【Python量化】手把手教你用python做股票分析入门
- -python金融量化 已获得授权. 关注可了解更多的金融与Python干货. 目前,获取股票数据的渠道有很多,而且基本上是免费的,比如,行情软件有同花顺、东方财富等,门户网站有新浪财经、腾讯财经、和讯网等. Python也有不少免费的开源api可以获取交易行情数据,如pandas自带的库,tushare和baostock等.

虽然这个问题也有些年头了,但相信现在仍然会有不少朋友对如何用Python分析股票很感兴趣,所以今天我们就分享一篇美国数据科学专家William Koehrsen 利用Python股票分析工具Stocker的实战教程。相信本文会对你在这个问题上有不少启发。
对于数据科学研究来说,海量数据和免费的开源工具包很容易得到。在Quandl金融程序库和Prophet建模程序库上研究了一段时间后,我(作者William Koehrsen——译者注)决定自己试着简单研究一下股票数据。最终我写出了一个1000行Python代码的完整股票分析预测工具。虽然我没有足够的信心用它来投资股市,但我在这个过程中学习了大量的Python知识。本着开源互助的精神,在下文我也会相应的结果和代码分享给大家,希望对你有所帮助。

本文会展示如何使用Stocker(一个基于类的Python工具)用于股票分析和预测(从名字上也能看出来是干嘛的)。我曾多次尝试攻克类这个难题,它是Python中面向对象编程的基础知识。但是跟读大多数编程语言书一样,我研究Python编程书的时候,还是不能很好的理解那些概念。但后来当我在项目中亲手解决了一个的从来没见过的问题后,才能真正明白书上概念的含义,这再次说明,自己亲身实践得到的经验胜过刻板的理论解释!
除了Stocker之外,我们还会涉及一些重要的主题,包括Python类的基础知识和加法模型。如果你想使用Stocker,可以在GitHub上找到完整的代码以及使用文档:
https://github.com/WillKoehrsen/Data-Analysis/tree/master/stocker 。Stocker易于使用(即使对于Python新手也是如此),任何人都可以很快上手。现在,我们来看看Stocker!
Stocker入门
在安装所需的库之后,我们要做的第一件事就是将Stocker类导入到我们的Python 会话中。我们可以通过交互式Python 会话导入或通过Jupyter Notebook脚本目录。
from stocker import Stocker
我们现在在Python 会话中有了Stocker类,我们可以用它来创建类的一个实例。在Python中,类的实例称为对象,创建对象的行为被称为实例化或构造。为了构造一个Stocker对象,我们需要传入一个有效的股票代码的名称作为参数(粗体表示输出)。
microsoft = Stocker('MSFT')
MSFT Stocker Initialized. Data covers 1986-03-13 to 2018-01-16.
现在,我们有一个microsoft对象,包含Stocker类的所有属性。Stocker在quandl WIKI数据库( https://www.quandl.com/databases/WIKIP/documentation/about)的基础上建立,该数据库使我们能够访问3000多支美国股票,并提供多年的每日股价据: https://media.githubusercontent.com/media/WillKoehrsen/Data-Analysis/master/stocker/data/stock_list.csv。在本文中,我们将一直使用微软的股票数据。
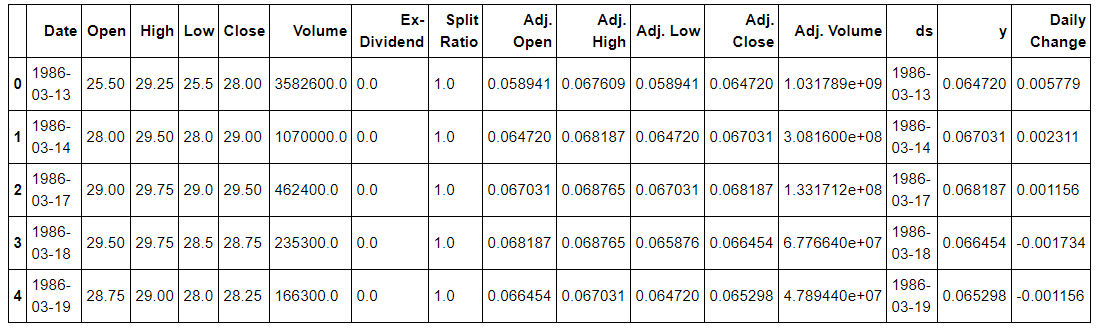
Python中的类由两个主要部分组成:属性和方法。属性是与整个类或者类的特定实例(对象)相关联的值或数据。方法是包含在类中,可以作用于数据的函数。Stocker对象的一个属性是特定公司的股票数据,当我们构造它时,属性与该对象相关联。我们可以获取该属性,将其赋值给另一个变量进行检验:
# Stock is an attribute of the microsoft object
stock_history = microsoft.stock
stock_history.head()
Python类的好处是方法(函数)和它们施加作用的数据与同一个对象相关联。我们可以使用Stocker对象的一个方法来绘制指定股票的历史走势图。
# A method (function) requires parentheses
microsoft.plot_stock()
Maximum Adj. Close = 89.58 on 2018-01-12.
Minimum Adj. Close = 0.06 on 1986-03-24.
Current Adj. Close = 88.35.
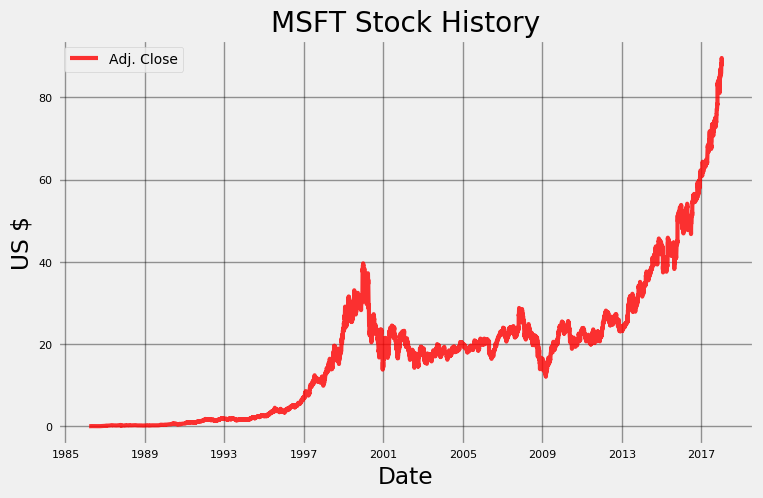
默认绘制的值是调整后的收盘价格,它考虑了股票的拆分情况(当一个股票被分成多个股票,比如2个,每个新股票的价格是原始价格的1/2)。
上图是我们可以从Google搜索中找到的一张非常基础的图表,但是我们可以使用几行Python代码自己完成!plot_stock函数有许多可选的参数。默认情况下,此方法绘制整个日期范围的调整后收盘价格,但我们可以选择范围、绘制的统计数据和图表类型。例如,如果我们想比较 每日股价波动与 交易的调整交易量(股份数量,也就是交易了多少手),我们可以在函数调用中指定特定的参数。
microsoft.plot_stock(start_date = '2000-01-03', end_date = '2018-01-16', stats = ['Daily Change', 'Adj. Volume'], plot_type='pct')
Maximum Daily Change = 2.08 on 2008-10-13.
Minimum Daily Change = -3.34 on 2017-12-04.
Current Daily Change = -1.75.
Maximum Adj. Volume = 591052200.00 on 2006-04-28.
Minimum Adj. Volume = 7425503.00 on 2017-11-24.
Current Adj. Volume = 35945428.00.
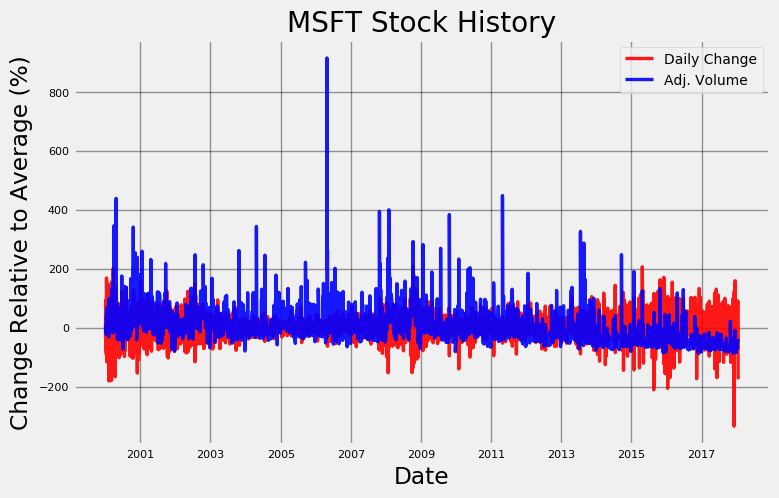
请注意,y轴是对应统计量平均值的百分比变化。这种设计很有用处,因为每天的股票交易量多达几十万股,而每日股价波动通常只有几美元!通过转换为百分比,我们可以在相似的尺度上同时查看两个数据集。图像显示 交易股数与每日股价变动之间没有相关性。但这很令人费解,因为我们预计的是在价格变化较大的日子,人们会交易更多股票,因为人们急于利用这种价格波动获利(也就是抄底)。然而,唯一真正的趋势似乎是交易量随着时间的推移而下降。在2017年12月4日,价格也出现大幅下降,我们可以尝试将这个现象与微软当天的新闻相关联。
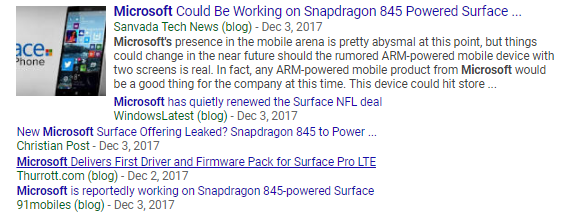
当然,似乎没有任何迹象表明微软股票将在第二天出现10年内最大跌幅!事实上,如果我们根据新闻来预测股票走势,我们可能会购买股票,因为微软与NFL的交易(第二个搜索到的结果)听起来像是一个利好消息。
通过使用plot_stock函数,我们可以查看任何日期范围内的任何数据,并查找与现实世界事件(如果有的话)之间的相关性。现在,我们将转向Stocker更令人兴奋的部分之一:制作“假钱”!(当然是 模拟资金啦)。
我们先暂时假设我们在微软公司首次公开募股(IPO)上购买了100股。那我们现在会变得多么富有?
microsoft.buy_and_hold(start_date='1986-03-13',
end_date='2018-01-16', nshares=100)
MSFT Total buy and hold profit from 1986-03-13 to 2018-01-16 for 100 shares = $8829.11
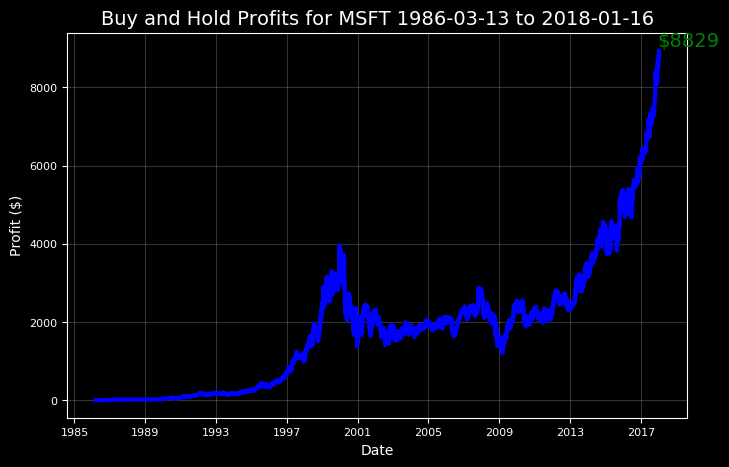
除了让我们感到美滋滋以外,利用这些结果也能让我们及时抛售,将收益最大化。
如果我们觉得过于自信,这不太现实,可以尝试调整结果亏点钱:
microsoft.buy_and_hold(start_date='1999-01-05',
end_date='2002-01-03', nshares=100)
MSFT Total buy and hold profit from 1999-01-05 to 2002-01-03 for 100 shares = $-56.92
令人惊讶的是,确实有可能在股市中亏损!
加法模型(Additive Models)
加法模型是分析和预测时间序列的强大工具,时序数据是现实中最常见的数据类型之一。这个模型很简单易懂:将时间序列表示为不同时间尺度和整体趋势的模式组合。我们知道微软股票的长期趋势是稳步增长,但也可能存在每年或每日的模式,例如每周二增长一次。用于分析时间序列和日常观察(如股票)的常用的库是Facebook开发的Prophet。Stocker和Prophet完成了已经预先完成所有的建模工作,因此我们可以使用简单的方法调用它们就行。
model, model_data = microsoft.create_prophet_model()
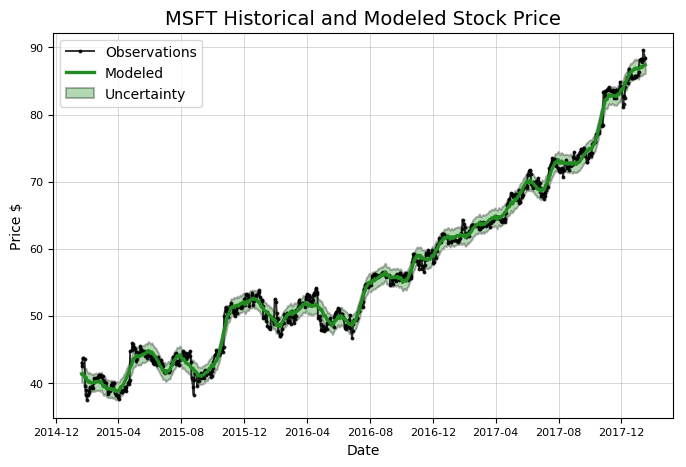
加法模型可以消减数据中的噪音,正是噪音导致了建模出的趋势与实际趋势不完全一致。Prophet模型还计算了不确定性,这是建模的一个重要部分,因为在处理现实中的波动时,我们无法肯定我们的预测。我们也可以使用Prophet模型来预测将来的情况,但现在我们更关心过去的数据。 请注意,此方法调用返回了两个对象:一个模型和一些数据,我们将其赋给变量。我们现在使用这些变量绘制时间序列组件。
# model and model_data are from previous method call
model.plot_components(model_data)
plt.show()
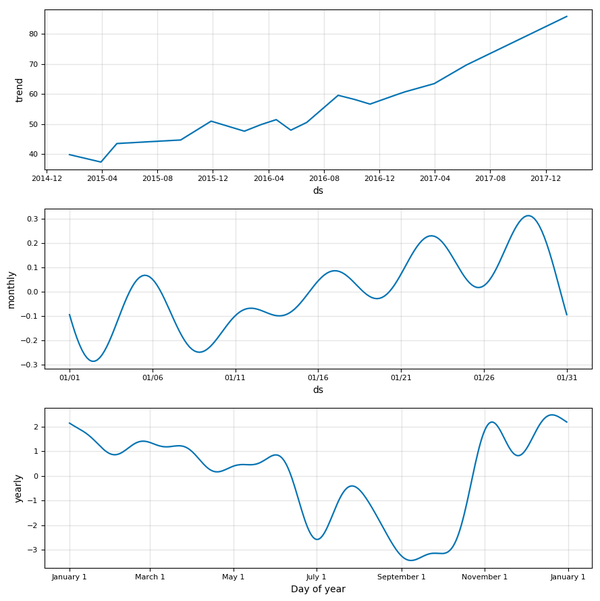
过去三年总体趋势是明显上升的,似乎还有一个明显的年度走势(上面三幅图中的最底部图),价格在9月和10月触底反弹,11月和1月达到峰值。随着时间尺度的减小,数据变得越来越嘈杂。如果我们相信可能存在每周变化的趋势,我们可以通过更改Stocker对象的weekly_seasonality属性将其添加到Prophet模型中:
print(microsoft.weekly_seasonality)
microsoft.weekly_seasonality = True
print(microsoft.weekly_seasonality)
False
True
weekly_seasonalityFalse的默认值是False,但我们更改该值使我们的模型中包含每周变化趋势。然后我们调用create_prophet_model并绘制结果。以下是新模型的每周变化趋势。
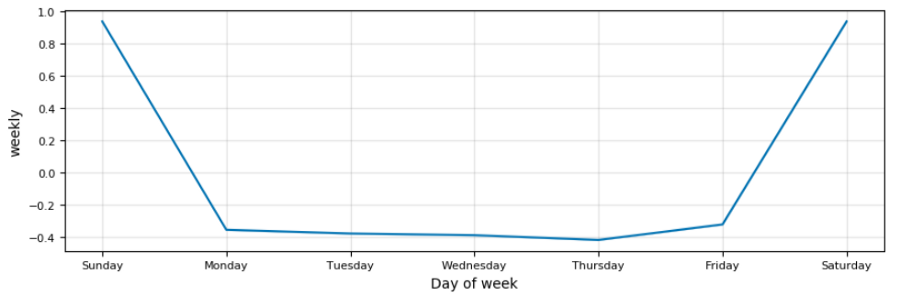
我们可以忽略周末,因为价格仅在工作日内发生变化(实际上,在周末价格会有小幅变化,但不影响我们的分析)。不过,每周的趋势预测对我们的模型没有帮助,所以在继续建模之前,我们将关闭每周的趋势预测。预期会出现这种情况: 对于股票数据,随着时间尺度缩短,会出现大量噪音。在以天为单位的时间尺度上,股票的走势基本是随机的,只有通过缩小时间尺度到每年才能看到趋势。这也很好地说明为啥不能每天都琢磨股票!
极值点
极值点是当时间序列从递增转到递减或者从递减转到递增(更严格地说,它们位于时间序列的速率变化最大的地方)时发生变化的点。这些时间点非常重要,因为了解股票何时达到顶峰或即将上涨,可以帮助我们将经济效益最大化。 找出极值点,可以让我们预测股票价格未来波动的情况。Stocker对象可以自动为我们找到10个最大的极值点。
microsoft.changepoint_date_analysis()
Changepoints sorted by slope rate of change (2nd derivative):
Date Adj. Close delta
48 2015-03-30 38.238066 2.580296
337 2016-05-20 48.886934 2.231580
409 2016-09-01 55.966886 -2.053965
72 2015-05-04 45.034285 -2.040387
313 2016-04-18 54.141111 -1.936257
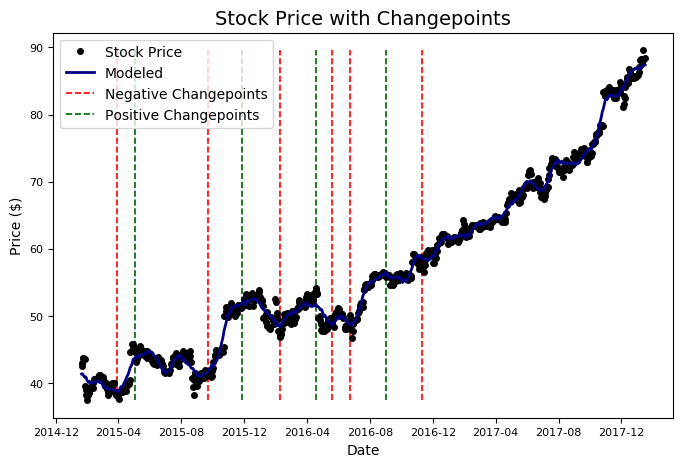
极值点趋向于与股价的高峰和低谷相吻合。Prophet只在前80%的数据中找到极值点。但是,这些结果非常有用,因为我们可以尝试将它们与真实事件相关联。我们可以重复我们之前所做的工作,并在Google手动搜索这些日期的新闻,但我想让Stocker自动完成这些。你或许知道一个叫Google Search Trends的工具,可以让你随时查看Google搜索中任何关键词的搜索热度。Stocker可以自动查看我们指定的关键词的查询频率,并将结果绘制在原始数据上。要查找和绘制关键词的查询频率,我们需要修改前面的方法调用。
# same method but with a search term
microsoft.changepoint_date_analysis(search = 'Microsoft profit')
Top Related Queries:
query value
0 microsoft non profit 100
1 microsoft office 55
2 apple 30
3 microsoft 365 30
4 microsoft office 365 20
Rising Related Queries:
query value
0 microsoft 365 120
1 microsoft office 365 90
2 microsoft profit 2014 70
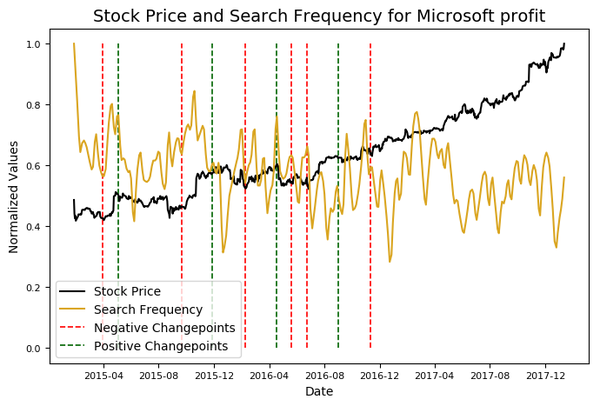
除了绘制相对搜索频率之外,Stocker还会显示图表日期范围内的最相关和查询频率最高的关键词的趋势图。在图上,通过将值除以它们的最大值,y轴原始数据被归一化处理后控制在0和1之间,从而能让我们比较具有不同比例的两个变量。从图中可以看出,“微软利润”关键词与微软股票价格之间没有相关性。
如果我们找到了相关性,那么由于因果关系也会导致一些问题。我们不知道是新闻事件导致了价格变化,还是价格变化引发了事件的发生。可能会找到一些其他有用的信息,但也有偶然发生的低关联性的事情。(对于这种随机关系的处理方法,请查看虚假关联: 15 Insane Things That Correlate With Each Other)。大胆的尝试一些不同的事件,看看你是否能找到有趣的趋势!
microsoft.changepoint_date_analysis(search = 'Microsoft Office')
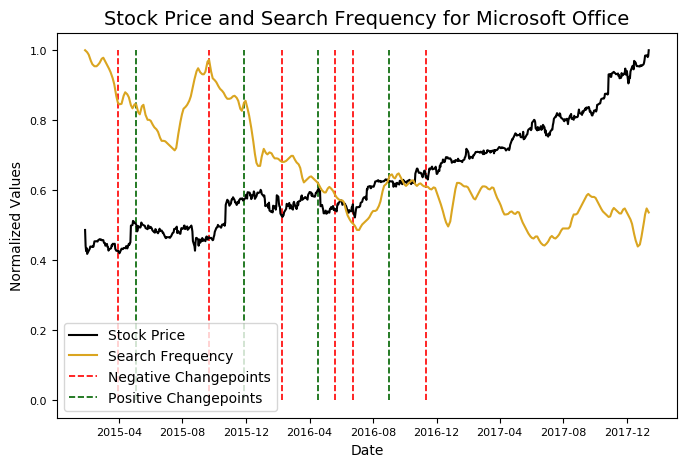
看起来Office的搜索量下降却会导致股价上涨,也许有人应该知会微软一声。
预测
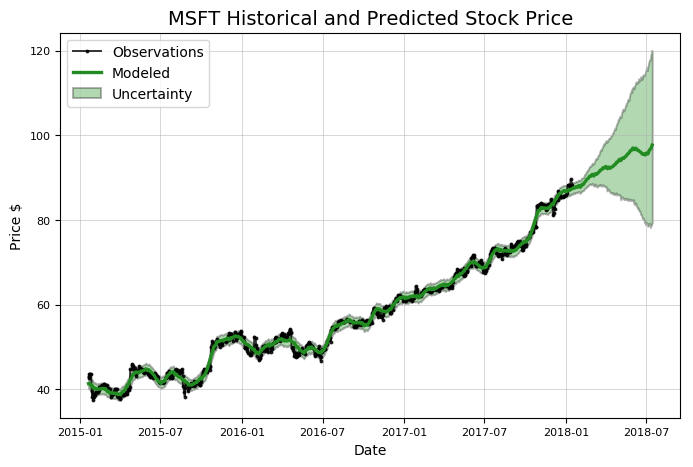
上面我们只探究了Stocker的前一半功能而已,现在讲讲Stocker的预测能力。虽然这样做没什么用(或者至少不会得到回报),但在这个过程中还有很多需要学习的东西!请继续关注未来关于Stocker预测能力的文章,或者尝试自己使用Stocker进行预测,可以查看这里: WillKoehrsen/Data-Analysis。下面是我们利用Stocker预测的微软股票未来走势:
# specify number of days in future to make a prediction
model, future = microsoft.create_prophet_model(days=180)
Predicted Price on 2018-07-15 = $97.67
结语
Stocker是我们用Python分析股票时一个很实用的工具,已经开源,而且更重要的是能教会我们很多有关数据科学、Python和股票市场的知识。我们生活在一个很棒的时代,任何人都可以自学编程,探索甚至是像机器学习这样的未知领域。希望大家也能亲自实践用Python分析股票,也许会有意想不到的收获。
想了解更多 Python 姿势?快来集智主站:
集智专栏参考资料:
https://towardsdatascience.com/stock-analysis-in-python-a0054e2c1a4c
