
推荐系统中的点击率预估 – Advertising & Recommendation
- -推荐系统的框架模式大致是:多种召回策略(触发层),一种融合排序策略(排序层),也可认为两阶段排序模型[33]:. 召回策略方法繁多(例如常见的协同过滤中的item-based,user-based,以及MF矩阵分解),最终的融合排序层中,如果采用point-wise[24]排序方法,最常用的是点击率(CTR)预估[1],作为排序依据.

推荐系统的框架模式大致是:多种召回策略(触发层),一种融合排序策略(排序层),也可认为两阶段排序模型[33]:
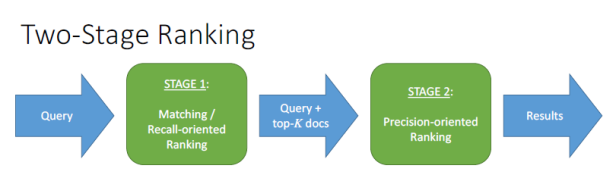
召回策略方法繁多(例如常见的协同过滤中的item-based,user-based,以及MF矩阵分解),最终的融合排序层中,如果采用point-wise[24]排序方法,最常用的是点击率(CTR)预估[1],作为排序依据。
点击率预估 = 在某种环境x下,某个推送y展现给某个用户z后,用户点击的概率r。广告中点击率预估计算出的是精准的点击概率,A点击率0.22% , B点击率0.34%等,需要结合其它因子(出价)用于排序;推荐算法对准确值没有明确要求,只需计算出一个最优的次序A>B>C即可[31]。点击率 = 浏览数/点击数(点击率越高,意味着在相同投入的情况下,收获了更多的用户注意力)。
本文介绍基于Logistic Regression和FTRL的点击率预估模型,其它更多方法请参见[10]。本文结构如下
在图片广告(display advertising)中CTR的预测方法被广泛研究,逻辑回归(Logistic Regression,LR)因为在大规模系统中的实现简单和高性能,是工业界使用最为广泛的 CTR 预估模型。
如果用逻辑回归来建模点击率预测的问题,我们根据以下框架来进行:在t时刻,利用特征向量Xt来描述一个实例,同时给定模型权重向量Wt,预测p(t)=σ(Wt•Xt),其中σ = 1=(1 + exp(-a))为sigmoid函数。对应的log损失函数(logloss)为
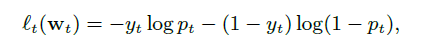
通过上式可以很容易计算出loss function关于W的梯度
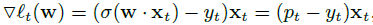
LR 模型简单,训练时便于并行化,在预测时只需要对特征进行线性加权,所以性能比较好,往往适合处理海量 id 类特征,用 id 类特征有一个很重要的好处,就是防止信息损失(相对于范化的 CTR 特征),对于头部资源会有更细致的描述。
LR 的缺点也很明显,首先对连续特征的处理需要先进行离散化,人工分桶的方式会引入多种问题。另外 LR 需要进行人工特征组合,这就需要开发者有非常丰富的领域经验,才能不走弯路。这样的模型迁移起来比较困难,换一个领域又需要重新进行大量的特征工程[10]。
无论是线性回归(Linear Regression)、逻辑回归(Logistic Regression)、支持向量机(SVM)、深度学习(Deep Learning)中,最优化求解都是基本的步骤。常见的梯度下降、牛顿法、拟牛顿法等属于批量处理的方法(Batch),每次更新都需要对已经训练过的样本重新训练一遍。而当我们面对高维高数据量的时候,批量处理的方式就显得笨重和不够高效,因此需要在线学习(Online Learning)的方法来解决相同的问题[7]。
在线学习算法的特点是:每来一个训练样本,就用该样本产生的loss和梯度对模型迭代一次,一个一个数据地进行训练,因此可以处理大数据量训练和在线训练。在进行大规模的模型训练时,线性模型的Online Learning算法有很多优势。尽管特征向量可能有多大上亿的维度,但每个样本可能只有几百个维度有非零值。因为每个样本只需要考虑一次,这种特性允许从硬盘或者网络流式读取数据来进行有效训练[4]。Online Learning能够根据线上反馈数据,实时快速地进行模型调整,使得模型及时反映线上的变化,提高线上预测的准确率[3]。
在Batch模式下,L1正则化通常产生更加稀疏(Sparse)的模型,系数𝑊的更多维度为0,这些为0的维度就代表了不是很相关的维度,从而起到了特征选择(Feature Selection)的目的。不同于Batch训练方法的是,Online中每次权重向量W的更新并不是沿着全局梯度进行下降,而是沿着某个样本的产生的梯度方向进行下降,整个寻优过程变得像是一个随机查找的过程(这就是SGD中Stochastic的来历),这样Online最优化求解即使采用L1正则化的方式,也很难产生稀疏解。在各个在线最优化求解算法中,稀疏性是其中一个主要的追求目标[7]。尤其做工程应用,稀疏的特征会大大减少predict时的内存和复杂度。
在线梯度下降(OGD)(OGD与随机梯度下降类似)已被证明是解决此类问题的有效方法–能够产生良好的预测准确度,且占据很少的计算资源。但是在实际应用中,最终模型的大小是一个关键因素,权重向量W中非零系数的数量决定了使用的内存大小。不幸的是,OGD并不能有效地产生稀疏模型,简单地将L1正则项加入到损失函数的梯度上并不能产生确切等于0的系数[4]。
为了得到稀疏的特征权重𝑊,最简单粗暴的方式就是设定一个阈值,当𝑊的某维度上系数小于这个阈值时将其设置为0(称作简单截断)。这种方法实现起来很简单,也容易理解。但实际中(尤其在OGD里面)𝑊的某个系数比较小可能是因为该维度训练不足引起的,简单进行截断会造成这部分特征的丢失[7]。
截断梯度法(TG, Truncated Gradient)实际上是对简单截断的一种改进。简单截断法以𝑘为窗口,当𝑡/𝑘不为整数时采用标准的SGD进行迭代,当𝑡/𝑘为整数时,采用如下权重更新方式:
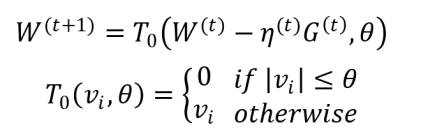
上述的简单截断法被TG的作者形容为too aggressive,因此TG在此基础上进行了改进,同样是采用截断的方式,但是比较不那么粗暴。采用相同的方式表示为:
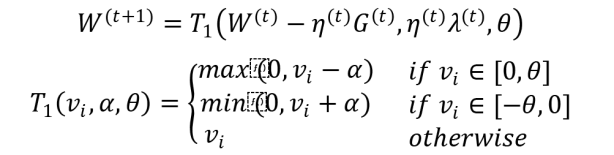
TG的算法逻辑如下:

在FOBOS中,将权重的更新分为两个步骤:
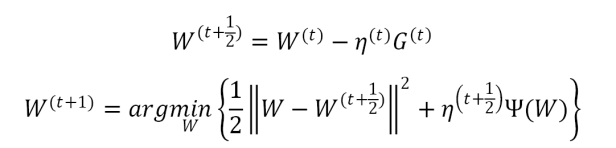
前一个步骤实际上是一个标准的梯度下降步骤,后一个步骤可以理解为对梯度下降的结果进行微调。观察第二个步骤,发现对𝑊的微调也分为两部分:(1) 前一部分保证微调发生在梯度下降结果的附近;(2)后一部分则用于处理正则化,产生稀疏性[7]。
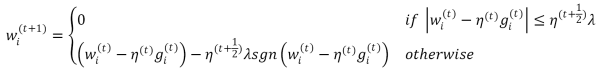
L1-FOBOS在每次更新𝑊的时候,对𝑊的每个维度都会进行判定,当满足一定条件 时对该维度进行截断。

当一条样本产生的梯度不足以令对应维度上的权重值发生足够大的变化(𝜂(𝑡+12)𝜆),认为在本次更新过程中该维度不够重要,应当令其权重为0。可以认为L1-FOBOS是TG在特定条件下的特殊形式。
不论怎样,简单截断、TG、FOBOS都还是建立在SGD的基础之上的,属于梯度下降类型的方法,这类型方法的优点就是精度比较高,并且TG、FOBOS也都能在稀疏性上得到提升。但是有些其它类型的算法,例如RDA,是从另一个方面来求解Online Optimization并且更有效地提升了特征权重的稀疏性[7][2]。L1-RDA特征权重的各个维度更新的方式为:
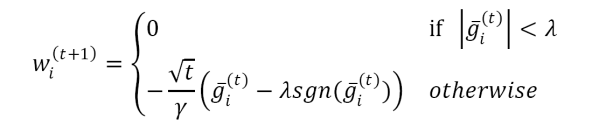
上面公式可以这样理解:当某个维度上累积梯度平均值的绝对值 𝑔 𝑖(𝑡) 小于阈值𝜆的时候,该维度权重将被置0,特征权重的稀疏性由此产生。
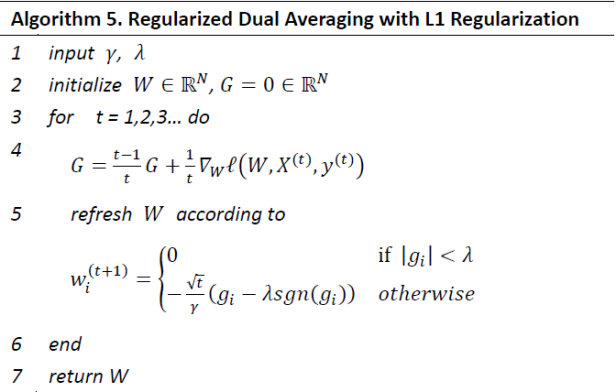
L1-RDA的截断阈值为 𝜆 ,是一个常数,并不随着𝑡而变化,因此可以认为L1-RDA比L1-FOBOS在截断判定上更加aggressive,这种性质使得L1-RDA更容易产生稀疏性;此外,RDA中判定对象是梯度的累加平均值𝑔 𝑖(𝑡),不同于TG或L1-FOBOS中针对单次梯度计算的结果进行判定,避免了由于某些维度由于训练不足导致截断的问题。并且通过调节 𝜆 一个参数,很容易在精度和稀疏性上进行权衡。
那么这两者的优点能不能在一个算法上体现出来?这就是FTRL要解决的问题。[9]中总结了FTRL的形成思路

在详细介绍FTRL算法之前再了解一下FTL(Follow The Leader)算法[25],FTL思想就是每次找到让之前所有损失函数之和最小的参数。

FTL的缺点是[13][26]W在上下一轮训练之间会发生剧烈变化,预测不太稳定。
FTRL算法就是在FTL的优化目标的基础上,加入了正规化,防止过拟合。
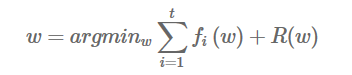
FTRL算法的损失函数,一般也不是能够很快求解的,这种情况下,一般需要找一个代理的损失函数。代理损失函数需要满足几个要求:
为了衡量条件2中的两个解的差距,这里需要引入regret的概念。假设每一步用的代理函数是h(w),每次取
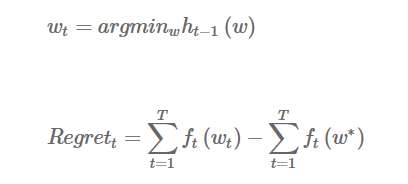
其中 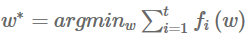
是原函数的最优解,就是我们每次代理函数求出解,离真正损失函数求出解的损失差距。当然这个损失必须满足以下条件,Online Learning 才可以有效
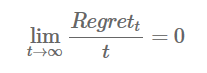
随着训练样本的增多,这两个优化目标优化出的参数的实际损失值差距越来越小。当fi(w)是凸函数时,可以取代理函数为
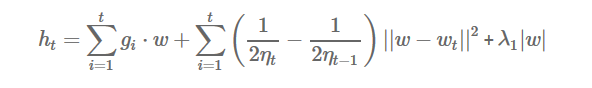
其中gi是fi(w)的次梯度(当fi(w)是可导的,次梯度就是梯度),学习率ηt满足:
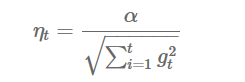
加入L1正则项能够产生稀疏系数,除了特征选择的作用以外,稀疏性可以使得预测计算的复杂度降低[7],L1正则项能够产生稀疏性的原因,具体请参见[7][10]。只要ft(w)是凸函数,则代理函数ht满足Regret函数对t的导数为0这个条件。根据以上可以得到w的解析解:
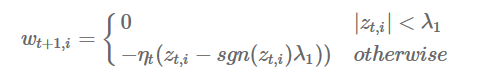
其中
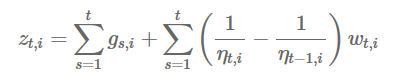
对于上面的迭代式,如果 

下图是[4]中给出的针对Logistic Regression的L1&L2-FTRL算法逻辑

上述两个更新流程中更新权重向量W部分不同的地方在于第一个流程中超参数ß为0。也就是说在[4]给出的算法中,学习率为
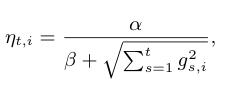
FTRL,较SGD有以下优势[40]:
用于点击率预估的数据主要是日志数据,而数据采样主要涉及样本关联、样本选择、样本权重等问题,数据预处理主要是解决数据缺失,不平衡,噪音等问题[31]。
在实际中,正样本和负样本严重不均衡[30],严重的不均衡会带来模型估计上的问题。通过对训练数据集进行subsampling,可以大大减小训练数据集的大小。另一种方法是正样本全部采(至少有一个广告被点击的数据),负样本使用一个比例r采样(完全没有广告被点击的数据)。但是直接在这种采样上进行训练,会导致比较大的biased prediction。
解决办法是在训练的时候,对样本再乘一个权重,权重直接乘到loss上面,从而梯度也会乘以这个权重[2],总体思路就是先采样减少负样本数目,在训练的时候再用权重弥补负样本[9][11]。原理是保证采样后的期望损失等于原损失[37]。
[41]中发现,在负样本上进行1%的采样(样本量大小为),在训练时间和预测准确性上达到了良好的均衡。
[31]中
 特征工程
特征工程CTR预估模型采用的特征,主要有三类:用户相关的特征、商品相关的特征、以及用户-商品匹配特征。用户相关的特征包括年龄、性别、职业、兴趣、品类偏好、浏览/购买品类等基本信息,以及用户近期点击量、购买量、消费额等统计信息。商品相关的特征包括所属品类、销量、价格、评分、历史CTR/CVR等信息。用户-商品匹配特征主要有浏览/购买品类匹配、浏览/购买商家匹配、兴趣偏好匹配等几个维度。以下是[3]给出的移动端推荐相关特征

ID类特征,User、Item 、Context基本特征,移动特定场景相关特征:设备ID VS 用户ID;城市区域特征;手机型号特征,PC & Mobile 特征融合。每个特征权重反映该特征在数据中的统计意义,方便进行特征组合和模型debug,比较方便引入在线学习[37]。
特征处理一般包括以下内容[31]:

LR 处理离散特征可以得心应手,但处理连续特征的时候需要进行离散化。通常连续特征会包含:大量的反馈 CTR 特征、表示语义相似的值特征、年龄价格等属性特征。以年龄为例,可以用业务知识分桶:用小学、初中、高中、大学、工作的平均年龄区间做分桶;也可以通过统计量分桶,使各个分桶内的数据均匀分布。其中Criteo利用GBDT来自动计算特征的分桶和交叉特征[34]。
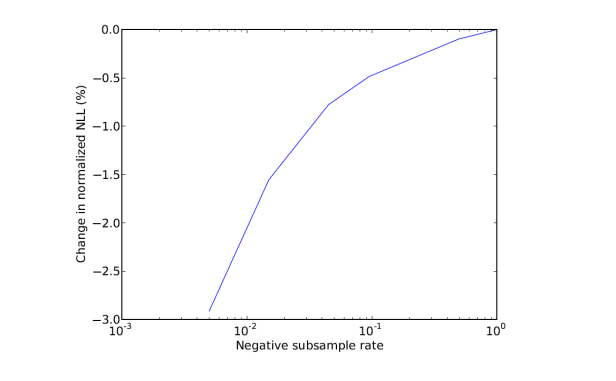
[19]中对于Avazu竞赛[20]中的点击率预估数据,总结了三种特征处理方法。第一种方法是直接对每一列进行OneHotEncoding,取编码之后的index作为新的特征。
第二种方法是通过分析数据,组合关联的特征,例如组合device-model,device-id,device_ip三个特征的值作为用户的标识id,然后再进行OneHotEncoding,同样取编码之后的index作为新的特征。而在推荐系统CTR预估中,很可能已经具有用户id。
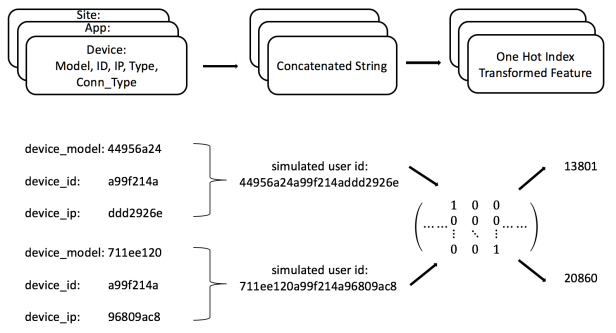
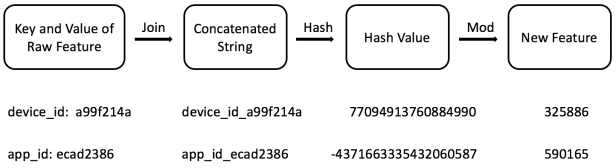
第三种方法是对于每一个键值对,例如device_id等于a99f214a的数据,组合为device_id_a99f214a,对组合之后的字符串进行哈希编码,并对一个很大的数取余数,用最后得到的余数作为新的特征,例如下图中325886表示第325886个特征值为1。
模型的评估主要分为离线和线上评估:

线上评估指标包括MAP和NDCG[35]。
[36]
[31] 中给出了推荐系统中点击率预估的系统流程:
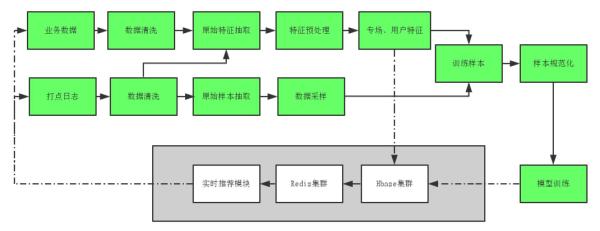
[3]中给出了一个在移动端推荐排序的Online Learning架构。线上的展示日志,点击日志和下单日志会写入不同的Kafka流。读取Kafka流,以HBase为中间缓存,完成label match(下单和点击对映到相应的展示日志),在做label match的过成中,会对把同一个session的日志放在一起,方便后面做训练数据中的筛选。训练算法不断地从HBase中读取数据,完成模型地训练,训练模型放在Medis(美团内部的Redis)中,线上会用Medis中的模型预测下单率,根据预测的下单率,完成排序。

[12]中提供了一个基于Python实现FTRL的版本,训练过程具体逻辑如下可供参考

[17]中基于Outbrain[22]给出的广告展示记录、广告基本数据和展示广告时的上下文环境数据。其中展示记录包括:
广告基本数据包括
广告的展示上下文数据包括
[28]中的方法在利用FTRL训练数据前,采用上文中提到的第三种特征处理方法,将所有三个类别下特征的值和特征类别进行字符串组合之后,取哈希编码并取余数得到的值作为特征,在每个样本的训练过程中更新系数向量和特征学习率向量,并利用MAP@12(平均准确率,Mean Average Precision[29][32],MAP)评估测试样本上的预测效果。[27]中提供了一个基于R语言的版本。
[16]中给出了一个基于Factorization Machine和FTRL优化框架下的,用于解决二分类问题,比如CTR预估。
FTRL 可以在线训练,这样使 LR 存储于模型中的信息可以得到快速的更新。另外 FTRL 也具有不错的稀疏性和精确度,可以减少内存占用防止过拟合。最后 FTRL_Proximal 还支持动态的学习率,可以对不同完整性的特征采用不同的步长进行梯度下降。FTRL 同样具有 LR 的缺点,需要人工特征工程和人工离散化分桶[10]。
https://github.com/zhouyonglong/MarketingAnalytics/blob/master/outbrain_ftrl_starter.py
[1]http://mp.weixin.qq.com/s/scnAVuiMb3kH2NLyOmdCcQ
[2]A Survey on Algorithms of the Regularized Convex Optimization Problem
[3]https://tech.meituan.com/online-learning.html
[4]Ad Click Prediction : a View from the Trenches
[5]Display Advertising with Real-Time Bidding and Behavioural Targeting
[6]https://www.quora.com/What-is-an-intuitive-explanation-of-Follow-the-Regularized-Leader-FTRL-algorithm
[7]冯扬.在线最优化求解
[8]Factorization Machines with Follow-The-Regularized-Leader for CTR prediction in Display Advertising
[9]http://www.cnblogs.com/EE-NovRain/p/3810737.html
[10]https://www.qcloud.com/community/article/701728
[11]http://blog.csdn.net/a819825294/article/details/51227265
[12]https://github.com/zhouyonglong/FTRLp
[13]poetniu.Online Learning/Optimization算法实现与理论分析
[14]https://www.qcloud.com/community/article/643549
[15]https://www.qcloud.com/community/article/622182
[16]https://github.com/zhouyonglong/alphaFM
[17]https://www.kaggle.com/sudalairajkumar/ftrl-starter-with-leakage-vars
[18]https://www.kaggle.com/c/criteo-display-ad-challenge/discussion/10322
[19]Jian Li.Ad Click-Through Rate Prediction
[20]https://www.kaggle.com/c/avazu-ctr-prediction
[21]https://www.zhihu.com/question/37866658
[22]https://www.kaggle.com/c/outbrain-click-prediction
[23]http://www.cs.cmu.edu/~ninamf/courses/806/
[24] Efficiency/Effectiveness Trade-offs in Learning to Rank
[25]Online Learning II : ERM and Follow the (Regularized) Leader
[26]Online Learning and Online Convex Optimization
[27]http://dsnotes.com/post/2017-01-27-lessons-learned-from-outbrain-click-prediction-kaggle-competition/
[28]https://www.kaggle.com/sudalairajkumar/ftrl-starter-with-leakage-vars/comments
[29]Performance Evaluation of Information Retrieval Systems
[30]计算广告 互联网商业变现的市场与技术
[31]https://zhuanlan.zhihu.com/p/27278885
[32]https://github.com/benhamner/Metrics/blob/master/Python/ml_metrics/average_precision.py#L34
[33]Efficiency/Effectiveness Trade-offs in Learning to Rank
[34]http://labs.criteo.com/Role/data-scientist/
[35]http://fastml.com/evaluating-recommender-systems/
[36]http://www.cnblogs.com/zhengyun_ustc/p/55solution1.html
[37]夏粉.广告数据上的大规模机器学习
[38]https://yq.aliyun.com/articles/122
[39]https://tech.meituan.com/mt_dsp.html
[40]http://mp.weixin.qq.com/s/lUP2BehOh7KczR3WRnOqFw
[41]Simple and scalable response prediction for display advertising
[42]https://github.com/alexeygrigorev/libffm-python