Stable Diffusion 模型技术架构与原理
- - 简单之美Stable Diffusion 是一个文本到图像(txt2img)的潜在扩散模型(LDM),是由 CompVis、Stability AI 和 LAION 的研究人员实现并开源的. 我们站在 Stable Diffusion 模型应用用户的角度来看,其实没有多么复杂,核心就是根据文本生成图像,其中可以通过一些技巧或者说调整用户参数,来改变文本生成图像的过程,从而达到优化最终生成图像的目的.
Stable Diffusion 是一个文本到图像(txt2img)的潜在扩散模型(LDM),是由 CompVis、Stability AI 和 LAION 的研究人员实现并开源的。我们站在 Stable Diffusion 模型应用用户的角度来看,其实没有多么复杂,核心就是根据文本生成图像,其中可以通过一些技巧或者说调整用户参数,来改变文本生成图像的过程,从而达到优化最终生成图像的目的。但是,Stable Diffusion 底层技术的角度看,这个过程非常非常复杂,所以我们这里先给出模型的 Architecture Overview,先从总体上看整个架构或结构是什么样的,然后深入到每一个部分去了解具体的技术细节或原理。
1 模型架构概览
从 High-level 的视角,Stable Diffusion 模型都包含哪些主要组件,以及整体的处理流程,我们引用了 The Illustrated Stable Diffusion 一文中的一个图,并在原图上做了微小改动(为了方便理解添加了表示三个核心步骤的数字序号),来表示 Stable Diffusion 模型的处理机制,如下图所示:
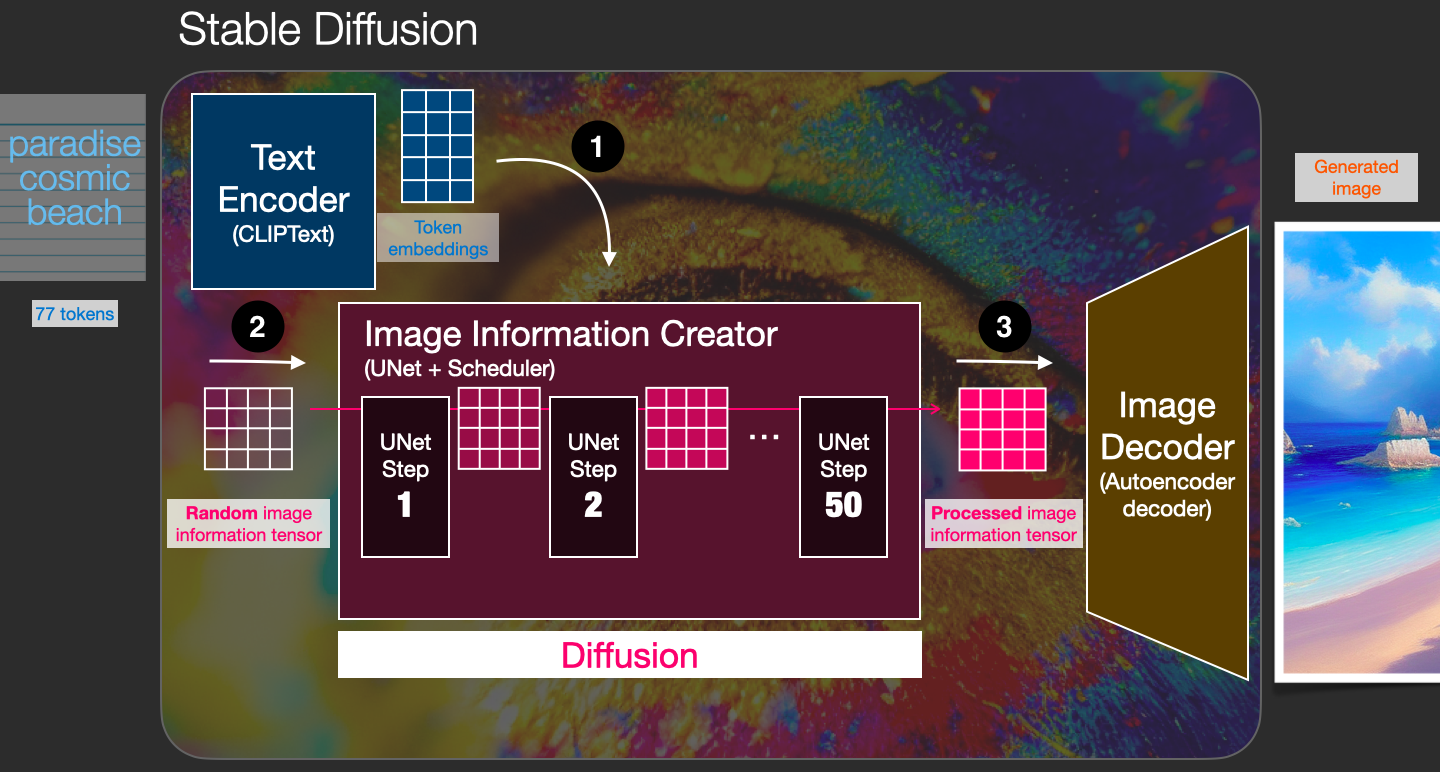
基于上图,我们分步骤描述一下 txt2image 处理的整个过程:
首先,输入 Prompt 提示词 “paradise, cosmic, beach”,经过 Text Encoder 组件的处理,将输入的 Prompt 提示词转换成 77×768 的 Token Embeddings,该 Embeddings 输入到 Image Information Creator 组件;
然后,Random image information tensor 是由一个 Latent Seed(Gaussian noise ~ N(0, 1)) 随机生成的 64×64 大小的图片表示,它表示一个完全的噪声图片,作为 Image Information Creator 组件的另一个初始输入;
接着,通过 Image Information Creator 组件的处理(该过程称为 Diffusion),生成一个包含图片信息的 64×64 的 Processed image tensor,该输出包含了前面输入 Prompt 提示词所具有的语义信息的图片的信息;
最后,上一步生成的 Processed image tensor 信息经过 Image Decoder 组件处理后生成最终的和输入 Prompt 提示词相关的 512×512 大小的图片输出。
最终使用 Stable Diffusion 模型来进行推理,得到我们需要的根据提示词生成的图像(当然 Stable Diffusion 模型不只是能够实现 txt2image,也可以实现其它的推理功能,如 image2image、txt + imange => image)。我们通过一个详细的流程图,展示整个推理的过程,如下图所示:
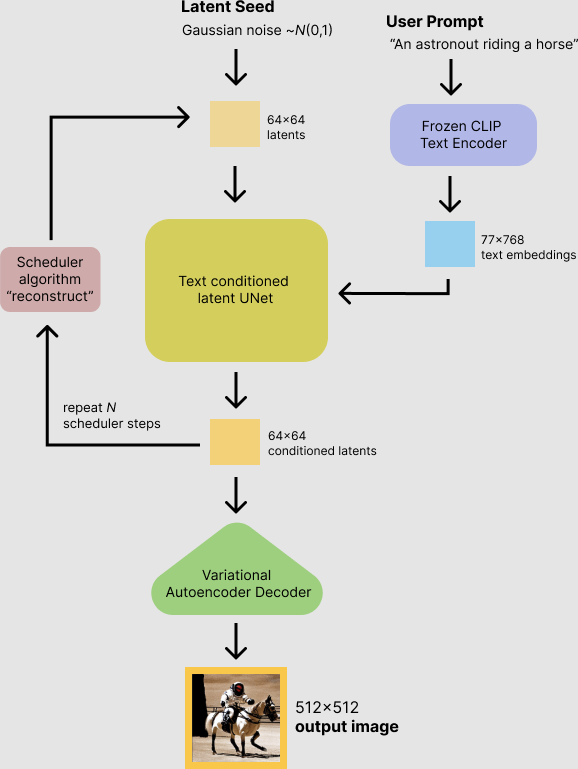
下面,我们从组件的视角来理解,上面提到的其中三个核心组件,深入到这些组件的内部来了解具体都做了什么处理工作。
2 Text Encoder
Text Encoder 是用来处理输入的 Prompt 提示词的,将其转换成对应的 Token Embeddings,它使用了由 OpenAI 开发实现的 ClipText 模型,该模型是基于 BERT 实现的预训练语言模型(Language Model),模型包含 63M 参数。如果对语言模型有所了解,从模型中提取 Token Embedding 是最基础的功能,Stable Diffusion 模型使用 ClipText 将输入 Prompt 提示词转换成对应的 Token Embeddings。
3 Image Information Creator
Image Information Creator 是最核心也最复杂的组件,它是在原始的 image2image 处理流程中进行改造和优化,使用了输入 Prompt 提示词给定的语义信息,从一个随机的 Random image information tensor 经过迭代生成了最终包含图片所有信息的 Processed image tensor。Image Information Creator 包含一个神经网络 UNet 和调度器 Scheduler,实现的核心功能就是 Diffusion,它是在 Latent Space 中实现的,其中包含一个 Forward Diffusion 过程和一个 Reverse Diffusion 过程。
为了直观理解,我们将看一下在 UNet 网络训练过程中,初始输入的 Random image information tensor 是如何逐步加入 Prompt 提示词语义信息并影响最终生成的图片质量,假设 UNet 网络去噪(Denoising)迭代 50 次,直接把每次的迭代结果通过 Image Decoder 解码成图像,如下图所示:
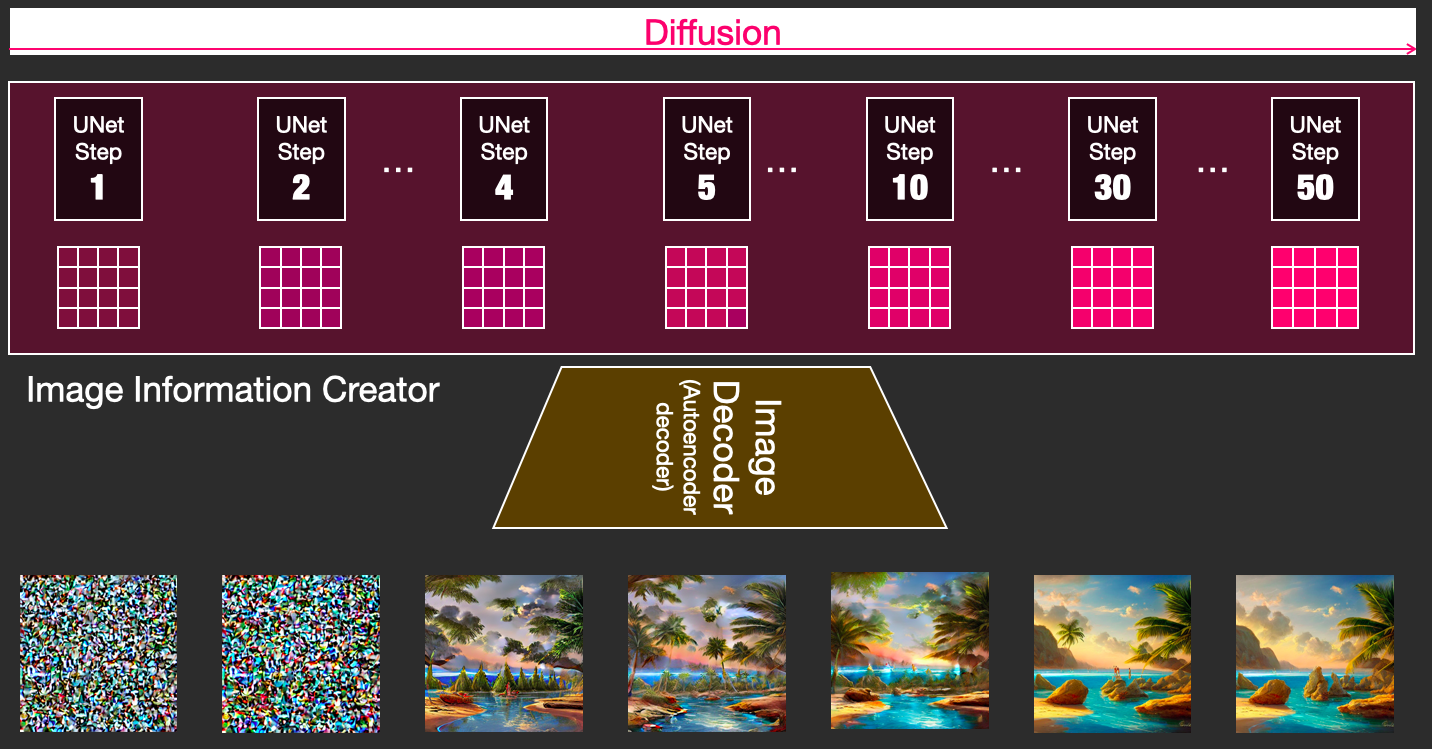
可见,最初的 Random image information tensor 完全是噪声数据,经过一次一次地迭代去噪,注入提示词语义,图片逐渐具备了我们所期望的内容和质量。
3.1 神经网络视角:UNet 网络架构
UNet 是一个 image2image 的神经网络,更具体一点应该是一个 CNN + inverted CNN 网络,主要目标就是去噪(Denoising),从而生成对应的图像。我们从神经网络的视角,看下 UNet 网络的架构,如下图所示:
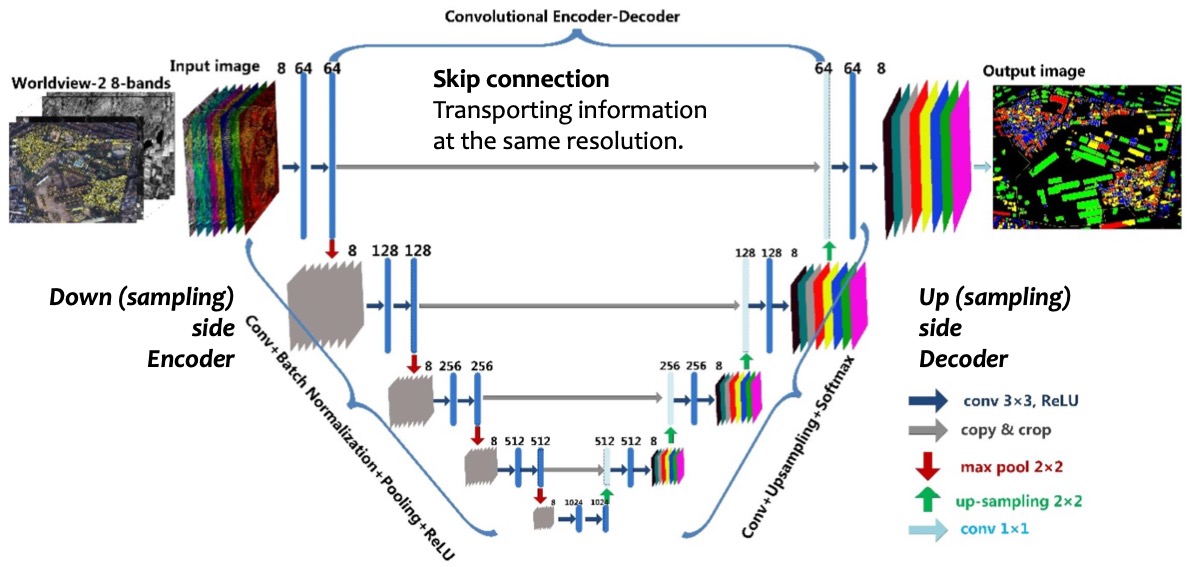
上图中没有体现对应的输入 Prompt 提示词语义信息。在 Stable Diffusion 模型中,UNet 网络各层的构建过程,如下所示:
(conv_in): Conv2d(4, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (time_proj): Timesteps() (time_embedding): TimestepEmbedding (linear_1): Linear(in_features=320, out_features=1280, bias=True) (act): SiLU() (linear_2): Linear(in_features=1280, out_features=1280, bias=True) (down_blocks): (0): CrossAttnDownBlock2D (1): CrossAttnDownBlock2D (2): CrossAttnDownBlock2D (3): DownBlock2D (up_blocks): (0): UpBlock2D (1): CrossAttnUpBlock2D (2): CrossAttnUpBlock2D (3): CrossAttnUpBlock2D (mid_block): UNetMidBlock2DCrossAttn (attentions): (resnets): (conv_norm_out): GroupNorm(32, 320, eps=1e-05, affine=True) (conv_act): SiLU() (conv_out): Conv2d(320, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
上面有添加对应的提示词语义信息,比如 CrossAttnDownBlock2D、CrossAttnUpBlock2D。为了更详细、直观地表示 UNet 网络中的 Attention 信息,我们通过下图来看图片的 Image Tensor 和输入 Prompt 的 Embedding(Text Attention)是如何一起在 UNet 网络中整合在一起的:
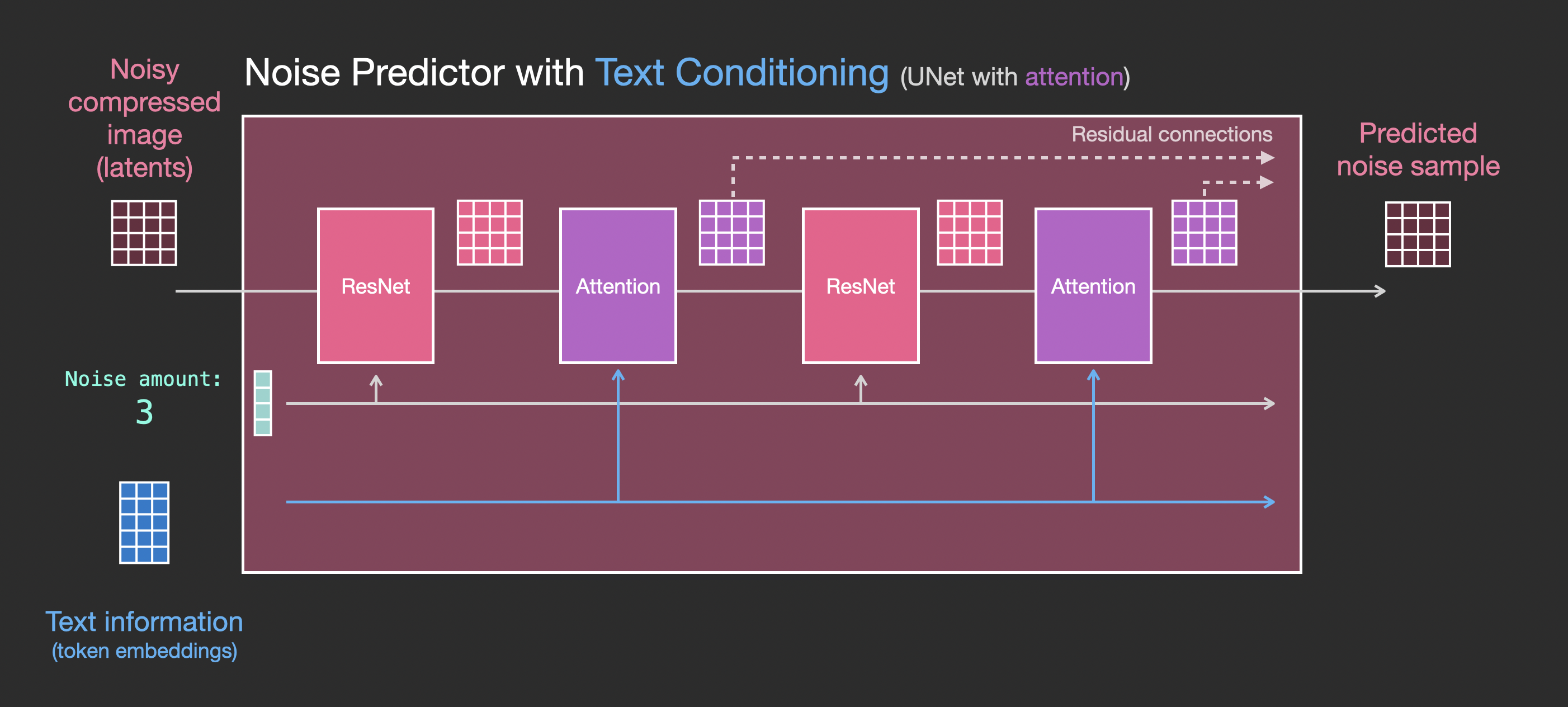
3.2 图像转换视角:原始图像 + 提示词 => 最终图像
从图像转换视角看,我们不能不提到 Pixel Space 和 Latent Space。对于最开始输入的图像,它是在 Pixel Space 中,使用像素表示,这个我们能够比较容易感知和理解。当输入的图像、 Prompt 提示词分别被转换成 Image Embeddings、Token Embeddings 之后,后续的操作就开始进入 Latent Space 中,通过向量来表示和并进行各种处理操作,得到了包含 “原始图像 + 提示词” 信息的图片向量数据信息(Latent Image),最后要把这个生成图片向量数据信息,从 Latent Space 再映射到 Pixel Space,得到我们最终需要生成的视觉图像。这最后一步的映射转换是在 Image Decoder 组件中进行的。
为了直观,我们描述这个过程是如何一步一步完成的(引用文章 How does Stable Diffusion work? 中给出的分析),步骤如下所示:
第 1 步:输入图像被 Encode 到 Latent Space
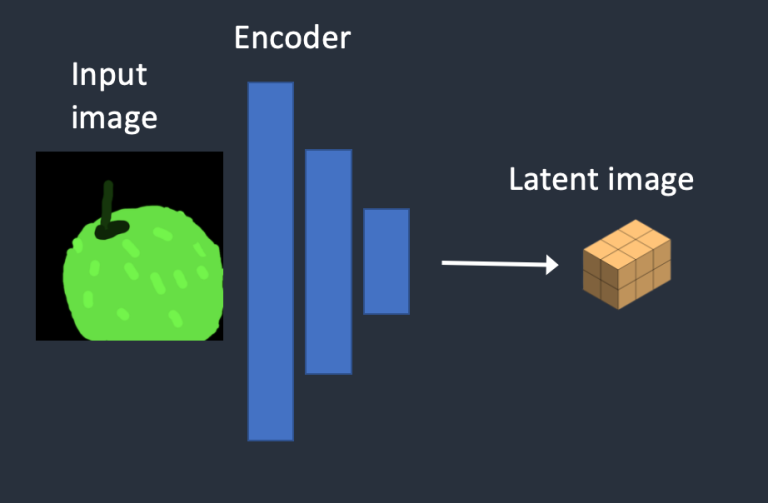
原始图像转换成了 Latent Space 中的向量表示,我们称为 Latent Image。
第 2 步:向图像中添加噪声
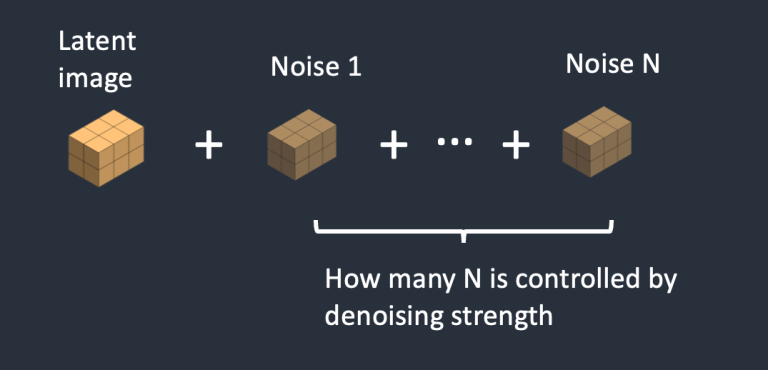
通过有控制地向 Latent Image 中添加噪声,0 表示没有添加噪声,数字 N 越大表示加入的噪声越多,最后得到的是一个包含噪声的图像的向量数据表示。
第 3 步:输入 Latent Space 中的带噪声图像和 Prompt 提示词,Noise Predictor 预测其中的噪声信息 Latent Noise
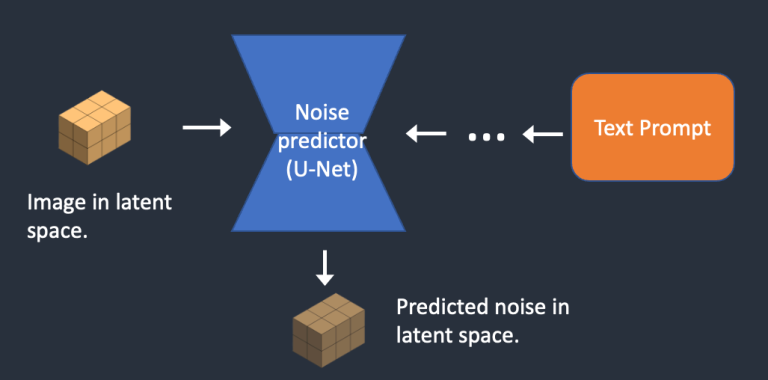
上面输出的的结果是一个 4x64x64 的噪声 Tensor。
第 4 步:从 Latent Image 中减去 Latent Noise,得到 New Latent Image
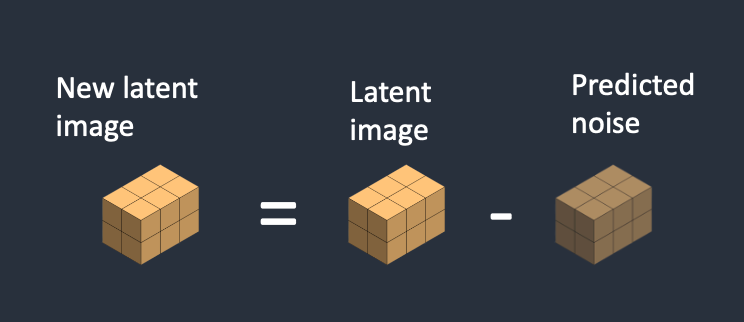
第 5 步:VAE Decoder 将 Latent Image 转换成 Pixel Space 中的图像
前面 3~4 步骤会循环执行指定次数,这是一个 UpSampling 的过程,得到最终的 Latent Image,最后在执将 Latent Image 转换成最终的图像,如下图所示:
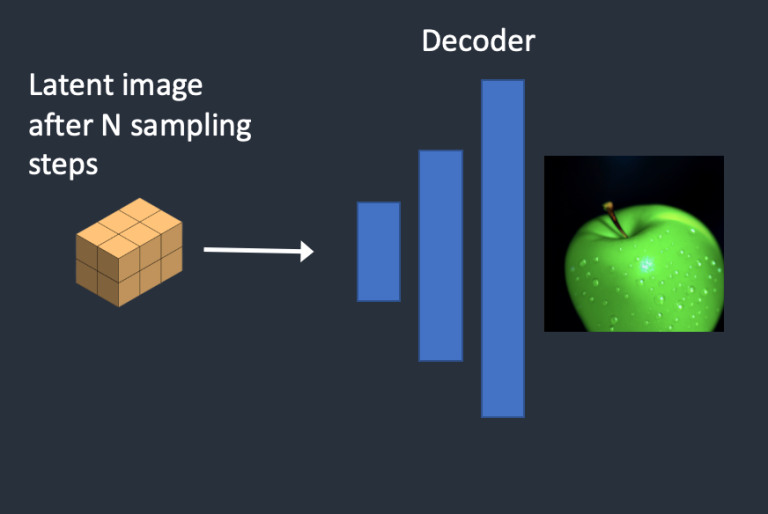
4 Image Decoder
最后 Image Decoder 根据得到的 Latent Image,基于 VAE Decoder 生成最终的图像。
关于 VAE(Variational Autoencoder),它是一个神经网络,由 Encoder 和 Decoder 两部分组成,如下图所示:
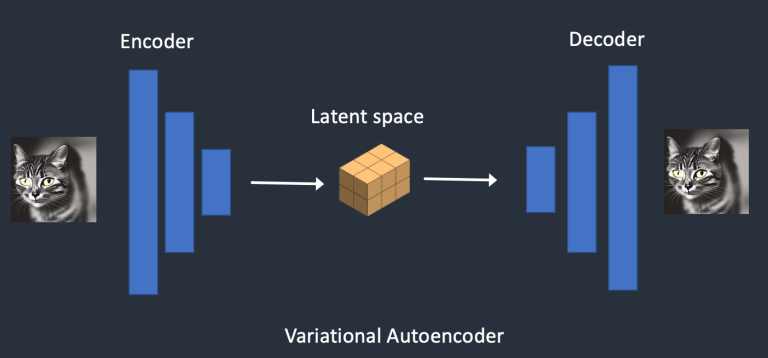
其中,Encoder 能够将一个图像压缩到低维空间表示,在 Stable Diffusion 模型中,将原始输入图像通过 Encode 转换成 Latent Space 中的向量表示 Latent Image;Decoder 能够将一个压缩表示的图像向量数据转换成高维空间表示,在 Stable Diffusion 模型中将 Latent Space 中图像的向量表示 Latent Image 通过 Decode 转换成 Pixel Space 中的视觉图像。
5 参考资料