OceanBase 数据库采用 Shared-Nothing 架构,各个节点之间完全对等,每个节点都有自己的 SQL 引擎、存储引擎,运行在普通 PC 服务器组成的集群之上,具备可扩展、高可用、高性能、低成本、云原生等核心特性。
OceanBase 数据库的整体架构如下图所示。 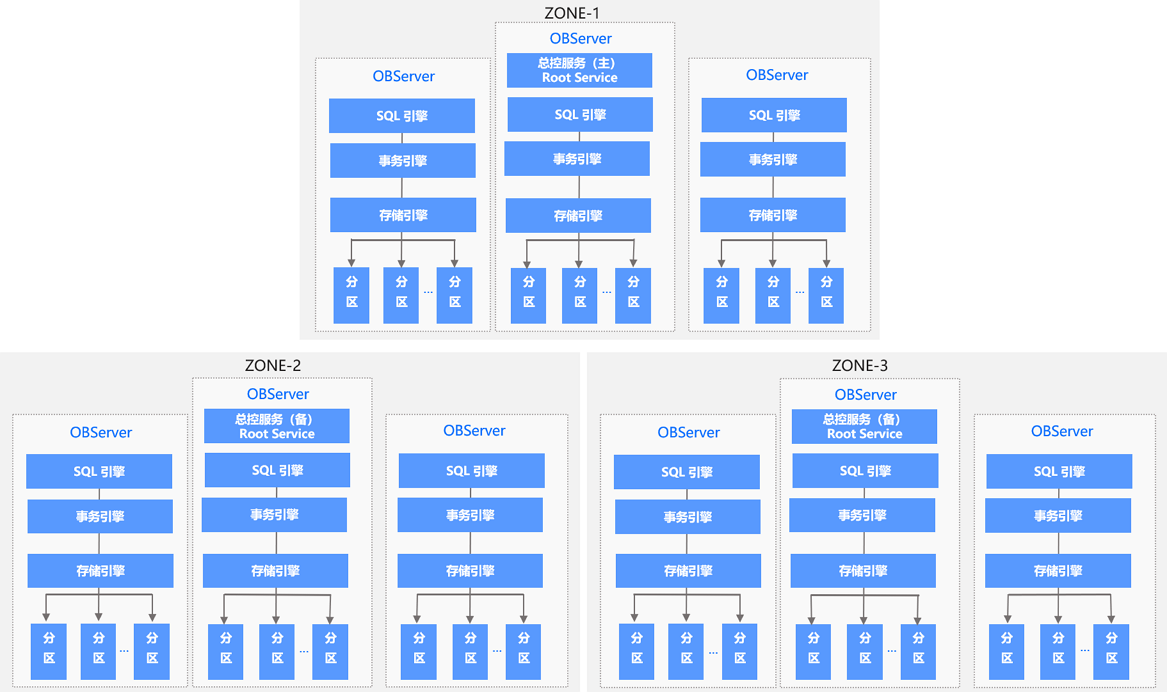
集群架构
OceanBase 数据库支持数据跨地域(Region)部署,每个地域可能位于不同的城市,距离通常比较远,所以 OceanBase 数据库可以支持多城市部署,也支持多城市级别的容灾。一个 Region 可以包含一个或者多个 Zone,Zone 是一个逻辑的概念,它包含了 1 台或者多台运行了 OBServer 进程的服务器(以下简称 OBServer)。每一个 Zone 上包含一个完整的数据副本,由于 OceanBase 数据库的数据副本是以分区为单位的,所以同一份数据会分布在不同的 Zone 上。每个分区的主副本所在服务器被称为 Leader,所在的 Zone 被称为 Primary Zone。如果不设定 Primary Zone,系统会根据负载均衡的策略,在多个全功能副本里自动选择一个作为 Leader。
每个 Zone 会提供两种服务:总控服务(RootService)和分区服务(PartitionService)。其中每个 Zone 上都会存在一个总控服务,运行在某一个 OBServer 上,整个集群中只存在一个主总控服务,其他的总控服务作为主总控服务的备用服务运行。总控服务负责整个集群的资源调度、资源分配、数据分布信息管理以及 Schema 管理等功能。 其中:
-
资源调度主要包含了向集群中添加、删除 OBServer,在 OBServer 中创建资源规格、Tenant 等供用户使用的资源;
-
资源均衡主要是指各种资源(例如:Unit)在各个 Zone 或者 OBServer 之间的迁移。
-
数据分布管理是指总控服务会决定数据分布的位置信息,例如:某一个分区的数据分布到哪些 OBServer 上。
-
Schema 管理是指总控服务会负责调度和管理各种 DDL 语句。
分区服务用于负责每个 OBServer 上各个分区的管理和操作功能的模块,这个模块与事务引擎、存储引擎存在很多调用关系。
OceanBase 数据库基于 Paxos 的分布式选举算法来实现系统的高可用,最小的粒度可以做到分区级别。集群中数据的一个分区(或者称为副本)会被保存到所有的 Zone 上,整个系统中该副本的多个分区之间通过 Paxos 协议进行日志同步。每个分区和它的副本构成一个独立的 Paxos 复制组,其中一个分区为主分区(Leader),其它分区为备分区(Follower)。所有针对这个副本的写请求,都会自动路由到对应的主分区上进行。主分区可以分布在不同的 OBServer 上,这样对于不同副本的写操作也会分布到不同的数据节点上,从而实现数据多点写入,提高系统性能。
存储引擎
OceanBase 数据库的存储引擎采用了基于 LSM-Tree 的架构,把基线数据和增量数据分别保存在磁盘(SSTable)和内存(MemTable)中,具备读写分离的特点。对数据的修改都是增量数据,只写内存。所以 DML 是完全的内存操作,性能非常高。读的时候,数据可能会在内存里有更新过的版本,在持久化存储里有基线版本,需要把两个版本进行合并,获得一个最新版本。

如上图所示,在内存中针对不同的数据访问行为,OceanBase 数据库设计了多种缓存结构。除了常见的数据块缓存之外,OceanBase 数据库也会对行进行缓存,行缓存会极大加速对单行的查询性能。为了避免对不存在行的空查,OceanBase 数据库对行缓存构建了布隆过滤器,并对布隆过滤器进行缓存。OLTP 业务大部分操作为小查询,通过小查询优化,OceanBase 数据库避免了传统数据库解析整个数据块的开销,达到了接近内存数据库的性能。当内存的增量数据达到一定规模的时候,会触发增量数据和基线数据的合并,把增量数据落盘。同时每天晚上的空闲时刻,系统也会启动每日合并。另外,由于基线是只读数据,而且内部采用连续存储的方式,OceanBase 数据库可以根据不同特点的数据采用不同的压缩算法,既能做到高压缩比,又不影响查询性能,大大降低了成本。
SQL 引擎
OceanBase 数据库的 SQL 引擎是整个数据库的数据计算中枢,和传统数据库类似,整个引擎分为解析器、优化器、执行器三部分。当 SQL 引擎接受到了 SQL 请求后,经过语法解析、语义分析、查询重写、查询优化等一系列过程后,再由执行器来负责执行。所不同的是,在分布式数据库里,查询优化器会依据数据的分布信息生成分布式的执行计划。如果查询涉及的数据在多台服务器,需要走分布式计划,这是分布式数据库 SQL 引擎的一个重要特点,也是十分考验查询优化器能力的场景。OceanBase 数据库查询优化器做了很多优化,诸如算子下推、智能连接、分区裁剪等。如果 SQL 语句涉及的数据量很大,OceanBase 数据库的查询执行引擎也做了并行处理、任务拆分、动态分区、流水调度、任务裁剪、子任务结果合并、并发限制等优化技术。
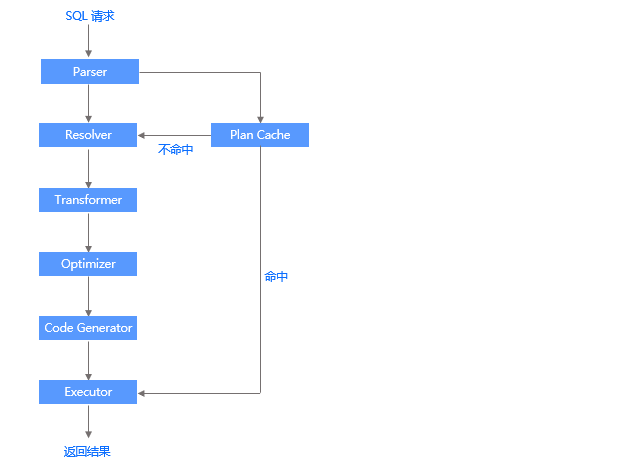
下图描述了一条 SQL 语句的执行过程,并列出了 SQL 引擎中各个模块之间的关系。
-
Parser(词法/语法解析模块)
Parser 是整个 SQL 执行引擎的词法或语法解析器,在收到用户发送的 SQL 请求串后,Parser 会将字符串分成一个个的单词,并根据预先设定好的语法规则解析整个请求,将 SQL 请求字符串转换成带有语法结构信息的内存数据结构,称为语法树(Syntax Tree)。
为了加速 SQL 请求的处理速度,OceanBase 数据库对 SQL 请求采用了特有的快速参数化,以加速查找执行计划的速度。
-
Resolver(语义解析模块)
当生成语法树之后,Resolver 会进一步将该语法树转换为带有数据库语义信息的内部数据结构。在这一过程中,Resolver 将根据数据库元信息将 SQL 请求中的 token 翻译成对应的对象(例如库、表、列、索引等),生成语句树。
-
Transformer(逻辑改写模块)
在查询优化中,经常利用等价改写的方式,将用户 SQL 转换为与之等价的另一条 SQL,以便于优化器生成最佳的执行计划,这一过程称为查询改写。Transformer 在 Resolver 之后,分析用户 SQL 的语义,并根据内部的规则或代价模型,将用户 SQL改写为与之等价的其他形式,并将其提供给后续的优化器做进一步的优化。Transformer 的工作方式是在原 Statement Tree 上做等价变换,变换的结果仍然是一棵语句树。
-
Optimizer(优化器)
优化器是整个 SQL 优化的核心,其作用是为 SQL 请求生成最佳的执行计划。在优化过程中,优化器需要综合考虑 SQL 请求的语义、对象数据特征、对象物理分布等多方面因素,解决访问路径选择、联接顺序选择、联接算法选择、分布式计划生成等多个核心问题,最终选择一个对应该 SQL 的最佳执行计划。SQL 的执行计划是一棵由多个操作符构成的执行树。
-
Code Generator(代码生成器)
优化器负责生成最佳的执行计划,但其输出的结果并不能立即执行,还需要通过代码生成器将其转换为可执行的代码,这个过程由 Code Generator 负责。
-
Executor(执行器)
当 SQL 的执行计划生成后,Executor 会启动该 SQL 的执行过程。对于不同类型的执行计划,Executor 的逻辑有很大的不同:对于本地执行计划,Executor 会简单的从执行计划的顶端的算子开始调用,由算子自身的逻辑完成整个执行的过程,并返回执行结果;对于远程或分布式计划,Executor 需要根据预选的划分,将执行树分成多个可以调度的线程,并通过 RPC 将其发送给相关的节点执行。
-
Plan Cache(执行计划缓存模块)
执行计划的生成是一个比较复杂的过程,耗时比较长,尤其是在 OLTP 场景中,这个耗时往往不可忽略。为了加速 SQL 请求的处理过程,SQL 执行引擎会将该 SQL 第一次生成的执行计划缓存在内存中,后续的执行可以反复执行这个计划,避免了重复查询优化的过程。