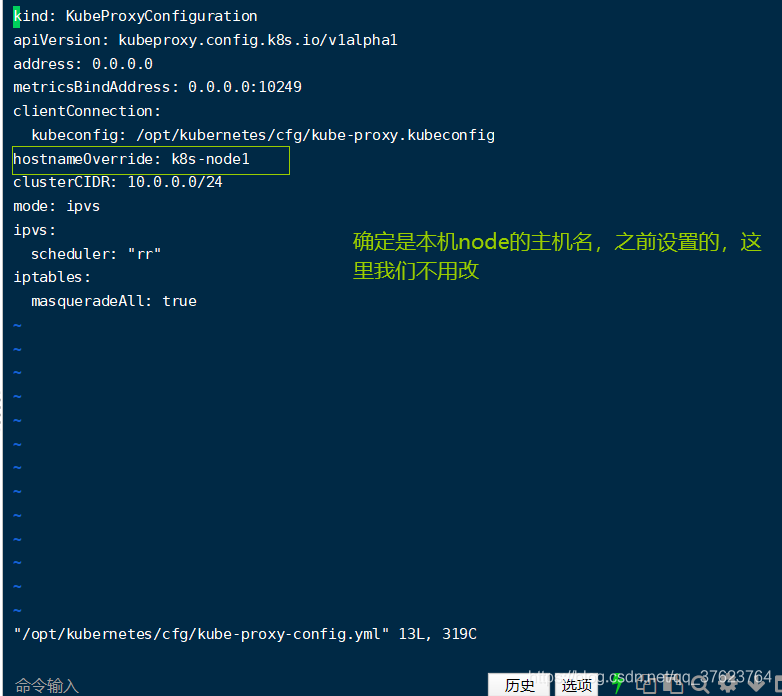
vi /opt/kubernetes/cfg/kube-proxy-config.yml
vi /opt/kubernetes/cfg/kubelet.conf
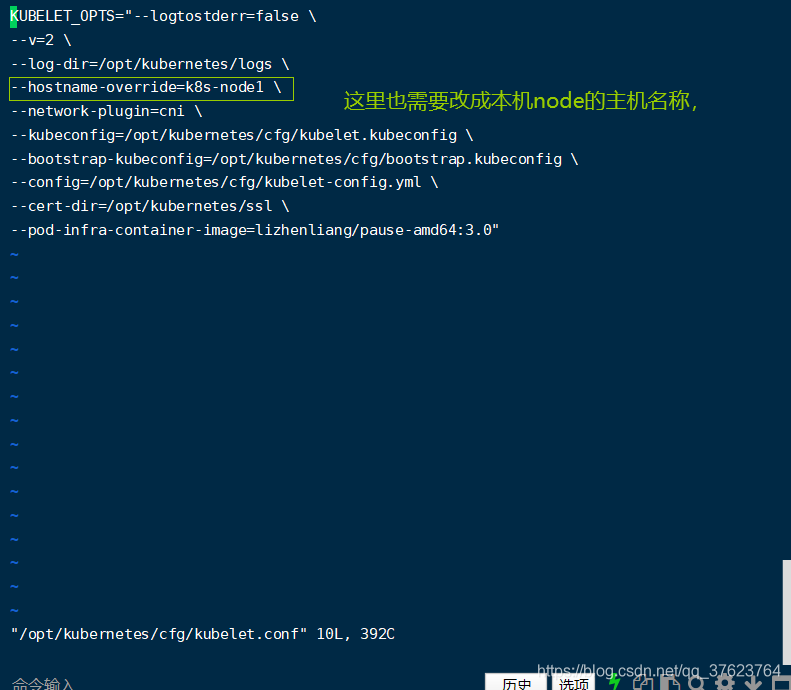
vi /opt/kubernetes/cfg/bootstrap.kubeconfig,这个是基于bootstrap自动颁发证书:
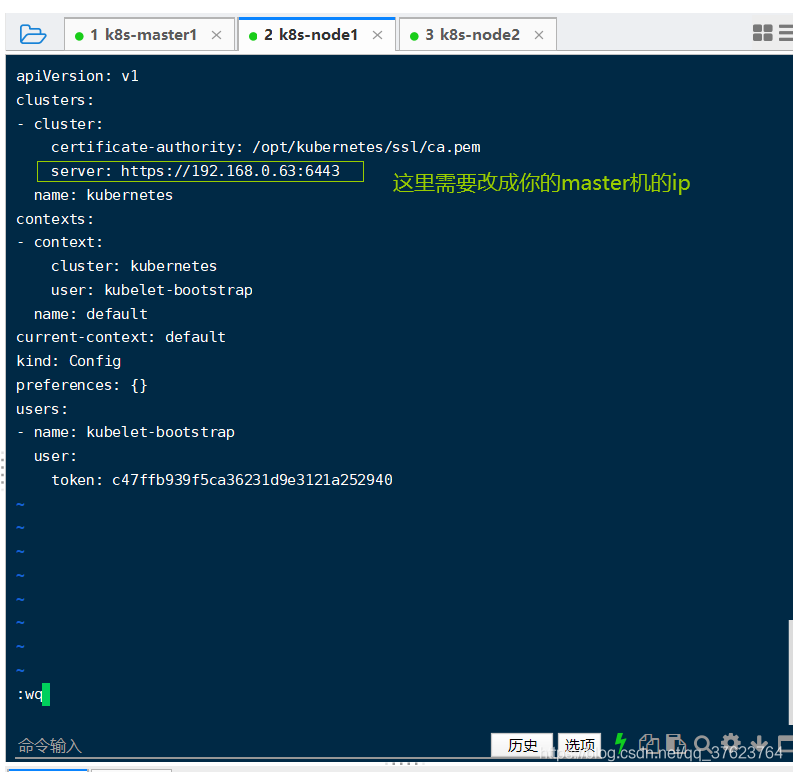
8、在node1上启动kube-proxy和kubelet服务,还要设置开机自启动:
systemctl start kube-proxy
systemctl enable kube-proxy
systemctl start kubelet
systemctl enable kubelet node上两个组件的日志跟master一样也在logs下,docker的日志是用 docker logs 容器来查看。比如现在 tail -f /opt/kubernetes/logs/kubelet.INFO就可以查看node的kubelet组件的日志,学会看这些组件的日志文件,对以后排错很有用:
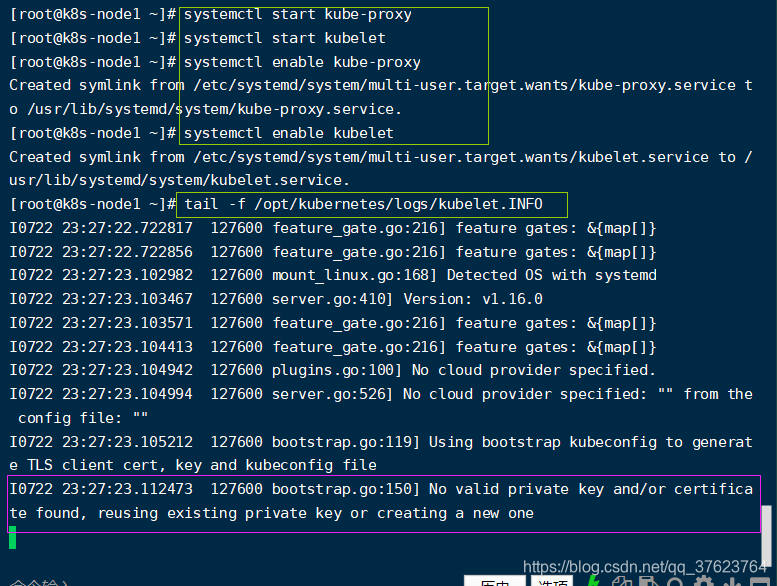
9、如果日志的 最后一行信息提示上图所示就表示node中两个服务启动正常,最后一行的意思是没有给node1颁发( 正确的)证书,因为node上的证书是从master拷过来的。所以现在我们需要在master上给node自动颁发证书(基于bootstrap),首先 在master机上查看是否有node1发过来的请求颁发证书的请求: kubectl get csr

收到请求后就执行 kubectl certificate approve 图中的token或者说NAME,然后再次查看请求就发现是已颁发的状态:

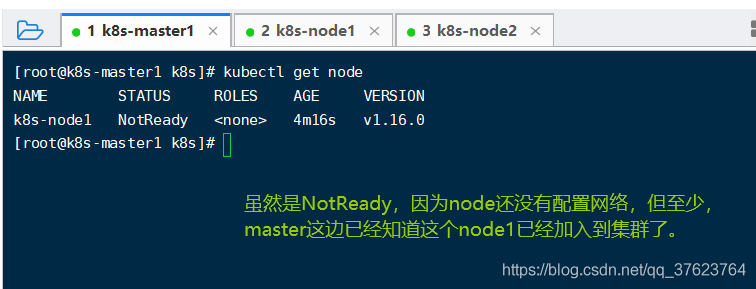
10、给node1颁发好正确的证书之后就能再master上看到node1节点了: kubectl get node
11、现在node1已经完成,现在再配置node2就重复操作就行了,从第二十二步解压k8s-node.tar.gz开始重复操作,注意:修改kubelet.conf配置文件中的主机名的时候,现在是k8s-node2。
12、node2也部署好三个组件之后,再次在master上执行 kubectl get node如果能看到两个node已经加入到k8s集群就说明你的K8S搭建没问题了。至于为什么是NotReady,因为现在我们没有把k8s内部网络打通,外部无论如何都访问不到node上的pod服务,所以是NotReady,等k8s网络打通了,这里就是Ready了,还好k8s已经帮我们提前想好了打通内部网络的解决方案。

13、查看两台node日志比如看kubelet组件:下图都提示没有在对应目录下找到cni网络插件。所以下一步就是给两台node安装网络插件,让上面的STATUS变为Ready。
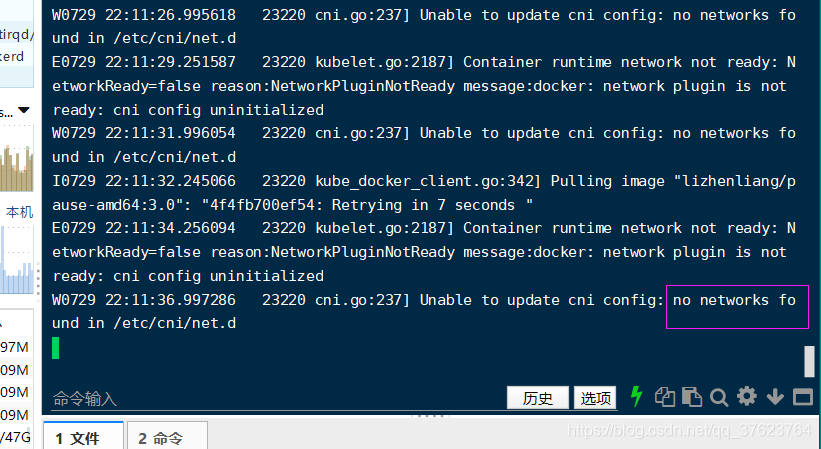
1、确认node上是否启用CNI插件:在node上执行 grep "cni" /opt/kubernetes/cfg/kubelet.conf(出现下图表示已启动)

2、在node上创建两个目录,然后解压之前解压k8s-node.tar.gz生成的cni插件压缩包到bin下:
mkdir-p/opt/cni/bin/etc/cni/net.d
tar-zxvf cni-plugins-linux-amd64-v0.8.2.tgz-C/opt/cni/bin/ 3、 配置docker国内镜像源,因为node节点是要跑pod的,肯定是要拉docker镜像的,pod是自动跑,我们只需在master上执行yaml文件或创建控制器。我们要修改docker镜像源为国内,要不然拉在线镜像太慢了。修改方式很简单只需要两步:修改两台node机上的 vi /etc/docker/daemon.json,然后全部删了修改成你的docker镜像源地址,我是用的自己的阿里云加速镜像地址,你可以设置网易163的如下。保存退出,执行 systemctl daemon-reload && systemctl restart docker,记住以后凡是重启K8S中配置文件被修改过的组件都要加reload使配置生效再restart。
{"registry-mirrors":["http://hub-mirror.c.163.com"]} 4、 一定要退到第1步把node2也做好才走这一步执行yaml文件, 现在在master机上!!执行yaml脚本kube-flannel.yaml,实现在node上安装和启动网络插件功能。首先把网盘中的 YAML上传到master的/root下。cd进YAML执行 kubectl apply -f kube-flannel.yaml命令,k8s中启动pod的方式之一就是执行yaml文件,也是我们最最常用的方式,这个yaml文件中就可以指定把pod启动在哪个名称空间以及pod暴漏的端口。这个命令的作用就是让两个node下载镜像,启动容器。这一步跟你自己在两台node上docker pull这个yaml文件中的镜像下来run是一个效果,只不过yaml文件能在master直接控制node启动pod以及怎么启动。
5、在master上执行 kubectl get pods -n kube-system查看namespace为kube-system(这个yaml文件指定的)的所有pod,这里就会出现两个pod,一个是node1上的一个是node2上的,这两个pod就是我们说的cni网络插件。如果yaml文件执行成功,两个pod的STATUS就会变为Running,否则为Pending。再次执行 kubectl get node查看集群中的node状态,就能看到两个节点已经变为了Ready。注意执行yaml文件后,在node上启动pod这个操作受限于网络。我们已经给两个node都换成国内163docker镜像源,所以基本一分钟就搞定了。用yaml文件来跑pod,如果要停止pod,要使用 kubectl delete -f kube-flannel.yaml删除,直接 kubectl delete pod -n 名称空间 pod名称是删不掉的。包括以后用创建控制器的方式来启动pod,也是删控制器才有用,比如: kubectl delete deployment 控制器名称,原因就是你删pod,会自动新建副本,这是k8s的容灾机制。成功后如下图:可以看到两个pod正常启动。除了get node之外,其它k8s的名词比如svc,pod,deployment等的get和delete都是需要指定名称空间的,不用-n指定名称空间会默认在default名称空间。

6、最后授权master的apiserver可以访问node上的kubelet,在master上执行如下命令:
kubectlapply-f apiserver-to-kubelet-rbac.yaml 这23步做完之后,包含一台master和两台node以及(跑在这三台机上的)三个etcd服务的K8S集群就搭建成功了,后续有异常的话有个简单的解决办法,重启master上的三个组件(kube-apiserver,kube-controller-manager,kube-scheduler),node上的三个组件(docker,kubelet,kube-proxy)。k8s说白了就是这六个组件在运作。
1、K8S集群搭建成功之后,我们就不需要去管node节点了,一切都在master机上操作。本例中我们用master来调度集群中的两个node跑nginx的pod,并且实现K8S的滚动更新和回滚。nginx容器镜像版本使用1.7.9和1.8,前面我们修改docker的镜像源为国内163,我们就用官方的nginx镜像。
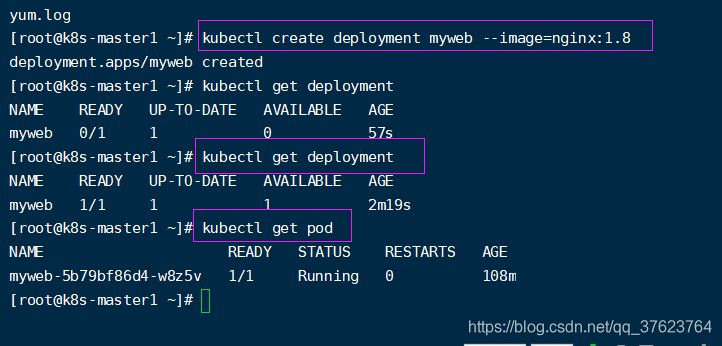
2、除了执行yaml文件可以启动pod,还有一种不常用的方式:手动创建控制器来启动pod,现在我们分别去两个node上pull下来nginx的1.8和1.7.9版本两个镜像。由于有加速地址,是很快就能拉下来的。然后再回到master执行 kubectl create deployment myweb --image=nginx:1.8,这个命令就相当于 kubectl create deployment myweb --image=nginx:1.8 -n default,这个命令的意思是创建了一个名叫myweb的deployment控制器,让它去找个node在默认名称空间default( 你也可以-n指定一个名称空间)启一个1.8版本nginx的pod。控制器除了deployment还有其它好几个,后面会单独说。然后过个一两分钟执行 kubectl get deployment,发现deployment启动了,执行 kubectl get pod发现pod也启动好了。
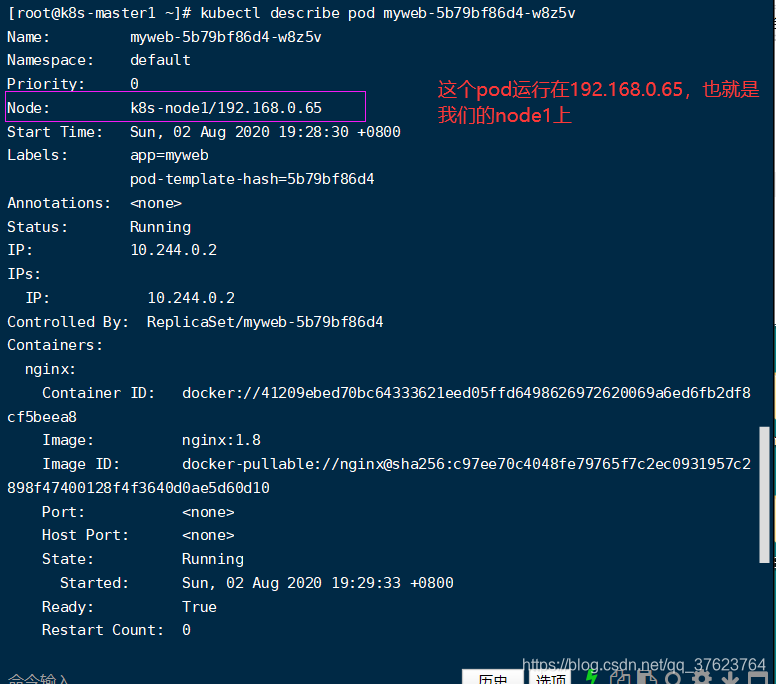
3、用 kubectl describe pod NAME,这个NAME就是执行kubectl get pod展示的第一列pod信息,上图开头的myweb就已经表示这个pod是由哪个名称空间的deploment启动的:下图能看到这个pod运行在node1上,这个查看pod详细信息的命令在以后pod出问题排错时会经常用到。为啥不是node2呢,这是scheduler自动按特定算法选出来的不是我们定的,具体流程上一篇博文详细讲过。你还可以继续 kubectl create deployment web1 --image=nginx:1.7.9再创建一个名为web1的控制器并且让它启动一个1.7.9版本nginx的pod,这里我们就先只启动一个。
4、我们最常用的就是这个kubectl,它可以get node,get deployment,get pod。最后两个命令的最后都可以加-n 来指定查看哪个名称空间,不指定的话pod的默认名称空间是 default,deployment的名称空间是 kube-system。上文有专门讲过名称空间作用。用 kubectl get ns可以查看现有的所有名称空间。
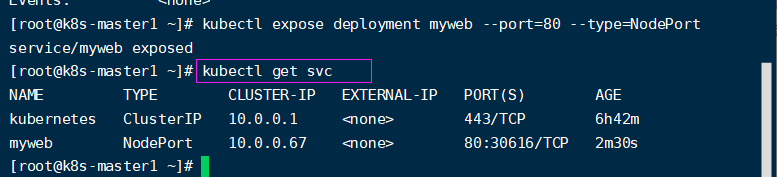
5、那我们怎么样能访问这个node1上pod跑的nginx页面呢?你看下图那个ip就是我们k8S给pod分配的ip,这个ip是个内网ip。回想一下我们用docker跑nginx的时候,是用 -p来让宿主机的某个端口来映射到nginx容器的80端口,达到我们访问nginx容器的目的。我们前面讲过服务发现,就是service和ingress,下面我们就用service的方式,在K8S中也是要暴露pod的端口到物理机。暴露名为myweb的控制器启动的pod上的80端口,因为nginx的默认端口是80,除非你改了nginx的配置文件,那我们这儿跟着改就行了。执行 kubectl expose deployment myweb --port=80 --type=NodePort,然后K8S就会把80映射到node的一个随机端口。用 kubectl get svc就能查看到底映射到了虚机的哪个端口(svc代表service):下图看到是30616
6、访问任意一台node的ip加30616端口,就能看到nginx的welcome页面了。为什么明明看到pod是跑在node1,node2也能访问,这就是集群,所有工作节点都在k8s集群中提供服务。k8s的node默认只能向外界暴漏的端口范围为 30000-32767,就算是随机端口也是在这个范围。所以以后你自己写yaml文件创建service指定暴漏端口来发布服务的时候要注意这个端口范围。
1、K8S官方的 dashboard,不建议(这一步你可以不做):
先安装dashboard,在master上 cd YAML,然后 kubectl apply -f /root/YAML/dashboard.yaml,yaml文件方式启动pod会自动暴漏端口,k8s就会自动去node上下载镜像启动pod,这个pod的默认名称空间为kubernetes-dashboard。 kubectl get pod -n kubernetes-dashboard查看pod启动状态,再用 kubectl get svc -n kubernetes-dashboard来查看pod暴露到了node的哪个端口。因为我们在两个node上都修改了docker镜像源,随便它调度到哪个node都很快。所以不到一分钟pod就跑起来了。 

最后也是用两个node的任意一个ip(也是要用109或104才行)的30001端口访问(记住一定要用https协议)
2、第三方的 kuboard,也是推荐的,功能更全面:把网盘中的kubectl apply -f start_kuboard.yaml文件拿到master上来。
3、然后就可以执行(k8s集群搭建好之后所有调度都在master上) kubectl apply -f start_kuboard.yaml,这个yaml文件中指定了在kube-system名称空间下,并且指定启动在node1上,如果你的主机名称不是k8s-node1需要进去该一下,执行完了之后就 kubectl get pod -n kube-system查看pod执行状态,还可以 kubectl describe pod -n kube-system pod的NAME确认到底是不是跑在我们规定的node1上。
4、最后:我们执行 kubectl get svc -n kube-system查看映射到了哪个端口,其实不用看,就是在yaml文件中就能看到,映射到了node1的32567端口。访问任意node节点的ip加32567端口:
5、显然,下一步我们就需要生成token完成登录。只需在master执行这个命令即可,会马上返回一个token,这个token就是我们的k8s令牌。
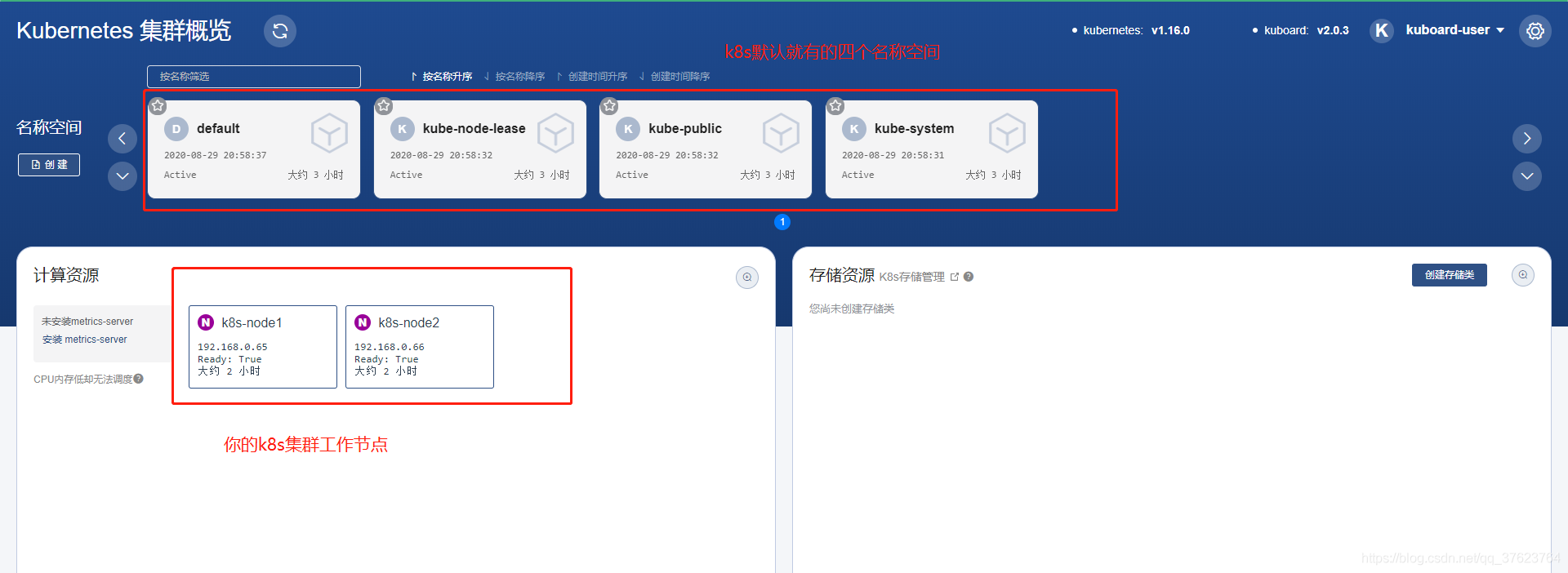
kubectl-n kube-system get secret $(kubectl-n kube-system get secret|grep kuboard-user|awk'{print $1}')-o go-template='{{.data.token}}'|base64-d 6、使用token完成登录:进来之后你就会看到有这四个名称空间, 是k8s默认创建好的。你执行yaml文件或创建控制器时用-n指定一个不存在的名称空间,k8s就会在这儿给你生成。我们前面用deployment的方式手动创建了一个名叫myweb的控制器,让它在default名称空间中(因为我们启动时没有指定名称空间)跑一个nginx的pod。你现在点default进去就能看到。
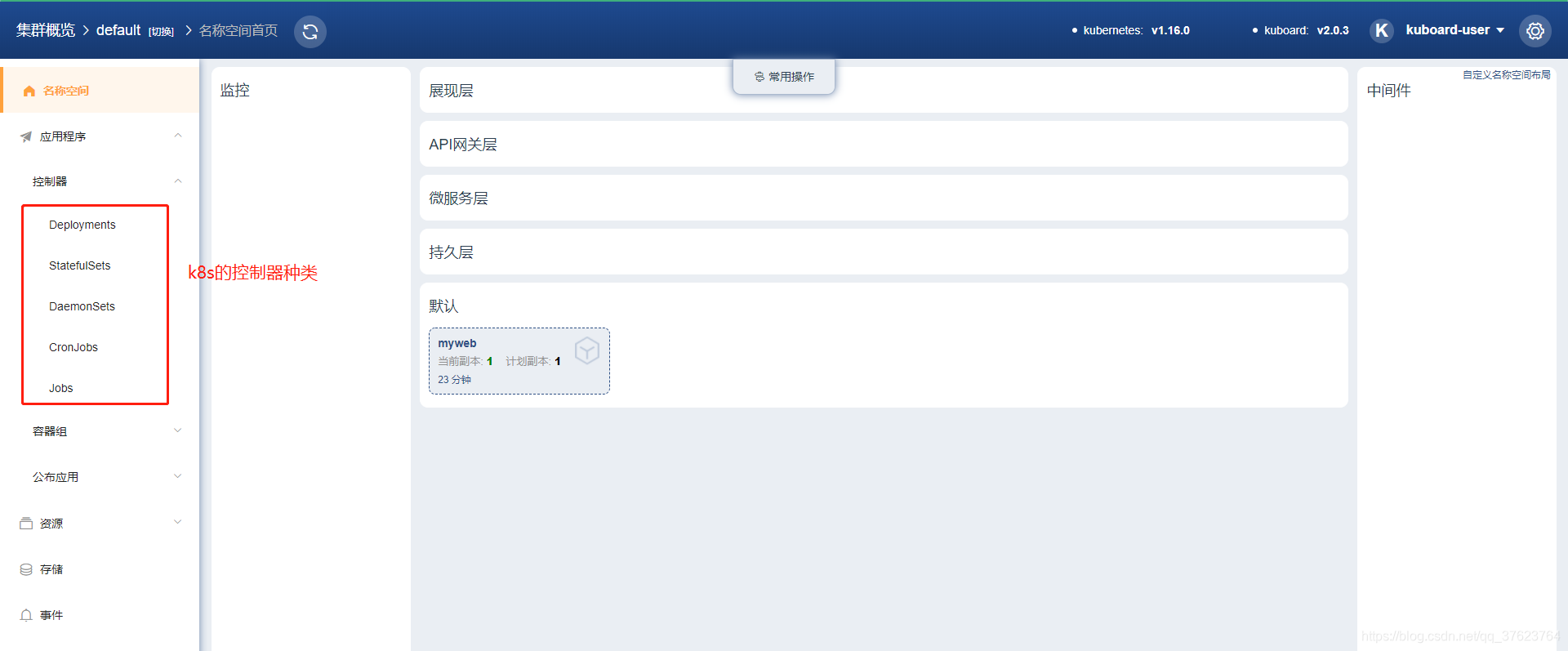
7、前面我们都是通过yaml文件或deployment来创建pod,现在有了图形页面我们还可以直接在页面上创建pod,并且kubeboard还支持像gitlab上的CI/CD持续集成,你的代码更新之后自动生成更新后的yaml文件,然后你再来k8s页面上删除pod,k8s就会重启一个pod达到更新代码功能的效果。
比如我们在web上用deployment来启动一个nginx的pod:
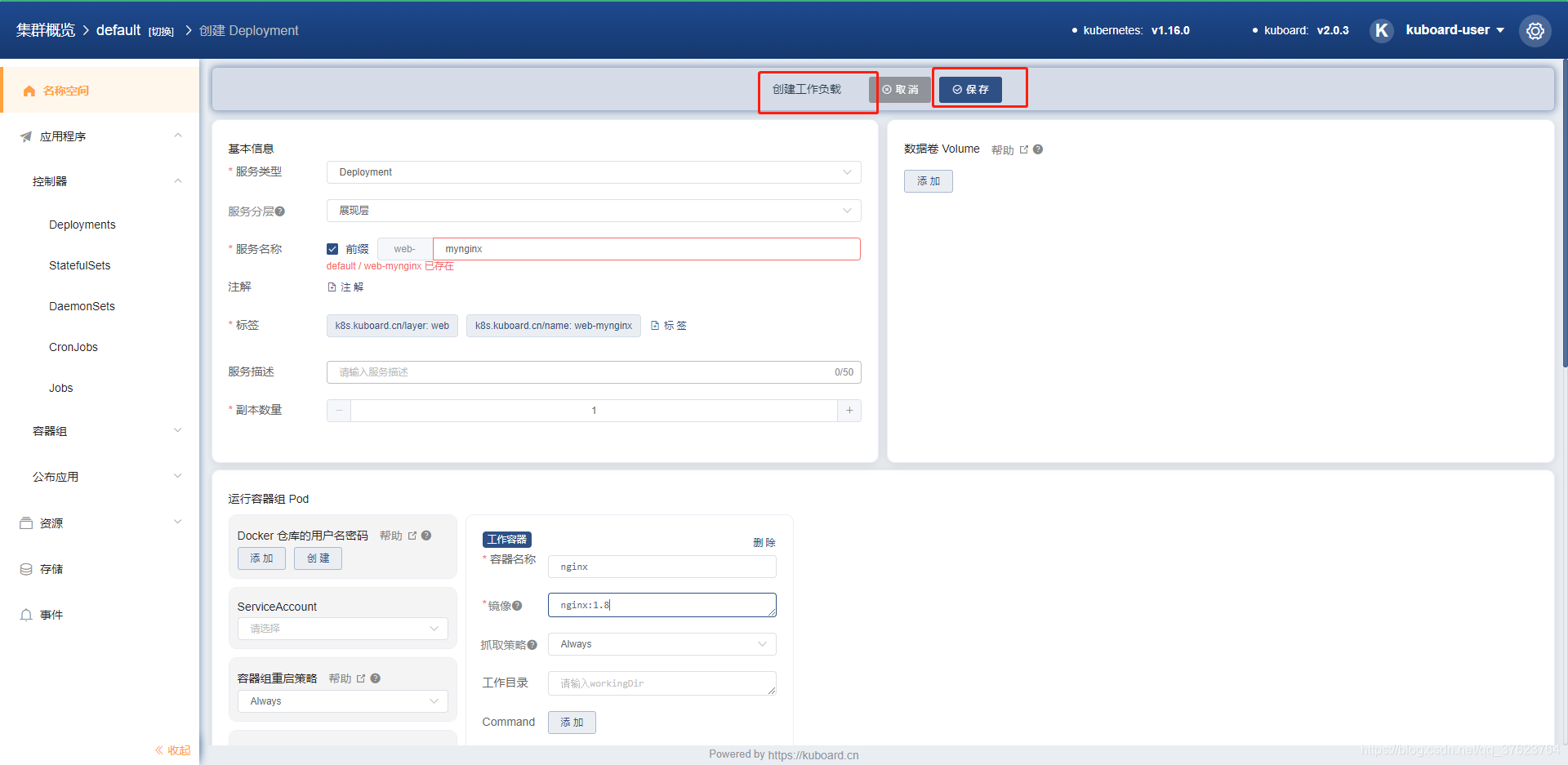
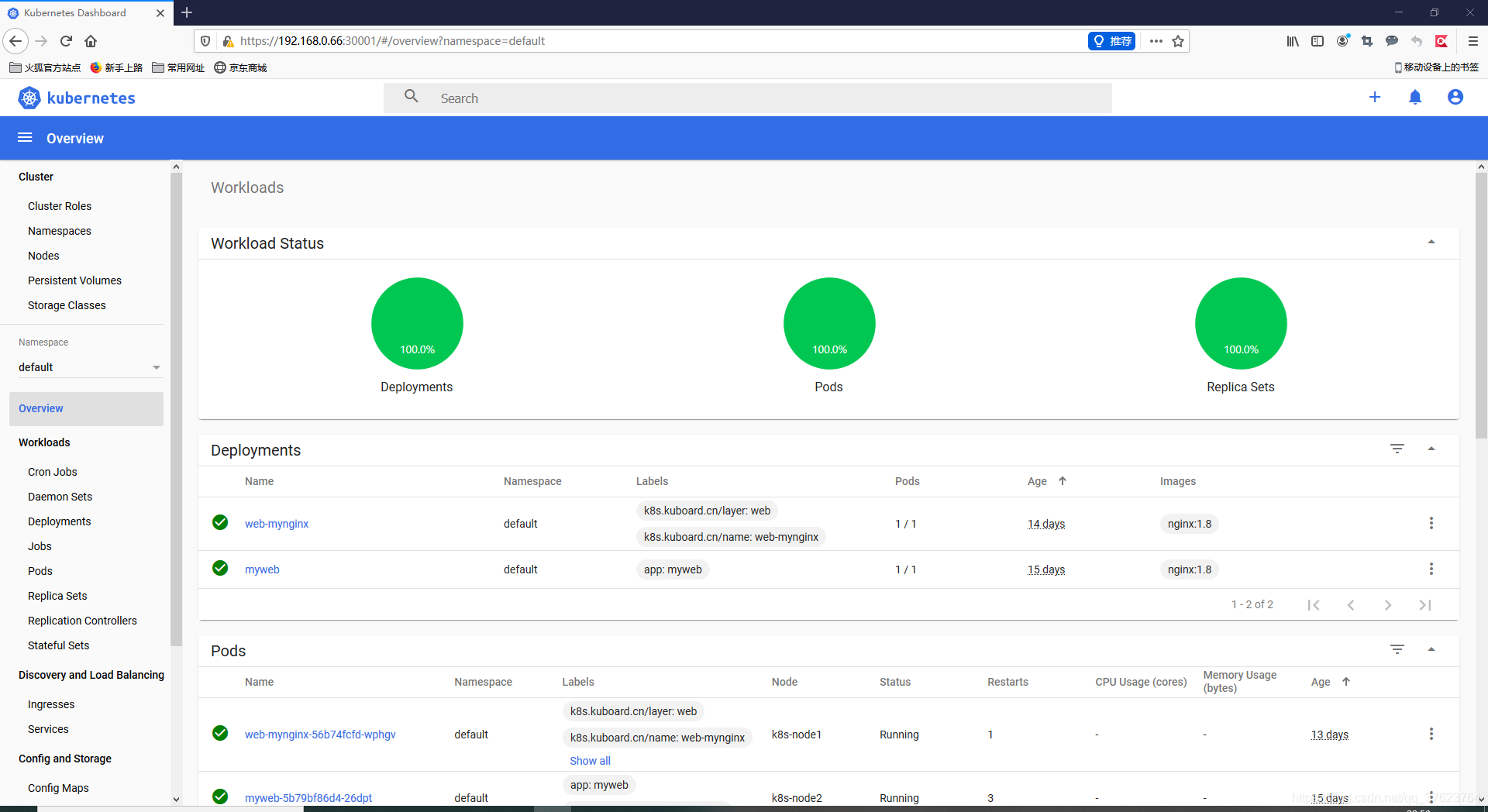
3、最常用的dashboard。直接在master上执行两个yaml文件交付两个pod上去, kubectl apply -f dashboard.yaml 和 dashboard-adminuser.yaml,就完成了dashboard图形化界面的部署。最后使用此命令来获取k8s的RBAC(基于角色权限管理)的token令牌: kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')完成登录。用任意工作节点的ip加端口(用get svc来查看端口),用火狐浏览器来访问,一定要使用https协议。
1、最开始我们克隆出来的master2和两台LB还没有使用。现在就加一台master2来实现高可用。首先也是初始化master2,首先更改网卡配置文件中的IPADDR一项我是配置为192.168.0.64,重启网络,然后照我们之前的初始化六个步骤做,那个时间配置那儿,就不要照master1了,因为时间服务器一台就够了,照配置node来做,然后在master1上执行五条命令:
scp-r/opt/etcd root@k8s-master2:/opt
scp-r/opt/kubernetes/root@k8s-master2:/opt
cd/usr/lib/systemd/system
scp kube-apiserver.service kube-controller-manager.service kube-scheduler.service root@k8s-master2:/usr/lib/systemd/system
scp/bin/kubectl root@k8s-master2:/bin 2、回到master2节点,修改apiserver的配置文件: vi /opt/kubernetes/cfg/kube-apiserver.conf,只修改两行,把下图换成你的master2的ip。
--advertise-address=192.168.0.64\--service-cluster-ip-range=10.0.0.0/24\ 3、在master2上启动三个组件,执行:
systemctl daemon-reloadsystemctl restart kube-apiserver
systemctl enable kube-apiserver
systemctl restart kube-controller-manager
systemctl enable kube-controller-manager
systemctl restart kube-scheduler
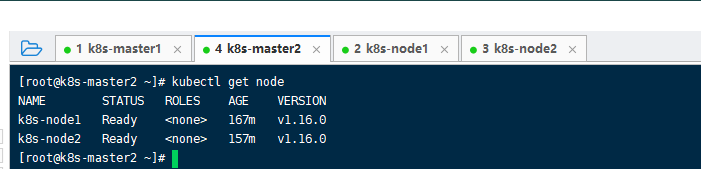
systemctl enable kube-scheduler 4、检查是否启动三个组件成功:ps -aux | grep kube。最直观就是这个命令: kubectl get node,如果你在这台master2也能get到node1和node2,就可以了,代表,你的这个master2已经作为主节点加入到K8S集群中。
1、k8s内部的pod之间访问是用内网ip,但是pod的ip是不定的,当pod被重启后,ip是会变化的。为了解决这个问题,我们前面引入了label标签来关联上service,通过固定集群service的ip来让接入点的ip稳定,但是这样还是不够自动化,我能不能不要serviceip,要service名称就可以呢?如何自动关联上service和集群网络的ip呢?你马上想到我们常用的dns,它能把baidu.com解析为39.156.69.79这个ip。但是我们现在是想实现集群内部的service名称跟集群ip对应起来,比如service1能解析为192.168.0.65这个ip,并调度到映射的pod端口上实现服务发现。k8s中用来实现service名称解析的就是这个CoreDNS插件。
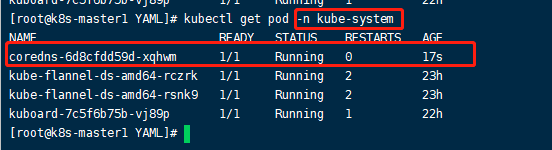
2、在master1上 kubectl apply -f coredns.yaml
1、默认情况下,k8s只能在master上来管理,来执行命令。get信息,create控制器,apply我们的yaml文件。这些操作都只能在master上。node上执行不了,根本原因就是:node上没有kubectl这个命令。那我就把它scp到node1下
scp/bin/kubectl root@k8s-node1:/bin 2、结果执行node1提示localhost:8080拒绝访问:

3、再回到master上:
a、颁发admin证书
cd TLS/k8s
vi admin-csr.json
cfssl gencert-ca=ca.pem-ca-key=ca-key.pem-config=ca-config.json-profile=kubernetes admin-csr.json|cfssljson-bare admin b、创建kubeconfig文件,设置集群参数,然后就会再本目录下生成admin.pem
kubectl configset-cluster kubernetes \--server=https://192.168.0.63:6443\--certificate-authority=ca.pem \--embed-certs=true \--kubeconfig=config 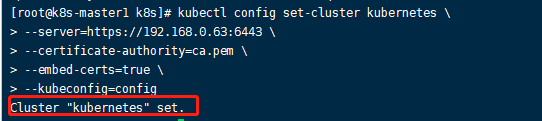
c、设置客户端认证参数
kubectl configset-credentials cluster-admin \--certificate-authority=ca.pem \--embed-certs=true \--client-key=admin-key.pem \--client-certificate=admin.pem \--kubeconfig=config 
d、设置上下文参数,这一步做完之后就会生成一个名叫config的文件。
kubectl configset-context default \--cluster=kubernetes \--user=cluster-admin \--kubeconfig=config 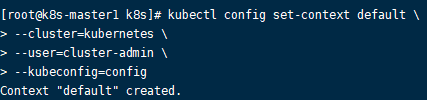
再执行:
kubectl config use-context default--kubeconfig=config e、把config文件发送到node上:
scp config root@k8s-node1:/root f、在node节点基于config实现执行kubectl命令:
kubectl get node--kubeconfig=config 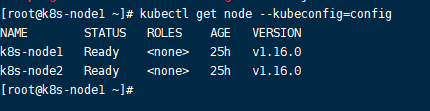
但是这样指定config太麻烦,我想想再master一直方便。直接在node上执行: mv /root/config /root/.kube,就可以不加–指定也可以执行了。
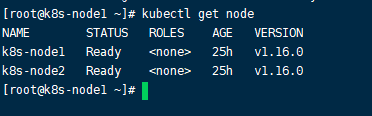
这个config是比较重要的,任何人拿到你这个文件,就都可以管理你的整个k8s集群了,里面有你的master的ip以及刚刚生成的访问密钥。
1、devops自动化:python docker+k8s git+jenkins。
2、k8s >> docker三剑客(compose做容器编排来启动容器,swam容器具体启动到那个node,主机数量不够通过machine来加node)。
3、pod与pod控制器:一个pod是一个或多个容器,控制器用来启动、管理pod数量和状态。
创建控制器的方式: kubectl run pod名称 --images=nginx:1.8 --replicas=1 -n 名称空间或 kubectl create 控制器类型 控制器名称 --images=nginx:1.8 --replicas=1 -n 名称空间(run是在集群跑pod,create是在集群创建资源,实际也是跑pod);通过kuboard的web端来创建;通过 kubectl apply -f yaml文件创建deployment,然后再写一个yaml文件来运行,就可以创建service对象来映射pod的端口。其实完全可以在kuboard上操作,创建pod之后有自动生成的yaml文件,创建service之后也有yaml文件。那两个yaml文件你拿来手动apply,跟你在board运行是一个效果。
4、service干什么用的:因为pod地址容易发生改变,通过service可以为外界提供一个统一的pod入口,端口映射。通常来说一类pod就有一个service。
5、查看k8s对象状态(pod故障分析): kubectl get 资源类型,可能有node,pod,svc,deployment,结尾加-o wide可以查看控制器或pod具体调度到哪个node,但没有 kubectl describe pod pod名详细。还有一些选项: -n(不指定默认名称空间为default) ; -A显示所有名称空间(常用) ;最后除了查看组件日志,还能像查看某个docker容器日志一样 docker logs 容器名称或ID查看具体pod的日志信息: kubectl logs pod名称。也能像docker进入容器一样进入pod: kubectl exec -it pod名称 bash,还可以 -l指定看哪些标签的资源,如app=nginx
6、服务伸缩:根据客户端的请求流量,改副本数,重新apply一下yaml文件。还可以自动弹性伸缩,

7、滚动更新:先启动新的pod再杀死之前版本的pod,创建一个,杀死一个。比如你想把之前的nginx1.8版本更新为nginx1.7,就改一下yaml文件中的nginx的版本号,再apply一下,就实现更新了。怎么滚回1.8呢
8、先创建pod,再检查pod是否启动正常,再发布,再伸缩,再滚动更新
注意:在k8s环境中,开发交付的是 镜像,而不是程序源代码。
1、制作镜像:大部分是基于Dockerfile文件。
2、将镜像启动为pod。
3、暴露pod,让内部pod可以互相访问。
4、对外发布应用。
5、监控和日志收集
镜像类别(三类):
镜像作用:一个镜像就是一个服务。基础镜像:用官方centos,不需要做;运行环境镜像:在容器里跑python,java代码,以及为项目提供运行环境;项目镜像:这三类镜像的最终版,最后整合成这个项目镜像。
规划:
master:192.168.0.63
node:192.168.0.65 192.168.0.66