数据湖存储系统Paimon
- - 标点符Apache Paimon 是一个面向大数据生态系统的高性能数据湖存储系统. 它最初是由 Flink 社区开发的,旨在为大数据处理提供高效的存储解决方案. Apache Paimon(以前称为 Flink Table Store)是一个专为流处理和批处理而设计的数据湖存储系统. 它解决了现代数据处理中的一些关键问题,以下是一些主要的方面:.
Apache Paimon 是一个面向大数据生态系统的高性能数据湖存储系统。它最初是由 Flink 社区开发的,旨在为大数据处理提供高效的存储解决方案。
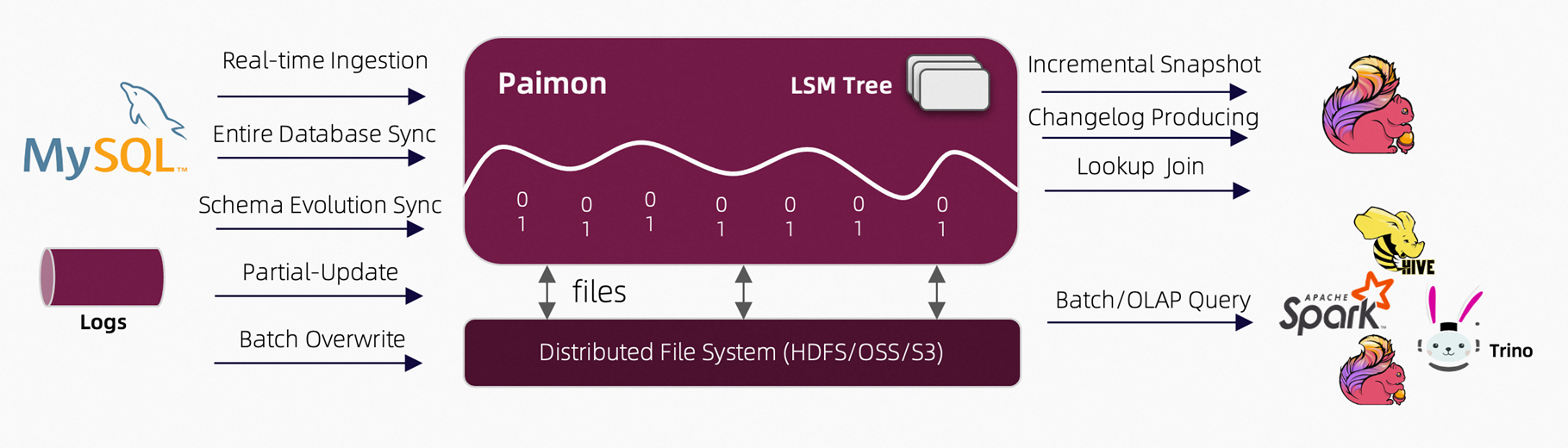
Apache Paimon(以前称为 Flink Table Store)是一个专为流处理和批处理而设计的数据湖存储系统。它解决了现代数据处理中的一些关键问题,以下是一些主要的方面:
通过解决这些问题,Apache Paimon 为需要处理大规模数据的企业提供了一种高效、灵活且一致的数据存储和处理解决方案。
设计目标
核心特性
目前Apache Paimon提供以下核心能力:
应用场景
社区和发展
Apache Paimon 是 Apache 软件基金会下的一个开源项目,受益于活跃的开发者社区和用户群体。其持续的发展和更新,使其不断适应大数据领域的新需求和新挑战。
Apache Paimon 的生态系统设计旨在与现有的大数据处理框架和工具无缝集成,从而提供灵活性和易用性。以下是关于 Paimon 在兼容性和集成方面的一些细节:
与 Hadoop 的兼容性:
与 Spark 的兼容性:
与 Flink 的兼容性:
与大数据处理框架的集成:
与数据湖和数据仓库的集成:
可扩展的插件体系:
通过与这些大数据生态系统的兼容性和集成能力,Apache Paimon 提供了一种灵活而强大的解决方案,能够在不改变现有基础设施的情况下提升数据处理能力。
Apache Paimon 是一种专为流处理和批处理设计的数据湖存储系统,其数据存储设计旨在提供高效的数据读写、更新和删除操作。
列式存储:
分区和分桶:
增量更新:
删除操作:
ACID 事务:
快照机制:
元数据存储:
Schema 演变:
高效的读取:
写入优化:
索引是提高数据查询性能的有效工具。在 Paimon 中,虽然具体的索引机制可能依赖于底层的存储和计算引擎,但一般支持以下几种常见的索引类型:
主键索引:
二级索引:
分区索引:
缓存机制通过在内存中存储数据的部分或全部,提高数据访问速度,减少对磁盘的 I/O 操作。
查询结果缓存:
数据块缓存:
元数据缓存:
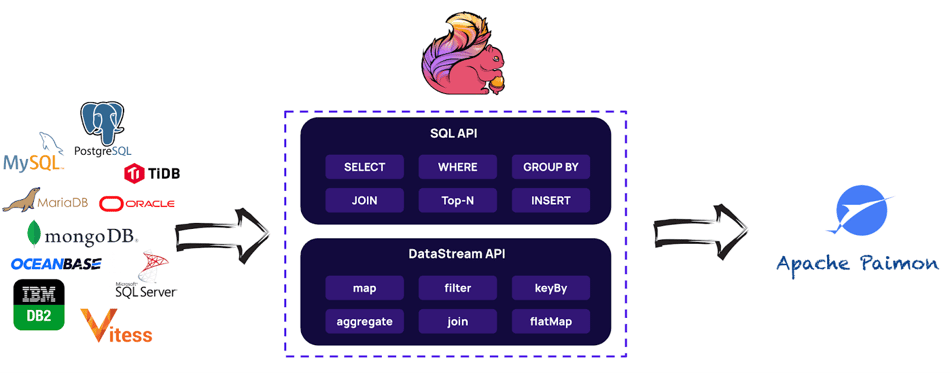
创建 Apache Paimon 表通常需要通过 SQL 语句来完成。Paimon 支持标准的 SQL 语法,可以使用各种计算框架(如 Apache Flink 或 Apache Spark)来执行这些 SQL 语句。
步骤:
示例代码:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class CreatePaimonTable {
public static void main(String[] args) throws Exception {
// 设置 Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建 Paimon 表
tableEnv.executeSql(
"CREATE TABLE paimon_table (" +
" id INT, " +
" name STRING, " +
" age INT, " +
" PRIMARY KEY (id) NOT ENFORCED" +
") WITH (" +
" 'connector' = 'paimon'," +
" 'path' = 'path/to/paimon/table'" +
")"
);
// 打印表信息
tableEnv.executeSql("DESCRIBE paimon_table").print();
// 执行作业
env.execute("Create Paimon Table");
}
}
步骤:
示例代码:
from pyspark.sql import SparkSession
# 创建 SparkSession
spark = SparkSession.builder \
.appName("Create Paimon Table") \
.config("spark.jars.packages", "<paimon-connector-package>") \
.getOrCreate()
# 创建 Paimon 表
spark.sql("""
CREATE TABLE paimon_table (
id INT,
name STRING,
age INT,
PRIMARY KEY (id) NOT ENFORCED
) USING paimon
OPTIONS (
path 'path/to/paimon/table'
)
""")
# 打印表信息
spark.sql("DESCRIBE paimon_table").show()
# 停止 SparkSession
spark.stop()
注意事项
在 Apache Paimon 中,对数据进行分区是一种有效的策略,可以提高查询性能和管理大规模数据集。分区允许将数据划分为更小的部分,使得查询可以更快地定位到相关的数据集,从而减少扫描的数据量。
分区是一种将数据集根据某些字段的值划分为多个逻辑部分的方式。每个分区包含特定字段值范围内的数据。常见的分区字段包括日期、地理位置或其他业务相关字段。
选择分区字段:
定义分区策略:
CREATE TABLE orders (
order_id STRING,
customer_id STRING,
order_date DATE,
amount DOUBLE
) PARTITIONED BY (order_date);
在这个例子中,order_date 字段被用作分区字段。
数据写入和管理:
分区的优点
分区的注意事项
将数据导入到 Apache Paimon 中,通常需要通过与大数据处理框架(如 Apache Flink 或 Apache Spark)的集成来实现。这是因为 Paimon 本身是一个数据湖存储系统,通常需要借助计算框架来进行数据的读写操作。以下是几种常见的方法:
Apache Flink 是与 Paimon 集成最紧密的流处理框架。你可以通过 Flink 作业将数据导入到 Paimon。
步骤:
Apache Spark 也是一个常用的数据处理框架,可以用于将批处理数据导入到 Paimon。
步骤:
如果 Paimon 提供了命令行工具,你也可以直接使用这些工具将数据导入到 Paimon。
步骤:
如果需要更高的灵活性或集成到自定义应用程序中,你可以使用 Paimon 的 Java API 或其他语言支持的 API。
步骤:
注意事项
要将 MySQL 的 binlog 数据导入到 Apache Paimon 中,你可以使用 Apache Flink 作为数据处理引擎,因为 Flink 提供了对 MySQL binlog 的良好支持。
配置 MySQL binlog
启用 binlog:在 MySQL 配置文件中启用 binlog。
[mysqld] log-bin=mysql-bin server-id=1 binlog-format=ROW
创建用户:为 Flink 创建一个用户,具有读取 binlog 的权限。
CREATE USER 'flink'@'%' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'flink'@'%'; FLUSH PRIVILEGES;
编写 Flink 作业
使用 Flink 的 MySQL CDC(Change Data Capture)连接器来读取 MySQL binlog 数据,并将其写入 Paimon。
Flink 作业示例:
依赖配置:确保在 Flink 项目中添加 MySQL CDC 连接器和 Paimon 连接器的依赖。
作业代码:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.connector.mysql.cdc.MySQLSource;
import org.apache.flink.connector.mysql.cdc.config.MySQLSourceConfigFactory;
import org.apache.flink.types.Row;
public class MySQLToPaimon {
public static void main(String[] args) throws Exception {
// 设置 Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 配置 MySQL Source
MySQLSourceConfigFactory configFactory = MySQLSourceConfigFactory.newBuilder()
.hostname("your-mysql-host")
.port(3306)
.databaseList("your-database")
.tableList("your-database.your-table")
.username("flink")
.password("password")
.build();
MySQLSource<String> mySQLSource = MySQLSource.<String>builder()
.hostname("your-mysql-host")
.port(3306)
.databaseList("your-database")
.tableList("your-database.your-table")
.username("flink")
.password("password")
.deserializer(new StringDebeziumDeserializationSchema())
.build();
// 读取 binlog 数据
DataStream<String> mySQLStream = env.addSource(mySQLSource);
// 将数据转换为表
Table mySQLTable = tableEnv.fromDataStream(mySQLStream);
// 写入 Paimon
tableEnv.executeSql(
"CREATE TABLE paimon_table (...) WITH (...)"
);
mySQLTable.executeInsert("paimon_table");
// 执行作业
env.execute("MySQL Binlog to Paimon");
}
}
运行 Flink 作业
验证数据导入
注意事项
查询 Apache Paimon 中的数据通常需要借助与之集成的计算框架,如 Apache Flink 或 Apache Spark。这些框架提供了灵活的查询能力,可以对存储在 Paimon 中的数据进行分析和处理。
Flink 提供了流处理和批处理的能力,可以通过 SQL 或 Table API 来查询 Paimon 中的数据。
步骤:
示例代码:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.api.Table;
public class PaimonQuery {
public static void main(String[] args) throws Exception {
// 设置 Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 注册 Paimon 表
tableEnv.executeSql(
"CREATE TABLE paimon_table (" +
" id INT, " +
" name STRING, " +
" age INT" +
") WITH (" +
" 'connector' = 'paimon'," +
" 'path' = 'path/to/paimon/table'" +
")"
);
// 执行查询
Table result = tableEnv.sqlQuery("SELECT * FROM paimon_table WHERE age > 30");
// 输出查询结果
tableEnv.toChangelogStream(result).print();
// 执行作业
env.execute("Paimon Query");
}
}
Spark 也可以通过 DataFrame API 或 SQL 来查询 Paimon 中的数据。
步骤:
示例代码:
import org.apache.spark.sql.SparkSession
object PaimonQuery {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Paimon Query")
.getOrCreate()
// 读取 Paimon 表
val paimonDF = spark.read
.format("paimon")
.load("path/to/paimon/table")
// 执行查询
val result = paimonDF.filter("age > 30")
// 显示查询结果
result.show()
spark.stop()
}
}
注意事项
要使用 PySpark 查询 Apache Paimon 中的数据,你需要确保 Paimon 和 Spark 环境已正确配置,并且可以通过 Spark SQL 或 DataFrame API 来访问和查询 Paimon 中的数据。以下是一个详细的指南,帮助你在 PySpark 中查询 Paimon 数据:
环境准备
启动 PySpark Shell 或 编写 PySpark 脚本
你可以选择在 PySpark Shell 中直接运行命令,或者编写一个独立的 PySpark 脚本。
使用 PySpark Shell
pyspark --packages <paimon-connector-package>
编写 PySpark 脚本
from pyspark.sql import SparkSession
# 创建 SparkSession
spark = SparkSession.builder \
.appName("Paimon Query") \
.config("spark.jars.packages", "<paimon-connector-package>") \
.getOrCreate()
# 读取 Paimon 表
paimon_df = spark.read \
.format("paimon") \
.load("path/to/paimon/table")
# 执行查询
result_df = paimon_df.filter(paimon_df.age > 30)
# 显示查询结果
result_df.show()
# 停止 SparkSession
spark.stop()
运行脚本或命令
注意事项
Apache Paimon 提供了强大的数据版本管理和时间旅行功能,这些功能对于数据分析和管理非常有用,特别是在需要审计、调试或回溯历史数据时。以下是对 Paimon 数据版本控制和时间旅行功能的详细介绍:
版本化数据存储:
快照管理:
增量更新:
时间旅行查询:
SQL 支持:
示例查询语法:
SELECT * FROM table_name FOR SYSTEM_TIME AS OF ‘2023-01-01 10:00:00’;
在这个例子中,查询将返回数据在指定时间点的状态。
快照导航:
参考链接: