导读:本文主要介绍目前腾讯数据治理的所在阶段和实践经验,以及基于目前的经验所沉淀的数据治理平台:WeData。
今天的介绍会围绕下面三方面展开:
-
数据治理挑战
-
腾讯内部数据治理实践
-
WeData 数据治理平台能力
分享嘉宾|王浩仙 腾讯云 技术产品
编辑整理|聚变 腾讯
出品社区|DataFun
01 数据治理挑战
首先和大家分享腾讯在数据治理上所面临的挑战。
1. 数据治理的挑战
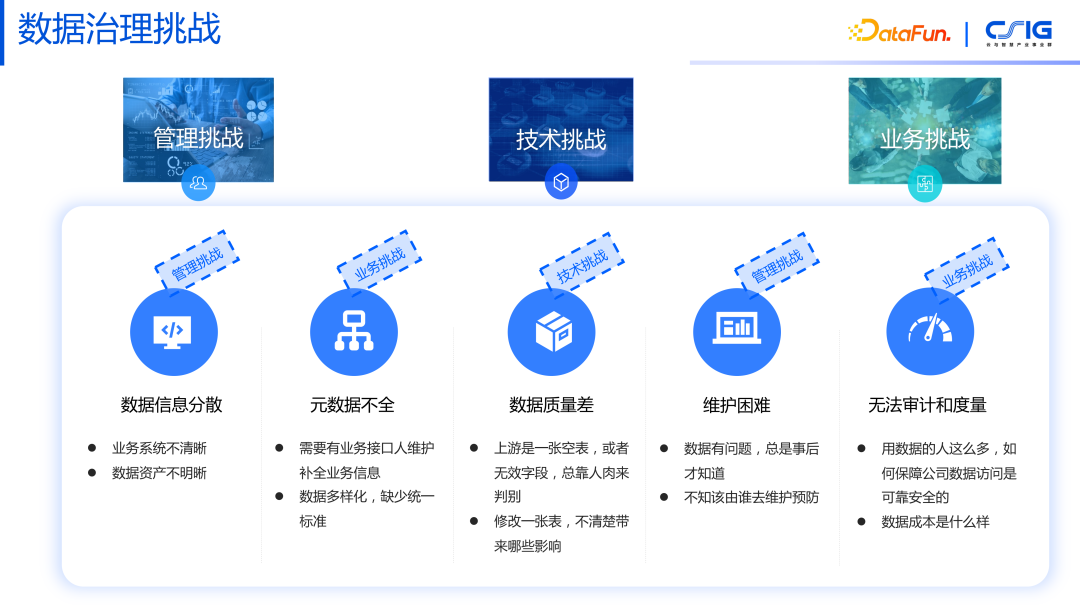
在数据治理的过程中会遇到很多问题,我们简单分成三类:
- 管理类挑战:数据信息分散在不同的业务部门的业务库中,数据上报也分散在不同的位置,难以对这些分散的数据进行统一的管理。随着数据量的不断增大,如何投入更少的人力去进行数据信息的维护也是一大难题。
- 技术类挑战:我们的数据工程师在收集到数据后,数据的质量该怎么保证?如果数据本身质量不过关,可能带来负面的业务效果。
- 业务类挑战:在所有的数据上报之后,底层的业务元信息缺失,无法进行统一的审计或者度量。
2. 数据治理“马斯洛的需求层次理论” 
数据治理对于不同企业,或者是一个企业在不同的发展阶段,所面临的问题是不一样的,这里进行了一个简单分类:
- 时效性:数据采集上来后,我们会关注数据产出的及时性,因为如果数据发生的时效性没有达标的话,对当前的业务判断来讲价值就会降低。
- 质量性:在数据已经有了一些闭环应用的基础上,还需要有准确性,完整性,有效性,如此才能保证在数据应用上能达成期望的效果。
- 可用性:如果数据是不可用的,则数据对我们的价值就降低。
- 安全性:在数据量很大之后,我们会更多地去关注数据共享或者数据应用,在这个过程中,我们的数据安全如何保障。
- 成本:解决问题过程中可能耗费大量人力、物力以及计算资源,我们是否能在解决问题的同时降低成本。
02
腾讯内部数据治理实践 1. 腾讯内部业务现状 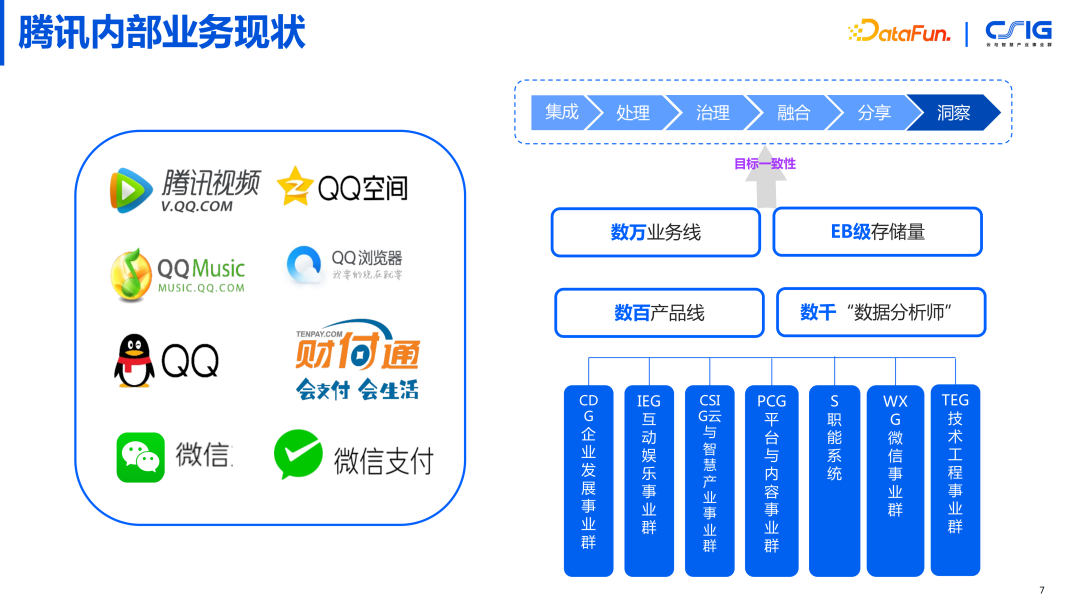
接下来介绍腾讯内部的业务现状,腾讯分很多的 BG,包括企业、娱乐、云方向、内容方向。这些涉及数万业务线,数百个产品线,达到 EB 级的数据存储量,拥有数千的数据分析师。
2. 腾讯数据治理三阶段 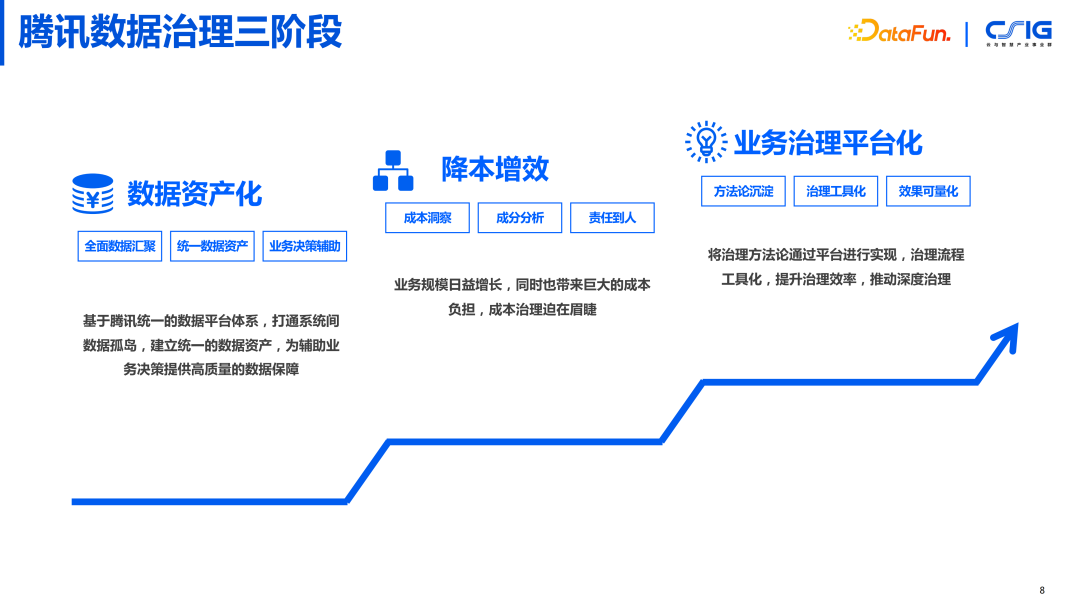
每条业务线虽然不同,但也会有一些共性的地方。从大的方向上我们会分为三个阶段:
- 第一阶段:数据资产化,把数据这个物料变成一个有价值的资产,这才是我们所有的人做数据的一个最核心的目标。把这个目标达成了之后,才能把数据真正利用起来。
- 第二阶段:降本增效,如何把之前我们在做数据资产化过程中消耗的一些资源降下来,把整个投入降低,但是还能保持或者提高数据资产化的效果。
- 第三阶段:在前两个阶段都完成之后,会发现可以抽象出来一些通用的东西,把我们内部的经验理念孵化出来,去解决更多的问题,这是 数据治理平台化产品化的阶段。
3. 腾讯内部实践:腾讯新闻数据资产化 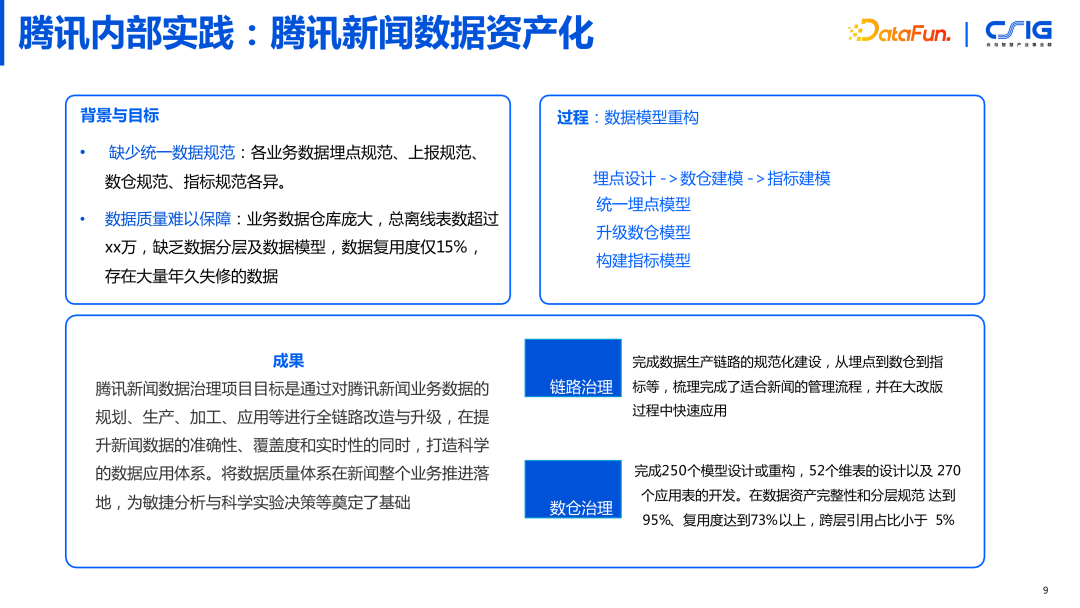
数据资产化阶段的实践,以腾讯新闻为例,在做数据治理这件事情的时候,最开始我们面临着两大问题:
- 缺少统一数据规范:各业务数据埋点规范、上报规范、数仓规范、指标规范各异。
- 数据质量难以保障:业务数据仓库庞大,缺乏数据分层及数据模型,数据复用度仅 15%, 存在大量年久失修的数据。
针对这两大问题,我们进行了统一的数据资产化,包括统一埋点模型,升级数仓模型,构建指标模型。完成数据生产链路的规范化建设,从埋点到数仓到指标等,梳理完成了适合新闻的管理流程,并在大改版过程中快速应用。完成了 250 个模型设计或重构,52 个维表的设计以及 270 个应用表的开发。在数据资产完整性和分层规范达到 95%、复用度达到 73% 以上,跨层引用占比小于 5%。
4. 腾讯内部实践:PCG(平台与内容事业群)数据成本治理 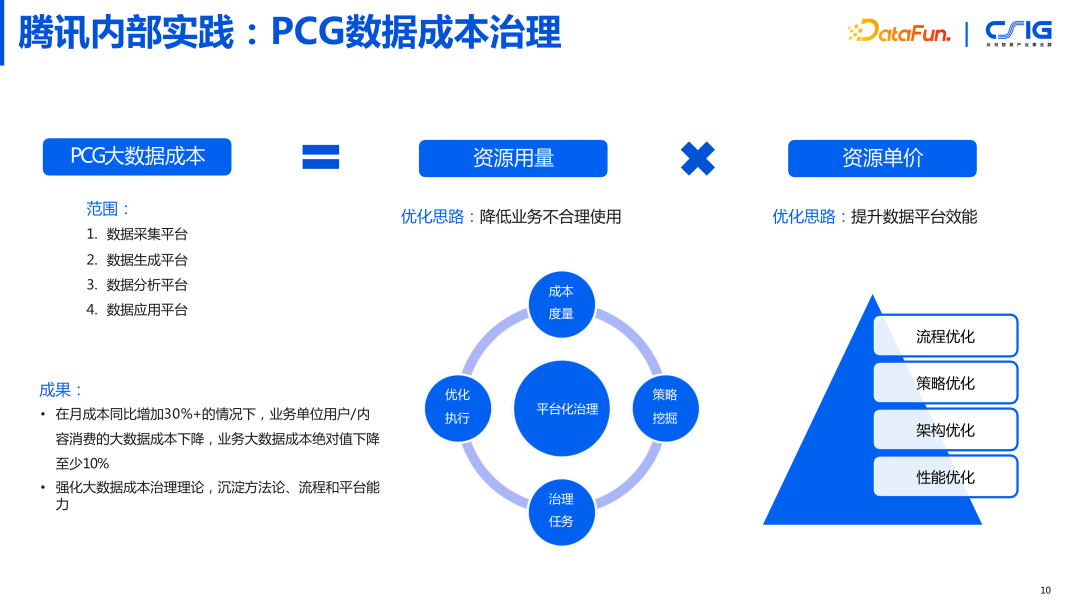
数据成本的治理,我们以腾讯内部 PCG(平台与内容事业群)业务线为例。在做成本治理的时候,我们要去定义成本的范围,包括:数据采集平台,数据生成平台,数据分析平台,数据应用平台。我们通过两个方面进行了优化,一方面从资源用量上降低业务不合理使用,另一方面从资源单价上提升数据平台的效能。截止到今年,在月成本同比增加 30%+ 的情况下,业务单位用户/内容消费的大数据成本下降,业务大数据成本绝对值下降至少 10%。强化了大数据成本治理理论,沉淀了方法论、流程和平台能力。
5. 腾讯内部实践:治理平台化推动业务治理落地 
海量数据给业务带来了巨大价值,同时也带来巨大的成本及负担。业务团队大数据成本盘点困难、治理执行门槛成本双高、治理效果不能有效量化,都是业务在推进资产治理的痛点。
我们把推动治理平台化分为了 4 个阶段: - 现状概览:洞察全域数仓及大数据成本,呈现最真实的业务资产情况。
- 资产明细:全方位治理项洞察,基于资产分规范,对当前业务的待治理项进行明细展示。
- 治理方案:平台内置治理方案结合业务定制化治理方案。
- 治理执行:一站式治理执行,针对洞察出的治理项进行治理动作。
构建了一套属于我们自己的资产价值评分体系,包括:规范性、安全性、数据质量、数据成本、数据应用情况。将评分给到数据治理的实施人,帮助制定治理方案和复盘治理效果。
03
WeData 数据治理平台能力
1. 腾讯内部大数据能力的对外商业化输出——WeData 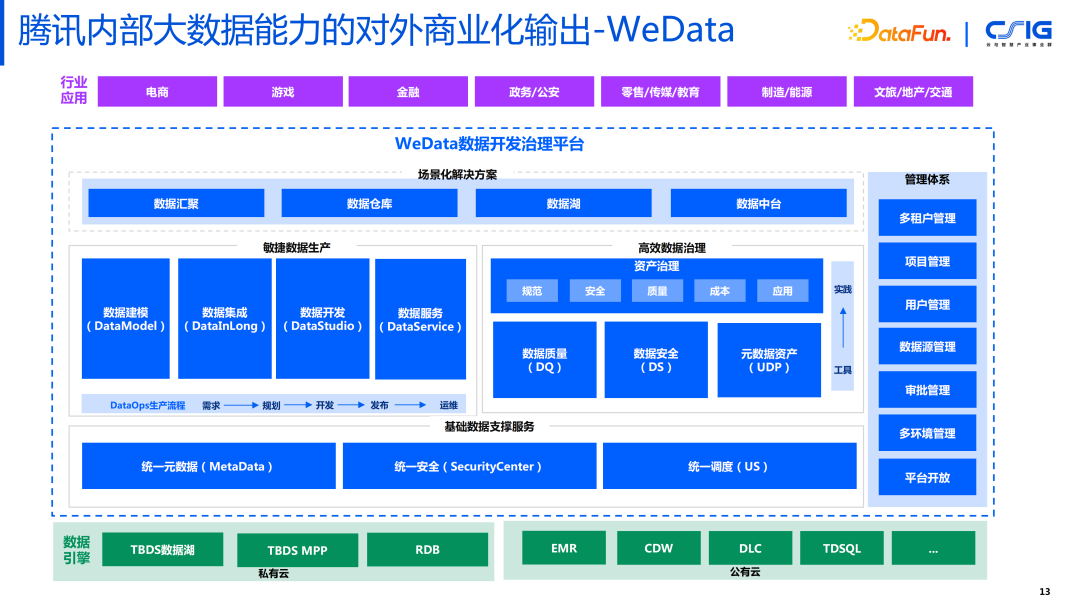
这是 WeData 数据开发治理平台的架构图,要形成一个闭环,与数据的生产生联动,因为数据治理不仅要处理存量数据,还要处理未来增量的数据。平台主要分成两大部分,左边是敏捷数据生产,包括:数据建模、数据集成、数据开发、数据服务。右边是高效数据治理,包括:资产治理,数据质量,数据安全,元数据资产。
2. WeData 数据治理服务 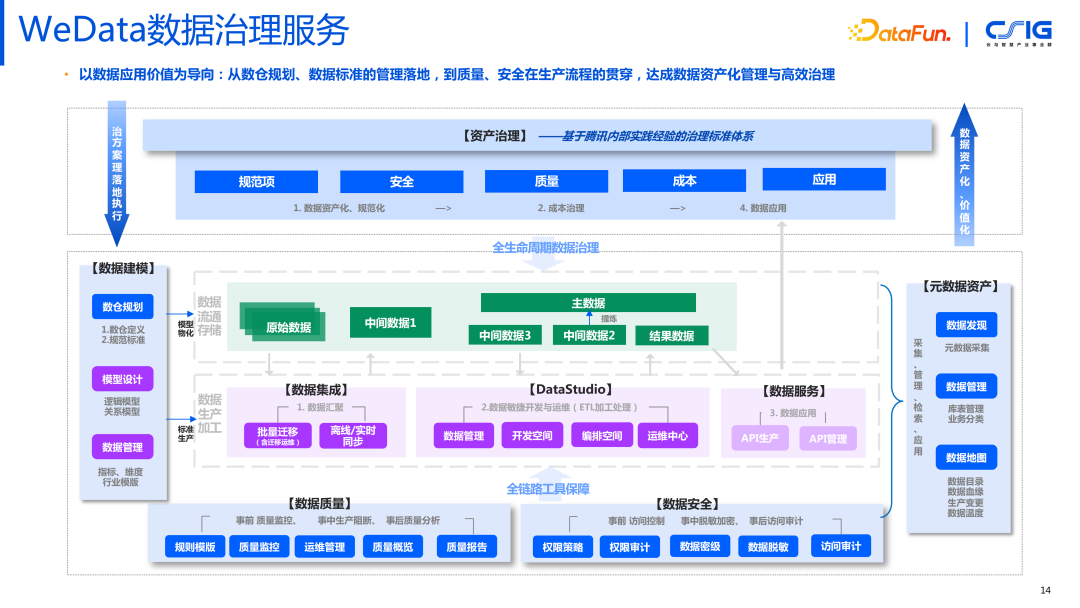
首先我们看图的中心部分,分为上下两层,上面是数据流通与存储的过程,下面是加工生产的过程,包括数据汇聚,数据开发与运维(基础管理,库表构建,脚本开发,脚本编排)和数据服务(在数据上生成 API)。
从图的左边看,首先要做的是数据建模,涉及到治理部分的能力,就包括最开始的数仓的规划,数仓定义和规范标准,模型定义和指标定义。前期定义之后,在接下来的数据生产的过程中,才能验证数据是否符合这个标准,如果前期没有定义,也可以在后期其他模块逐步地去发现完善它。
图的下方,主要是数据质量和数据安全部分。数据质量包括:事前的质量监控;事中的质量监测(如果不达标,我们会阻断流程,避免污染下游的数据);事后的质量分析报告。数据安全也是包含三个部分,事前访问控制、事中脱敏加密,事后访问审计。数据的质量与安全的治理,贯穿数据的全生命周期。
图的右边是元数据资产,可以分成三个部分,首先发现元数据,采集元数据。接着,元数据采集上来之后,我作为数据的生产方,要具备管理好数据的能力,包括两层,第一层就是基本的技术元数据:库表,字段等。此外,还要从业务的角度去理解,所以需要大量的业务元数据的信息,与技术元信息进行关联。形成关联关系之后,数据使用者才能真正理解数据的业务含义。第三部分就是数据目录,通过数据目录 让所有使用数据的人能快速的定位到目标数据。通过血缘关系,帮助排查数据的来源和去向。数据变更记录了数据源的每次变化以及对下游的影响。数据温度则体现了数据使用的具体情况。
3. WeData数据治理——规范工具 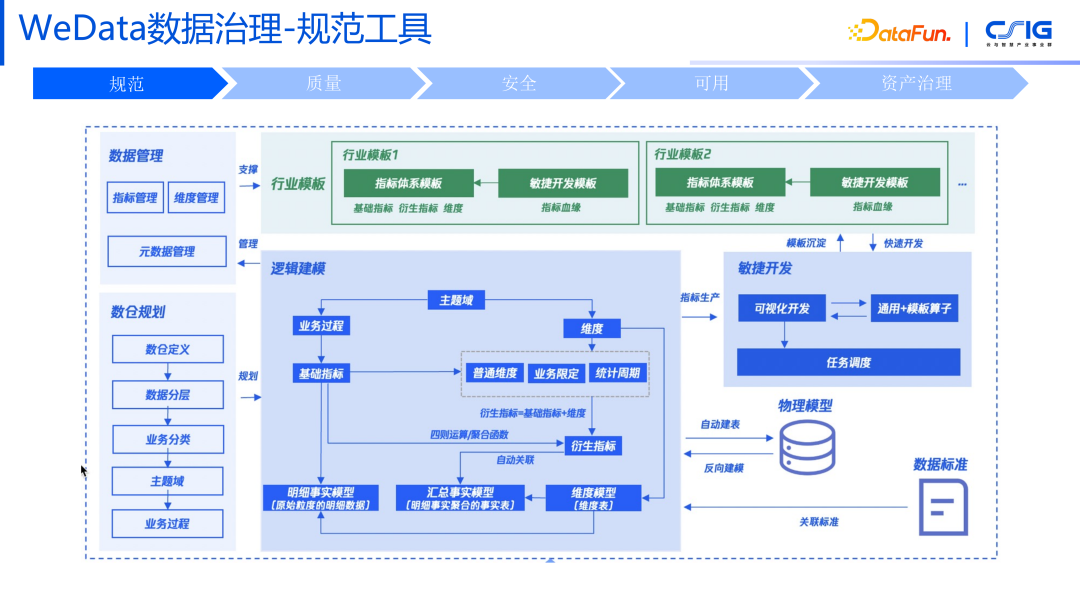
规范化工具可以分成三个部分,第一个部分就是数据管理,包括指标的管理,维度管理和元数据管理。第二部分是数仓规划,包括数仓定义,数据分层,业务分类,定义主题域业务过程。这一套规范定义完成了之后,还需要进行物化。物化指的是我们在生产数据的时候,将逻辑模型和真实的物理关联起来。此外,因为对接了很多不同行业的客户,我们也形成了不同行业的行业模板,可以在行业模板的基础上,完成企业体系标准的构建。
4. WeData数据治理——质量工具 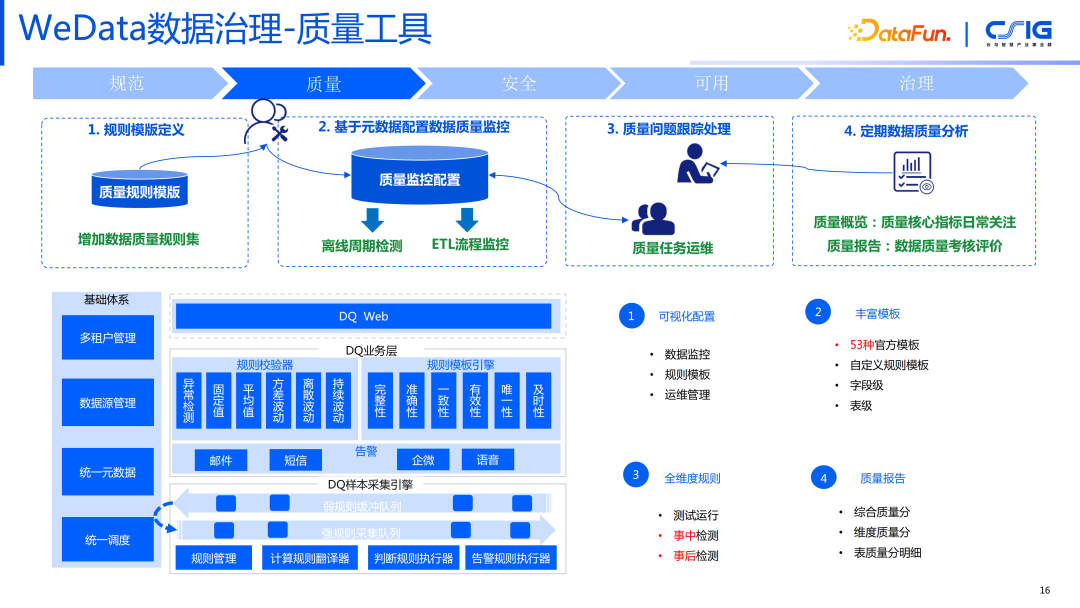
质量工具要完成的过程分成 4 步: 第一步,定义规 则,确定数据质量衡量的标准是什么,形成质量规则库。规则又分成两部分,首先会有一些基础的规则,包括基础的空表的检测,数据行数检测,准确性或者唯一性的检测,在常规模板里面包括了均值的比较,波动率等指标;同时还可以通过自定义 SQL 的方式来完成具有业务特性的规则校验。
第二步,规则确定好后,需要把这个规则和我们的数据本身进行关联,去达到一个质量监控的效果。一般来说有两种形态,第一种形态就是事中在 ETL 的流程中进行监控,挂载到开发任务上去。当数据生产之后,去检查这个数据是否符合我们的质量规则,如果不符合可以进行阻断式的操作。第二种形态是离线周期性的检测,例如检测各分区的数据质量情况。
第三步,当发现数据问题之后,会进行一次数据问题的运维。一般情况下,数据都是会上下波动的,但如果波动超过了一定范围,则会发出报警。例如,一张表每天都应该有 1000 行,但是今天只有 500 行,可能这个数据的产出就有问题了,或者是其他一个业务导致的,这个时候会产生数据质量的告警,通知到相关的责任人,告警也不是处理的终点,我们会有质量报警的工单体系,当告警通知到责任人后,如果他觉得这个问题需要别人来参与的话,可以进行转单,直到这个的数据流程单被处理结束,最终形成一个问题记录进行归档,如果被认为是典型问题的话,还可以进行记录,在后面有其他人遇到类似问题的时候,可以借鉴处理。
第四步,有定期的质量报告的分析,针对哪些表经常会被阻塞,哪些任务经常会发生告警,把这种经常性出现问题的表找出来。 5. WeData 数据治理——安全工具 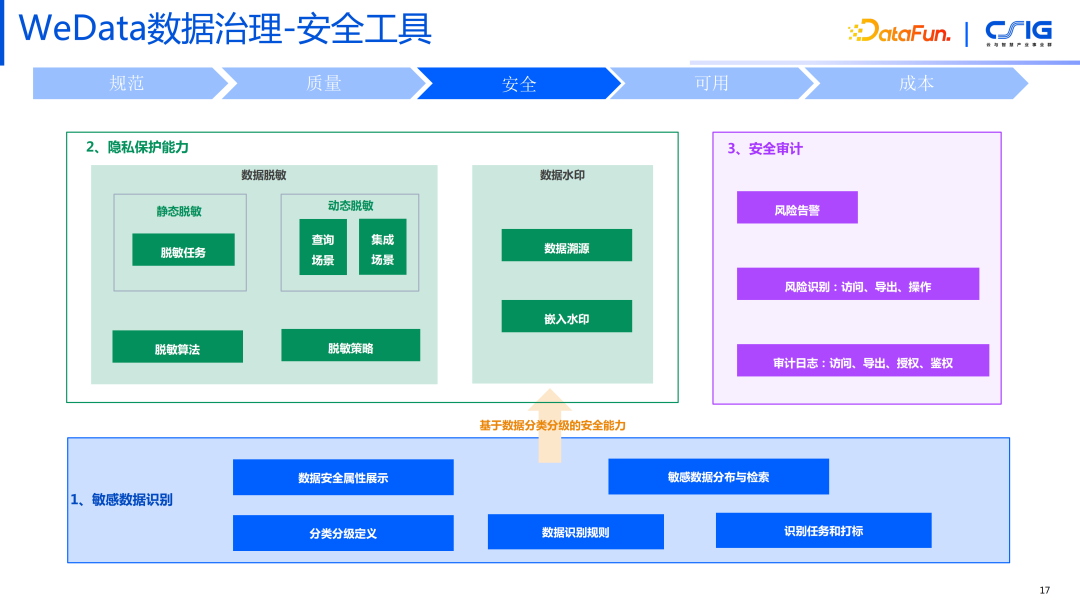
数据安全工具从三个方面进行治理:
从安全的角度进行数据的分类分级,确定数据是内部数据,还是敏感数据,还是机密性数据,这时就需要分级及分类的定义。此外需要提供规则识别的能力,通过这样的规则确定什么样的数据才是机密的数据 or 敏感的数据。比如在当前疫情反复的情况下,很可能会采集到很多姓名、性别、身份证这样的机密信息。我们可以做一个任务去管理数据扫描,扫描完之后把数据的分类进行打标,因为数据安全的分类、分级本质上也是定义在元数据上面的一种信息,扫描识别之后会存在底层元数据信息里面,让数据使用者知道谨慎地使用这些数据。
包括两种形式:第一种是常规的静态脱敏,可以把数据进行一个脱敏任务,到目标端形成一个脱敏后的数据。例如对身份证号码手机号登录,会进行打码处理,然后才能对外的输出。第二种是动态脱敏,跟平台工具紧密相关,比如数据集成的过程中,可以进行数据的加密,在数据查询时能够检索到。之后在数据分享时,就产生水印,水印支持溯源,进行一系列的隐私保护。
数据已经发出去之后,是我们的安全审计,哪些人访问、导出、下载过,尤其针对敏感数据。
6. WeData 数据治理——元数据资产管理工具 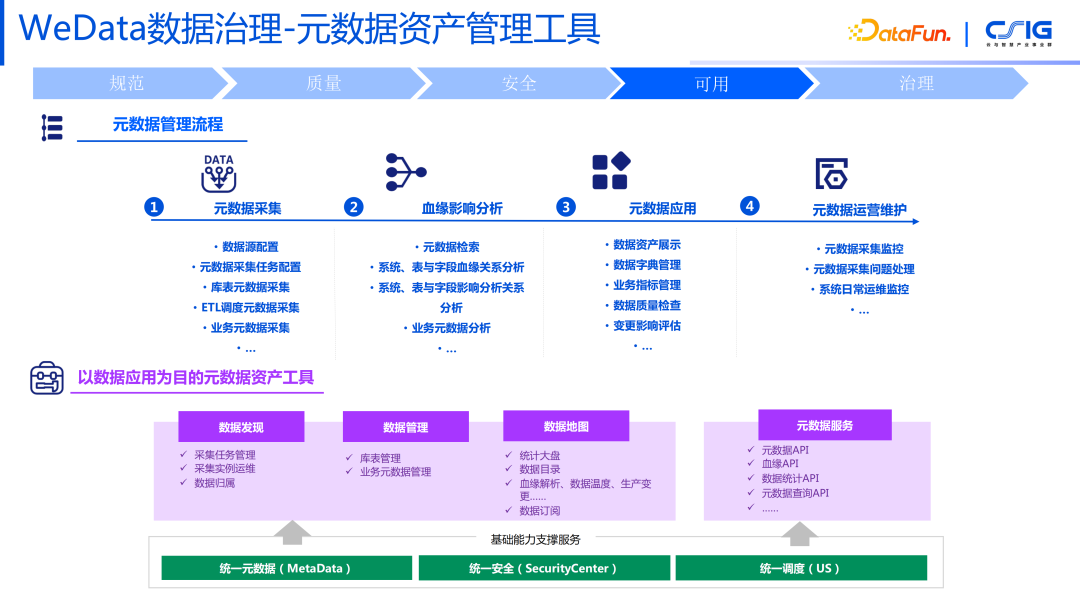
数据可用性治理包含三个步骤:
第一步,提高数据搜索能力。如何能快速的去定位到想要的数据,包括全域内大搜的能力,因为作为一个业务方要去使用某个数据时,要知道企业内部是否有这个数据,如果没有那么谁可以去生产这部分的数据,如果有的话该找谁去申请以及如何去用这个数据,所以要在企业的范围内有一个全局的快捷的数据定位能力。
第二步,提高数据理解能力。找到数据后,业务方不是特别清楚数据的具体情况,但是我可以根据其他用户的使用情况(比方这份数据的热度和打份情况),把数据作为一个商品,快速的给到想要使用这些数据的人。将技术元信息和业务元信息全部呈现给用户,让他知道这个数据的全貌。
第三步,提高数据应用能力 ,查到数据后如何去应用。从数据使用者的角度,需要以何种形态去呈现,让数据使用者能够更好地使用数据。
7. WeData 数据治理——治理实践落地 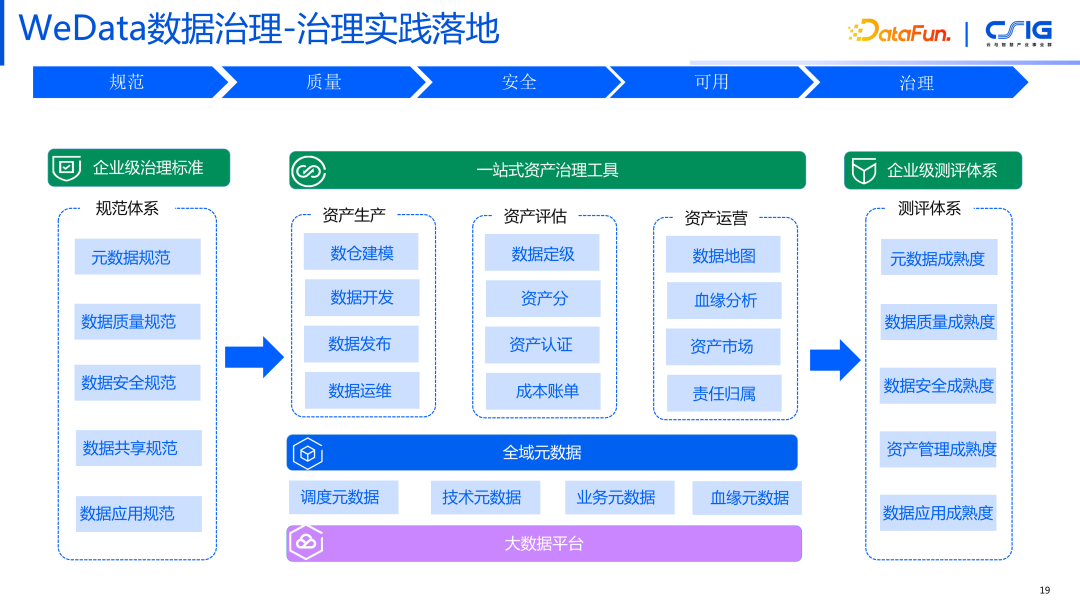
在前面这几部分,包括规范、质量、安全以及可用性的基础上,我们对数据进行了深度的治理。治理达成的效果就是降本增效,降低不需要的那些数据的成本,提高数据的使用率。在资产治理模块对资产进行打分,形成企业级的评级体系。让组织治理者根据质量分进行治理的落地,去掉那些不常用的、冷的数据、数据孤岛的数据、重复的数据,再把有效的数据更好地利用起来。
04 问答环节
Q1:元数据打了安全标签之后,怎么向下游的模型或者任务进行传递?
A1:Wedata 在做元数据安全打标的时候都是相互独立的,不会根据血缘关系进行传递,因为上下游可能是不同的业务线,对敏感性的定义不同。
Q2:请问业务元数据该如何采集梳理,业务的元数据具体包括哪些内容?A2:按照我们资产资产治理的理论,业务元数据分为 5 类,第一类是规范性元数据,属于哪个分层哪个主题域业务域;第二类是质量元数据;第三类是安全元数据;第四类是成本元数据;第五类是应用元数据,包括使用上的温度。一般从这个 5 个维度去了解业务元信息。
Q3:请问 tbds 和 wedata 的关系是什么?A3:tbds 指的是我们底层的数据处理引擎,腾讯大数据产品主要分为两部分,共有云部分是 emr 和 cdw 数据仓库等产品,私有云上底层引擎体系管叫 tbds。其中,wedata 是指的数据治理工具。
今天的分享就到这里,谢谢大家。
|分享嘉宾|

王浩仙
腾讯云大数据平台产品中心 技术产品
从事大数据产品领域7年,曾就职于金山、阿里,目前作为腾讯云大数据平台产品中心数据治理产品负责人。