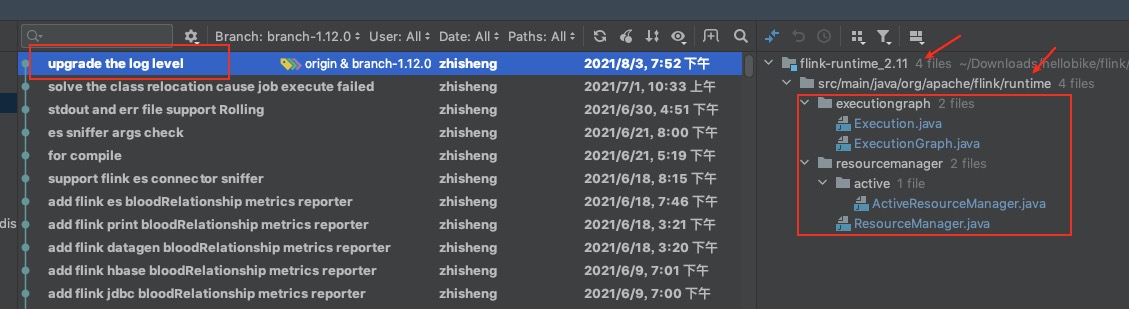
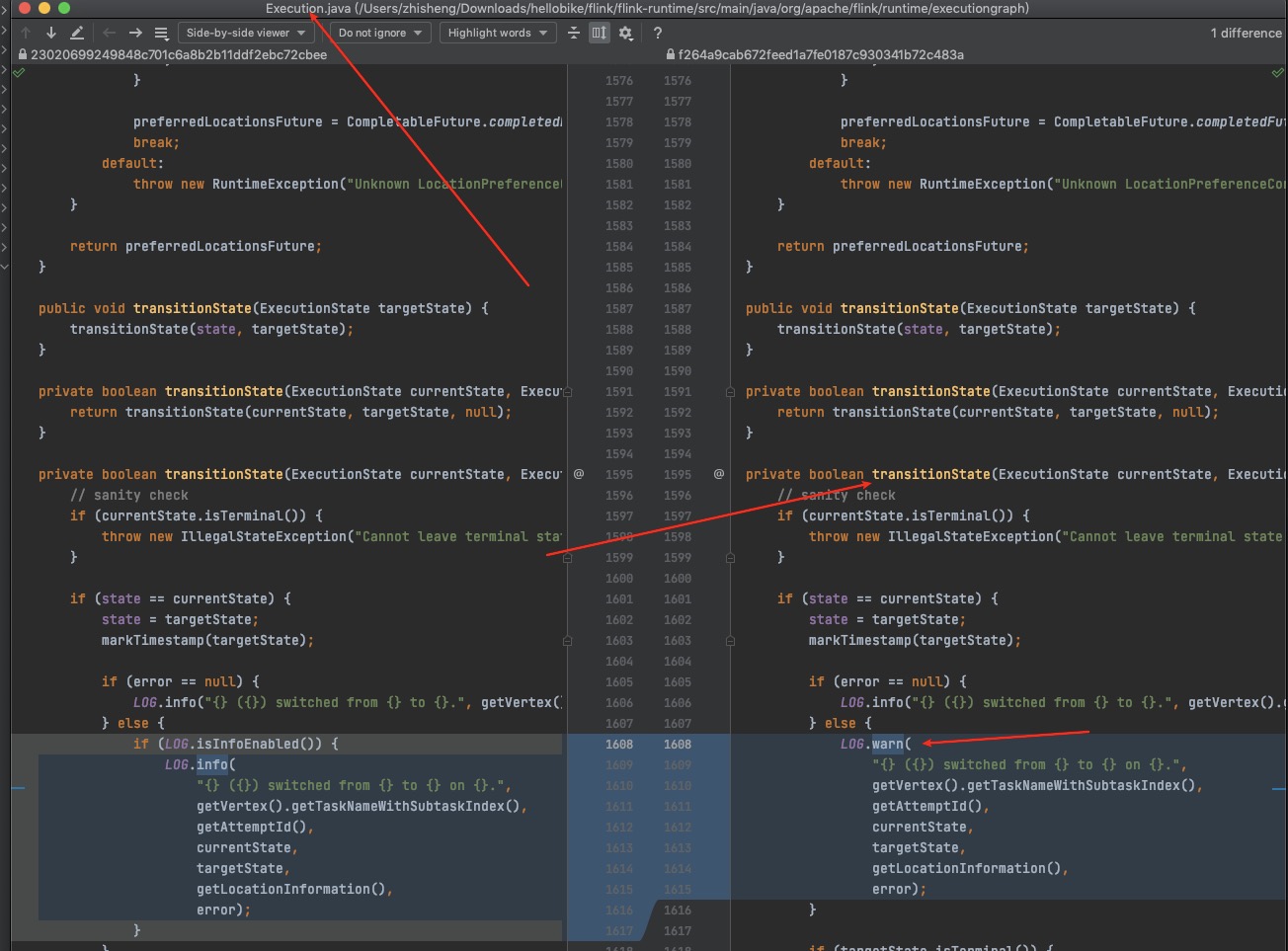
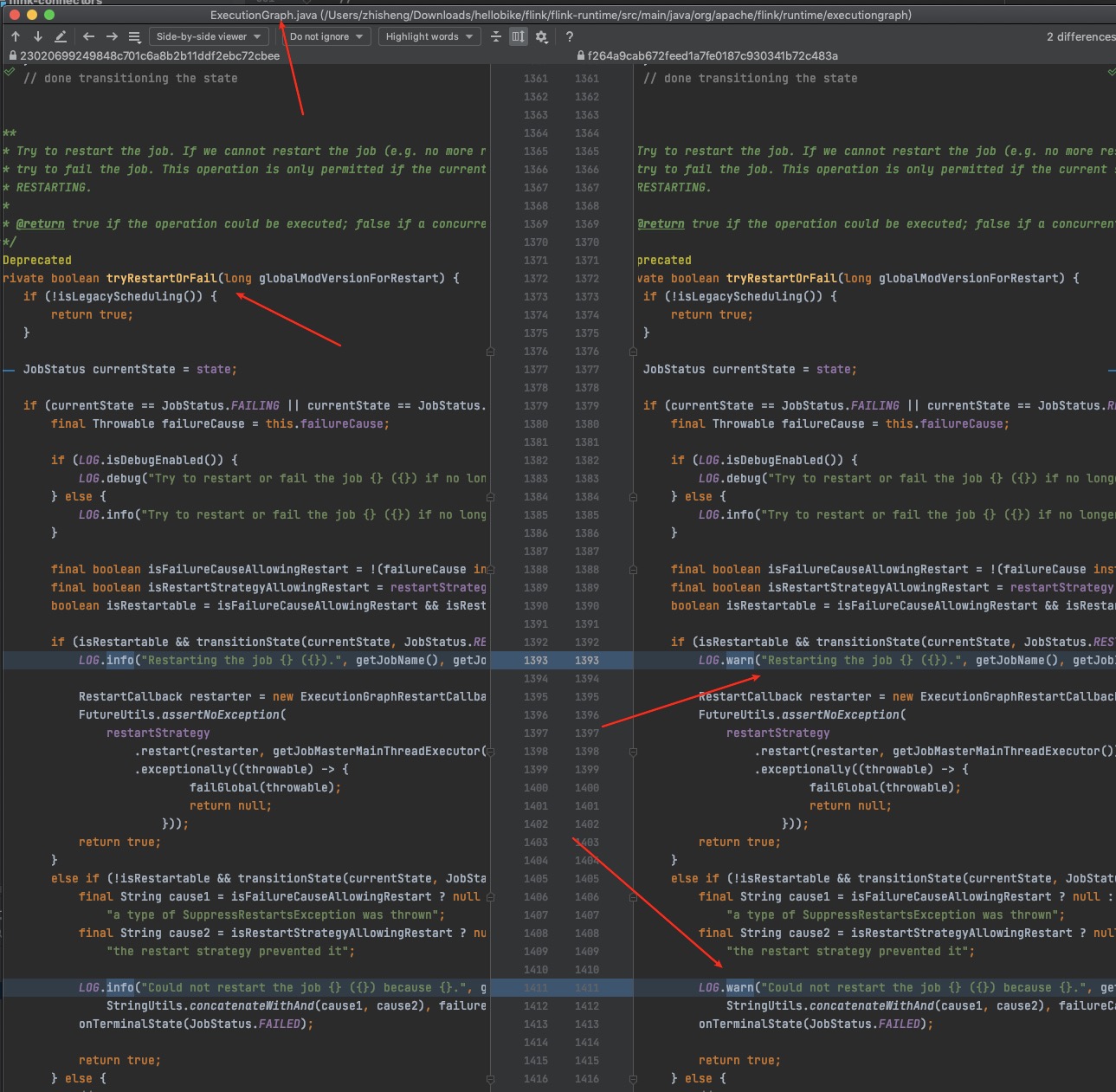
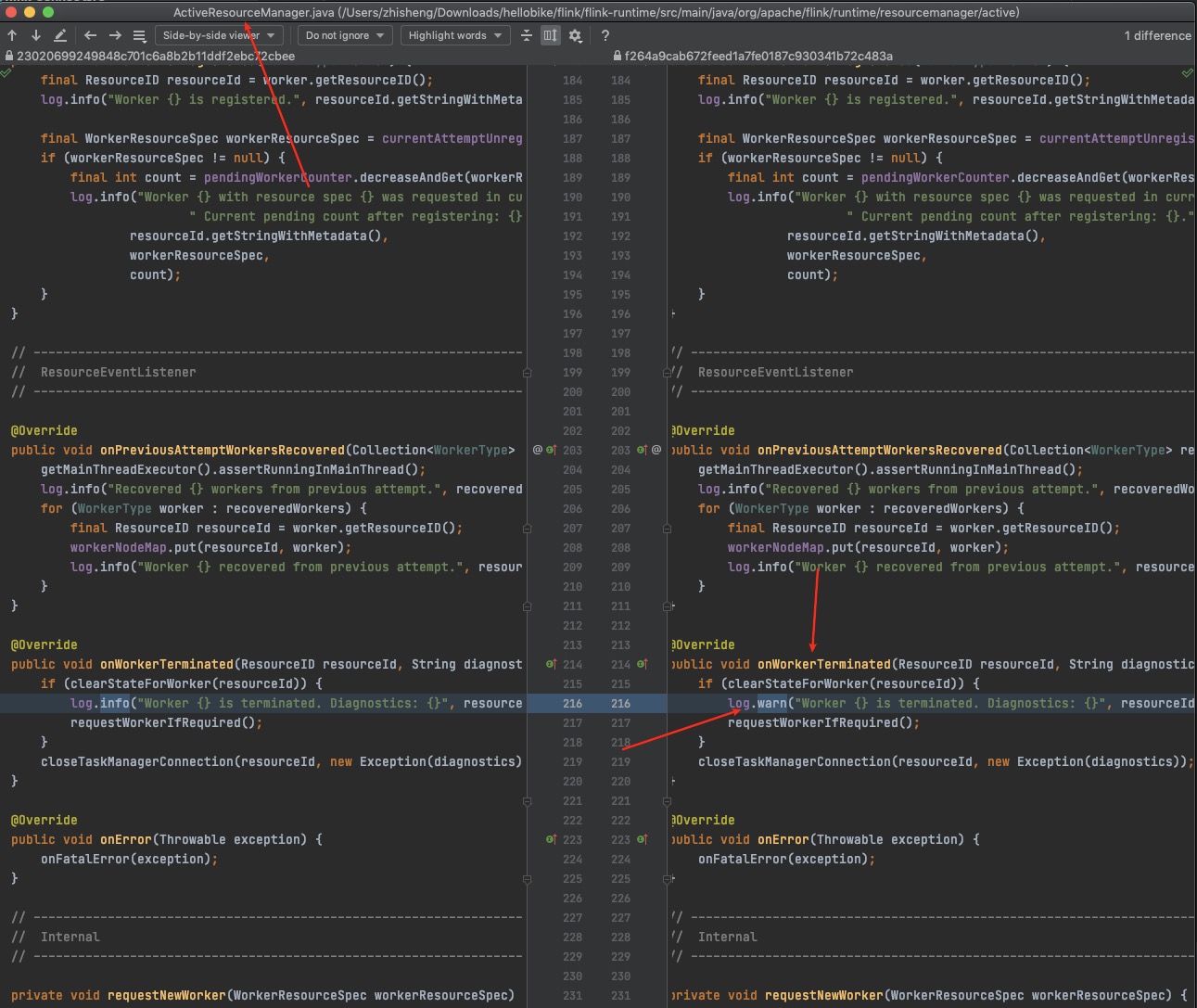
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
| package com.zhisheng.log.appender;
import com.zhisheng.flink.model.LogEvent;
import com.zhisheng.flink.util.ExceptionUtil;
import com.zhisheng.flink.util.JacksonUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonProcessingException;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.config.ConfigException;
import org.apache.logging.log4j.core.Filter;
import org.apache.logging.log4j.core.Layout;
import org.apache.logging.log4j.core.appender.AbstractAppender;
import org.apache.logging.log4j.core.config.Property;
import org.apache.logging.log4j.core.config.plugins.Plugin;
import org.apache.logging.log4j.core.config.plugins.PluginAttribute;
import org.apache.logging.log4j.core.config.plugins.PluginElement;
import org.apache.logging.log4j.core.config.plugins.PluginFactory;
import org.apache.logging.log4j.core.config.plugins.validation.constraints.Required;
import java.io.File;
import java.io.Serializable;
import java.net.InetAddress;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.UUID;
@Slf4j
@Plugin(name = "KafkaLog4j2Appender", category = "Core", elementType = "appender", printObject = true)
public class KafkaLog4j2Appender extends AbstractAppender {
private final String source;
private final String topic;
private final String level;
private final Producer<String, String> producer;
private String appId;
private String containerId;
private String containerType;
private final String taskName;
private final String taskId;
private String nodeIp;
protected KafkaLog4j2Appender(String name, Filter filter, Layout<? extends Serializable> layout, boolean ignoreExceptions, Property[] properties, String source, String bootstrapServers, String topic, String level) {
super(name, filter, layout, ignoreExceptions, properties);
this.source = source;
this.topic = topic;
this.level = level;
Properties envProperties = System.getProperties();
Map<String, String> envs = System.getenv();
String clusterId = envs.get("CLUSTER_ID");
if (clusterId != null) {
//k8s cluster
appId = clusterId;
containerId = envs.get("HOSTNAME");
if (envs.get("HOSTNAME").contains("taskmanager")) {
containerType = "taskmanager";
} else {
containerType = "jobmanager";
}
//k8s 物理机器 ip
if (envs.get("_HOST_IP_ADDRESS") != null) {
nodeIp = envs.get("_HOST_IP_ADDRESS");
}
} else {
//yarn cluster
String logFile = envProperties.getProperty("log.file");
String[] values = logFile.split(File.separator);
if (values.length >= 3) {
appId = values[values.length - 3];
containerId = values[values.length - 2];
String log = values[values.length - 1];
if (log.contains("jobmanager")) {
containerType = "jobmanager";
} else if (log.contains("taskmanager")) {
containerType = "taskmanager";
} else {
containerType = "others";
}
} else {
log.error("log.file Property ({}) doesn't contains yarn application id or container id", logFile);
}
}
taskName = envProperties.getProperty("taskName", null);
taskId = envProperties.getProperty("taskId", null);
Properties props = new Properties();
for (Property property : properties) {
props.put(property.getName(), property.getValue());
}
if (bootstrapServers != null) {
props.setProperty("bootstrap.servers", bootstrapServers);
} else {
throw new ConfigException("The bootstrap servers property must be specified");
}
if (this.topic == null) {
throw new ConfigException("Topic must be specified by the Kafka log4j appender");
}
String clientIdPrefix = taskId != null ? taskId : appId;
if (clientIdPrefix != null) {
props.setProperty("client.id", clientIdPrefix + "_log");
}
if (props.getProperty("acks") == null) {
props.setProperty("acks", "0");
}
if (props.getProperty("retries") == null) {
props.setProperty("retries", "0");
}
if (props.getProperty("batch.size") == null) {
props.setProperty("batch.size", "16384");
}
if (props.getProperty("linger.ms") == null) {
props.setProperty("linger.ms", "5");
}
if (props.getProperty("compression.type") == null) {
props.setProperty("compression.type", "lz4");
}
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer<>(props);
}
@Override
public void append(org.apache.logging.log4j.core.LogEvent event) {
try {
if (level.contains(event.getLevel().toString().toUpperCase()) && !event.getLoggerName().contains("xxx")) { //控制哪些类的日志不收集
producer.send(new ProducerRecord<>(topic, appId, subAppend(event)));
}
} catch (Exception e) {
log.warn("Parsing the log event or send log event to kafka has exception", e);
}
}
private String subAppend(org.apache.logging.log4j.core.LogEvent event) throws JsonProcessingException {
LogEvent logEvent = new LogEvent();
Map<String, String> tags = new HashMap<>();
String logMessage = null;
try {
InetAddress inetAddress = InetAddress.getLocalHost();
tags.put("host_name", inetAddress.getHostName());
tags.put("host_ip", inetAddress.getHostAddress());
} catch (Exception e) {
log.error("Error getting the ip and host name of the node where the job({}) is running", appId, e);
} finally {
try {
logMessage = ExceptionUtil.stacktraceToString(event.getThrown());
logEvent.setContent(logMessage);
} catch (Exception e) {
if (logMessage != null) {
logMessage = logMessage + "\n\t" + e.getMessage();
}
logEvent.setContent(logMessage);
} finally {
logEvent.setId(UUID.randomUUID().toString());
logEvent.setTimestamp(event.getTimeMillis());
logEvent.setSource(source);
if (logMessage != null) {
logMessage = event.getMessage().getFormattedMessage() + "\n" + logMessage;
} else {
logMessage = event.getMessage().getFormattedMessage();
}
logEvent.setContent(logMessage);
StackTraceElement eventSource = event.getSource();
tags.put("class_name", eventSource.getClassName());
tags.put("method_name", eventSource.getMethodName());
tags.put("file_name", eventSource.getFileName());
tags.put("line_number", String.valueOf(eventSource.getLineNumber()));
tags.put("logger_name", event.getLoggerName());
tags.put("level", event.getLevel().toString());
tags.put("thread_name", event.getThreadName());
tags.put("app_id", appId);
tags.put("container_id", containerId);
tags.put("container_type", containerType);
if (taskId != null) {
tags.put("task_id", taskId);
}
if (taskName != null) {
tags.put("task_name", taskName);
}
if (nodeIp != null) {
tags.put("node_ip", nodeIp);
}
logEvent.setTags(tags);
}
}
return JacksonUtil.toJson(logEvent);
}
@PluginFactory
public static KafkaLog4j2Appender createAppender(@PluginElement("Layout") final Layout<? extends Serializable> layout,
@PluginElement("Filter") final Filter filter,
@Required(message = "No name provided for KafkaLog4j2Appender") @PluginAttribute("name") final String name,
@PluginAttribute(value = "ignoreExceptions", defaultBoolean = true) final boolean ignoreExceptions,
@Required(message = "No bootstrapServers provided for KafkaLog4j2Appender") @PluginAttribute("bootstrapServers") final String bootstrapServers,
@Required(message = "No source provided for KafkaLog4j2Appender") @PluginAttribute("source") final String source,
@Required(message = "No topic provided for KafkaLog4j2Appender") @PluginAttribute("topic") final String topic,
@Required(message = "No level provided for KafkaLog4j2Appender") @PluginAttribute("level") final String level,
@PluginElement("Properties") final Property[] properties) {
return new KafkaLog4j2Appender(name, filter, layout, ignoreExceptions, properties, source, bootstrapServers, topic, level);
}
@Override
public void stop() {
super.stop();
if (producer != null) {
producer.close();
}
}
}
|