探索人机深度融合的高可用性人工智能应用
- - 我爱自然语言处理目前,人工智能技术在世界范围内热度极高,但却出现了“雷声大、雨点小”的现象. 一方面,随着近年来深度学习技术的不断发展,计算能力的不断提高,更深更复杂网络的普及使用,加上深度学习端到端的特性,看起来好像人工智能就是端到端的标注,不断地做数据清洗,增加标注数据,加深模型参数,就可以实现计算机像人类一样工作.

目前,人工智能技术在世界范围内热度极高,但却出现了“雷声大、雨点小”的现象。一方面,随着近年来深度学习技术的不断发展,计算能力的不断提高,更深更复杂网络的普及使用,加上深度学习端到端的特性,看起来好像人工智能就是端到端的标注,不断地做数据清洗,增加标注数据,加深模型参数,就可以实现计算机像人类一样工作。另一方面,人工智能在实际应用场景落地时经常失败,常听到有“只见人工,不见智能”,“有多少人工就有多少智能”的吐槽。因此,目前许多人工智能技术的实现现阶段还不能脱离人工经验。
人工智能落地需要人工智慧,这里核心在于结合场景和算法特点做合理的设计,而非关注更多标准化的标注或者设计更精深的算法网络。达观是ToB的自然语言处理(NLP)公司,主要做办公文档自动处理。近年来在金融、政务、制造业等行业成功落地了非常多的NLP项目。
NLP也被誉为人工智能皇冠上的明珠,AI落地特别是NLP落地尤其不容易,通过机器处理办公文档远比从一堆图片中找出有猫的图片要复杂得多。因为让机器处理办公文档,往往存在缺少大量的训练语料情况,不同行业间需要处理的具体问题千差万别,人工都需要专业培训甚至几年工作经验才能处理妥当。本文主要结合达观的实践落地经验,探讨在具体NLP项目落地时,计算机“智能”需要哪些必不可少的“人工”。
人工智能难以落地的主要原因之一是要处理的问题过于复杂,如果只靠算法模型的自学习,很难学到对应知识,从而作出正确决策,就像用大学生的题目考小学生,不可能考得好。但如果我们能 人工对负责问题进行拆解,分解成多个简单问题,那每个简单的问题可能通过模型就能解决。但如何拆解?拆解成什么程度模型是可以处理的呢?达观的经验是:当面对一个NLP问题,人类看完后立刻就能反应出结果的,这样的问题模型就是我们定义的“简单问题”,是机器可以解决的。下面以合同文档抽取的场景为例帮助大家理解。
假设我们需要构建模型从PDF格式的合同中抽取出甲方、乙方、违约条款等字段信息,看看机器是怎么一步步进行拆解的:
首先看机器的输入数据。PDF格式内部只是规定了每个字符或者线条应该在屏幕上什么位置,这些元素本身没有任何语义上的信息,在计算机看来这份文档其实只有字符以及其位置等简单信息,并没有人看渲染好的PDF文件的对齐、大小、重要性等更多信息。如果通过端到端的方式,把文字以及坐标一起输入到模型,让模型自己学习文档结构,理论上可以抽取出需要的字段。这种方式乍听之下可以一试,但实际效果是非常差的。因为让人看到一堆字和坐标,希望判断出抽取的字段,那本身就是非常复杂的事情,所以我们还需要进一步拆解。

文档解析模型负责解析PDF协议,并且通过一定算法将文档结构化,也就是转成章节、表格、段落等文字流,再输入到字段抽取的模型。这两个模型是否足够简单并能落地呢?
大部分文档下,哪个是文字块,哪个是表格,哪个是图片,人是可以瞬间判断出来的。而文字块拆成章节、标题、段落,尤其是有些文档段落开始并没有明显空格,那人还是需要仔细看,有时候还要分析上下文才能分析出来。所以我们将文档解析继续拆解成元素识别模型和段落识别模型。
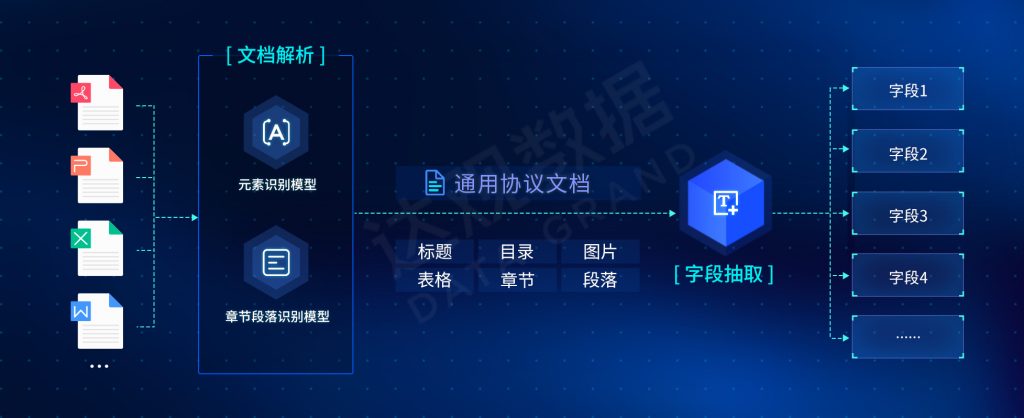
对于字段抽取,有些字段比较简单,比如甲方、乙方,人眼就能看出结果,这些字段直接通过模型抽取问题不大;有些字段稍微复杂一些,比如合同总金额有时候是在文本中的,有时候是在表格里面的,人在看的时候也需要反应一下才能得到信息,所以可以对字段抽取再进行拆解。表格里面需要专门的表格抽取模型,如果是无线表格,人在看的时候往往还需要将虚线进行对应,所以也可以拆出无线表格识别的模型。文本抽取中,有些字段是长文本。比如违约条款,人在找的时候往往是通过前后文找到抽取的开始和结束,而短字段则更关注抽取本身以及上下文的内容。通过对每个步骤的复杂度进行分析,可以进一步拆解为下面结构。
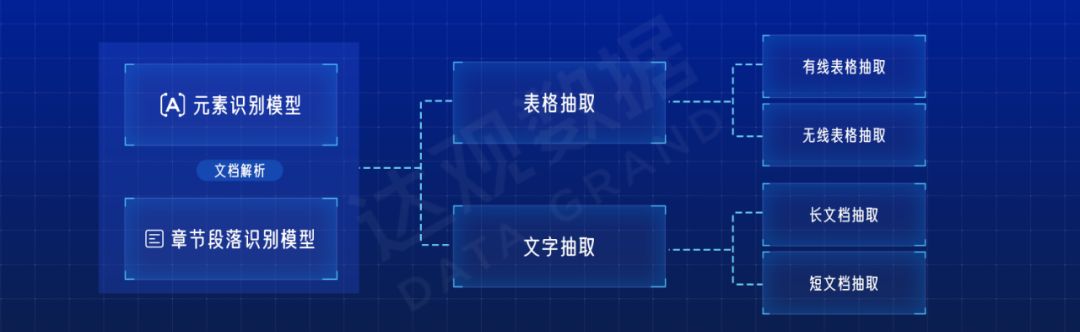
这就是文档抽取常见的模型,但在实际使用中,根据具体数据情况以及分析字段的特点,可能还会再进行拆解。比如某些字段可能是在固定的某些章节或者段落中,用全局的文本进行训练和预测有很大的干扰,那我们就可以再增加一个字段章节预测的模型,定位该字段所在章节。再比如租房合同抽取的字段的文本是比较简单的选择性文本,对于模型来说也有一定困难。在销售合同文本中常常出现:
如果需要退货,采用B进行退货退款:
这样的文本则需要拆成2个模型,一个是抽取选择项的模型,另一个是抽取选择列表的模型。
模型选择也是需要“人工”经验的, 需要结合标注数据规模、数据特点、模型难度等进行选择和处理。比如前面提到的章节预测的模型,如果章节标题特征比较明显,则可以直接通过关键词或者机器学习模型来进行分类处理,如果写法不太规范,需要通过章节标题和章节内容进行判断,则可能考虑基于bert的深度学习算法。就我们达观的经验而言,不同模型,如果使用完全相同的数据,调优后效果差距在5%以内,如果场景能比较好的使用上预训练模型,比如bert,那效果能提升10%-15%。
选定模型之后,也可以通过增加一些特征从而进一步降低模型的难度,提高准确度。在垂直领域文档处理上,业务词典是常用的方法。业务词典包括了专有名词,也包括了字段的重要关键信息的特征。比如我们要抽取合同的乙方,对于公司采购而言,很多都是有供应商库的,或者说可以获得之前与他们签合同的乙方的名称。这个名称构成的词典可能不全,所以不能只靠这个来匹配,但将这个“乙方专有名词”输入模型作为参考特征,是非常有用的。字段的重要关键信息的特征,指的是抽取的这个字段非常关键的上下文。比如抽取“甲方”这个字段,虽然话术可以有多种,比如甲方是xxx,甲方:xxx,甲方是本次的承办单位xxxx等等,但基本都会带“甲方”几个关键字,所以如果把这些专有名词也加入模型,准确度往往会有不小的提升。下面这个是重要词(专有名词或者业务词)使用的例子。

假设“委员”和“委员会”是重要词。需要对“美国联邦通信委员会最近正式批准苹果展开5G通信试验”的每个字生成词向量。这里的方法是通过2-gram,3-gram,4-gram和5-gram对每个字进行编码,编成8个位,每种gram各2个位表示上文是否是重要词和下文是否是重要词。以“委”字为例编码方式为:
其他行业知识也可以用类似的方式生成字向量。把所有的行业向量和原始的字向量进行拼接,作为模型的输入,这样模型就能直接获得行业经验,从而有更好的效果。
有些文本问题有很强的业务性,难以进行拆解,或者业务逻辑太复杂,很难让机器学习到对应的知识。清华大学人工智能研究院院长张钹院士在一次演讲中提到“人的智能没法通过单纯的大数据学习把它学出来,那怎么办?很简单,加上知识,让它有推理的能力,做决策的能力,这样就能解决突发事件。” 达观在落地实践中就是通过知识图谱来解决这种复杂的问题。
知识图谱的概念由 Google 在 2012 年正式提出,是一种语义网络知识库,将现有知识的以结构化多关系图(Multi-Relational Graph)的形式进行储存、使用、展示形成。通过将多个实体关系三元组进行融合,形成包含多个不同的实体节点和多种类别的关系边的多关系图,即知识图谱。知识图谱落地也有很多挑战,构建和维护知识图谱的工作量是非常大的,很多项目因为构建过程太过复杂而最终失败。需要合理设计和运用知识图谱,也需要“人工”经验。达观通过知识图谱辅助智能制造有很多成功的落地案例,下面结合实际应用场景,谈下里面的一些经验。
生产制造过程中,有很多时候会遇到一些故障,比如手机发热,螺丝拧不上等问题,不快速解决会影响生产流程。之前遇到这类问题只能通过咨询经验丰富的“专家”,但总会存在专家找不到或者专家不一定有空的情况。我们希望通过NLP和知识图谱技术可以解决这个问题。
达观通过对里面的数据进行研究发现,要找到这些问题的答案经常要涉及好多文件,比如产品说明书,故障手册等。有些问题容易获得答案,但有些问题可能需要通过一些复杂的推理才能获得答案,甚至不一定能找到答案。面对这个问题,我们设计了制造业失效图谱。
为了解决专家录入进行构建的成本过高的问题,一方面我们设计的失效图谱schema只和失效本身相关,其他生成过程中的知识并不纳入产品范围之类,从而减少生成图谱的工作量。另一方面,我们在 图谱构建的时候,以人工结合智能。从相关的文档,比如产品说明书,故障维修手册,失效分析文档等内容中提取相关属性数据,经过人工审核,再录入到图谱中。这种人机结合的方式生成图谱相比于纯人工生成图谱可以大幅减少工作量。图谱数据的抽取主要采用基于pipeline抽取和联合抽取的方法。
pipeline抽取,是用NER技术先抽取出实体和属性后,再通过分类方法对实体两两进行分类判断。这种方法的优点是灵活性高,不同类型的实体可以用不同的模型进行抽取,关系抽取的分类算法也可以结合实际数据进行优化和调整,缺点在于可能产生错误传播,实体错误后面的关系肯定是错误的,以及忽略了实体属性抽取和关系抽取内部的可能联系。
基于联合抽取的方法是同时抽取实体、属性、关系。针对实体抽取出的实体对,在当前句子对应的依存句法树中找到能够覆盖该实体对的最小依存句法树, 并基于 TreeLSTM 生成该子树对应的向量表示,最后,根据子树根节点对应的 TreeLSTM 向量进行关系分类。
一些知识可以通过抽取已有的文档,但有些文档缺失或者抽取难度很高的,则由专家来进行人工录入,从而构造了一个针对失效的知识图谱。有了这个图谱,就形成了计算机的知识。
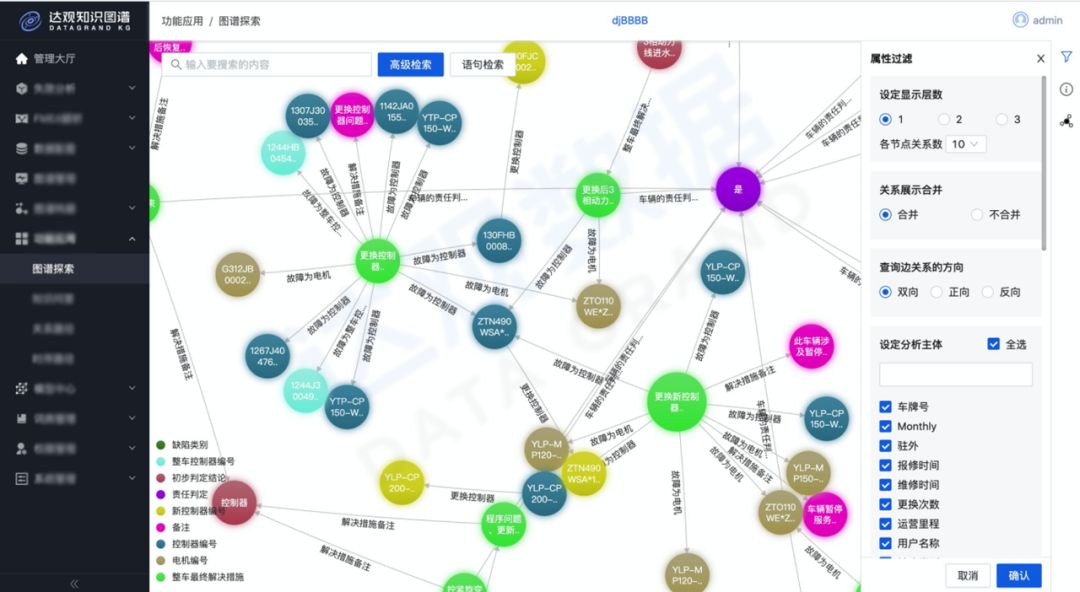
失效图谱例
基于图谱赋予的知识,企业可以使用基于知识图谱的问答(KBQA)来解决生产中实际碰到的问题,我们叫“归因分析”。基于图谱的问答需要能理解各种query的真实意图,尤其是query可能输错,可能表述不规范,需要还能对应到图谱得到正确的答案。这里面也需要对问题进行拆解,分解成一个个可以解决的模型。
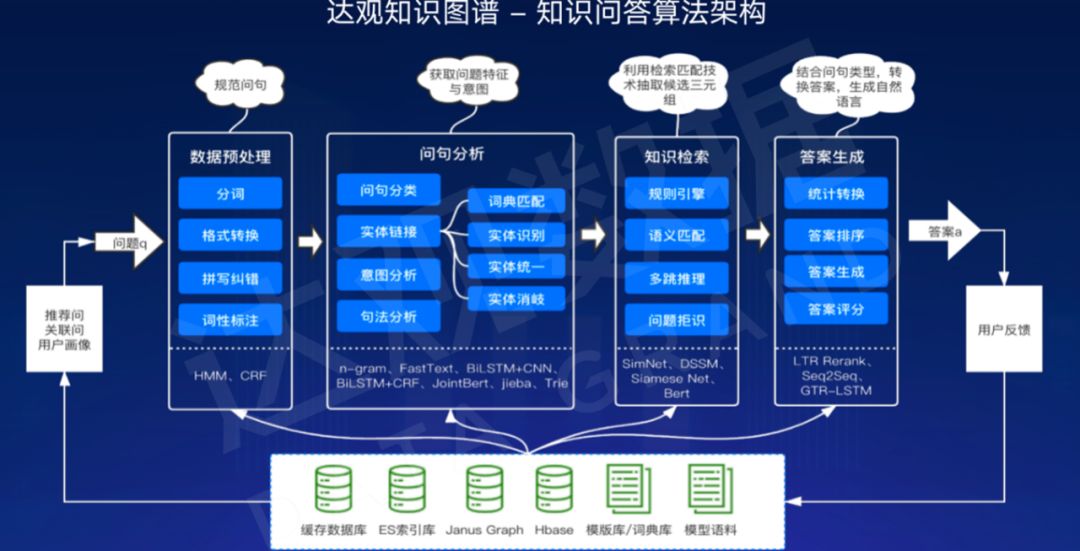
KBQA处理流程
一般来说,KBQA分为数据预处理,问句分析,知识检索,答案生成4个阶段。
针对人工智能产品或解决方案,一般大家都在讨论技术如何提升,效果如何优化。以达观在过去几年落地的很多AI项目来说, 场景选择和产品形态的设计其实是落地非常关键的环节。从落地的角度,本质需求是希望可以更快地高质量完成预计的工作,并不是需要一个多少准确率的模型。而且这里的高质量,在办公文档处理上的落地需求往往是100%准确。而目前的算法基本都不能达到100%准确,而且算法本身并不知道错在哪里,这也是AI落地碰到的最大挑战。因为当需要所有数据进行复核,“快速”这个需求就会大打折扣。如何“快速”审核就是需要在场景选择以及产品形态上做很多工作。
01 比对数据
用第三方数据或者有规则进行校验,就能快速发现AI错误之处。比如电子合同和图片合同进行文档比对的场景,ocr的错误通过比对,可以快速的找到出现ocr错误的地方,人工可以快速进行查看。

文档比对产品kh
02 业务关系
文档中识别的元素有些是有业务关系的,可以通过字段的关系来验证识别是否正确。比如下图总和的值应该是上面列表中数值计算后的结果。如果识别出来的结果总和公式不正确,那很可能是中间哪个元素识别出现了问题,如果识别出来的结果总和公式正确,那基本识别本身也是正确的。
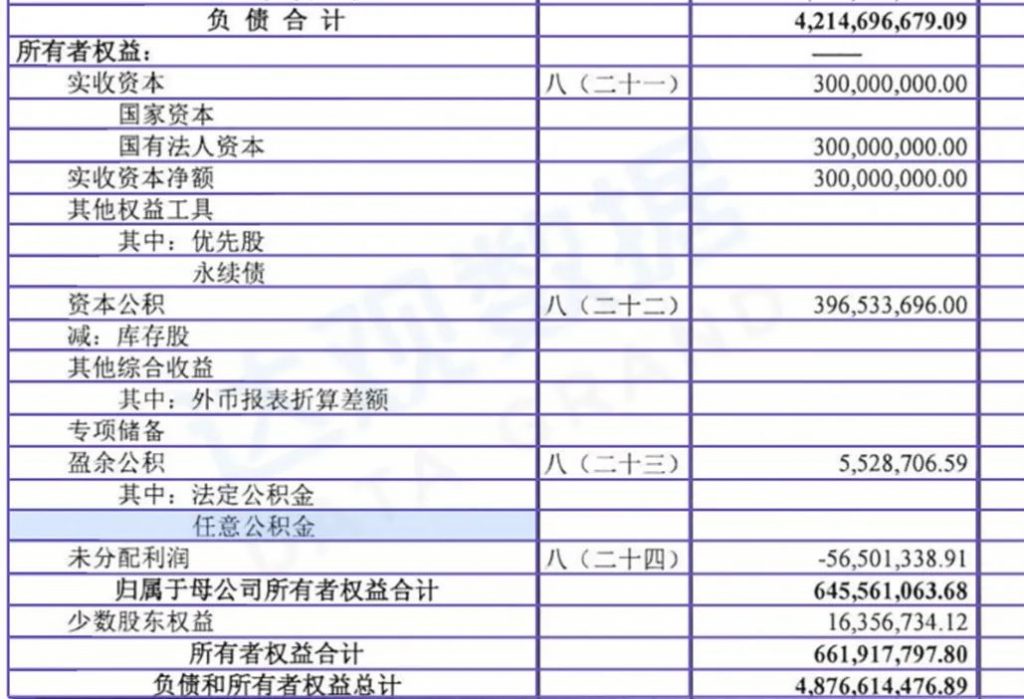
财务文档中的勾稽关系
03 高效审核
人工审核过程的产品交互是非常重要的,需要对比较耗费时间的环节结合具体业务场景的审核过程进行合理交互设计。审核过程主要是“找到”和“修订”两个动作,达观通过对抽取结果进行高亮,点击字段跳转等功能帮助审核人员快速“找到”抽取结果以及上下文,通过划选和快捷键等功能加速人工“修订”的时间。
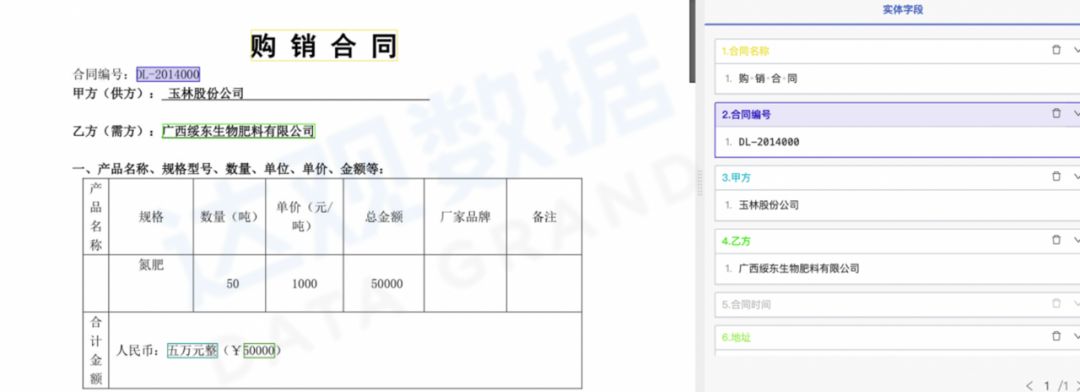
人工审核产品交互
人工智能落地是一个挺有挑战性的工作,既需要攻克技术难度,不断提升算法精度,也需要了解业务,了解场景,才能选择合适的场景,构建合理的算法流程,设计方便的产品交互,把这些“人工”的价值发挥出来, 以人机协同的方式促进算力和模型的提高,才能真正实现“人工智能”。