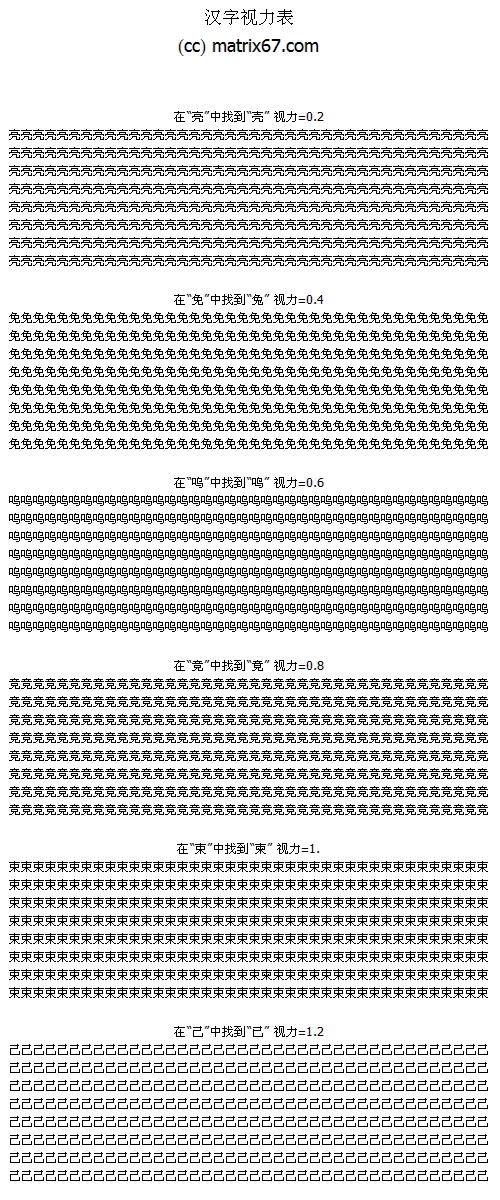用Mathematica寻找最相似的汉字
- hhx - Matrix67: My Blog Mathematica 提供了一个看上去毫无用途的无厘头函数 Rasterize ,它可以以图片的格式输出运算结果. 比如,下面这个句子可以打印出 (x+1)^n 的展开式的“倒影”:. 今天我突然想到,我们可以利用这个函数很方便地分析汉字在图象上的性质. 函数 Binarize 可以把图象转换为单色单通道, ImageData 则可以把图象转换成数组的形式,以便我们定量分析.
Mathematica 提供了一个看上去毫无用途的无厘头函数 Rasterize ,它可以以图片的格式输出运算结果。比如,下面这个句子可以打印出 (x+1)^n 的展开式的“倒影”:
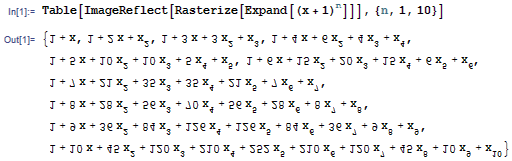
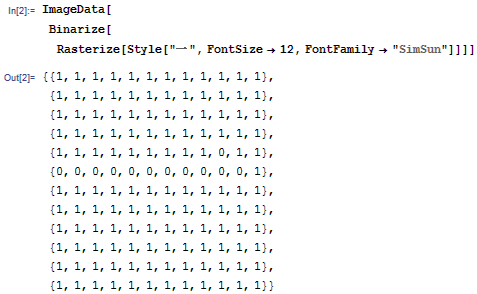
今天我突然想到,我们可以利用这个函数很方便地分析汉字在图象上的性质。函数 Binarize 可以把图象转换为单色单通道, ImageData 则可以把图象转换成数组的形式,以便我们定量分析。因此,下面这句话就可以把一个汉字转换成 12*12 的 01 矩阵:
下面这几句话可以把 GB2312 中的最常用的 3755 个一级汉字按照宋体 12 像素点阵字的像素点多少进行排序。
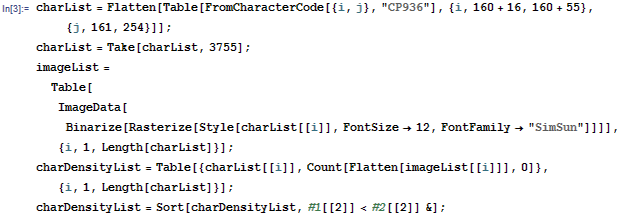
可以看到,像素点最少的 10 个汉字为:
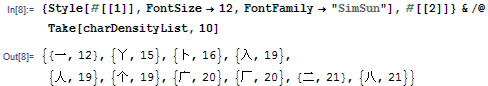
像素点最多的 10 个汉字则为:
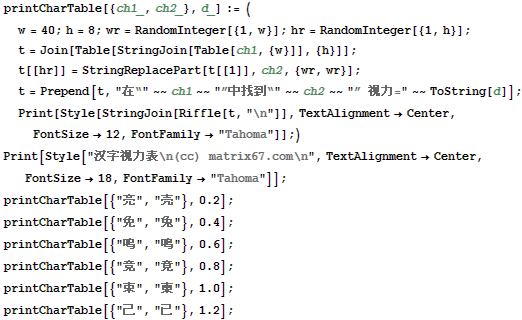
曾经多次在网上看到诸如“三秒钟之内找到我”、“你吃过康帅博方便面吗”之类的帖子,不由得感叹汉字之强大。于是我开始思考,汉字中哪些字对长得最像?于是,我利用上面这些函数写了一段 Mathematica 程序,跑了几个小时的时间终于得出了在 3755 个一级汉字所对应的宋体 12 像素点阵字中像素不同之处最少的字对。其中有一对字仅一个像素之差,它们是“己”和“已”字。其它的一些结果如下:
只差 2 个像素:(鸣,呜), (柬,束), (竟,竞)
只差 3 个像素:(壳,亮), (含,合)
只差 4 个像素:(上,土), (免,兔), (兵,乒), (士,土)
只差 5 个像素:(夫,失), (臣,巨), (未,朱), (宜,直)
但是,我对上面这个结果并不满意,因为有这么一个问题被忽略掉了:虽然相差相同数量的像素点,但差异发生在不同的地方,主观上的视觉差别程度是不同的。比方说,同样只差 4 个像素,人们会觉得 (士,土) 之间的差异远远小于 (上,土) 之间的差异。我们可以用一个更简单的例子来说明这种情况:

图 A 和图 B 、图 A 和图 C 都只差一个像素,但从人眼的角度来看,图 C 要和图 A 接近一些。这是为什么呢?或许这就是人和机器的区别吧。机器能够精确地知道每个像素的位置,但人却很难做到这一点,一般只能分辨出每个像素的大致位置。为了模拟人眼的感受,我想到把所有的汉字全部模糊化,让每个像素点都在其周边留下一些影子,这相当于从一个近视眼的角度去量化字形的差异。

对前面的三个例图进行模糊并转化为 256 灰阶后,图 A 和图 B 的各像素灰度值的差值的平方和为 33699 ,图 A 和图 C 的各像素灰度值的差值的平方和则为 29330 ,后者比前者小得多。又是几个小时的时间, Mathematica 终于找出了在这个意义下字形最接近的 50 个字:
(己,已), (竟,竞), (鸣,呜), (柬,束), (壳,亮), (含,合), (免,兔), (荚,英), (士,土), (宜,直)
(并,井), (杜,社), (夫,失), (侍,恃), (昔,音), (未,朱), (囤,围), (检,捡), (昧,味), (桶,捅)
(末,未), (懦,儒), (著,着), (上,土), (兵,乒), (素,索), (臣,巨), (迸,进), (盖,蛊), (槐,愧)
(优,忧), (官,言), (挡,档), (醇,酵), (柠,拧), (茧,苗), (儿,几), (蓬,篷), (供,洪), (幂,幕)
(扁,肩), (贵,贪), (金,全), (借,惜), (厘,屋), (析,折), (戍,戌), (大,太), (悄,俏), (失,矢)
这些字究竟相仿到什么程度呢?让我们用上面这个列表中的头 6 组字对做一张“汉字视力表”吧: